
Korzystanie z procesorów graficznych (GPU) do uruchamiania modeli systemów uczących się może znacząco poprawić wydajność modelu i wygodę użytkowników Twoich aplikacji obsługujących ML. Na urządzeniach z iOS możesz włączyć Przyspieszone przez GPU wykonywanie modeli za pomocą przekazanie dostępu. Przedstawiciele działają jako sterowniki sprzętowe LiteRT, które umożliwia uruchamianie kodu modelu na procesorach GPU.
Na tej stronie dowiesz się, jak włączyć akcelerację GPU w modelach LiteRT w Aplikacje na iOS. Aby dowiedzieć się więcej o korzystaniu z przekazywania GPU w przypadku LiteRT, w tym sprawdzonych metod i zaawansowanych technik, zawiera artykuł GPU .
Używanie GPU z interfejsem Interpreter API
Tłumacz literatury LiteRT API udostępnia zestaw ogólnych do tworzenia aplikacji do systemów uczących się. Poniżej instrukcje dodawania obsługi GPU do aplikacji na iOS. Ten przewodnik zakłada, że masz już aplikację na iOS, która może wykonać model ML dzięki LiteRT.
Zmodyfikuj plik Podfile, aby obsługiwał GPU
Od wersji LiteRT 2.3.0 dostęp do GPU jest wykluczony
z poda, aby zmniejszyć rozmiar pliku binarnego. Możesz je uwzględnić, określając
podspecyfikacja poda TensorFlowLiteSwift:
pod 'TensorFlowLiteSwift/Metal', '~> 0.0.1-nightly',
LUB
pod 'TensorFlowLiteSwift', '~> 0.0.1-nightly', :subspecs => ['Metal']
Możesz też użyć TensorFlowLiteObjC lub TensorFlowLiteC, jeśli chcesz używać
Objective-C (dostępny w wersji 2.4.0 i nowszych) lub C API.
Inicjowanie i używanie przekazywania dostępu do GPU
Możesz używać przedstawicieli GPU za pomocą tłumacza języka tłumaczonego przy użyciu LiteRT API z wieloma programami, języki. Zalecamy używanie języków Swift i Objective-C, ale możesz też używać C++ C: Jeśli korzystasz z wersji LiteRT wcześniej, użycie języka C jest wymagane niż 2,4. Poniższe przykłady kodu pokazują, jak używać przedstawiciela z każdym tych języków.
Swift
import TensorFlowLite // Load model ... // Initialize LiteRT interpreter with the GPU delegate. let delegate = MetalDelegate() if let interpreter = try Interpreter(modelPath: modelPath, delegates: [delegate]) { // Run inference ... }
Objective-C
// Import module when using CocoaPods with module support @import TFLTensorFlowLite; // Or import following headers manually #import "tensorflow/lite/objc/apis/TFLMetalDelegate.h" #import "tensorflow/lite/objc/apis/TFLTensorFlowLite.h" // Initialize GPU delegate TFLMetalDelegate* metalDelegate = [[TFLMetalDelegate alloc] init]; // Initialize interpreter with model path and GPU delegate TFLInterpreterOptions* options = [[TFLInterpreterOptions alloc] init]; NSError* error = nil; TFLInterpreter* interpreter = [[TFLInterpreter alloc] initWithModelPath:modelPath options:options delegates:@[ metalDelegate ] error:&error]; if (error != nil) { /* Error handling... */ } if (![interpreter allocateTensorsWithError:&error]) { /* Error handling... */ } if (error != nil) { /* Error handling... */ } // Run inference ...
C++
// Set up interpreter. auto model = FlatBufferModel::BuildFromFile(model_path); if (!model) return false; tflite::ops::builtin::BuiltinOpResolver op_resolver; std::unique_ptr<Interpreter> interpreter; InterpreterBuilder(*model, op_resolver)(&interpreter); // Prepare GPU delegate. auto* delegate = TFLGpuDelegateCreate(/*default options=*/nullptr); if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; // Run inference. WriteToInputTensor(interpreter->typed_input_tensor<float>(0)); if (interpreter->Invoke() != kTfLiteOk) return false; ReadFromOutputTensor(interpreter->typed_output_tensor<float>(0)); // Clean up. TFLGpuDelegateDelete(delegate);
C (przed 2.4.0)
#include "tensorflow/lite/c/c_api.h" #include "tensorflow/lite/delegates/gpu/metal_delegate.h" // Initialize model TfLiteModel* model = TfLiteModelCreateFromFile(model_path); // Initialize interpreter with GPU delegate TfLiteInterpreterOptions* options = TfLiteInterpreterOptionsCreate(); TfLiteDelegate* delegate = TFLGPUDelegateCreate(nil); // default config TfLiteInterpreterOptionsAddDelegate(options, metal_delegate); TfLiteInterpreter* interpreter = TfLiteInterpreterCreate(model, options); TfLiteInterpreterOptionsDelete(options); TfLiteInterpreterAllocateTensors(interpreter); NSMutableData *input_data = [NSMutableData dataWithLength:input_size * sizeof(float)]; NSMutableData *output_data = [NSMutableData dataWithLength:output_size * sizeof(float)]; TfLiteTensor* input = TfLiteInterpreterGetInputTensor(interpreter, 0); const TfLiteTensor* output = TfLiteInterpreterGetOutputTensor(interpreter, 0); // Run inference TfLiteTensorCopyFromBuffer(input, inputData.bytes, inputData.length); TfLiteInterpreterInvoke(interpreter); TfLiteTensorCopyToBuffer(output, outputData.mutableBytes, outputData.length); // Clean up TfLiteInterpreterDelete(interpreter); TFLGpuDelegateDelete(metal_delegate); TfLiteModelDelete(model);
Uwagi na temat użycia języka interfejsu GPU API
- Wersje LiteRT wcześniejsze niż 2.4.0 mogą używać interfejsu C API tylko w przypadku Objective-C.
- Interfejs API C++ jest dostępny tylko wtedy, gdy korzystasz z bazel lub kompilowania TensorFlow Lite dla siebie. Interfejsu API C++ nie można używać z CocoaPods.
- Jeśli używasz LiteRT z delegatem GPU w C++, pobierz GPU
przekazać dostęp za pomocą funkcji
TFLGpuDelegateCreate(), a następnie przekazać ją doInterpreter::ModifyGraphWithDelegate(), zamiast dzwonićInterpreter::AllocateTensors()
Kompilowanie i testowanie w trybie wydania
Zmień na kompilację wersji z odpowiednimi ustawieniami akceleratora Metal API na aby zwiększyć skuteczność i przeprowadzić testy końcowe. W tej sekcji wyjaśniamy, jak włączyć kompilację wersji i skonfigurować ustawienie przyspieszania metalu.
Aby przejść na kompilację wersji:
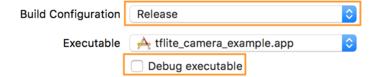
- Aby zmienić ustawienia kompilacji, wybierz Produkt > Schemat > Edytuj schemat... a następnie Uruchom.
- Na karcie Informacje zmień Konfigurację kompilacji na Wersja i
odznacz Debuguj plik wykonywalny.
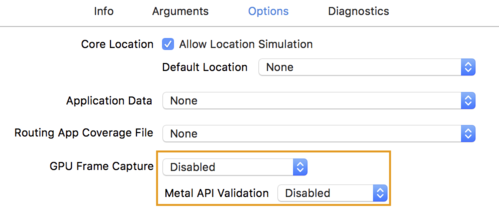
- Kliknij kartę Options (Opcje) i zmień GPU Frame Capture na Disabled (Wyłączone).
i Walidacja interfejsu Metal API na Wyłączona.
- Pamiętaj, aby wybrać tryb Tylko wersje wykorzystujący architekturę 64-bitową. Poniżej
Nawigator projektów > tflite_camera_example > PROJEKT > nazwa_projektu >
Ustawienia kompilacji ustawione na Twórz tylko aktywną architekturę > Zwolnij:
Tak.

Zaawansowana obsługa GPU
W tej sekcji omawiamy zaawansowane zastosowania przekazywania GPU w iOS, w tym: delegowania opcji, buforów wejściowych i wyjściowych oraz korzystanie z modeli kwantyzowanych.
Opcje przekazywania dostępu w systemie iOS
Konstruktor dla delegata GPU akceptuje struct opcji w Swift
API
Objective-C
API,
i C
.
przekazanie nullptr (C API) lub brak danych (Objective-C i Swift API) do
inicjator ustawia opcje domyślne (które są objaśnione w sekcji Podstawowe użycie
powyżej).
Swift
// THIS: var options = MetalDelegate.Options() options.isPrecisionLossAllowed = false options.waitType = .passive options.isQuantizationEnabled = true let delegate = MetalDelegate(options: options) // IS THE SAME AS THIS: let delegate = MetalDelegate()
Objective-C
// THIS: TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init]; options.precisionLossAllowed = false; options.waitType = TFLMetalDelegateThreadWaitTypePassive; options.quantizationEnabled = true; TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] initWithOptions:options]; // IS THE SAME AS THIS: TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] init];
C
// THIS: const TFLGpuDelegateOptions options = { .allow_precision_loss = false, .wait_type = TFLGpuDelegateWaitType::TFLGpuDelegateWaitTypePassive, .enable_quantization = true, }; TfLiteDelegate* delegate = TFLGpuDelegateCreate(options); // IS THE SAME AS THIS: TfLiteDelegate* delegate = TFLGpuDelegateCreate(nullptr);
Bufory wejściowe/wyjściowe z użyciem interfejsu API C++
Obliczanie w GPU wymaga, aby dane były dostępne dla GPU. Ten wymaga często kopii z pamięci. Należy unikać dane mogą przekraczać granice pamięci procesora/GPU, ponieważ może to zająć przez dłuższy czas. Zwykle takie przekroczenie jest nieuniknione, ale w niektórych w szczególnych przypadkach, jeden lub drugi może zostać pominięty.
Jeśli danymi wejściowymi sieci jest obraz wczytany już w pamięci GPU (na np. teksturę GPU zawierającą kanał aparatu), może pozostać w pamięci GPU bez dostępu do pamięci procesora. Podobnie, jeśli dane wyjściowe sieci są rodzaj możliwego do renderowania obrazu, np. styl obrazu przenieś możesz wyświetlić wynik bezpośrednio na ekranie.
Aby uzyskać najlepszą wydajność, LiteRT umożliwia użytkownikom bezpośredni odczyt z bufora sprzętowego TensorFlow i zapis w nim oraz omijanie kopii wspomnień, których można uniknąć.
Zakładając, że dane wejściowe obrazu są zapisane w pamięci GPU, musisz najpierw przekonwertować je na
Obiekt MTLBuffer dla Metal. TfLiteTensor możesz powiązać z
przygotowane przez użytkownika MTLBuffer za pomocą tagu TFLGpuDelegateBindMetalBufferToTensor()
. Pamiętaj, że ta funkcja musi zostać wywołana po
Interpreter::ModifyGraphWithDelegate() Dodatkowo dane wyjściowe wnioskowania to:
kopiowana z pamięci GPU do pamięci procesora. Możesz wyłączyć tę funkcję
dzwoniąc pod numer Interpreter::SetAllowBufferHandleOutput(true) w trakcie
jego zainicjowanie.
C++
#include "tensorflow/lite/delegates/gpu/metal_delegate.h" #include "tensorflow/lite/delegates/gpu/metal_delegate_internal.h" // ... // Prepare GPU delegate. auto* delegate = TFLGpuDelegateCreate(nullptr); if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; interpreter->SetAllowBufferHandleOutput(true); // disable default gpu->cpu copy if (!TFLGpuDelegateBindMetalBufferToTensor( delegate, interpreter->inputs()[0], user_provided_input_buffer)) { return false; } if (!TFLGpuDelegateBindMetalBufferToTensor( delegate, interpreter->outputs()[0], user_provided_output_buffer)) { return false; } // Run inference. if (interpreter->Invoke() != kTfLiteOk) return false;
Po wyłączeniu domyślnego działania kopiuję dane wyjściowe wnioskowania z GPU
pamięć do pamięci procesora wymaga jawnego wywołania funkcji
Interpreter::EnsureTensorDataIsReadable() dla każdego tensora wyjściowego. Ten
sprawdza się też w przypadku modeli kwantowych, ale nadal musisz zastosować
bufor o rozmiarze float32 z danymi float32,
wewnętrzny bufor zdekwantyzowany.
Modele kwantowe
Biblioteki delegowania GPU w iOS domyślnie obsługują modele kwantowe. Ty nie wprowadzenia zmian w kodzie, aby można było używać skwantyzowanych modeli z delegacją GPU. poniżej dowiesz się, jak wyłączyć kwantyzowaną obsługę testów lub do celów eksperymentalnych.
Wyłącz obsługę modeli kwantowych
Ten kod pokazuje, jak wyłączyć obsługę modeli kwantyzowanych.
Swift
var options = MetalDelegate.Options() options.isQuantizationEnabled = false let delegate = MetalDelegate(options: options)
Objective-C
TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init]; options.quantizationEnabled = false;
C
TFLGpuDelegateOptions options = TFLGpuDelegateOptionsDefault(); options.enable_quantization = false; TfLiteDelegate* delegate = TFLGpuDelegateCreate(options);
Więcej informacji o uruchamianiu modeli kwantowych z akceleracją GPU znajdziesz w artykule Omówienie przekazywania dostępu do GPU.