
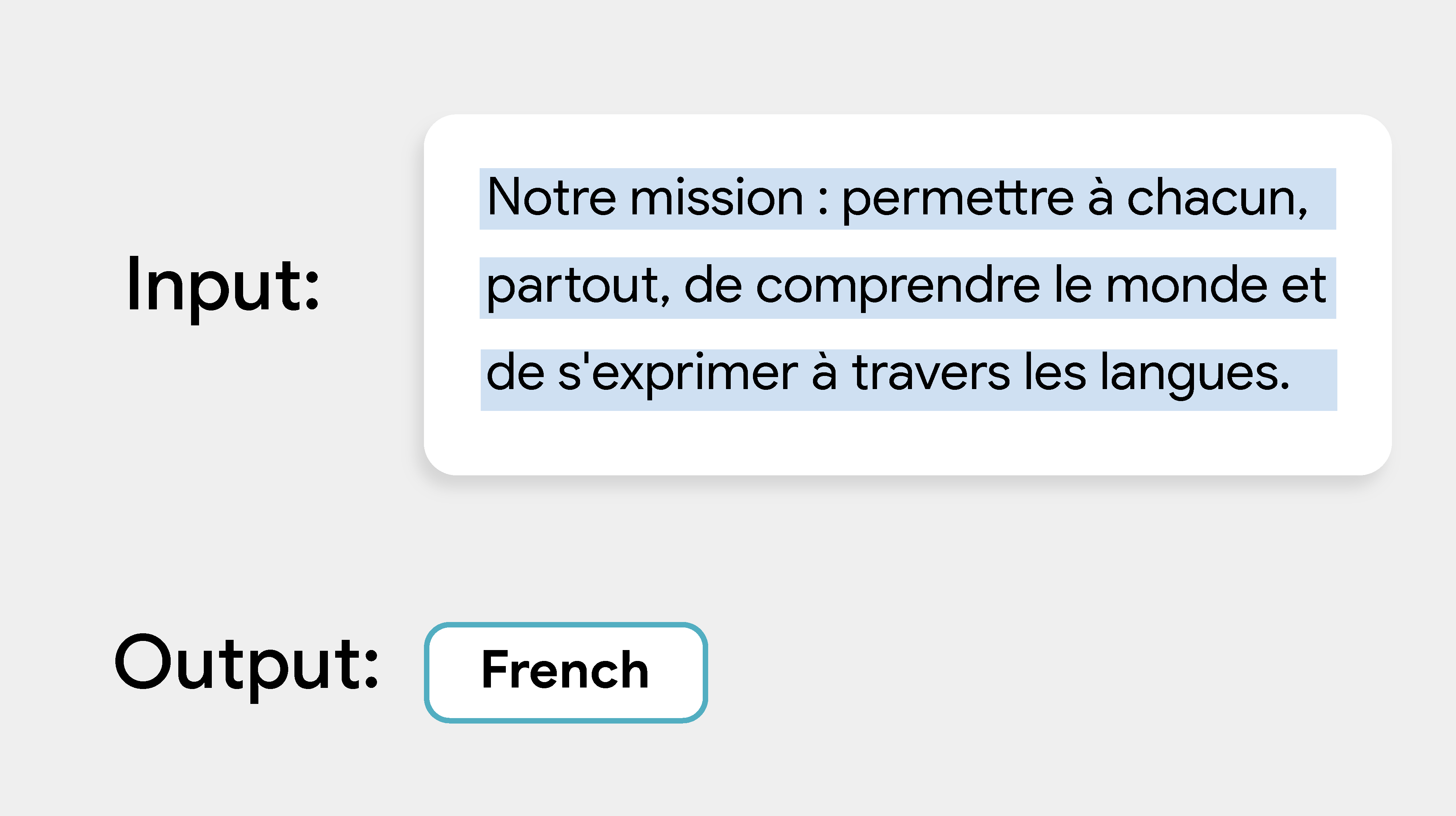
MediaPipe Language Detector टास्क की मदद से, किसी टेक्स्ट की भाषा की पहचान की जा सकती है. यह टास्क, मशीन लर्निंग (एमएल) मॉडल की मदद से टेक्स्ट डेटा पर काम करता है. साथ ही, अनुमान की एक सूची दिखाता है. इसमें हर अनुमान में ISO 639-1 भाषा कोड और संभावना शामिल होती है.
शुरू करें
अपने टारगेट प्लैटफ़ॉर्म के लिए, लागू करने से जुड़ी इनमें से किसी एक गाइड का पालन करके, इस टास्क का इस्तेमाल शुरू करें. प्लैटफ़ॉर्म के हिसाब से बनी इन गाइड में, इस टास्क को लागू करने का बुनियादी तरीका बताया गया है. इनमें सुझाया गया मॉडल और सुझाए गए कॉन्फ़िगरेशन विकल्पों के साथ कोड का उदाहरण भी शामिल है:
- Android - कोड का उदाहरण - गाइड
- Python - कोड का उदाहरण - गाइड
- वेब - कोड का उदाहरण - गाइड
टास्क की जानकारी
इस सेक्शन में, इस टास्क की सुविधाओं, इनपुट, आउटपुट, और कॉन्फ़िगरेशन के विकल्पों के बारे में बताया गया है.
सुविधाएं
- स्कोर थ्रेशोल्ड - अनुमान के स्कोर के आधार पर नतीजे फ़िल्टर करना
- अनुमति वाली सूची और ब्लॉकलिस्ट को लेबल करना - पता लगाई गई कैटगरी की जानकारी दें
| टास्क के इनपुट | टास्क के आउटपुट |
|---|---|
भाषा का पता लगाने वाली सुविधा, इनपुट डेटा के इस टाइप को स्वीकार करती है:
|
भाषा का पता लगाने वाला टूल, अनुमान की एक सूची दिखाता है. इसमें ये शामिल हैं:
|
कॉन्फ़िगरेशन के विकल्प
इस टास्क के लिए, कॉन्फ़िगरेशन के ये विकल्प उपलब्ध हैं:
| विकल्प का नाम | ब्यौरा | वैल्यू की रेंज | डिफ़ॉल्ट मान |
|---|---|---|---|
max_results |
सबसे ज़्यादा स्कोर वाली भाषा के अनुमान की ज़्यादा से ज़्यादा संख्या सेट करता है. हालांकि, ऐसा करना ज़रूरी नहीं है. अगर यह वैल्यू शून्य से कम है, तो सभी उपलब्ध नतीजे दिखाए जाते हैं. | कोई भी पॉज़िटिव संख्या | -1 |
score_threshold |
अनुमान के स्कोर का थ्रेशोल्ड सेट करता है. यह थ्रेशोल्ड, मॉडल के मेटाडेटा में दिए गए थ्रेशोल्ड (अगर कोई है) को बदल देता है. इस वैल्यू से कम के नतीजे अस्वीकार कर दिए जाते हैं. | कोई भी फ़्लोट | सेट नहीं है |
category_allowlist |
इस्तेमाल की अनुमति वाली भाषाओं के कोड की वैकल्पिक सूची सेट करता है. अगर यह सेट नहीं है, तो भाषा के उन अनुमान को फ़िल्टर कर दिया जाएगा जिनका भाषा कोड इस सेट में नहीं है. यह विकल्प, category_denylist के साथ इस्तेमाल नहीं किया जा सकता. दोनों का इस्तेमाल करने पर गड़बड़ी का मैसेज दिखता है. |
कोई भी स्ट्रिंग | सेट नहीं है |
category_denylist |
भाषा कोड की ऐसी वैकल्पिक सूची सेट करता है जिनकी अनुमति नहीं है. अगर यह सेट नहीं है, तो भाषा के जिन अनुमानों का भाषा कोड इस सेट में है उन्हें फ़िल्टर कर दिया जाएगा. यह विकल्प, category_allowlist के साथ काम नहीं करता. साथ ही, दोनों का इस्तेमाल करने पर गड़बड़ी होती है. |
कोई भी स्ट्रिंग | सेट नहीं है |
मॉडल
इस टास्क के साथ डेवलपमेंट शुरू करने पर, हम डिफ़ॉल्ट रूप से सुझाया गया मॉडल उपलब्ध कराते हैं.
भाषा का पता लगाने वाला मॉडल (सुझाया गया)
यह मॉडल, लाइटवेट (315 केबी) बनाने के लिए बनाया गया है. साथ ही, यह एम्बेडिंग पर आधारित, नेटवर्क क्लासिफ़िकेशन आर्किटेक्चर का इस्तेमाल करता है. यह मॉडल, ISO 639-1 भाषा कोड का इस्तेमाल करके भाषा की पहचान करता है. साथ ही, यह 110 भाषाओं की पहचान कर सकता है. इस मॉडल के साथ काम करने वाली भाषाओं की सूची के लिए, लेबल फ़ाइल देखें. इसमें भाषाओं को उनके आईएसओ 639-1 कोड के हिसाब से दिखाया जाता है.
| मॉडल का नाम | इनपुट का आकार | क्वांटाइज़ेशन का टाइप | मॉडल कार्ड | वर्शन |
|---|---|---|---|---|
| Language Detector | स्ट्रिंग UTF-8 | कोई नहीं (float32) | info | हाल ही के अपडेट |
टास्क के मानदंड
यहां पूरी पाइपलाइन के लिए टास्क के मानदंड दिए गए हैं. ये मानदंड, ऊपर दिए गए पहले से ट्रेन किए गए मॉडल पर आधारित हैं. इंतज़ार का समय, सीपीयू / जीपीयू का इस्तेमाल करके Pixel 6 पर औसत इंतज़ार का समय होता है.
| मॉडल का नाम | सीपीयू के इंतज़ार का समय | जीपीयू में इंतज़ार का समय |
|---|---|---|
| भाषा की पहचान करने की सुविधा | 0.31 मिलीसेकंड | - |