
Os operadores de aprendizado de máquina (ML) usados no modelo podem afetar o processo de conversão de um modelo do TensorFlow para o formato LiteRT. O conversor LiteRT oferece suporte a um número limitado de operações do TensorFlow usadas em modelos de inferência comuns, o que significa que nem todos os modelos podem ser convertidos diretamente. A ferramenta de conversão permite incluir outros operadores, mas converter um modelo dessa forma também exige que você modifique o ambiente de execução do LiteRT usado para executar o modelo, o que pode limitar sua capacidade de usar opções de implantação de execução padrão, como os Serviços do Google Play.
O conversor LiteRT foi projetado para analisar a estrutura do modelo e aplicar otimizações para torná-lo compatível com os operadores diretamente compatíveis. Por exemplo, dependendo dos operadores de ML no seu modelo, o conversor pode omitir ou fundir esses operadores para mapeá-los aos equivalentes do LiteRT.
Mesmo para operações compatíveis, às vezes são esperados padrões de uso específicos por motivos de desempenho. A melhor maneira de entender como criar um modelo do TensorFlow que pode ser usado com o LiteRT é considerar cuidadosamente como as operações são convertidas e otimizadas, além das limitações impostas por esse processo.
Operadores compatíveis
Os operadores integrados do LiteRT são um subconjunto dos operadores que fazem parte da biblioteca principal do TensorFlow. Seu modelo do TensorFlow também pode incluir operadores personalizados na forma de operadores compostos ou novos operadores definidos por você. O diagrama abaixo mostra as relações entre esses operadores.
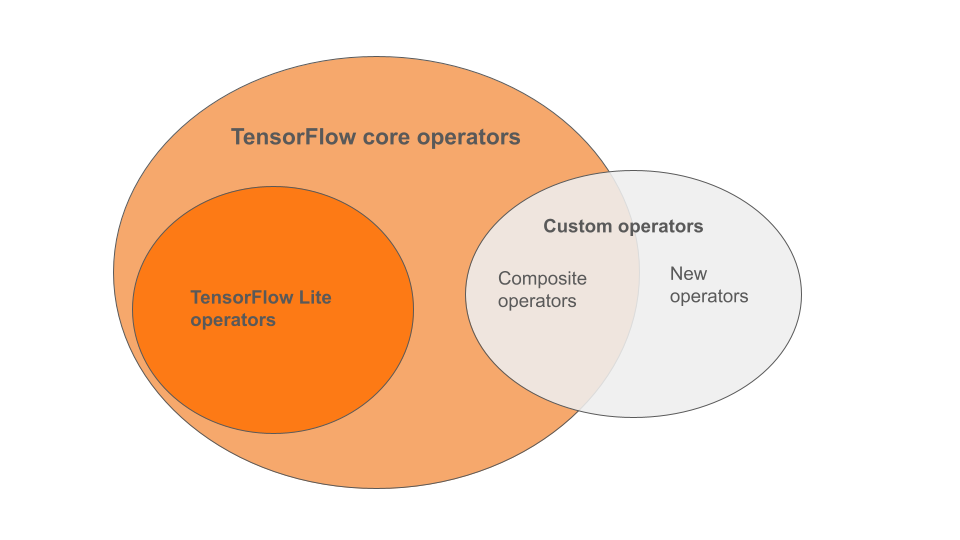
Nessa variedade de operadores de modelos de ML, há três tipos de modelos compatíveis com o processo de conversão:
- Modelos com apenas o operador integrado do LiteRT. (Recomendado)
- Modelos com os operadores integrados e operadores principais selecionados do TensorFlow.
- Modelos com operadores integrados, operadores principais do TensorFlow e/ou operadores personalizados.
Se o modelo tiver apenas operações compatíveis nativamente com o LiteRT, não será necessário usar flags extras para convertê-lo. Esse é o caminho recomendado porque esse tipo de modelo é convertido sem problemas e é mais simples de otimizar e executar usando o ambiente de execução LiteRT padrão. Você também tem mais opções de implantação para seu modelo, como os Serviços do Google Play. Comece com o guia do conversor LiteRT. Consulte a página de operações do LiteRT para ver uma lista de operadores integrados.
Se você precisar incluir operações selecionadas do TensorFlow na biblioteca principal, especifique isso na conversão e verifique se o tempo de execução inclui essas operações. Consulte o tópico Selecionar operadores do TensorFlow para etapas detalhadas.
Sempre que possível, evite a última opção de incluir operadores personalizados no modelo convertido. Operadores personalizados são criados combinando vários operadores primitivos do TensorFlow Core ou definindo um completamente novo. Quando os operadores personalizados são convertidos, eles podem aumentar o tamanho do modelo geral ao gerar dependências fora da biblioteca LiteRT integrada. As operações personalizadas, se não forem criadas especificamente para implantação em dispositivos móveis ou dispositivos, podem resultar em um desempenho pior quando implantadas em dispositivos com recursos limitados em comparação com um ambiente de servidor. Por fim, assim como a inclusão de operadores principais selecionados do TensorFlow, os operadores personalizados exigem que você modifique o ambiente de execução do modelo, o que limita o uso de serviços de execução padrão, como os Serviços do Google Play.
Tipos compatíveis
A maioria das operações do LiteRT tem como destino a inferência de ponto flutuante (float32) e quantizada (uint8, int8), mas muitas ainda não são compatíveis com outros tipos, como tf.float16 e strings.
Além de usar versões diferentes das operações, a outra diferença entre modelos de ponto flutuante e quantizados é a forma como eles são convertidos. A conversão quantizada exige informações de intervalo dinâmico para tensores. Isso exige "quantização falsa" durante o treinamento do modelo, recebendo informações de intervalo por um conjunto de dados de calibragem ou fazendo a estimativa de intervalo "on-the-fly". Consulte quantização para mais detalhes.
Conversões diretas, redução e fusão de constantes
Várias operações do TensorFlow podem ser processadas pela LiteRT, mesmo que não tenham um equivalente direto. É o caso de operações que podem ser simplesmente removidas do gráfico (tf.identity), substituídas por tensores (tf.placeholder) ou combinadas em operações mais complexas (tf.nn.bias_add). Até mesmo algumas operações compatíveis podem ser removidas por um desses processos.
Confira uma lista não exaustiva de operações do TensorFlow que geralmente são removidas do gráfico:
tf.addtf.debugging.check_numericstf.constanttf.divtf.dividetf.fake_quant_with_min_max_argstf.fake_quant_with_min_max_varstf.identitytf.maximumtf.minimumtf.multiplytf.no_optf.placeholdertf.placeholder_with_defaulttf.realdivtf.reduce_maxtf.reduce_mintf.reduce_sumtf.rsqrttf.shapetf.sqrttf.squaretf.subtracttf.tiletf.nn.batch_norm_with_global_normalizationtf.nn.bias_addtf.nn.fused_batch_normtf.nn.relutf.nn.relu6
Operações experimentais
As seguintes operações do LiteRT estão presentes, mas não estão prontas para modelos personalizados:
CALLCONCAT_EMBEDDINGSCUSTOMEMBEDDING_LOOKUP_SPARSEHASHTABLE_LOOKUPLSH_PROJECTIONSKIP_GRAMSVDF