
A tarefa MediaPipe Hand Landmarker permite detectar os pontos de referência das mãos em uma imagem. Estas instruções mostram como usar o Hand Landmarker com Python. O exemplo de código descrito nestas instruções está disponível no GitHub.
Para mais informações sobre os recursos, modelos e opções de configuração desta tarefa, consulte a Visão geral.
Exemplo de código
O código de exemplo para o Hand Landmarker oferece uma implementação completa dessa tarefa em Python para sua referência. Esse código ajuda a testar essa tarefa e a criar seu próprio detector de pontos de referência da mão. Você pode conferir, executar e editar o código de exemplo do Hand Landmarker usando apenas o navegador da Web.
Se você estiver implementando o Hand Landmarker para Raspberry Pi, consulte o app de exemplo do Raspberry Pi.
Configuração
Esta seção descreve as principais etapas para configurar seu ambiente de desenvolvimento e projetos de código especificamente para usar o Hand Landmarker. Para informações gerais sobre como configurar o ambiente de desenvolvimento para usar as tarefas do MediaPipe, incluindo os requisitos da versão da plataforma, consulte o Guia de configuração para Python.
Pacotes
A tarefa do MediaPipe Hand Landmarker requer o pacote PyPI do MediaPipe. É possível instalar e importar essas dependências com o seguinte:
$ python -m pip install mediapipe
Importações
Importe as classes a seguir para acessar as funções da tarefa do Hand Landmarker:
import mediapipe as mp
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
Modelo
A tarefa do MediaPipe Hand Landmarker requer um modelo treinado compatível com essa tarefa. Para mais informações sobre os modelos treinados disponíveis para o Hand Landmarker, consulte a seção "Modelos" da visão geral da tarefa.
Selecione e faça o download do modelo e armazene-o em um diretório local:
model_path = '/absolute/path/to/gesture_recognizer.task'
Use o parâmetro model_asset_path do objeto BaseOptions para especificar o caminho
do modelo a ser usado. Para conferir um exemplo de código, consulte a próxima seção.
Criar a tarefa
A tarefa do MediaPipe Hand Landmarker usa a função create_from_options para
configurar a tarefa. A função create_from_options aceita valores
para que as opções de configuração sejam processadas. Para mais informações sobre as opções de
configuração, consulte Opções de configuração.
O código a seguir demonstra como criar e configurar essa tarefa.
Esses exemplos também mostram as variações da construção de tarefas para imagens, arquivos de vídeo e transmissão ao vivo.
Imagem
import mediapipe as mp BaseOptions = mp.tasks.BaseOptions HandLandmarker = mp.tasks.vision.HandLandmarker HandLandmarkerOptions = mp.tasks.vision.HandLandmarkerOptions VisionRunningMode = mp.tasks.vision.RunningMode # Create a hand landmarker instance with the image mode: options = HandLandmarkerOptions( base_options=BaseOptions(model_asset_path='/path/to/model.task'), running_mode=VisionRunningMode.IMAGE) with HandLandmarker.create_from_options(options) as landmarker: # The landmarker is initialized. Use it here. # ...
Vídeo
import mediapipe as mp BaseOptions = mp.tasks.BaseOptions HandLandmarker = mp.tasks.vision.HandLandmarker HandLandmarkerOptions = mp.tasks.vision.HandLandmarkerOptions VisionRunningMode = mp.tasks.vision.RunningMode # Create a hand landmarker instance with the video mode: options = HandLandmarkerOptions( base_options=BaseOptions(model_asset_path='/path/to/model.task'), running_mode=VisionRunningMode.VIDEO) with HandLandmarker.create_from_options(options) as landmarker: # The landmarker is initialized. Use it here. # ...
Transmissão ao vivo
import mediapipe as mp BaseOptions = mp.tasks.BaseOptions HandLandmarker = mp.tasks.vision.HandLandmarker HandLandmarkerOptions = mp.tasks.vision.HandLandmarkerOptions HandLandmarkerResult = mp.tasks.vision.HandLandmarkerResult VisionRunningMode = mp.tasks.vision.RunningMode # Create a hand landmarker instance with the live stream mode: def print_result(result: HandLandmarkerResult, output_image: mp.Image, timestamp_ms: int): print('hand landmarker result: {}'.format(result)) options = HandLandmarkerOptions( base_options=BaseOptions(model_asset_path='/path/to/model.task'), running_mode=VisionRunningMode.LIVE_STREAM, result_callback=print_result) with HandLandmarker.create_from_options(options) as landmarker: # The landmarker is initialized. Use it here. # ...
Para conferir um exemplo completo de como criar um Hand Landmarker para uso com uma imagem, consulte o exemplo de código.
Opções de configuração
Esta tarefa tem as seguintes opções de configuração para aplicativos Python:
| Nome da opção | Descrição | Intervalo de valor | Valor padrão |
|---|---|---|---|
running_mode |
Define o modo de execução da tarefa. Há três
modos: IMAGE: o modo para entradas de imagem única. VÍDEO: o modo para quadros decodificados de um vídeo. LIVE_STREAM: o modo de uma transmissão ao vivo de dados de entrada, como de uma câmera. Nesse modo, o resultListener precisa ser chamado para configurar um listener para receber resultados de forma assíncrona. |
{IMAGE, VIDEO, LIVE_STREAM} |
IMAGE |
num_hands |
O número máximo de mãos detectadas pelo detector de pontos de referência da mão. | Any integer > 0 |
1 |
min_hand_detection_confidence |
A pontuação de confiança mínima para que a detecção de mão seja considerada bem-sucedida no modelo de detecção de palma. | 0.0 - 1.0 |
0.5 |
min_hand_presence_confidence |
A pontuação de confiança mínima para a pontuação de presença de mão no modelo de detecção de ponto de referência da mão. No modo de vídeo e na transmissão ao vivo, se a pontuação de confiança de presença da mão do modelo de ponto de referência da mão estiver abaixo desse limite, o Hand Landmarker vai acionar o modelo de detecção de palma. Caso contrário, um algoritmo de rastreamento de mão leve determina a localização da mão para detecções de marco subsequentes. | 0.0 - 1.0 |
0.5 |
min_tracking_confidence |
A pontuação de confiança mínima para que o rastreamento de mãos seja considerado bem-sucedido. Esse é o limite de IoU da caixa delimitadora entre as mãos no frame atual e no último. No modo de vídeo e no modo de transmissão do Hand Landmarker, se o rastreamento falhar, o Hand Landmarker aciona a detecção da mão. Caso contrário, a detecção de mãos é ignorada. | 0.0 - 1.0 |
0.5 |
result_callback |
Define o listener de resultado para receber os resultados de detecção
de forma assíncrona quando o marcador de mão está no modo de transmissão ao vivo.
Aplicável apenas quando o modo de execução está definido como LIVE_STREAM |
N/A | N/A |
Preparar dados
Prepare a entrada como um arquivo de imagem ou uma matriz NumPy
e converta-a em um objeto mediapipe.Image. Se a entrada for um arquivo de vídeo
ou uma transmissão ao vivo de uma webcam, use uma biblioteca externa, como o
OpenCV, para carregar os frames de entrada como matrizes
numpy.
Imagem
import mediapipe as mp # Load the input image from an image file. mp_image = mp.Image.create_from_file('/path/to/image') # Load the input image from a numpy array. mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=numpy_image)
Vídeo
import mediapipe as mp # Use OpenCV’s VideoCapture to load the input video. # Load the frame rate of the video using OpenCV’s CV_CAP_PROP_FPS # You’ll need it to calculate the timestamp for each frame. # Loop through each frame in the video using VideoCapture#read() # Convert the frame received from OpenCV to a MediaPipe’s Image object. mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=numpy_frame_from_opencv)
Transmissão ao vivo
import mediapipe as mp # Use OpenCV’s VideoCapture to start capturing from the webcam. # Create a loop to read the latest frame from the camera using VideoCapture#read() # Convert the frame received from OpenCV to a MediaPipe’s Image object. mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=numpy_frame_from_opencv)
Executar a tarefa
O Hand Landmarker usa as funções detect, detect_for_video e detect_async para acionar inferências. Para a detecção de pontos de referência da mão, isso envolve pré-processar dados de entrada, detectar mãos na imagem e detectar pontos de referência da mão.
O código abaixo demonstra como executar o processamento com o modelo de tarefa.
Imagem
# Perform hand landmarks detection on the provided single image. # The hand landmarker must be created with the image mode. hand_landmarker_result = landmarker.detect(mp_image)
Vídeo
# Perform hand landmarks detection on the provided single image. # The hand landmarker must be created with the video mode. hand_landmarker_result = landmarker.detect_for_video(mp_image, frame_timestamp_ms)
Transmissão ao vivo
# Send live image data to perform hand landmarks detection. # The results are accessible via the `result_callback` provided in # the `HandLandmarkerOptions` object. # The hand landmarker must be created with the live stream mode. landmarker.detect_async(mp_image, frame_timestamp_ms)
Observe o seguinte:
- Ao executar no modo de vídeo ou de transmissão ao vivo, também é necessário fornecer à tarefa do Hand Landmarker o carimbo de data/hora do frame de entrada.
- Ao ser executada no modelo de imagem ou vídeo, a tarefa de detecção de pontos de referência da mão bloqueia a linha de execução atual até que ela termine de processar a imagem de entrada ou o frame.
- Quando executada no modo de transmissão ao vivo, a tarefa de detecção de pontos de referência da mão não bloqueia a linha de execução atual, mas retorna imediatamente. Ele vai invocar o listener de resultado com o resultado da detecção sempre que terminar de processar um frame de entrada. Se a função de detecção for chamada quando a tarefa do Hand Landmarker estiver ocupada processando outro frame, a tarefa vai ignorar o novo frame de entrada.
Para conferir um exemplo completo de execução de um Hand Landmarker em uma imagem, consulte o exemplo de código.
Processar e mostrar resultados
O Hand Landmarker gera um objeto de resultado de Hand Landmarker para cada execução de detecção. O objeto de resultado contém pontos de referência de mãos em coordenadas de imagem, pontos de referência de mãos em coordenadas do mundo e lateralidade(mão esquerda/direita) das mãos detectadas.
Confira a seguir um exemplo dos dados de saída desta tarefa:
A saída HandLandmarkerResult contém três componentes. Cada componente é uma matriz, em que cada elemento contém os seguintes resultados para uma única mão detectada:
Mão dominante
A dominância da mão representa se as mãos detectadas são esquerda ou direita.
Pontos de referência
Há 21 pontos de referência da mão, cada um composto por coordenadas
x,yez. As coordenadasxeysão normalizadas para [0,0, 1,0] pela largura e altura da imagem, respectivamente. A coordenadazrepresenta a profundidade do ponto de referência, com a profundidade no pulso sendo a origem. Quanto menor o valor, mais próximo o ponto de referência está da câmera. A magnitude dezusa aproximadamente a mesma escala dex.Pontos turísticos do mundo
Os 21 pontos de referência da mão também são apresentados em coordenadas mundiais. Cada ponto de referência é composto por
x,yez, representando coordenadas 3D do mundo real em metros com a origem no centro geométrico da mão.
HandLandmarkerResult:
Handedness:
Categories #0:
index : 0
score : 0.98396
categoryName : Left
Landmarks:
Landmark #0:
x : 0.638852
y : 0.671197
z : -3.41E-7
Landmark #1:
x : 0.634599
y : 0.536441
z : -0.06984
... (21 landmarks for a hand)
WorldLandmarks:
Landmark #0:
x : 0.067485
y : 0.031084
z : 0.055223
Landmark #1:
x : 0.063209
y : -0.00382
z : 0.020920
... (21 world landmarks for a hand)
A imagem a seguir mostra uma visualização da saída da tarefa:
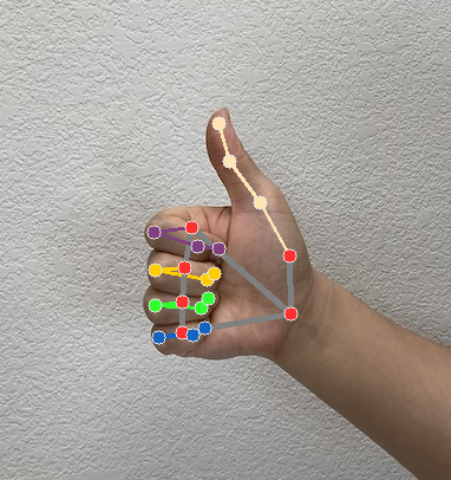
O código de exemplo do Hand Landmarker demonstra como mostrar os resultados retornados pela tarefa. Consulte o exemplo de código para mais detalhes.