
您在模型中使用的机器学习 (ML) 运算符可能会影响将 TensorFlow 模型转换为 LiteRT 格式的过程。LiteRT 转换器支持常用推理模型中使用的有限数量的 TensorFlow 操作,这意味着并非所有模型都可以直接转换。转换器工具允许您添加其他运算符,但以这种方式转换模型还需要您修改用于执行模型的 LiteRT 运行时环境,这可能会限制您使用标准运行时部署选项(例如 Google Play 服务)的能力。
LiteRT 转换器旨在分析模型结构并应用优化,使其与直接支持的运算符兼容。例如,根据模型中的机器学习运算符,转换器可能会省略或融合这些运算符,以便将它们映射到其 LiteRT 对等项。
即使对于受支持的操作,有时也需要特定的使用模式,以提高性能。若要了解如何构建可与 LiteRT 搭配使用的 TensorFlow 模型,最好的方法是仔细考虑运算的转换和优化方式,以及此过程带来的限制。
支持的运算符
LiteRT 内置运算符是 TensorFlow 核心库中运算符的一个子集。您的 TensorFlow 模型可能还包含自定义运算符,这些运算符可以是复合运算符,也可以是您定义的新运算符。下图显示了这些运算符之间的关系。
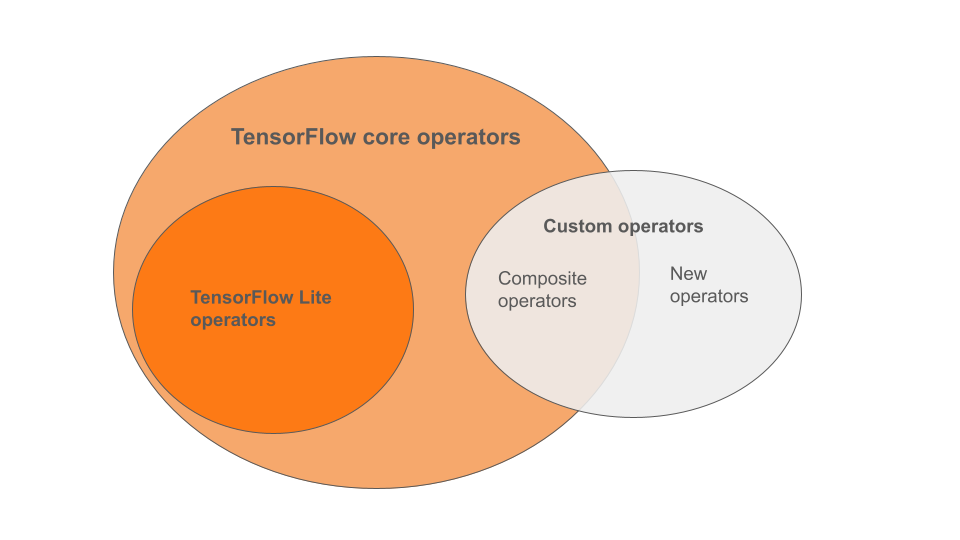
在此范围内的机器学习模型运算符中,转化过程支持 3 种类型的模型:
- 仅包含 LiteRT 内置运算符的模型。(推荐)
- 使用内置运算符和部分 TensorFlow 核心运算符的模型。
- 包含内置运算符、TensorFlow 核心运算符和/或自定义运算符的模型。
如果您的模型仅包含 LiteRT 原生支持的操作,则无需任何额外的标志即可转换该模型。建议采用此路径,因为这种类型的模型可以顺利转换,并且使用默认 LiteRT 运行时可以更轻松地优化和运行。您还可以选择更多模型部署选项,例如 Google Play 服务。您可以先参阅 LiteRT 转换器指南。如需查看内置运算符的列表,请参阅 LiteRT Ops 页面。
如果您需要包含核心库中的部分 TensorFlow 操作,则必须在转换时指定这些操作,并确保运行时包含这些操作。如需了解详细步骤,请参阅选择 TensorFlow 运算符主题。
尽可能避免采用最后一种方案,即在转换后的模型中包含自定义运算符。自定义运算符是指通过组合多个原始 TensorFlow 核心运算符创建的运算符,也可以是完全新定义的运算符。转换自定义运算符时,由于会产生内置 LiteRT 库之外的依赖项,因此可能会增加整个模型的大小。如果自定义操作不是专门为移动设备或设备部署创建的,那么与服务器环境相比,在部署到资源受限的设备时,可能会导致性能更差。最后,与包含所选 TensorFlow 核心运算符一样,自定义运算符也需要您修改模型运行时环境,这会限制您利用标准运行时服务(例如 Google Play 服务)。
支持的类型
大多数 LiteRT 操作都以浮点 (float32) 和量化 (uint8、int8) 推理为目标,但许多操作尚未针对 tf.float16 和字符串等其他类型实现。
除了使用不同版本的操作之外,浮点模型和量化模型之间的另一个区别在于它们的转换方式。量化转化需要张量的动态范围信息。这需要在模型训练期间进行“伪量化”,通过校准数据集获取范围信息,或进行“实时”范围估计。如需了解详情,请参阅量化。
直接转换、常量折叠和融合
即使某些 TensorFlow 操作没有直接的等效项,LiteRT 也可以处理这些操作。对于可以简单地从图中移除 (tf.identity)、替换为张量 (tf.placeholder) 或融合为更复杂的操作 (tf.nn.bias_add) 的操作,情况就是如此。即使是某些受支持的操作,有时也可能会通过上述某个过程移除。
以下是通常会从图中移除的 TensorFlow 操作的不完整列表:
tf.addtf.debugging.check_numericstf.constanttf.divtf.dividetf.fake_quant_with_min_max_argstf.fake_quant_with_min_max_varstf.identitytf.maximumtf.minimumtf.multiplytf.no_optf.placeholdertf.placeholder_with_defaulttf.realdivtf.reduce_maxtf.reduce_mintf.reduce_sumtf.rsqrttf.shapetf.sqrttf.squaretf.subtracttf.tiletf.nn.batch_norm_with_global_normalizationtf.nn.bias_addtf.nn.fused_batch_normtf.nn.relutf.nn.relu6
实验性操作
以下 LiteRT 操作存在,但尚未准备好用于自定义模型:
CALLCONCAT_EMBEDDINGSCUSTOMEMBEDDING_LOOKUP_SPARSEHASHTABLE_LOOKUPLSH_PROJECTIONSKIP_GRAMSVDF