
MediaPipe Gesture Recognizer टास्क की मदद से, हाथ के जेस्चर को रीयल टाइम में पहचाना जा सकता है. साथ ही, पहचाने गए हाथ के जेस्चर के नतीजे और पहचाने गए हाथों के लैंडमार्क मिलते हैं. इन निर्देशों में, वेब और JavaScript ऐप्लिकेशन के लिए, जेस्चर पहचानने की सुविधा का इस्तेमाल करने का तरीका बताया गया है.
इस टास्क को काम करते हुए देखने के लिए, डेमो देखें. इस टास्क की सुविधाओं, मॉडल, और कॉन्फ़िगरेशन के विकल्पों के बारे में ज़्यादा जानने के लिए, खास जानकारी देखें.
कोड का उदाहरण
जेस्चर पहचानने वाले टूल के लिए दिए गए उदाहरण कोड में, इस टास्क को JavaScript में पूरी तरह से लागू करने का तरीका बताया गया है. इस कोड की मदद से, इस टास्क को टेस्ट किया जा सकता है. साथ ही, जेस्चर पहचानने वाला अपना ऐप्लिकेशन बनाया जा सकता है. सिर्फ़ वेब ब्राउज़र का इस्तेमाल करके, जेस्चर पहचानने वाले उदाहरण को देखा, चलाया, और उसमें बदलाव किया जा सकता है.
सेटअप
इस सेक्शन में, जेस्चर पहचानने की सुविधा का इस्तेमाल करने के लिए, डेवलपमेंट एनवायरमेंट सेट अप करने का तरीका बताया गया है. वेब और JavaScript डेवलपमेंट एनवायरमेंट सेट अप करने के बारे में सामान्य जानकारी के लिए, वेब के लिए सेटअप गाइड देखें. इसमें प्लैटफ़ॉर्म के वर्शन से जुड़ी ज़रूरी शर्तें भी शामिल हैं.
JavaScript पैकेज
Gesture Recognizer का कोड, MediaPipe @mediapipe/tasks-vision
NPM पैकेज के ज़रिए उपलब्ध है. इन लाइब्रेरी को ढूंढने और डाउनलोड करने के लिए, प्लैटफ़ॉर्म की सेटअप गाइड में दिए गए निर्देशों का पालन करें.
ज़रूरी पैकेज को NPM के ज़रिए इंस्टॉल किया जा सकता है. इसके लिए, यह कमांड इस्तेमाल करें:
npm install @mediapipe/tasks-vision
अगर आपको कॉन्टेंट डिलीवरी नेटवर्क (सीडीएन) सेवा के ज़रिए टास्क कोड इंपोर्ट करना है, तो अपनी एचटीएमएल फ़ाइल में मौजूद <head> टैग में यह कोड जोड़ें:
<!-- You can replace JSDeliver with another CDN if you prefer to -->
<head>
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision/vision_bundle.mjs"
crossorigin="anonymous"></script>
</head>
मॉडल
MediaPipe Gesture Recognizer टास्क के लिए, ट्रेनिंग दिया गया ऐसा मॉडल ज़रूरी है जो इस टास्क के साथ काम करता हो. हाथ के जेस्चर पहचानने वाले टूल के लिए उपलब्ध ट्रेन किए गए मॉडल के बारे में ज़्यादा जानने के लिए, टास्क की खास जानकारी वाला मॉडल सेक्शन देखें.
मॉडल को चुनें और डाउनलोड करें. इसके बाद, इसे अपने प्रोजेक्ट डायरेक्ट्री में सेव करें:
<dev-project-root>/app/shared/models/
टास्क बनाना
इन्फ़रेंस चलाने के लिए टास्क तैयार करने के लिए, Gesture Recognizer createFrom...() फ़ंक्शन में से किसी एक का इस्तेमाल करें. ट्रेन किए गए मॉडल की फ़ाइल के रिलेटिव या ऐब्सलूट पाथ के साथ, createFromModelPath() फ़ंक्शन का इस्तेमाल करें.
अगर आपका मॉडल पहले से ही मेमोरी में लोड है, तो createFromModelBuffer() तरीके का इस्तेमाल किया जा सकता है.
नीचे दिए गए कोड के उदाहरण में, टास्क सेट अप करने के लिए createFromOptions() फ़ंक्शन का इस्तेमाल करने का तरीका दिखाया गया है. createFromOptions फ़ंक्शन की मदद से, कॉन्फ़िगरेशन के विकल्पों का इस्तेमाल करके, Gesture Recognizer को अपनी पसंद के मुताबिक बनाया जा सकता है. कॉन्फ़िगरेशन के विकल्पों के बारे में ज़्यादा जानने के लिए, कॉन्फ़िगरेशन के विकल्प लेख पढ़ें.
यहां दिए गए कोड में, कस्टम विकल्पों के साथ टास्क बनाने और उसे कॉन्फ़िगर करने का तरीका बताया गया है:
// Create task for image file processing:
const vision = await FilesetResolver.forVisionTasks(
// path/to/wasm/root
"https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision@latest/wasm "
);
const gestureRecognizer = await GestureRecognizer.createFromOptions(vision, {
baseOptions: {
modelAssetPath: "https://storage.googleapis.com/mediapipe-tasks/gesture_recognizer/gesture_recognizer.task"
},
numHands: 2
});
कॉन्फ़िगरेशन विकल्प
इस टास्क में, वेब ऐप्लिकेशन के लिए कॉन्फ़िगरेशन के ये विकल्प उपलब्ध हैं:
| विकल्प का नाम | ब्यौरा | वैल्यू की सीमा | डिफ़ॉल्ट मान |
|---|---|---|---|
runningMode |
यह कुकी, टास्क के रनिंग मोड को सेट करती है. इसके दो मोड हैं: IMAGE: यह मोड, एक इमेज वाले इनपुट के लिए होता है. VIDEO: यह वीडियो के डिकोड किए गए फ़्रेम या कैमरे जैसे इनपुट डेटा की लाइव स्ट्रीम के लिए मोड है. |
{IMAGE, VIDEO} |
IMAGE |
num_hands |
GestureRecognizer की मदद से, ज़्यादा से ज़्यादा हाथों का पता लगाया जा सकता है.
|
Any integer > 0 |
1 |
min_hand_detection_confidence |
हथेली का पता लगाने वाले मॉडल में, हाथ का पता लगाने की सुविधा के लिए कम से कम कॉन्फ़िडेंस स्कोर. | 0.0 - 1.0 |
0.5 |
min_hand_presence_confidence |
हाथ के लैंडमार्क का पता लगाने वाले मॉडल में, हाथ के मौजूद होने के स्कोर का कम से कम कॉन्फ़िडेंस स्कोर. हाथ के जेस्चर पहचानने वाले मॉडल के वीडियो मोड और लाइव स्ट्रीम मोड में, अगर हाथ के लैंडमार्क मॉडल से मिला हाथ की मौजूदगी का कॉन्फ़िडेंस स्कोर, इस थ्रेशोल्ड से कम है, तो यह पाम डिटेक्शन मॉडल को ट्रिगर करता है. ऐसा न होने पर, हाथ की ट्रैकिंग करने वाले हल्के एल्गोरिदम का इस्तेमाल किया जाता है. इससे, हाथ की जगह का पता लगाया जाता है, ताकि बाद में लैंडमार्क का पता लगाया जा सके. | 0.0 - 1.0 |
0.5 |
min_tracking_confidence |
हाथ के मूवमेंट को ट्रैक करने की सुविधा के लिए, कम से कम कॉन्फ़िडेंस स्कोर. यह मौजूदा फ़्रेम और पिछले फ़्रेम में मौजूद हाथों के बीच बाउंडिंग बॉक्स IoU थ्रेशोल्ड है. अगर जेस्चर पहचान करने वाले टूल के वीडियो मोड और स्ट्रीम मोड में ट्रैकिंग नहीं हो पाती है, तो जेस्चर पहचान करने वाला टूल, हाथ का पता लगाने की सुविधा को ट्रिगर करता है. ऐसा न होने पर, हाथ के जेस्चर (हाव-भाव) की पहचान करने की सुविधा काम नहीं करती. | 0.0 - 1.0 |
0.5 |
canned_gestures_classifier_options |
कैन किए गए जेस्चर क्लासिफ़ायर के व्यवहार को कॉन्फ़िगर करने के विकल्प. पहले से तैयार जेस्चर ["None", "Closed_Fist", "Open_Palm", "Pointing_Up", "Thumb_Down", "Thumb_Up", "Victory", "ILoveYou"]हैं |
|
|
custom_gestures_classifier_options |
कस्टम जेस्चर क्लासिफ़ायर के व्यवहार को कॉन्फ़िगर करने के विकल्प. |
|
|
डेटा तैयार करना
Gesture Recognizer, होस्ट ब्राउज़र के साथ काम करने वाले किसी भी फ़ॉर्मैट में मौजूद इमेज में जेस्चर की पहचान कर सकता है. यह टास्क, डेटा इनपुट की प्रीप्रोसेसिंग को भी मैनेज करता है. इसमें इमेज का साइज़ बदलना, उसे घुमाना, और वैल्यू को सामान्य करना शामिल है. वीडियो में जेस्चर पहचानने के लिए, एपीआई का इस्तेमाल किया जा सकता है. इससे एक बार में एक फ़्रेम को तेज़ी से प्रोसेस किया जा सकता है. साथ ही, फ़्रेम के टाइमस्टैंप का इस्तेमाल करके यह पता लगाया जा सकता है कि वीडियो में जेस्चर कब किए गए थे.
टास्क को रन करना
जेस्चर पहचानने वाला टूल, अनुमानों को ट्रिगर करने के लिए recognize() (रनिंग मोड 'image' के साथ) और recognizeForVideo() (रनिंग मोड 'video' के साथ) तरीकों का इस्तेमाल करता है. यह टास्क, डेटा को प्रोसेस करता है, हाथ के जेस्चर को पहचानने की कोशिश करता है, और फिर नतीजे दिखाता है.
नीचे दिए गए कोड में, टास्क मॉडल की मदद से प्रोसेसिंग को लागू करने का तरीका बताया गया है:
इमेज
const image = document.getElementById("image") as HTMLImageElement; const gestureRecognitionResult = gestureRecognizer.recognize(image);
वीडियो
await gestureRecognizer.setOptions({ runningMode: "video" }); let lastVideoTime = -1; function renderLoop(): void { const video = document.getElementById("video"); if (video.currentTime !== lastVideoTime) { const gestureRecognitionResult = gestureRecognizer.recognizeForVideo(video); processResult(gestureRecognitionResult); lastVideoTime = video.currentTime; } requestAnimationFrame(() => { renderLoop(); }); }
Gesture Recognizer की recognize() और recognizeForVideo() विधियों को कॉल करने पर, ये सिंक्रोनस तरीके से काम करती हैं और यूज़र इंटरफ़ेस थ्रेड को ब्लॉक कर देती हैं. अगर आपको किसी डिवाइस के कैमरे से लिए गए वीडियो फ़्रेम में जेस्चर (हाव-भाव) दिखते हैं, तो हर पहचान मुख्य थ्रेड को ब्लॉक कर देगी. इसे रोकने के लिए, वेब वर्कर लागू करें. इससे recognize() और recognizeForVideo() तरीकों को किसी अन्य थ्रेड पर चलाया जा सकेगा.
Gesture Recognizer टास्क को लागू करने के बारे में ज़्यादा जानकारी के लिए, उदाहरण देखें.
नतीजों को मैनेज करना और दिखाना
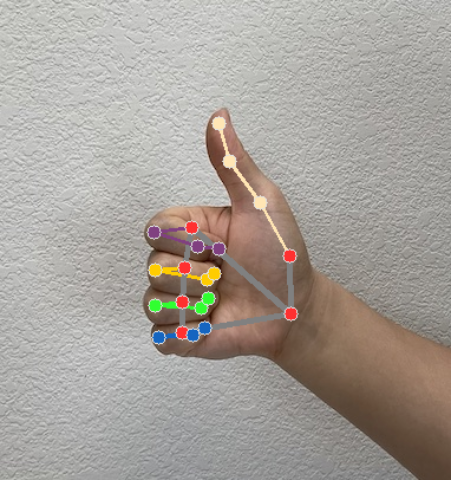
Gesture Recognizer, पहचान करने के हर रन के लिए, जेस्चर की पहचान करने वाला नतीजा ऑब्जेक्ट जनरेट करता है. नतीजे के ऑब्जेक्ट में, इमेज के कोऑर्डिनेट में हाथ के लैंडमार्क, दुनिया के कोऑर्डिनेट में हाथ के लैंडमार्क, हाथ के इस्तेमाल की प्राथमिकता(बायां/दायां हाथ), और हाथ के जेस्चर की कैटगरी शामिल होती हैं.
इस टास्क के आउटपुट डेटा का उदाहरण यहां दिया गया है:
GestureRecognizerResult में चार कॉम्पोनेंट होते हैं. हर कॉम्पोनेंट एक ऐरे होता है. इसमें मौजूद हर एलिमेंट में, एक हाथ का पता लगाया गया नतीजा होता है.
किसी खास हाथ का इस्तेमाल
'हाथ का इस्तेमाल' से पता चलता है कि पहचाने गए हाथ, बाएं हाथ हैं या दाएं हाथ.
हाथ के जेस्चर
पहचाने गए हाथों के जेस्चर की कैटगरी.
लैंडमार्क
हाथ के 21 लैंडमार्क होते हैं. हर लैंडमार्क में
x,y, औरzकोऑर्डिनेट होते हैं.xऔरyकोऑर्डिनेट को इमेज की चौड़ाई और ऊंचाई के हिसाब से, [0.0, 1.0] पर नॉर्मलाइज़ किया जाता है.zकोऑर्डिनेट, लैंडमार्क की गहराई को दिखाता है. इसमें कलाई की गहराई को ओरिजन माना जाता है. वैल्यू जितनी कम होगी, लैंडमार्क कैमरे के उतना ही करीब होगा.zकी वैल्यू,xकी वैल्यू के बराबर होती है.विश्व भू-स्थल
हाथ के 21 लैंडमार्क को वर्ल्ड कोऑर्डिनेट में भी दिखाया गया है. हर लैंडमार्क में
x,y, औरzशामिल होते हैं. ये मीटर में, हाथ के ज्योमेट्रिक सेंटर से ओरिजनल 3D कोऑर्डिनेट दिखाते हैं.
GestureRecognizerResult:
Handedness:
Categories #0:
index : 0
score : 0.98396
categoryName : Left
Gestures:
Categories #0:
score : 0.76893
categoryName : Thumb_Up
Landmarks:
Landmark #0:
x : 0.638852
y : 0.671197
z : -3.41E-7
Landmark #1:
x : 0.634599
y : 0.536441
z : -0.06984
... (21 landmarks for a hand)
WorldLandmarks:
Landmark #0:
x : 0.067485
y : 0.031084
z : 0.055223
Landmark #1:
x : 0.063209
y : -0.00382
z : 0.020920
... (21 world landmarks for a hand)
यहां दी गई इमेज में, टास्क के आउटपुट का विज़ुअलाइज़ेशन दिखाया गया है:
Gesture Recognizer टास्क बनाने की सुविधा को पूरी तरह से लागू करने के लिए, उदाहरण देखें.