
تتيح مهمة "التعرّف على الإيماءات" في MediaPipe التعرّف على إيماءات اليد في الوقت الفعلي، كما توفّر نتائج إيماءات اليد التي تم التعرّف عليها ومواضع اليدين التي تم رصدها. توضّح هذه التعليمات كيفية استخدام أداة Gesture Recognizer لتطبيقات الويب وتطبيقات JavaScript.
يمكنك الاطّلاع على هذه المهمة أثناء تنفيذها من خلال مشاهدة العرض التوضيحي. لمزيد من المعلومات حول إمكانات هذه المهمة ونماذجها وخيارات إعداداتها، يُرجى الاطّلاع على نظرة عامة.
مثال على الرمز
يوفّر نموذج الرمز البرمجي الخاص بأداة Gesture Recognizer عملية تنفيذ كاملة لهذه المهمة بلغة JavaScript يمكنك الرجوع إليها. يساعدك هذا الرمز في اختبار هذه المهمة والبدء في إنشاء تطبيقك الخاص للتعرّف على الإيماءات. يمكنك عرض مثال "أداة التعرّف على الإيماءات" وتشغيله وتعديله باستخدام متصفّح الويب فقط.
الإعداد
يوضّح هذا القسم الخطوات الأساسية لإعداد بيئة التطوير لاستخدام أداة Gesture Recognizer تحديدًا. للحصول على معلومات عامة حول إعداد بيئة تطوير الويب وJavaScript، بما في ذلك متطلبات إصدار النظام الأساسي، يُرجى الاطّلاع على دليل الإعداد للويب.
حِزم JavaScript
يتوفّر رمز Gesture Recognizer من خلال حزمة @mediapipe/tasks-vision
NPM في MediaPipe. يمكنك العثور على هذه المكتبات وتنزيلها باتّباع التعليمات الواردة في دليل الإعداد الخاص بالمنصة.
يمكنك تثبيت الحِزم المطلوبة من خلال NPM باستخدام الأمر التالي:
npm install @mediapipe/tasks-vision
إذا كنت تريد استيراد رمز المهمة من خلال خدمة شبكة توصيل المحتوى (CDN)، أضِف الرمز التالي في العلامة <head> في ملف HTML:
<!-- You can replace JSDeliver with another CDN if you prefer to -->
<head>
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision/vision_bundle.mjs"
crossorigin="anonymous"></script>
</head>
الطراز
تتطلّب مهمة "التعرّف على الإيماءات" في MediaPipe نموذجًا مدرَّبًا متوافقًا مع هذه المهمة. لمزيد من المعلومات عن النماذج المدرَّبة المتاحة لأداة Gesture Recognizer، يُرجى الاطّلاع على نظرة عامة على المهمة قسم "النماذج".
اختَر النموذج ونزِّله، ثم خزِّنه في دليل مشروعك:
<dev-project-root>/app/shared/models/
إنشاء المهمة
استخدِم إحدى دوال createFrom...() الخاصة بأداة Gesture Recognizer
لإعداد المهمة من أجل تنفيذ عمليات الاستدلال. استخدِم الدالة createFromModelPath()
مع مسار نسبي أو مطلق إلى ملف النموذج المدرَّب.
إذا كان النموذج محملًا في الذاكرة، يمكنك استخدام طريقة createFromModelBuffer().
يوضّح مثال الرمز البرمجي أدناه كيفية استخدام الدالة createFromOptions() لإعداد المهمة. تسمح لك الدالة createFromOptions بتخصيص
Gesture Recognizer باستخدام خيارات الضبط. لمزيد من المعلومات حول خيارات الإعداد، يُرجى الاطّلاع على خيارات الإعداد.
يوضّح الرمز التالي كيفية إنشاء المهمة وضبطها باستخدام خيارات مخصّصة:
// Create task for image file processing:
const vision = await FilesetResolver.forVisionTasks(
// path/to/wasm/root
"https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision@latest/wasm "
);
const gestureRecognizer = await GestureRecognizer.createFromOptions(vision, {
baseOptions: {
modelAssetPath: "https://storage.googleapis.com/mediapipe-tasks/gesture_recognizer/gesture_recognizer.task"
},
numHands: 2
});
خيارات الإعداد
تتضمّن هذه المهمة خيارات الإعداد التالية لتطبيقات الويب:
| اسم الخيار | الوصف | نطاق القيم | القيمة التلقائية |
|---|---|---|---|
runningMode |
تضبط هذه السمة وضع التشغيل للمهمة. يتوفّر وضعان: IMAGE: الوضع المخصّص لإدخال صورة واحدة. الفيديو: الوضع المخصّص للإطارات التي تم فك ترميزها من فيديو أو بث مباشر لبيانات الإدخال، مثل البيانات الواردة من كاميرا |
{IMAGE, VIDEO} |
IMAGE |
num_hands |
يمكن لجهاز GestureRecognizer رصد عدد أقصى من الأيدي.
|
Any integer > 0 |
1 |
min_hand_detection_confidence |
الحد الأدنى لنتيجة الثقة التي يجب تحقيقها حتى يُعتبَر رصد اليد ناجحًا في نموذج رصد راحة اليد. | 0.0 - 1.0 |
0.5 |
min_hand_presence_confidence |
الحد الأدنى لنتيجة الثقة في نموذج رصد العلامات الفارقة في اليد. في وضع "الفيديو" ووضع "البث المباشر" في Gesture Recognizer، إذا كانت نتيجة الثقة في رصد اليد من نموذج "المعالم الرئيسية لليد" أقل من هذا الحدّ، سيتم تفعيل نموذج رصد راحة اليد. في ما عدا ذلك، يتم استخدام خوارزمية بسيطة لتتبّع اليد لتحديد موضع اليدين من أجل رصد المعالم اللاحق. | 0.0 - 1.0 |
0.5 |
min_tracking_confidence |
تمثّل هذه السمة الحدّ الأدنى لدرجة الثقة التي يجب تحقيقها لكي يُعدّ تتبُّع اليد ناجحًا. هذا هو الحد الأدنى لمؤشر IoU الخاص بالمربّع المحيط بين اليدين في الإطار الحالي والإطار الأخير. في "وضع الفيديو" و"وضع البث" في Gesture Recognizer، إذا تعذّر التتبُّع، سيؤدي ذلك إلى تفعيل ميزة رصد اليد. وفي ما عدا ذلك، يتم تخطّي عملية رصد اليد. | 0.0 - 1.0 |
0.5 |
canned_gestures_classifier_options |
خيارات ضبط سلوك مصنّف الإيماءات الجاهزة الإيماءات الجاهزة هي ["None", "Closed_Fist", "Open_Palm", "Pointing_Up", "Thumb_Down", "Thumb_Up", "Victory", "ILoveYou"] |
|
|
custom_gestures_classifier_options |
خيارات ضبط سلوك مصنّف الإيماءات المخصّصة |
|
|
إعداد البيانات
يمكن أن تتعرّف أداة Gesture Recognizer على الإيماءات في الصور بأي تنسيق متوافق مع المتصفح المضيف. تتولّى المهمة أيضًا المعالجة المسبقة لإدخال البيانات، بما في ذلك تغيير الحجم والتدوير وتسوية القيم. للتعرّف على الإيماءات في الفيديوهات، يمكنك استخدام واجهة برمجة التطبيقات لمعالجة إطار واحد في كل مرة بسرعة، وذلك باستخدام الطابع الزمني للإطار لتحديد وقت حدوث الإيماءات في الفيديو.
تنفيذ المهمة
يستخدم Gesture Recognizer الطريقتَين recognize() (مع وضع التشغيل 'image') وrecognizeForVideo() (مع وضع التشغيل 'video') لتفعيل الاستنتاجات. تعالج المهمة البيانات وتحاول التعرّف على الإيماءات باليد، ثم تعرض النتائج.
يوضّح الرمز التالي كيفية تنفيذ المعالجة باستخدام نموذج المهمة:
صورة
const image = document.getElementById("image") as HTMLImageElement; const gestureRecognitionResult = gestureRecognizer.recognize(image);
فيديو
await gestureRecognizer.setOptions({ runningMode: "video" }); let lastVideoTime = -1; function renderLoop(): void { const video = document.getElementById("video"); if (video.currentTime !== lastVideoTime) { const gestureRecognitionResult = gestureRecognizer.recognizeForVideo(video); processResult(gestureRecognitionResult); lastVideoTime = video.currentTime; } requestAnimationFrame(() => { renderLoop(); }); }
يتم تنفيذ طلبات البيانات من الطريقتَين recognize() وrecognizeForVideo() في Gesture Recognizer بشكل متزامن، ما يؤدي إلى حظر سلسلة التعليمات الخاصة بواجهة المستخدم. إذا تعرّفت على إيماءات في لقطات الفيديو من كاميرا أحد الأجهزة، سيؤدي كل تعرّف إلى حظر سلسلة التعليمات الرئيسية. يمكنك منع ذلك من خلال تنفيذ برامج عاملة على الويب لتشغيل طريقتَي recognize() وrecognizeForVideo() في سلسلة محادثات أخرى.
للحصول على تنفيذ أكثر اكتمالاً لمهمة تشغيل أداة Gesture Recognizer، اطّلِع على المثال.
التعامل مع النتائج وعرضها
ينشئ أداة التعرّف على الإيماءات عنصر نتيجة رصد إيماءة لكل عملية رصد. يحتوي عنصر النتيجة على نقاط بارزة في اليد بإحداثيات الصورة، ونقاط بارزة في اليد بإحداثيات العالم، واستخدام إحدى اليدين(اليد اليسرى/اليمنى)، وفئات إيماءات اليدين التي تم رصدها.
في ما يلي مثال على بيانات الإخراج من هذه المهمة:
تحتوي GestureRecognizerResult الناتجة على أربعة مكوّنات، وكل مكوّن هو عبارة عن مصفوفة، حيث يحتوي كل عنصر على النتيجة التي تم رصدها ليد واحدة تم رصدها.
استخدام إحدى اليدين
يمثل استخدام إحدى اليدين ما إذا كانت الأيدي التي تم رصدها هي أيدي يمنى أو يسرى.
الإيماءات
فئات الإيماءات التي تم التعرّف عليها للأيدي التي تم رصدها
معالم
هناك 21 موضعًا بارزًا في اليد، ويتألف كل موضع من إحداثيات
xوyوz. يتم تسوية الإحداثياتxوyإلى [0.0, 1.0] حسب عرض الصورة وارتفاعها على التوالي. يمثّل الإحداثيzعمق المعلم، ويكون العمق عند المعصم هو نقطة الأصل. كلما كانت القيمة أصغر، كان المعلم أقرب إلى الكاميرا. يستخدم حجمzالمقياس نفسه تقريبًا المستخدَم فيx.المعالم العالمية
يتم أيضًا عرض 21 معلمًا بارزًا في اليد بإحداثيات العالم. يتألف كل معلم من
xوyوz، ما يمثّل إحداثيات ثلاثية الأبعاد في العالم الحقيقي بالمتر، ويكون مركزها الهندسي في منتصف اليد.
GestureRecognizerResult:
Handedness:
Categories #0:
index : 0
score : 0.98396
categoryName : Left
Gestures:
Categories #0:
score : 0.76893
categoryName : Thumb_Up
Landmarks:
Landmark #0:
x : 0.638852
y : 0.671197
z : -3.41E-7
Landmark #1:
x : 0.634599
y : 0.536441
z : -0.06984
... (21 landmarks for a hand)
WorldLandmarks:
Landmark #0:
x : 0.067485
y : 0.031084
z : 0.055223
Landmark #1:
x : 0.063209
y : -0.00382
z : 0.020920
... (21 world landmarks for a hand)
تعرض الصور التالية تمثيلاً مرئيًا لناتج المهمة:
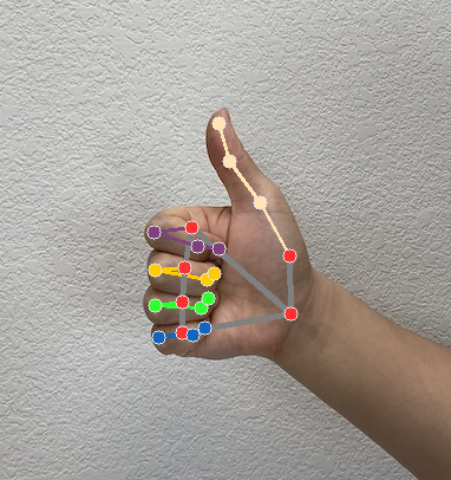
للحصول على تنفيذ أكثر اكتمالاً لإنشاء مهمة Gesture Recognizer، يُرجى الاطّلاع على المثال.