
Usar unidades de procesamiento gráfico (GPU) para ejecutar tus modelos de aprendizaje automático (AA) puede mejorar drásticamente el rendimiento del modelo y la experiencia del usuario de tus aplicaciones habilitadas para AA. En los dispositivos iOS, puedes habilitar el uso de Ejecución acelerada por GPU de tus modelos mediante un delegate. Los delegados actúan como controladores de hardware para LiteRT, que te permite ejecutar el código de tu modelo en procesadores de GPU.
En esta página, se describe cómo habilitar la aceleración de GPU para modelos LiteRT en apps para iOS. Para obtener más información sobre el uso del delegado de GPU para LiteRT, incluidas las prácticas recomendadas y las técnicas avanzadas, consulta la documentación de GPU página de delegados.
Usa GPU con la API de Interpreter
El intérprete de LiteRT API ofrece un conjunto de datos para compilar aplicaciones de aprendizaje automático. Lo siguiente Las instrucciones te guiarán para agregar compatibilidad con GPU a una app para iOS. Esta guía supone que ya tienes una app para iOS que puede ejecutar correctamente un modelo de AA con LiteRT.
Modifica el Podfile para incluir la compatibilidad con GPU
A partir de la versión LiteRT 2.3.0, se excluye el delegado de GPU
del Pod para reducir el tamaño del objeto binario. Puedes incluirlos especificando un
subespecificación para el Pod TensorFlowLiteSwift:
pod 'TensorFlowLiteSwift/Metal', '~> 0.0.1-nightly',
O
pod 'TensorFlowLiteSwift', '~> 0.0.1-nightly', :subspecs => ['Metal']
También puedes usar TensorFlowLiteObjC o TensorFlowLiteC si quieres usar
Objective-C, que está disponible para las versiones 2.4.0 y posteriores, o la API de C.
Inicializa y usa el delegado de GPU
Puedes usar el delegado de la GPU con el Interpretador de LiteRT API con cierta programación idiomas. Te recomendamos Swift y Objective-C, pero también puedes usar C++ y C) Debes usar C si usas una versión anterior de LiteRT. que la 2.4. En los siguientes ejemplos de código, se describe cómo usar el delegado con cada de estos lenguajes.
Swift
import TensorFlowLite // Load model ... // Initialize LiteRT interpreter with the GPU delegate. let delegate = MetalDelegate() if let interpreter = try Interpreter(modelPath: modelPath, delegates: [delegate]) { // Run inference ... }
Objective-C
// Import module when using CocoaPods with module support @import TFLTensorFlowLite; // Or import following headers manually #import "tensorflow/lite/objc/apis/TFLMetalDelegate.h" #import "tensorflow/lite/objc/apis/TFLTensorFlowLite.h" // Initialize GPU delegate TFLMetalDelegate* metalDelegate = [[TFLMetalDelegate alloc] init]; // Initialize interpreter with model path and GPU delegate TFLInterpreterOptions* options = [[TFLInterpreterOptions alloc] init]; NSError* error = nil; TFLInterpreter* interpreter = [[TFLInterpreter alloc] initWithModelPath:modelPath options:options delegates:@[ metalDelegate ] error:&error]; if (error != nil) { /* Error handling... */ } if (![interpreter allocateTensorsWithError:&error]) { /* Error handling... */ } if (error != nil) { /* Error handling... */ } // Run inference ...
C++
// Set up interpreter. auto model = FlatBufferModel::BuildFromFile(model_path); if (!model) return false; tflite::ops::builtin::BuiltinOpResolver op_resolver; std::unique_ptr<Interpreter> interpreter; InterpreterBuilder(*model, op_resolver)(&interpreter); // Prepare GPU delegate. auto* delegate = TFLGpuDelegateCreate(/*default options=*/nullptr); if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; // Run inference. WriteToInputTensor(interpreter->typed_input_tensor<float>(0)); if (interpreter->Invoke() != kTfLiteOk) return false; ReadFromOutputTensor(interpreter->typed_output_tensor<float>(0)); // Clean up. TFLGpuDelegateDelete(delegate);
C (antes de 2.4.0)
#include "tensorflow/lite/c/c_api.h" #include "tensorflow/lite/delegates/gpu/metal_delegate.h" // Initialize model TfLiteModel* model = TfLiteModelCreateFromFile(model_path); // Initialize interpreter with GPU delegate TfLiteInterpreterOptions* options = TfLiteInterpreterOptionsCreate(); TfLiteDelegate* delegate = TFLGPUDelegateCreate(nil); // default config TfLiteInterpreterOptionsAddDelegate(options, metal_delegate); TfLiteInterpreter* interpreter = TfLiteInterpreterCreate(model, options); TfLiteInterpreterOptionsDelete(options); TfLiteInterpreterAllocateTensors(interpreter); NSMutableData *input_data = [NSMutableData dataWithLength:input_size * sizeof(float)]; NSMutableData *output_data = [NSMutableData dataWithLength:output_size * sizeof(float)]; TfLiteTensor* input = TfLiteInterpreterGetInputTensor(interpreter, 0); const TfLiteTensor* output = TfLiteInterpreterGetOutputTensor(interpreter, 0); // Run inference TfLiteTensorCopyFromBuffer(input, inputData.bytes, inputData.length); TfLiteInterpreterInvoke(interpreter); TfLiteTensorCopyToBuffer(output, outputData.mutableBytes, outputData.length); // Clean up TfLiteInterpreterDelete(interpreter); TFLGpuDelegateDelete(metal_delegate); TfLiteModelDelete(model);
Notas de uso del lenguaje de la API de GPU
- Las versiones LiteRT anteriores a la 2.4.0 solo pueden usar la API C para Objective‐C.
- La API de C++ solo está disponible cuando usas Bazel o compilas TensorFlow. Lite por tu cuenta No se puede usar la API de C++ con CocoaPods.
- Cuando usas LiteRT con el delegado de la GPU con C++, obtén la GPU.
delegar a través de la función
TFLGpuDelegateCreate()y, luego, pasarlo alInterpreter::ModifyGraphWithDelegate(), en lugar de llamarInterpreter::AllocateTensors()
Cómo compilar y probar con el modo de lanzamiento
Cambia a una compilación de lanzamiento con la configuración adecuada del acelerador de la API de Metal para para obtener un mejor rendimiento y para las pruebas finales. En esta sección, se explica cómo habilita una compilación de lanzamiento y establece la configuración de la aceleración de Metal.
Para cambiar a una compilación de lanzamiento, haz lo siguiente:
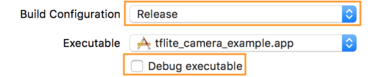
- Para editar la configuración de compilación, selecciona Producto > Esquema > Editar esquema... y, luego, selecciona Ejecutar.
- En la pestaña Info, cambia Build Configuration a Release.
Desmarca Depurar ejecutable.
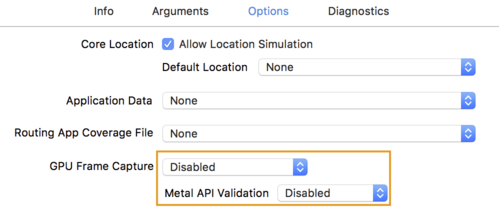
- Haz clic en la pestaña Options y cambia GPU Frame Capture a Disabled.
y Metal API Validation como Disabled.
- Asegúrate de seleccionar compilaciones solo de lanzamiento en una arquitectura de 64 bits. Por debajo
Navegador de proyectos > tflite_camera_example > PROYECTO > tu_nombre_de_tu_proyecto >
Build Settings establece Build Active Architecture Only > Suelta en
Sí.

Compatibilidad avanzada con GPU
Esta sección abarca los usos avanzados del delegado de GPU para iOS, incluido opciones de delegado, búferes de entrada y salida, y uso de modelos cuantificados.
Delegar opciones para iOS
El constructor para el delegado de la GPU acepta un struct de opciones en Swift
API,
Objective-C
API,
y C
API.
Pasar nullptr (API de C) o nada (API de Objective-C y Swift) a la
el inicializador establece las opciones predeterminadas (que se explican en la sección Uso básico)
ejemplo anterior).
Swift
// THIS: var options = MetalDelegate.Options() options.isPrecisionLossAllowed = false options.waitType = .passive options.isQuantizationEnabled = true let delegate = MetalDelegate(options: options) // IS THE SAME AS THIS: let delegate = MetalDelegate()
Objective-C
// THIS: TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init]; options.precisionLossAllowed = false; options.waitType = TFLMetalDelegateThreadWaitTypePassive; options.quantizationEnabled = true; TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] initWithOptions:options]; // IS THE SAME AS THIS: TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] init];
C
// THIS: const TFLGpuDelegateOptions options = { .allow_precision_loss = false, .wait_type = TFLGpuDelegateWaitType::TFLGpuDelegateWaitTypePassive, .enable_quantization = true, }; TfLiteDelegate* delegate = TFLGpuDelegateCreate(options); // IS THE SAME AS THIS: TfLiteDelegate* delegate = TFLGpuDelegateCreate(nullptr);
Búferes de entrada y salida con la API de C++
El procesamiento en la GPU requiere que los datos estén disponibles para la GPU. Esta requisito suele implicar que debes realizar una copia en la memoria. Debes evitar tener si tus datos superan el límite de memoria de CPU/GPU si es posible, ya que esto puede ocupar durante una cantidad de tiempo significativa. Por lo general, ese cruce es inevitable, pero en algunos casos especiales, uno u otro se puede omitir.
Si la entrada de red es una imagen ya cargada en la memoria de la GPU (por ejemplo, una textura de GPU que contiene el feed de la cámara), esta puede permanecer en la memoria de la GPU sin ingresar a la memoria de la CPU. Del mismo modo, si la salida de la red está en el formato de una imagen renderizada, como un estilo de imagen transferencia puedes mostrar el resultado directamente en la pantalla.
Para lograr el mejor rendimiento, LiteRT permite que los usuarios puede leer y escribir directamente en el búfer de hardware de TensorFlow, así como omitir copias de memoria evitables.
Si suponemos que la entrada de imagen está en la memoria GPU, primero debes convertirla en un
Objeto MTLBuffer para Metal. Puedes asociar un TfLiteTensor a un
MTLBuffer preparado por el usuario con TFLGpuDelegateBindMetalBufferToTensor()
. Ten en cuenta que esta función debe llamarse después
Interpreter::ModifyGraphWithDelegate() Además, el resultado de la inferencia es
de forma predeterminada, se copia de la memoria de la GPU a la memoria de la CPU. Puedes desactivar este comportamiento
llamando a Interpreter::SetAllowBufferHandleOutput(true) durante
de inicio.
C++
#include "tensorflow/lite/delegates/gpu/metal_delegate.h" #include "tensorflow/lite/delegates/gpu/metal_delegate_internal.h" // ... // Prepare GPU delegate. auto* delegate = TFLGpuDelegateCreate(nullptr); if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; interpreter->SetAllowBufferHandleOutput(true); // disable default gpu->cpu copy if (!TFLGpuDelegateBindMetalBufferToTensor( delegate, interpreter->inputs()[0], user_provided_input_buffer)) { return false; } if (!TFLGpuDelegateBindMetalBufferToTensor( delegate, interpreter->outputs()[0], user_provided_output_buffer)) { return false; } // Run inference. if (interpreter->Invoke() != kTfLiteOk) return false;
Una vez que se desactiva el comportamiento predeterminado, se copia el resultado de la inferencia de la GPU
entre la memoria y la CPU requiere una llamada explícita
Interpreter::EnsureTensorDataIsReadable() para cada tensor de salida. Esta
también funciona para modelos cuantizados, pero aún debes usar
búfer de tamaño flotante float32 con datos de float32, ya que el búfer está vinculado al
búfer interno descuantizado.
Modelos cuantificados
Las bibliotecas delegadas de GPU para iOS admiten modelos cuantizados de forma predeterminada. No debes deberá realizar cambios en el código para usar modelos cuantizados con el delegado de la GPU. El En la siguiente sección, se explica cómo inhabilitar la asistencia cuantizada para pruebas o con fines experimentales.
Inhabilitar la compatibilidad con modelos cuantizados
En el siguiente código, se muestra cómo inhabilitar la compatibilidad con modelos cuantizados.
Swift
var options = MetalDelegate.Options() options.isQuantizationEnabled = false let delegate = MetalDelegate(options: options)
Objective-C
TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init]; options.quantizationEnabled = false;
C
TFLGpuDelegateOptions options = TFLGpuDelegateOptionsDefault(); options.enable_quantization = false; TfLiteDelegate* delegate = TFLGpuDelegateCreate(options);
Para obtener más información sobre cómo ejecutar modelos cuantizados con aceleración de GPU, consulta Descripción general del delegado de GPU.