
借助 MediaPipe 手部特征点检测器任务,您可以检测图片中手部的特征点。 以下说明介绍了如何将手部特征点检测器用于 Web 和 JavaScript 应用。
如需详细了解此任务的功能、模型和配置选项 ,请参阅概览。
代码示例
手部特征点检测器的示例代码提供了此任务在 JavaScript 中的完整实现,供您参考。此代码可帮助您测试此任务,并开始构建自己的手部特征点检测应用。您只需使用 Web 浏览器即可查看、运行和修改手部特征点检测器示例。
设置
本部分介绍了设置开发环境以专门使用手部特征点检测器的关键步骤。如需了解有关 设置 Web 和 JavaScript 开发环境的一般信息(包括 平台版本要求),请参阅 Web 设置指南。
JavaScript 软件包
手部特征点检测器代码可通过 MediaPipe @mediapipe/tasks-vision
NPM 软件包获取。您可以
按照平台
设置指南中的说明查找和下载这些库。
您可以使用以下命令通过 NPM 安装所需的软件包:
npm install @mediapipe/tasks-vision
如果您想通过内容分发网络 (CDN) 服务导入任务代码,请在 HTML 文件中的 <head> 标记中添加以下代码:
<!-- You can replace JSDeliver with another CDN if you prefer to -->
<head>
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision/vision_bundle.mjs"
crossorigin="anonymous"></script>
</head>
模型
MediaPipe 手部特征点检测器任务需要与此任务兼容的训练模型。如需详细了解可用于手部特征点检测器的可用训练模型,请参阅 任务概览的“模型”部分。
选择并下载模型,然后将其存储在项目目录中:
<dev-project-root>/app/shared/models/
创建任务
使用其中一个手部特征点检测器 createFrom...() 函数来准备运行推理的任务。使用 createFromModelPath() 函数以及训练模型文件的相对或绝对路径。
如果您的模型已加载到内存中,则可以使用 createFromModelBuffer() 方法。
以下代码示例演示了如何使用 createFromOptions() 函数来设置任务。借助 createFromOptions 函数,您可以使用配置选项自定义手部特征点检测器。如需详细了解配置
选项,请参阅配置选项。
以下代码演示了如何使用自定义选项构建和配置任务:
const vision = await FilesetResolver.forVisionTasks(
// path/to/wasm/root
"https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision@latest/wasm"
);
const handLandmarker = await HandLandmarker.createFromOptions(
vision,
{
baseOptions: {
modelAssetPath: "hand_landmarker.task"
},
numHands: 2
});
配置选项
此任务具有以下适用于 Web 和 JavaScript 应用的配置选项:
| 选项名称 | 说明 | 值范围 | 默认值 |
|---|---|---|---|
runningMode |
设置任务的运行模式。有两种
模式: IMAGE:用于单张图片输入的模式。 VIDEO:用于视频的解码帧或输入数据(例如来自摄像头的数据)的直播的模式。 |
{IMAGE, VIDEO} |
IMAGE |
numHands |
手部特征点检测器检测到的手部数量上限。 | Any integer > 0 |
1 |
minHandDetectionConfidence |
在手掌检测模型中,手部检测被视为成功的最低置信度分数。 | 0.0 - 1.0 |
0.5 |
minHandPresenceConfidence |
手部 特征点检测模型中手部存在置信度分数的最低置信度分数。在视频模式和直播模式下, 如果手部特征点模型的手部存在置信度分数低于 此阈值,手部特征点检测器会触发手掌检测模型。否则,轻量级手部跟踪算法会确定手部的位置,以便进行后续的特征点检测。 | 0.0 - 1.0 |
0.5 |
minTrackingConfidence |
手部跟踪被视为 成功的最低置信度分数。这是当前帧和上一帧中手部之间的边界框 IoU 阈值。在手部特征点检测器的视频模式和流模式下,如果跟踪失败,手部特征点检测器会触发手部检测。否则,它会跳过手部检测。 | 0.0 - 1.0 |
0.5 |
准备数据
手部特征点检测器可以检测主机浏览器支持的任何格式的图片中的手部特征点。该任务还会处理数据输入预处理,包括调整大小、旋转和值归一化。如需检测视频中的手部特征点,您可以使用 API 快速处理每个帧,并使用帧的时间戳来确定手部特征点在视频中出现的时间。
运行任务
手部特征点检测器使用 detect()(运行模式为 image)和 detectForVideo()(运行模式为 video)方法来触发推理。该任务会处理数据,尝试检测手部特征点,然后报告结果。
对 detect() 和 detectForVideo() 方法的调用会同步运行,并会阻塞界面线程。如果您检测设备摄像头拍摄的视频帧中的手部特征点,则每次检测都会阻塞主线程。您可以通过实现 Web Worker 在另一个线程上运行 detect() 和 detectForVideo() 方法来避免这种情况。
以下代码演示了如何使用任务模型执行处理:
图片
const image = document.getElementById("image") as HTMLImageElement; const handLandmarkerResult = handLandmarker.detect(image);
视频
await handLandmarker.setOptions({ runningMode: "video" }); let lastVideoTime = -1; function renderLoop(): void { const video = document.getElementById("video"); if (video.currentTime !== lastVideoTime) { const detections = handLandmarker.detectForVideo(video); processResults(detections); lastVideoTime = video.currentTime; } requestAnimationFrame(() => { renderLoop(); }); }
如需更完整地了解如何运行手部特征点检测器任务,请参阅 示例。
处理和显示结果
手部特征点检测器会为每次检测运行生成一个手部特征点检测器结果对象。结果对象包含图片坐标中的手部特征点、世界坐标中的手部特征点以及检测到的手的惯用手(左手/右手)。
以下示例展示了此任务的输出数据:
HandLandmarkerResult 输出包含三个组件。每个组件都是一个数组,其中每个元素都包含单个检测到的手的以下结果:
惯用手
惯用手表示检测到的手是左手还是右手。
特征点
共有 21 个手部特征点,每个特征点都由
x、y和z坐标组成。x和y坐标分别根据图片宽度和高度归一化为 [0.0, 1.0]。z坐标表示特征点深度,手腕处的深度为原点。值越小,特征点越靠近摄像头。z的大小与x的比例大致相同。世界特征点
21 个手部特征点也以世界坐标表示。每个特征点都由
x、y和z组成,表示以米为单位的真实世界 3D 坐标,原点位于手的几何中心。
HandLandmarkerResult:
Handedness:
Categories #0:
index : 0
score : 0.98396
categoryName : Left
Landmarks:
Landmark #0:
x : 0.638852
y : 0.671197
z : -3.41E-7
Landmark #1:
x : 0.634599
y : 0.536441
z : -0.06984
... (21 landmarks for a hand)
WorldLandmarks:
Landmark #0:
x : 0.067485
y : 0.031084
z : 0.055223
Landmark #1:
x : 0.063209
y : -0.00382
z : 0.020920
... (21 world landmarks for a hand)
下图显示了任务输出的可视化效果:
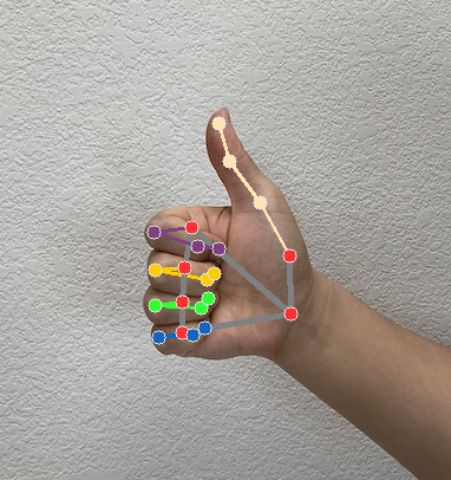
手部特征点检测器示例代码演示了如何显示从任务返回的 结果,请参阅 示例