
Mit der MediaPipe-Aufgabe „Gestenerkennung“ können Sie Handbewegungen in Echtzeit erkennen. Außerdem werden die erkannten Handbewegungsergebnisse und die Handmarkierungen der erkannten Hände bereitgestellt. In dieser Anleitung erfahren Sie, wie Sie den Gestenerkennungsdienst mit Android-Apps verwenden. Der in dieser Anleitung beschriebene Code ist auf GitHub verfügbar.
In der Web-Demo können Sie sich diese Aufgabe in Aktion ansehen. Weitere Informationen zu den Funktionen, Modellen und Konfigurationsoptionen dieser Aufgabe finden Sie in der Übersicht.
Codebeispiel
Der Beispielcode für MediaPipe Tasks ist eine einfache Implementierung einer Gestenerkennungs-App für Android. Im Beispiel wird die Kamera eines Android-Geräts verwendet, um Handgesten kontinuierlich zu erkennen. Außerdem können Bilder und Videos aus der Gerätegalerie verwendet werden, um Gesten statisch zu erkennen.
Sie können die App als Ausgangspunkt für Ihre eigene Android-App verwenden oder sich an ihr orientieren, wenn Sie eine vorhandene App ändern. Der Beispielcode für die Gestenererkennung wird auf GitHub gehostet.
Code herunterladen
In der folgenden Anleitung wird beschrieben, wie Sie mit dem Befehlszeilentool git eine lokale Kopie des Beispielcodes erstellen.
So laden Sie den Beispielcode herunter:
- Klonen Sie das Git-Repository mit dem folgenden Befehl:
git clone https://github.com/google-ai-edge/mediapipe-samples
- Optional können Sie Ihre Git-Instanz so konfigurieren, dass eine spärliche Überprüfung verwendet wird, sodass nur die Dateien für die Beispiel-App „Gesture Recognizer“ vorhanden sind:
cd mediapipe-samples git sparse-checkout init --cone git sparse-checkout set examples/gesture_recognizer/android
Nachdem Sie eine lokale Version des Beispielcodes erstellt haben, können Sie das Projekt in Android Studio importieren und die App ausführen. Eine Anleitung dazu finden Sie im Einrichtungsleitfaden für Android.
Schlüsselkomponenten
Die folgenden Dateien enthalten den wichtigsten Code für diese Beispielanwendung zur Erkennung von Handzeichen:
- GestureRecognizerHelper.kt: Initialisiert die Gestenentfernung und kümmert sich um das Modell und die Auswahl des Delegaten.
- MainActivity.kt: Implementiert die Anwendung, einschließlich des Aufrufs von
GestureRecognizerHelperundGestureRecognizerResultsAdapter. - GestureRecognizerResultsAdapter.kt: Verarbeitet und formatiert die Ergebnisse.
Einrichtung
In diesem Abschnitt werden die wichtigsten Schritte zur Einrichtung Ihrer Entwicklungsumgebung und zur Programmierung von Projekten beschrieben, die speziell für die Verwendung des Gestener erkennters entwickelt wurden. Allgemeine Informationen zum Einrichten Ihrer Entwicklungsumgebung für die Verwendung von MediaPipe-Aufgaben, einschließlich Anforderungen an die Plattformversion, finden Sie im Einrichtungsleitfaden für Android.
Abhängigkeiten
Für die Aufgabe „Gestenerkennung“ wird die com.google.mediapipe:tasks-vision-Bibliothek verwendet. Fügen Sie der Datei build.gradle Ihrer Android-App diese Abhängigkeit hinzu:
dependencies {
implementation 'com.google.mediapipe:tasks-vision:latest.release'
}
Modell
Für die MediaPipe-Gestenerkennung ist ein trainiertes Modellpaket erforderlich, das mit dieser Aufgabe kompatibel ist. Weitere Informationen zu verfügbaren trainierten Modellen für den Gestenerkennungsdienst finden Sie in der Aufgabenübersicht im Abschnitt „Modelle“.
Wählen Sie das Modell aus, laden Sie es herunter und speichern Sie es im Projektverzeichnis:
<dev-project-root>/src/main/assets
Geben Sie den Pfad des Modells im Parameter ModelAssetPath an. Im Beispielcode wird das Modell in der Datei GestureRecognizerHelper.kt definiert:
baseOptionBuilder.setModelAssetPath(MP_RECOGNIZER_TASK)
Aufgabe erstellen
Bei der MediaPipe-Gestenerkennungsaufgabe wird die Funktion createFromOptions() verwendet, um die Aufgabe einzurichten. Die Funktion createFromOptions() akzeptiert Werte für die Konfigurationsoptionen. Weitere Informationen zu Konfigurationsoptionen finden Sie unter Konfigurationsoptionen.
Der Gestenerkennungsdienst unterstützt drei Eingabedatentypen: Standbilder, Videodateien und Live-Videostreams. Sie müssen beim Erstellen der Aufgabe den Ausführungsmodus angeben, der dem Datentyp der Eingabe entspricht. Wählen Sie den Tab für den Datentyp Ihrer Eingabedaten aus, um zu erfahren, wie Sie die Aufgabe erstellen und die Inferenz ausführen.
Bild
val baseOptionsBuilder = BaseOptions.builder().setModelAssetPath(MP_RECOGNIZER_TASK)
val baseOptions = baseOptionBuilder.build()
val optionsBuilder =
GestureRecognizer.GestureRecognizerOptions.builder()
.setBaseOptions(baseOptions)
.setMinHandDetectionConfidence(minHandDetectionConfidence)
.setMinTrackingConfidence(minHandTrackingConfidence)
.setMinHandPresenceConfidence(minHandPresenceConfidence)
.setRunningMode(RunningMode.IMAGE)
val options = optionsBuilder.build()
gestureRecognizer =
GestureRecognizer.createFromOptions(context, options)
Video
val baseOptionsBuilder = BaseOptions.builder().setModelAssetPath(MP_RECOGNIZER_TASK)
val baseOptions = baseOptionBuilder.build()
val optionsBuilder =
GestureRecognizer.GestureRecognizerOptions.builder()
.setBaseOptions(baseOptions)
.setMinHandDetectionConfidence(minHandDetectionConfidence)
.setMinTrackingConfidence(minHandTrackingConfidence)
.setMinHandPresenceConfidence(minHandPresenceConfidence)
.setRunningMode(RunningMode.VIDEO)
val options = optionsBuilder.build()
gestureRecognizer =
GestureRecognizer.createFromOptions(context, options)
Livestream
val baseOptionsBuilder = BaseOptions.builder().setModelAssetPath(MP_RECOGNIZER_TASK)
val baseOptions = baseOptionBuilder.build()
val optionsBuilder =
GestureRecognizer.GestureRecognizerOptions.builder()
.setBaseOptions(baseOptions)
.setMinHandDetectionConfidence(minHandDetectionConfidence)
.setMinTrackingConfidence(minHandTrackingConfidence)
.setMinHandPresenceConfidence(minHandPresenceConfidence)
.setResultListener(this::returnLivestreamResult)
.setErrorListener(this::returnLivestreamError)
.setRunningMode(RunningMode.LIVE_STREAM)
val options = optionsBuilder.build()
gestureRecognizer =
GestureRecognizer.createFromOptions(context, options)
Mit der Beispielcodeimplementierung für den Gestenerkennungsdienst kann der Nutzer zwischen Verarbeitungsmodi wechseln. Dieser Ansatz macht den Code zum Erstellen von Aufgaben komplizierter und ist möglicherweise nicht für Ihren Anwendungsfall geeignet. Sie finden diesen Code in der Funktion setupGestureRecognizer() in der Datei GestureRecognizerHelper.kt.
Konfigurationsoptionen
Für diese Aufgabe sind die folgenden Konfigurationsoptionen für Android-Apps verfügbar:
| Option | Beschreibung | Wertebereich | Standardwert | |
|---|---|---|---|---|
runningMode |
Legt den Ausführungsmodus für die Aufgabe fest. Es gibt drei Modi: IMAGE: Der Modus für Eingaben mit einem einzelnen Bild. VIDEO: Der Modus für decodierte Frames eines Videos. LIVE_STREAM: Der Modus für einen Livestream von Eingabedaten, z. B. von einer Kamera. In diesem Modus muss resultListener aufgerufen werden, um einen Listener für den asynchronen Empfang von Ergebnissen einzurichten. |
{IMAGE, VIDEO, LIVE_STREAM} |
IMAGE |
|
numHands |
Die maximale Anzahl von Händen, die vom GestureRecognizer erkannt werden kann.
|
Any integer > 0 |
1 |
|
minHandDetectionConfidence |
Die Mindestpunktzahl für die Handerkennung, die im Modell für die Handflächenerkennung als erfolgreich gilt. | 0.0 - 1.0 |
0.5 |
|
minHandPresenceConfidence |
Der Mindestwert der Konfidenz der Anwesenheit der Hand im Modell zur Erkennung von Handmarkierungen. Wenn der Konfidenzwert für die Präsenz einer Hand aus dem Modell für Handmarkierungen im Video- und Livestream-Modus der Gestenerkennung unter diesem Schwellenwert liegt, wird das Modell zur Handflächenerkennung ausgelöst. Andernfalls wird ein einfacher Algorithmus für die Handerkennung verwendet, um die Position der Hand(en) für die anschließende Landmark-Erkennung zu bestimmen. | 0.0 - 1.0 |
0.5 |
|
minTrackingConfidence |
Der Mindestwert für die Zuverlässigkeitsbewertung, damit die Handerkennung als erfolgreich gilt. Dies ist der IoU-Grenzwert des Begrenzungsrahmens zwischen den Händen im aktuellen und im letzten Frame. Wenn die Erkennung im Video- und Streammodus der Gestenererkennung fehlschlägt, löst die Gestenererkennung die Handerkennung aus. Andernfalls wird die Handerkennung übersprungen. | 0.0 - 1.0 |
0.5 |
|
cannedGesturesClassifierOptions |
Optionen zum Konfigurieren des Klassifikators für vordefinierte Gesten. Die vordefinierten Touch-Gesten sind ["None", "Closed_Fist", "Open_Palm", "Pointing_Up", "Thumb_Down", "Thumb_Up", "Victory", "ILoveYou"]. |
|
|
|
customGesturesClassifierOptions |
Optionen zum Konfigurieren des Verhaltens des Klassifikators für benutzerdefinierte Touch-Gesten. |
|
|
|
resultListener |
Legt fest, dass der Ergebnisempfänger die Klassifizierungsergebnisse asynchron empfängt, wenn sich die Gesterkenner im Livestream-Modus befindet.
Kann nur verwendet werden, wenn der Ausführungsmodus auf LIVE_STREAM festgelegt ist. |
ResultListener |
– | – |
errorListener |
Legt einen optionalen Fehler-Listener fest. | ErrorListener |
– | – |
Daten vorbereiten
Der Gestenerkennungsdienst funktioniert mit Bildern, Videodateien und Livestreams. Die Aufgabe übernimmt die Vorverarbeitung der Dateneingabe, einschließlich Größenänderung, Drehung und Wertnormalisierung.
Im folgenden Code wird gezeigt, wie Daten zur Verarbeitung übergeben werden. Diese Beispiele enthalten Details zum Umgang mit Daten aus Bildern, Videodateien und Livestreams.
Bild
import com.google.mediapipe.framework.image.BitmapImageBuilder import com.google.mediapipe.framework.image.MPImage // Convert the input Bitmap object to an MPImage object to run inference val mpImage = BitmapImageBuilder(image).build()
Video
import com.google.mediapipe.framework.image.BitmapImageBuilder import com.google.mediapipe.framework.image.MPImage val argb8888Frame = if (frame.config == Bitmap.Config.ARGB_8888) frame else frame.copy(Bitmap.Config.ARGB_8888, false) // Convert the input Bitmap object to an MPImage object to run inference val mpImage = BitmapImageBuilder(argb8888Frame).build()
Livestream
import com.google.mediapipe.framework.image.BitmapImageBuilder import com.google.mediapipe.framework.image.MPImage // Convert the input Bitmap object to an MPImage object to run inference val mpImage = BitmapImageBuilder(rotatedBitmap).build()
Im Beispielcode für die Gestenererkennung wird die Datenvorbereitung in der Datei GestureRecognizerHelper.kt ausgeführt.
Aufgabe ausführen
Der Gestenerkennungsdienst verwendet die Funktionen recognize, recognizeForVideo und recognizeAsync, um Inferenzen auszulösen. Bei der Gestenerkennung umfasst dies die Vorverarbeitung der Eingabedaten, die Erkennung von Händen im Bild, die Erkennung von Handmarkierungen und die Erkennung der Geste anhand der Markierungen.
Im folgenden Code wird gezeigt, wie die Verarbeitung mit dem Aufgabenmodell ausgeführt wird. Diese Beispiele enthalten Details zum Umgang mit Daten aus Bildern, Videodateien und Live-Videostreams.
Bild
val result = gestureRecognizer?.recognize(mpImage)
Video
val timestampMs = i * inferenceIntervalMs gestureRecognizer?.recognizeForVideo(mpImage, timestampMs) ?.let { recognizerResult -> resultList.add(recognizerResult) }
Livestream
val mpImage = BitmapImageBuilder(rotatedBitmap).build()
val frameTime = SystemClock.uptimeMillis()
gestureRecognizer?.recognizeAsync(mpImage, frameTime)
Wichtige Hinweise:
- Wenn Sie die Erkennung im Video- oder Livestream-Modus ausführen, müssen Sie der Gesterkenner-Aufgabe auch den Zeitstempel des Eingabeframes angeben.
- Wenn die Ausführung im Bild- oder Videomodus erfolgt, blockiert die Gestenererkennungsaufgabe den aktuellen Thread, bis die Verarbeitung des Eingabebilds oder ‑frames abgeschlossen ist. Führen Sie die Verarbeitung in einem Hintergrund-Thread aus, um die Benutzeroberfläche nicht zu blockieren.
- Wenn die Ausführung im Livestream-Modus erfolgt, blockiert die Aufgabe „Gestenerkennung“ den aktuellen Thread nicht, sondern gibt sofort eine Rückgabe zurück. Sie ruft den Ergebnis-Listener mit dem Erkennungsergebnis jedes Mal auf, wenn die Verarbeitung eines Eingabeframes abgeschlossen ist. Wenn die Erkennungsfunktion aufgerufen wird, während die Gestenerkennungsaufgabe gerade einen anderen Frame verarbeitet, wird der neue Eingabeframe ignoriert.
Im Beispielcode für die Gestenererkennung sind die Funktionen recognize, recognizeForVideo und recognizeAsync in der Datei GestureRecognizerHelper.kt definiert.
Ergebnisse verarbeiten und anzeigen
Der Gestenerkennungsalgorithmus generiert für jeden Erkennungslauf ein Ergebnisobjekt für die Gestenererkennung. Das Ergebnisobjekt enthält Handmarkierungen in Bildkoordinaten, Handmarkierungen in Weltkoordinaten, die Handdominanz(linke/rechte Hand) und die Kategorien der erkannten Handgesten.
Im Folgenden finden Sie ein Beispiel für die Ausgabedaten dieser Aufgabe:
Die resultierende GestureRecognizerResult enthält vier Komponenten. Jede Komponente ist ein Array, in dem jedes Element das erkannte Ergebnis einer einzelnen erkannten Hand enthält.
Links-/Rechtshänder
„Handedness“ gibt an, ob die erkannten Hände links- oder rechtshändig sind.
Touch-Gesten
Die erkannten Gestekategorien der erkannten Hände.
Landmarken
Es gibt 21 Landmarken für die Hand, die jeweils aus
x-,y- undz-Koordinaten bestehen. Die Koordinatenxundywerden durch die Bildbreite bzw. -höhe auf [0, 0; 1, 0] normalisiert. Diez-Koordinate steht für die Markierungstiefe. Die Tiefe am Handgelenk ist der Ursprung. Je kleiner der Wert, desto näher ist das Wahrzeichen an der Kamera. Die Größe vonzwird ungefähr auf derselben Skala wiexdargestellt.Sehenswürdigkeiten der Welt
Die 21 Landmarken für die Hand werden ebenfalls in Weltkoordinaten dargestellt. Jedes Landmark besteht aus
x,yundz, die 3D-Koordinaten in Metern mit dem Ursprung im geometrischen Mittelpunkt der Hand darstellen.
GestureRecognizerResult:
Handedness:
Categories #0:
index : 0
score : 0.98396
categoryName : Left
Gestures:
Categories #0:
score : 0.76893
categoryName : Thumb_Up
Landmarks:
Landmark #0:
x : 0.638852
y : 0.671197
z : -3.41E-7
Landmark #1:
x : 0.634599
y : 0.536441
z : -0.06984
... (21 landmarks for a hand)
WorldLandmarks:
Landmark #0:
x : 0.067485
y : 0.031084
z : 0.055223
Landmark #1:
x : 0.063209
y : -0.00382
z : 0.020920
... (21 world landmarks for a hand)
Die folgenden Bilder zeigen eine Visualisierung der Aufgabenausgabe:
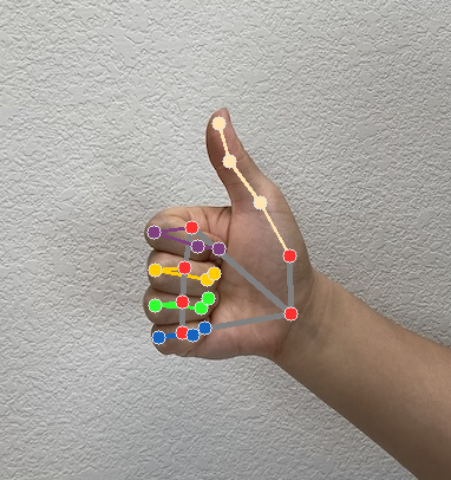
Im Beispielcode für die Gestenererkennung verarbeitet die Klasse GestureRecognizerResultsAdapter in der Datei GestureRecognizerResultsAdapter.kt die Ergebnisse.