
Përdorimi i njësive të përpunimit grafik (GPU) për të ekzekutuar modelet tuaja të mësimit të makinerisë (ML) mund të përmirësojë në mënyrë dramatike performancën e modelit tuaj dhe përvojën e përdoruesit të aplikacioneve tuaja të aktivizuara me ML. Në pajisjet iOS, mund të aktivizoni përdorimin e ekzekutimit të përshpejtuar nga GPU të modeleve tuaja duke përdorur një delegat . Delegatët veprojnë si drejtues harduerësh për LiteRT, duke ju lejuar të ekzekutoni kodin e modelit tuaj në procesorët GPU.
Kjo faqe përshkruan se si të aktivizoni përshpejtimin GPU për modelet LiteRT në aplikacionet iOS. Për më shumë informacion rreth përdorimit të delegatit të GPU për LiteRT, duke përfshirë praktikat më të mira dhe teknikat e avancuara, shihni faqen e delegatëve të GPU .
Përdorni GPU me Interpreter API
LiteRT Interpreter API ofron një sërë API-sh për qëllime të përgjithshme për ndërtimin e një aplikacioni për mësimin e makinerive. Udhëzimet e mëposhtme ju udhëzojnë duke shtuar mbështetjen e GPU-së në një aplikacion iOS. Ky udhëzues supozon se tashmë keni një aplikacion iOS që mund të ekzekutojë me sukses një model ML me LiteRT.
Modifiko skedarin Podfile për të përfshirë mbështetjen e GPU-së
Duke filluar me lëshimin e LiteRT 2.3.0, delegati i GPU-së përjashtohet nga pod për të zvogëluar madhësinë binare. Ju mund t'i përfshini ato duke specifikuar një nënspeci për podin TensorFlowLiteSwift :
pod 'TensorFlowLiteSwift/Metal', '~> 0.0.1-nightly',
OSE
pod 'TensorFlowLiteSwift', '~> 0.0.1-nightly', :subspecs => ['Metal']
Mund të përdorni gjithashtu TensorFlowLiteObjC ose TensorFlowLiteC nëse dëshironi të përdorni Objective-C, i cili është i disponueshëm për versionet 2.4.0 dhe më të lartë, ose C API.
Inicializoni dhe përdorni delegatin GPU
Ju mund të përdorni delegatin e GPU-së me LiteRT Interpreter API me një numër gjuhësh programimi. Rekomandohen Swift dhe Objective-C, por mund të përdorni gjithashtu C++ dhe C. Përdorimi i C kërkohet nëse përdorni një version të LiteRT më të hershëm se 2.4. Shembujt e mëposhtëm të kodit përshkruajnë mënyrën e përdorimit të delegatit me secilën nga këto gjuhë.
Swift
import TensorFlowLite // Load model ... // Initialize LiteRT interpreter with the GPU delegate. let delegate = MetalDelegate() if let interpreter = try Interpreter(modelPath: modelPath, delegates: [delegate]) { // Run inference ... }
Objektivi-C
// Import module when using CocoaPods with module support @import TFLTensorFlowLite; // Or import following headers manually #import "tensorflow/lite/objc/apis/TFLMetalDelegate.h" #import "tensorflow/lite/objc/apis/TFLTensorFlowLite.h" // Initialize GPU delegate TFLMetalDelegate* metalDelegate = [[TFLMetalDelegate alloc] init]; // Initialize interpreter with model path and GPU delegate TFLInterpreterOptions* options = [[TFLInterpreterOptions alloc] init]; NSError* error = nil; TFLInterpreter* interpreter = [[TFLInterpreter alloc] initWithModelPath:modelPath options:options delegates:@[ metalDelegate ] error:&error]; if (error != nil) { /* Error handling... */ } if (![interpreter allocateTensorsWithError:&error]) { /* Error handling... */ } if (error != nil) { /* Error handling... */ } // Run inference ...
C++
// Set up interpreter. auto model = FlatBufferModel::BuildFromFile(model_path); if (!model) return false; tflite::ops::builtin::BuiltinOpResolver op_resolver; std::unique_ptr<Interpreter> interpreter; InterpreterBuilder(*model, op_resolver)(&interpreter); // Prepare GPU delegate. auto* delegate = TFLGpuDelegateCreate(/*default options=*/nullptr); if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; // Run inference. WriteToInputTensor(interpreter->typed_input_tensor<float>(0)); if (interpreter->Invoke() != kTfLiteOk) return false; ReadFromOutputTensor(interpreter->typed_output_tensor<float>(0)); // Clean up. TFLGpuDelegateDelete(delegate);
C (përpara 2.4.0)
#include "tensorflow/lite/c/c_api.h" #include "tensorflow/lite/delegates/gpu/metal_delegate.h" // Initialize model TfLiteModel* model = TfLiteModelCreateFromFile(model_path); // Initialize interpreter with GPU delegate TfLiteInterpreterOptions* options = TfLiteInterpreterOptionsCreate(); TfLiteDelegate* delegate = TFLGPUDelegateCreate(nil); // default config TfLiteInterpreterOptionsAddDelegate(options, metal_delegate); TfLiteInterpreter* interpreter = TfLiteInterpreterCreate(model, options); TfLiteInterpreterOptionsDelete(options); TfLiteInterpreterAllocateTensors(interpreter); NSMutableData *input_data = [NSMutableData dataWithLength:input_size * sizeof(float)]; NSMutableData *output_data = [NSMutableData dataWithLength:output_size * sizeof(float)]; TfLiteTensor* input = TfLiteInterpreterGetInputTensor(interpreter, 0); const TfLiteTensor* output = TfLiteInterpreterGetOutputTensor(interpreter, 0); // Run inference TfLiteTensorCopyFromBuffer(input, inputData.bytes, inputData.length); TfLiteInterpreterInvoke(interpreter); TfLiteTensorCopyToBuffer(output, outputData.mutableBytes, outputData.length); // Clean up TfLiteInterpreterDelete(interpreter); TFLGpuDelegateDelete(metal_delegate); TfLiteModelDelete(model);
Shënime të përdorimit të gjuhës GPU API
- Versionet LiteRT para 2.4.0 mund të përdorin vetëm C API për Objective-C.
- API C++ disponohet vetëm kur përdorni bazel ose kur ndërtoni vetë TensorFlow Lite. C++ API nuk mund të përdoret me CocoaPods.
- Kur përdorni LiteRT me delegatin e GPU-së me C++, merrni delegatin e GPU-së nëpërmjet funksionit
TFLGpuDelegateCreate()dhe më pas kaloni teInterpreter::ModifyGraphWithDelegate(), në vend që të thërrisniInterpreter::AllocateTensors().
Ndërtoni dhe provoni me modalitetin e lëshimit
Ndrysho në një version lëshimi me cilësimet e duhura të përshpejtuesit të Metal API për të marrë performancë më të mirë dhe për testimin përfundimtar. Ky seksion shpjegon se si të aktivizoni një cilësim të krijimit dhe konfigurimit të lëshimit për përshpejtimin Metal.
Për të ndryshuar në një version të versionit:
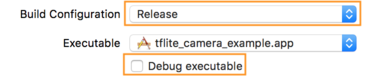
- Ndryshoni cilësimet e ndërtimit duke zgjedhur Produkt > Skema > Modifiko skemën... dhe më pas duke zgjedhur Ekzekuto .
- Në skedën Info , ndryshoni konfigurimin e ndërtimit në Release dhe zgjidhni Debug executable .
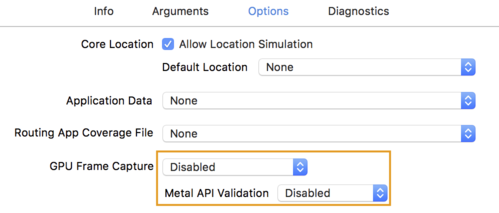
- Klikoni në skedën "Opsionet" dhe ndryshoni " Kapja e kornizës së GPU" në "Disabled" dhe "Vleresimi i API-së Metal" në "Disabled" .
- Sigurohuni që të zgjidhni ndërtimet vetëm për lëshim mbi arkitekturën 64-bit. Nën navigatorin e projektit > tflite_camera_example > PROJEKT > emrin_projekt_yt > Vendosni Cilësimet e ndërtimit Build Active Architecture Only > Lëshojeni në Po .

Mbështetje e avancuar GPU
Ky seksion mbulon përdorime të avancuara të delegatit të GPU-së për iOS, duke përfshirë opsionet e delegimit, buferët e hyrjes dhe daljes dhe përdorimin e modeleve të kuantizuara.
Delegoni opsionet për iOS
Konstruktori për delegatin e GPU-së pranon një struct opsionesh në Swift API , Objective-C API dhe C API . Kalimi nullptr (C API) ose asgjë (Objective-C dhe Swift API) te iniciatori vendos opsionet e paracaktuara (të cilat shpjegohen në shembullin e përdorimit bazë të mësipërm).
Swift
// THIS: var options = MetalDelegate.Options() options.isPrecisionLossAllowed = false options.waitType = .passive options.isQuantizationEnabled = true let delegate = MetalDelegate(options: options) // IS THE SAME AS THIS: let delegate = MetalDelegate()
Objektivi-C
// THIS: TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init]; options.precisionLossAllowed = false; options.waitType = TFLMetalDelegateThreadWaitTypePassive; options.quantizationEnabled = true; TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] initWithOptions:options]; // IS THE SAME AS THIS: TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] init];
C
// THIS: const TFLGpuDelegateOptions options = { .allow_precision_loss = false, .wait_type = TFLGpuDelegateWaitType::TFLGpuDelegateWaitTypePassive, .enable_quantization = true, }; TfLiteDelegate* delegate = TFLGpuDelegateCreate(options); // IS THE SAME AS THIS: TfLiteDelegate* delegate = TFLGpuDelegateCreate(nullptr);
Buferat hyrëse/dalëse duke përdorur C++ API
Llogaritja në GPU kërkon që të dhënat të jenë të disponueshme për GPU-në. Kjo kërkesë shpesh nënkupton që ju duhet të kryeni një kopje të kujtesës. Nëse është e mundur, duhet të shmangni që të dhënat tuaja të kalojnë kufirin e kujtesës CPU/GPU, pasi kjo mund të marrë një kohë të konsiderueshme. Zakonisht, një kalim i tillë është i pashmangshëm, por në disa raste të veçanta, njëra ose tjetra mund të anashkalohet.
Nëse hyrja e rrjetit është një imazh i ngarkuar tashmë në memorien GPU (për shembull, një teksturë GPU që përmban furnizimin e kamerës), ai mund të qëndrojë në memorien GPU pa hyrë kurrë në memorien e CPU. Në mënyrë të ngjashme, nëse dalja e rrjetit është në formën e një imazhi të rindërtuar, siç është një operacion transferimi i stilit të imazhit , ju mund ta shfaqni drejtpërdrejt rezultatin në ekran.
Për të arritur performancën më të mirë, LiteRT bën të mundur që përdoruesit të lexojnë dhe të shkruajnë drejtpërdrejt nga buferi i harduerit TensorFlow dhe të anashkalojnë kopjet e memories të shmangshme.
Duke supozuar se hyrja e imazhit është në memorien GPU, së pari duhet ta konvertoni atë në një objekt MTLBuffer për Metal. Ju mund të lidhni një TfLiteTensor me një MTLBuffer të përgatitur nga përdoruesi me funksionin TFLGpuDelegateBindMetalBufferToTensor() . Vini re se ky funksion duhet të thirret pas Interpreter::ModifyGraphWithDelegate() . Për më tepër, dalja e konkluzionit, si parazgjedhje, kopjohet nga memoria GPU në memorien e CPU. Ju mund ta çaktivizoni këtë sjellje duke thirrur Interpreter::SetAllowBufferHandleOutput(true) gjatë inicializimit.
C++
#include "tensorflow/lite/delegates/gpu/metal_delegate.h" #include "tensorflow/lite/delegates/gpu/metal_delegate_internal.h" // ... // Prepare GPU delegate. auto* delegate = TFLGpuDelegateCreate(nullptr); if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; interpreter->SetAllowBufferHandleOutput(true); // disable default gpu->cpu copy if (!TFLGpuDelegateBindMetalBufferToTensor( delegate, interpreter->inputs()[0], user_provided_input_buffer)) { return false; } if (!TFLGpuDelegateBindMetalBufferToTensor( delegate, interpreter->outputs()[0], user_provided_output_buffer)) { return false; } // Run inference. if (interpreter->Invoke() != kTfLiteOk) return false;
Pasi të çaktivizohet sjellja e paracaktuar, kopjimi i daljes së konkluzionit nga memoria e GPU-së në memorien e CPU-së kërkon një thirrje eksplicite te Interpreter::EnsureTensorDataIsReadable() për çdo tensor dalës. Kjo qasje funksionon gjithashtu për modelet e kuantizuara, por ju duhet të përdorni një tampon me madhësi float32 me të dhëna float32 , sepse buferi është i lidhur me buferin e brendshëm të de-kuantizuar.
Modele të kuantizuara
Bibliotekat e delegatëve të GPU-së iOS mbështesin si parazgjedhje modele të kuantizuara . Ju nuk keni nevojë të bëni ndonjë ndryshim kodi për të përdorur modele të kuantizuara me delegatin e GPU. Seksioni vijues shpjegon se si të çaktivizohet mbështetja e kuantizuar për qëllime testimi ose eksperimentale.
Çaktivizo mbështetjen e modelit të kuantizuar
Kodi i mëposhtëm tregon se si të çaktivizoni mbështetjen për modelet e kuantizuara.
Swift
var options = MetalDelegate.Options() options.isQuantizationEnabled = false let delegate = MetalDelegate(options: options)
Objektivi-C
TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init]; options.quantizationEnabled = false;
C
TFLGpuDelegateOptions options = TFLGpuDelegateOptionsDefault(); options.enable_quantization = false; TfLiteDelegate* delegate = TFLGpuDelegateCreate(options);
Për më shumë informacion rreth ekzekutimit të modeleve të kuantizuara me përshpejtim GPU, shihni përmbledhjen e delegatëve të GPU .