
Mit der Aufgabe „MediaPipe-Gestenerkennung“ können Sie Handbewegungen in Echtzeit erkennen. Außerdem werden die erkannten Handbewegungsergebnisse und die Handmarkierungen der erkannten Hände bereitgestellt. In dieser Anleitung erfahren Sie, wie Sie den Gestenerkennungsdienst mit Python-Anwendungen verwenden.
In der Webdemo können Sie sich diese Aufgabe in Aktion ansehen. Weitere Informationen zu den Funktionen, Modellen und Konfigurationsoptionen dieser Aufgabe finden Sie in der Übersicht.
Codebeispiel
Der Beispielcode für den Gestenerkennungsdienst bietet eine vollständige Implementierung dieser Aufgabe in Python. Mit diesem Code können Sie diese Aufgabe testen und mit dem Erstellen Ihrer eigenen Gestenerkennung beginnen. Sie können den Beispielcode für die Gestenererkennung mit nur Ihrem Webbrowser aufrufen, ausführen und bearbeiten.
Wenn Sie den Gestenerkennungsalgorithmus für Raspberry Pi implementieren, lesen Sie den Artikel zur Beispiel-App für Raspberry Pi.
Einrichtung
In diesem Abschnitt werden die wichtigsten Schritte zur Einrichtung Ihrer Entwicklungsumgebung und zur Programmierung von Projekten beschrieben, die speziell für die Verwendung des Gestener erkennters entwickelt wurden. Allgemeine Informationen zum Einrichten Ihrer Entwicklungsumgebung für die Verwendung von MediaPipe-Aufgaben, einschließlich Anforderungen an die Plattformversion, finden Sie im Einrichtungsleitfaden für Python.
Pakete
Für die Aufgabe „MediaPipe-Gestenerkennung“ ist das PyPI-Paket „mediapipe“ erforderlich. Sie können diese Abhängigkeiten mit den folgenden Befehlen installieren und importieren:
$ python -m pip install mediapipe
Importe
Importieren Sie die folgenden Klassen, um auf die Aufgabenfunktionen der Gestenererkennung zuzugreifen:
import mediapipe as mp
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
Modell
Für die MediaPipe-Gestenerkennung ist ein trainiertes Modellpaket erforderlich, das mit dieser Aufgabe kompatibel ist. Weitere Informationen zu verfügbaren trainierten Modellen für den Gestenerkennungsdienst finden Sie in der Aufgabenübersicht im Abschnitt „Modelle“.
Wählen Sie das Modell aus, laden Sie es herunter und speichern Sie es in einem lokalen Verzeichnis:
model_path = '/absolute/path/to/gesture_recognizer.task'
Geben Sie den Pfad des Modells im Parameter „Modellname“ an, wie unten dargestellt:
base_options = BaseOptions(model_asset_path=model_path)
Aufgabe erstellen
Bei der MediaPipe-Gestenerkennungsaufgabe wird die Funktion create_from_options verwendet, um die Aufgabe einzurichten. Die Funktion create_from_options akzeptiert Werte für zu verarbeitende Konfigurationsoptionen. Weitere Informationen zu Konfigurationsoptionen finden Sie unter Konfigurationsoptionen.
Im folgenden Code wird gezeigt, wie diese Aufgabe erstellt und konfiguriert wird.
Diese Beispiele zeigen auch die verschiedenen Möglichkeiten zur Aufgabenerstellung für Bilder, Videodateien und Live-Videostreams.
Bild
import mediapipe as mp BaseOptions = mp.tasks.BaseOptions GestureRecognizer = mp.tasks.vision.GestureRecognizer GestureRecognizerOptions = mp.tasks.vision.GestureRecognizerOptions VisionRunningMode = mp.tasks.vision.RunningMode # Create a gesture recognizer instance with the image mode: options = GestureRecognizerOptions( base_options=BaseOptions(model_asset_path='/path/to/model.task'), running_mode=VisionRunningMode.IMAGE) with GestureRecognizer.create_from_options(options) as recognizer: # The detector is initialized. Use it here. # ...
Video
import mediapipe as mp BaseOptions = mp.tasks.BaseOptions GestureRecognizer = mp.tasks.vision.GestureRecognizer GestureRecognizerOptions = mp.tasks.vision.GestureRecognizerOptions VisionRunningMode = mp.tasks.vision.RunningMode # Create a gesture recognizer instance with the video mode: options = GestureRecognizerOptions( base_options=BaseOptions(model_asset_path='/path/to/model.task'), running_mode=VisionRunningMode.VIDEO) with GestureRecognizer.create_from_options(options) as recognizer: # The detector is initialized. Use it here. # ...
Livestream
import mediapipe as mp BaseOptions = mp.tasks.BaseOptions GestureRecognizer = mp.tasks.vision.GestureRecognizer GestureRecognizerOptions = mp.tasks.vision.GestureRecognizerOptions GestureRecognizerResult = mp.tasks.vision.GestureRecognizerResult VisionRunningMode = mp.tasks.vision.RunningMode # Create a gesture recognizer instance with the live stream mode: def print_result(result: GestureRecognizerResult, output_image: mp.Image, timestamp_ms: int): print('gesture recognition result: {}'.format(result)) options = GestureRecognizerOptions( base_options=BaseOptions(model_asset_path='/path/to/model.task'), running_mode=VisionRunningMode.LIVE_STREAM, result_callback=print_result) with GestureRecognizer.create_from_options(options) as recognizer: # The detector is initialized. Use it here. # ...
Konfigurationsoptionen
Für diese Aufgabe gibt es die folgenden Konfigurationsoptionen für Python-Anwendungen:
| Option | Beschreibung | Wertebereich | Standardwert | |
|---|---|---|---|---|
running_mode |
Legt den Ausführungsmodus für die Aufgabe fest. Es gibt drei Modi: IMAGE: Der Modus für Eingaben mit einem einzelnen Bild. VIDEO: Der Modus für decodierte Frames eines Videos. LIVE_STREAM: Der Modus für einen Livestream von Eingabedaten, z. B. von einer Kamera. In diesem Modus muss resultListener aufgerufen werden, um einen Listener für den asynchronen Empfang von Ergebnissen einzurichten. |
{IMAGE, VIDEO, LIVE_STREAM} |
IMAGE |
|
num_hands |
Die maximale Anzahl von Händen, die vom GestureRecognizer erkannt werden kann.
|
Any integer > 0 |
1 |
|
min_hand_detection_confidence |
Die Mindestpunktzahl für die Handerkennung, die im Modell für die Handflächenerkennung als erfolgreich gilt. | 0.0 - 1.0 |
0.5 |
|
min_hand_presence_confidence |
Der Mindestwert der Konfidenz der Handpräsenz im Modell zur Erkennung von Handmarkierungen. Wenn der Konfidenzwert für die Präsenz einer Hand aus dem Modell für Handmarkierungen im Video- und Livestream-Modus der Gestenerkennung unter diesem Schwellenwert liegt, wird das Modell zur Handflächenerkennung ausgelöst. Andernfalls wird ein einfacher Algorithmus zur Handerkennung verwendet, um die Position der Hand(en) für die anschließende Markierungserkennung zu bestimmen. | 0.0 - 1.0 |
0.5 |
|
min_tracking_confidence |
Der Mindestwert für die Konfidenz, damit die Handerkennung als erfolgreich gilt. Dies ist der IoU-Grenzwert des Begrenzungsrahmens zwischen den Händen im aktuellen und im letzten Frame. Wenn die Erkennung im Video- und Streammodus der Gestenererkennung fehlschlägt, löst die Gestenererkennung die Handerkennung aus. Andernfalls wird die Handerkennung übersprungen. | 0.0 - 1.0 |
0.5 |
|
canned_gestures_classifier_options |
Optionen zum Konfigurieren des Klassifikators für vordefinierte Gesten. Die vordefinierten Touch-Gesten sind ["None", "Closed_Fist", "Open_Palm", "Pointing_Up", "Thumb_Down", "Thumb_Up", "Victory", "ILoveYou"]. |
|
|
|
custom_gestures_classifier_options |
Optionen zum Konfigurieren des Verhaltens des Klassifikators für benutzerdefinierte Touch-Gesten. |
|
|
|
result_callback |
Legt fest, dass der Ergebnisempfänger die Klassifizierungsergebnisse asynchron empfängt, wenn sich die Gesterkenner im Livestream-Modus befindet.
Kann nur verwendet werden, wenn der Ausführungsmodus auf LIVE_STREAM festgelegt ist. |
ResultListener |
– | – |
Daten vorbereiten
Bereiten Sie die Eingabe als Bilddatei oder als Numpy-Array vor und wandeln Sie sie dann in ein mediapipe.Image-Objekt um. Wenn Ihre Eingabe eine Videodatei oder ein Livestream von einer Webcam ist, können Sie eine externe Bibliothek wie OpenCV verwenden, um die Eingabeframes als Numpy-Arrays zu laden.
Bild
import mediapipe as mp # Load the input image from an image file. mp_image = mp.Image.create_from_file('/path/to/image') # Load the input image from a numpy array. mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=numpy_image)
Video
import mediapipe as mp # Use OpenCV’s VideoCapture to load the input video. # Load the frame rate of the video using OpenCV’s CV_CAP_PROP_FPS # You’ll need it to calculate the timestamp for each frame. # Loop through each frame in the video using VideoCapture#read() # Convert the frame received from OpenCV to a MediaPipe’s Image object. mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=numpy_frame_from_opencv)
Livestream
import mediapipe as mp # Use OpenCV’s VideoCapture to start capturing from the webcam. # Create a loop to read the latest frame from the camera using VideoCapture#read() # Convert the frame received from OpenCV to a MediaPipe’s Image object. mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=numpy_frame_from_opencv)
Aufgabe ausführen
Der Gesten-Recognizer verwendet die Funktionen „recognize“, „recognize_for_video“ und „recognize_async“, um Inferenzen auszulösen. Bei der Gestenerkennung umfasst dies die Vorverarbeitung der Eingabedaten, die Erkennung von Händen im Bild, die Erkennung von Handmarkierungen und die Erkennung der Geste anhand der Markierungen.
Im folgenden Code wird gezeigt, wie die Verarbeitung mit dem Aufgabenmodell ausgeführt wird.
Bild
# Perform gesture recognition on the provided single image. # The gesture recognizer must be created with the image mode. gesture_recognition_result = recognizer.recognize(mp_image)
Video
# Perform gesture recognition on the provided single image. # The gesture recognizer must be created with the video mode. gesture_recognition_result = recognizer.recognize_for_video(mp_image, frame_timestamp_ms)
Livestream
# Send live image data to perform gesture recognition. # The results are accessible via the `result_callback` provided in # the `GestureRecognizerOptions` object. # The gesture recognizer must be created with the live stream mode. recognizer.recognize_async(mp_image, frame_timestamp_ms)
Wichtige Hinweise:
- Wenn Sie die Erkennung im Video- oder Livestream-Modus ausführen, müssen Sie der Gesterkenner-Aufgabe auch den Zeitstempel des Eingabeframes angeben.
- Wenn die Ausführung im Bild- oder Videomodell erfolgt, blockiert die Gesterkennerungsaufgabe den aktuellen Thread, bis die Verarbeitung des Eingabebilds oder ‑frames abgeschlossen ist.
- Wenn die Ausführung im Livestream-Modus erfolgt, blockiert die Aufgabe „Gestenerkennung“ den aktuellen Thread nicht, sondern gibt sofort eine Rückgabe zurück. Sie ruft den Ergebnis-Listener mit dem Erkennungsergebnis jedes Mal auf, wenn die Verarbeitung eines Eingabeframes abgeschlossen ist. Wenn die Erkennungsfunktion aufgerufen wird, während die Gestenerkennungsaufgabe gerade einen anderen Frame verarbeitet, wird der neue Eingabeframe ignoriert.
Ein vollständiges Beispiel für die Ausführung eines Gestenerkennungsmoduls auf einem Bild finden Sie im Codebeispiel.
Ergebnisse verarbeiten und anzeigen
Der Gestenerkennungsalgorithmus generiert für jeden Erkennungslauf ein Ergebnisobjekt für die Gestenererkennung. Das Ergebnisobjekt enthält Handmarkierungen in Bildkoordinaten, Handmarkierungen in Weltkoordinaten, die Handdominanz(linke/rechte Hand) und die Kategorien der erkannten Handgesten.
Im Folgenden finden Sie ein Beispiel für die Ausgabedaten dieser Aufgabe:
Die resultierende GestureRecognizerResult enthält vier Komponenten. Jede Komponente ist ein Array, dessen jedes Element das erkannte Ergebnis einer einzelnen erkannten Hand enthält.
Links-/Rechtshänder
„Handedness“ gibt an, ob die erkannten Hände links- oder rechtshändig sind.
Touch-Gesten
Die erkannten Gestekategorien der erkannten Hände.
Landmarken
Es gibt 21 Landmarken für die Hand, die jeweils aus
x-,y- undz-Koordinaten bestehen. Die Koordinatenxundywerden durch die Bildbreite bzw. -höhe auf [0, 0; 1, 0] normalisiert. Diez-Koordinate steht für die Markierungstiefe. Die Tiefe am Handgelenk ist der Ursprung. Je kleiner der Wert, desto näher ist das Wahrzeichen an der Kamera. Die Größe vonzwird ungefähr auf derselben Skala wiexdargestellt.Sehenswürdigkeiten der Welt
Die 21 Landmarken für die Hand werden ebenfalls in Weltkoordinaten dargestellt. Jedes Landmark besteht aus
x,yundz, die 3D-Koordinaten in Metern mit dem Ursprung im geometrischen Mittelpunkt der Hand darstellen.
GestureRecognizerResult:
Handedness:
Categories #0:
index : 0
score : 0.98396
categoryName : Left
Gestures:
Categories #0:
score : 0.76893
categoryName : Thumb_Up
Landmarks:
Landmark #0:
x : 0.638852
y : 0.671197
z : -3.41E-7
Landmark #1:
x : 0.634599
y : 0.536441
z : -0.06984
... (21 landmarks for a hand)
WorldLandmarks:
Landmark #0:
x : 0.067485
y : 0.031084
z : 0.055223
Landmark #1:
x : 0.063209
y : -0.00382
z : 0.020920
... (21 world landmarks for a hand)
Die folgenden Bilder zeigen eine Visualisierung der Aufgabenausgabe:
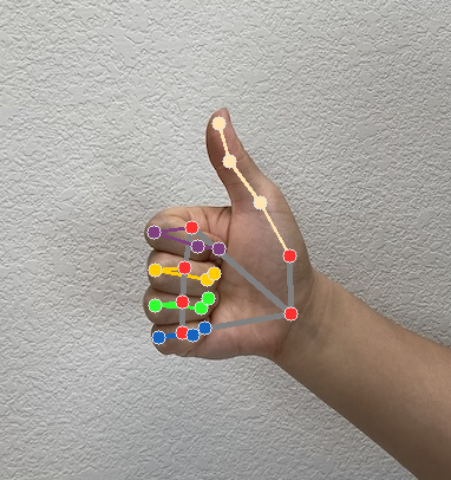
Im Beispielcode für die Gestenererkennung wird gezeigt, wie die vom Task zurückgegebenen Erkennungsergebnisse angezeigt werden. Weitere Informationen finden Sie im Codebeispiel.