Gemini, ses girişini analiz edip metin yanıtları oluşturabilir.
Python
from google import genai
import base64
client = genai.Client()
uploaded_file = client.files.upload(file="path/to/sample.mp3")
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "text", "text": "Describe this audio clip"},
{
"type": "audio",
"uri": uploaded_file.uri,
"mime_type": uploaded_file.mime_type
}
]
)
print(interaction.output_text)
JavaScript
import { GoogleGenAI } from "@google/genai";
const client = new GoogleGenAI({});
const uploadedFile = await client.files.upload({
file: "path/to/sample.mp3",
config: { mime_type: "audio/mp3" }
});
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{type: "text", text: "Describe this audio clip"},
{
type: "audio",
uri: uploadedFile.uri,
mime_type: uploadedFile.mimeType
}
]
});
console.log(interaction.output_text);
REST
# First upload the file, then use the URI:
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"input": [
{"type": "text", "text": "Describe this audio clip"},
{
"type": "audio",
"uri": "YOUR_FILE_URI",
"mime_type": "audio/mp3"
}
]
}'
Genel Bakış
Gemini, ses girişini analiz edip anlayabilir ve metin yanıtları oluşturabilir. Bu sayede aşağıdaki gibi kullanım alanları ortaya çıkar:
- Ses içeriğini açıklama, özetleme veya ses içeriğiyle ilgili soruları yanıtlama
- Metne dönüştürme ve çeviri (konuşmayı metne dönüştürme)
- Konuşmacı ayırma (farklı konuşmacıları tanımlama)
- Konuşma ve müzikte duygu algılama
- Zaman damgalarıyla belirli segmentleri analiz etme
Gerçek zamanlı ses ve video etkileşimleri için Live API'ye bakın. Gerçek zamanlı transkripsiyonu destekleyen özel konuşmayı metne dönüştürme modelleri için Google Cloud Speech-to-Text API'yi kullanın.
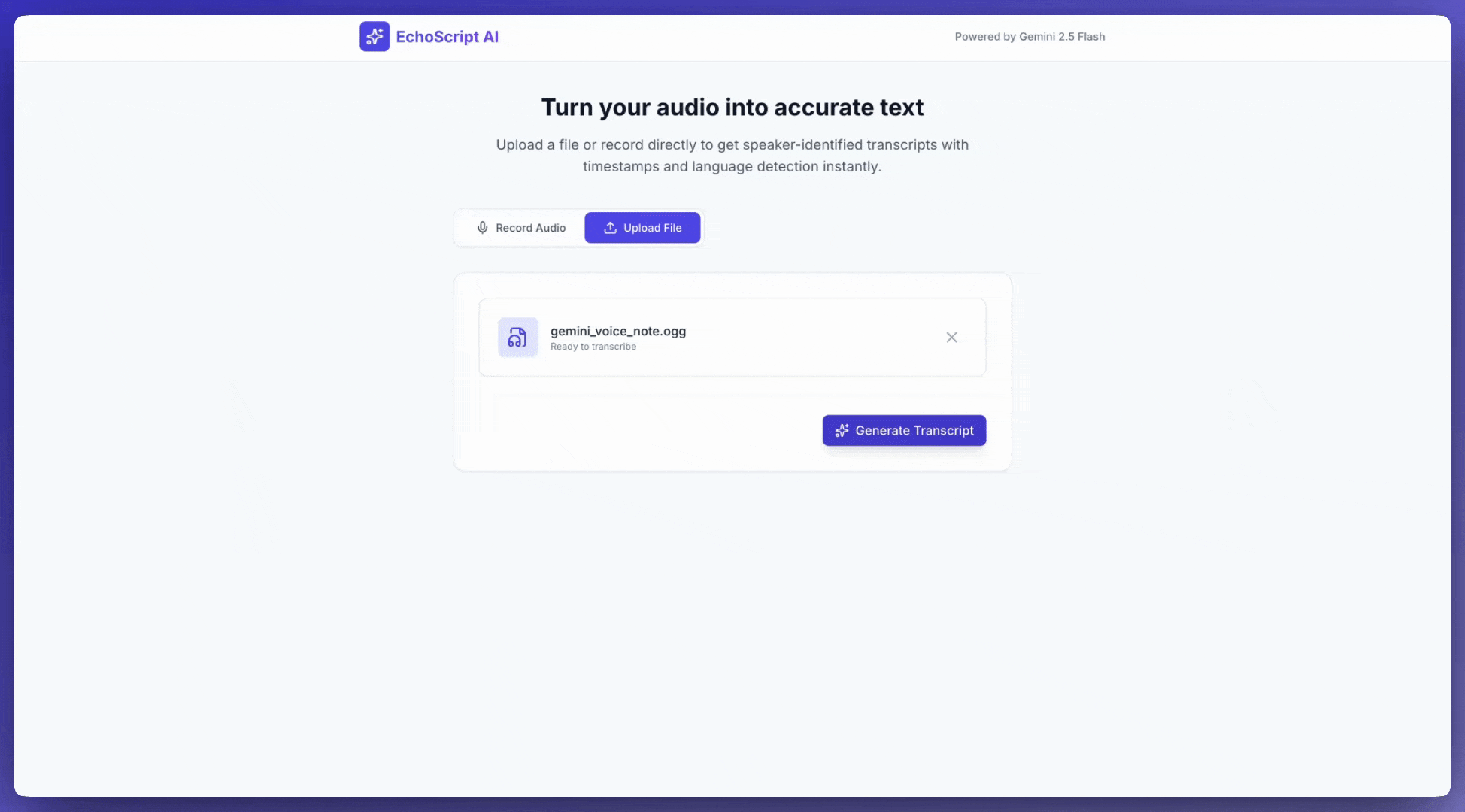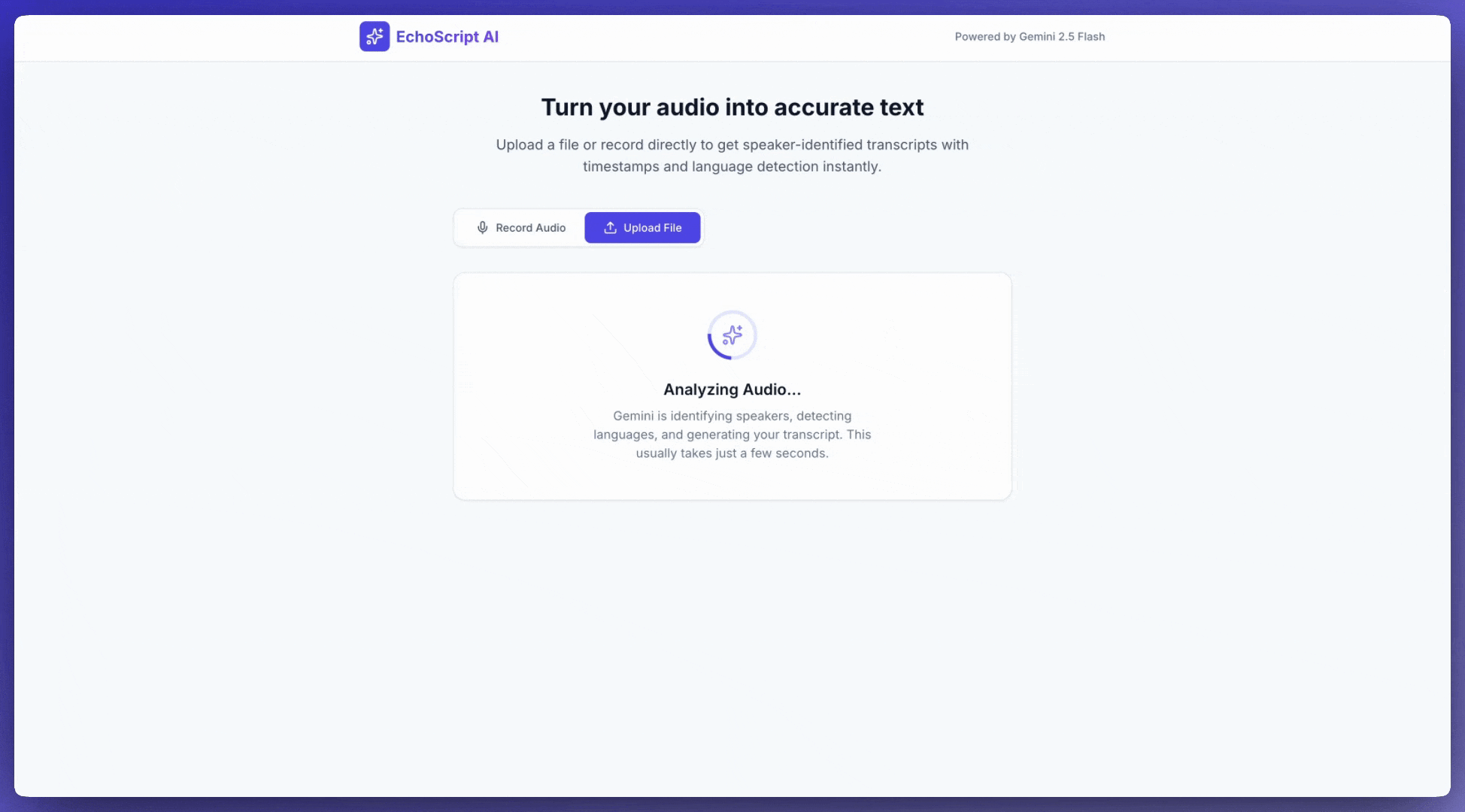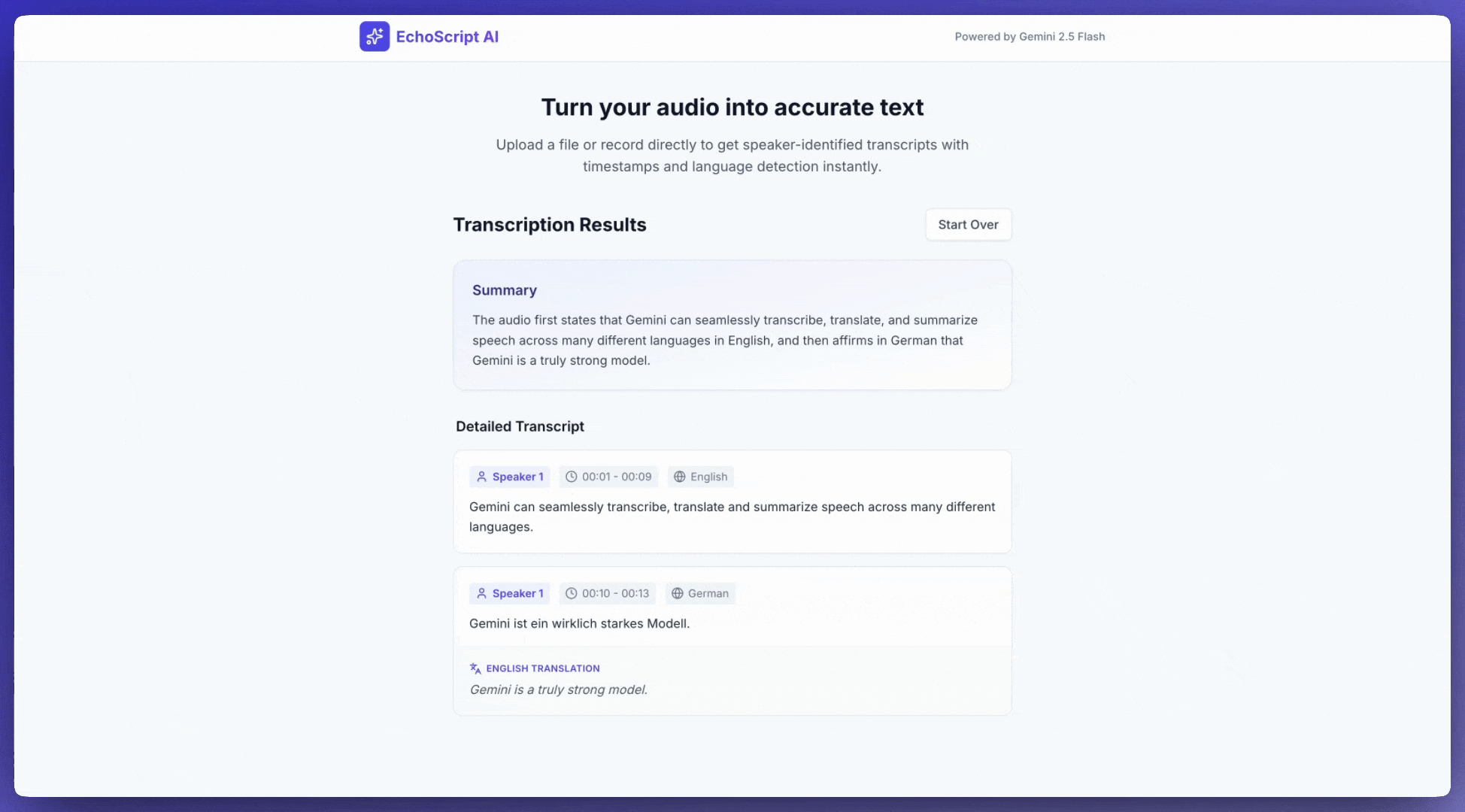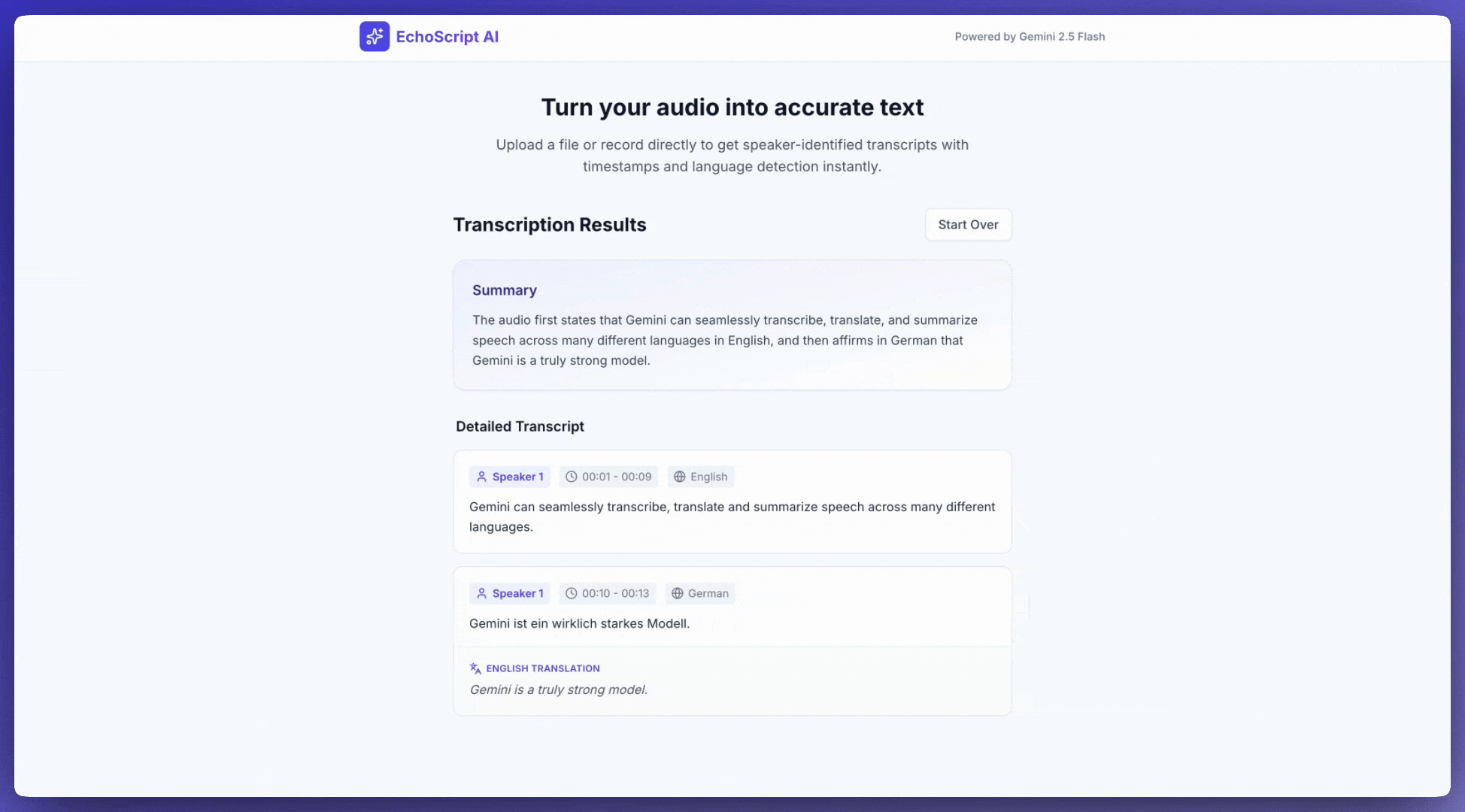
Konuşmayı metne dönüştürme
Bu örnekte, yapılandırılmış çıkışlar kullanarak konuşmayı zaman damgaları, konuşmacı ayrımı ve duygu algılama ile nasıl metne dönüştüreceğiniz, çevireceğiniz ve özetleyeceğiniz gösterilmektedir.
Python
from google import genai
client = genai.Client()
YOUTUBE_URL = "https://www.youtube.com/watch?v=ku-N-eS1lgM"
prompt = """
Process the audio file and generate a detailed transcription.
Requirements:
1. Identify distinct speakers (e.g., Speaker 1, Speaker 2).
2. Provide accurate timestamps for each segment (Format: MM:SS).
3. Detect the primary language of each segment.
4. If not English, provide the English translation.
5. Identify the primary emotion: Happy, Sad, Angry, or Neutral.
6. Provide a brief summary at the beginning.
"""
response_schema = {
"type": "object",
"properties": {
"summary": {"type": "string"},
"segments": {
"type": "array",
"items": {
"type": "object",
"properties": {
"speaker": {"type": "string"},
"timestamp": {"type": "string"},
"content": {"type": "string"},
"language": {"type": "string"},
"emotion": {
"type": "string",
"enum": ["happy", "sad", "angry", "neutral"]
}
},
"required": ["speaker", "timestamp", "content", "emotion"]
}
}
},
"required": ["summary", "segments"]
}
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "video", "uri": YOUTUBE_URL, "mime_type": "video/mp4"},
{"type": "text", "text": prompt}
],
response_format=response_schema,
)
print(interaction.output_text)
JavaScript
import { GoogleGenAI } from "@google/genai";
const client = new GoogleGenAI({});
const YOUTUBE_URL = "https://www.youtube.com/watch?v=ku-N-eS1lgM";
const prompt = `
Process the audio file and generate a detailed transcription.
Requirements:
1. Identify distinct speakers (e.g., Speaker 1, Speaker 2).
2. Provide accurate timestamps for each segment (Format: MM:SS).
3. Detect the primary language of each segment.
4. If not English, provide the English translation.
5. Identify the primary emotion: Happy, Sad, Angry, or Neutral.
6. Provide a brief summary at the beginning.
`;
const responseSchema = {
type: "object",
properties: {
summary: { type: "string" },
segments: {
type: "array",
items: {
type: "object",
properties: {
speaker: { type: "string" },
timestamp: { type: "string" },
content: { type: "string" },
language: { type: "string" },
emotion: {
type: "string",
enum: ["happy", "sad", "angry", "neutral"]
}
},
required: ["speaker", "timestamp", "content", "emotion"]
}
}
},
required: ["summary", "segments"]
};
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{ type: "video", uri: YOUTUBE_URL, mime_type: "video/mp4" },
{ type: "text", text: prompt }
],
response_format: responseSchema,
});
console.log(JSON.parse(interaction.output_text));
REST
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"input": [
{
"type": "video",
"uri": "https://www.youtube.com/watch?v=ku-N-eS1lgM",
"mime_type": "video/mp4"
},
{
"type": "text",
"text": "Transcribe with speaker diarization and emotion detection."
}
],
"response_format": {
"type": "object",
"properties": {
"summary": {"type": "string"},
"segments": {
"type": "array",
"items": {
"type": "object",
"properties": {
"speaker": {"type": "string"},
"timestamp": {"type": "string"},
"content": {"type": "string"},
"emotion": {"type": "string", "enum": ["happy", "sad", "angry", "neutral"]}
}
}
}
}
}
}'
Giriş sesi
Ses verilerini aşağıdaki şekillerde sağlayabilirsiniz:
- İstek göndermeden önce ses dosyası yükleyin.
- İstekle birlikte satır içi ses verilerini iletin.
Ses dosyası yükleme
20 MB'tan büyük dosyalar için Files API'yi kullanın.
Python
from google import genai
client = genai.Client()
uploaded_file = client.files.upload(file="path/to/sample.mp3")
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "text", "text": "Describe this audio clip"},
{
"type": "audio",
"uri": uploaded_file.uri,
"mime_type": uploaded_file.mime_type
}
]
)
print(interaction.output_text)
JavaScript
import { GoogleGenAI } from "@google/genai";
const client = new GoogleGenAI({});
const uploadedFile = await client.files.upload({
file: "path/to/sample.mp3",
config: { mimeType: "audio/mp3" }
});
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{type: "text", text: "Describe this audio clip"},
{
type: "audio",
uri: uploadedFile.uri,
mime_type: uploadedFile.mimeType
}
]
});
console.log(interaction.output_text);
REST
# First upload the file using the Files API, then use the URI:
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"input": [
{"type": "text", "text": "Describe this audio clip"},
{
"type": "audio",
"uri": "YOUR_FILE_URI",
"mime_type": "audio/mp3"
}
]
}'
Ses verilerini satır içi olarak iletme
Toplam istek boyutu 20 MB'tan küçük olan ses dosyaları için:
Python
from google import genai
import base64
client = genai.Client()
with open('path/to/small-sample.mp3', 'rb') as f:
audio_bytes = f.read()
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "text", "text": "Describe this audio clip"},
{
"type": "audio",
"data": base64.b64encode(audio_bytes).decode('utf-8'),
"mime_type": "audio/mp3"
}
]
)
print(interaction.output_text)
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
const client = new GoogleGenAI({});
const audioData = fs.readFileSync("path/to/small-sample.mp3", {
encoding: "base64"
});
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{type: "text", text: "Describe this audio clip"},
{
type: "audio",
data: audioData,
mime_type: "audio/mp3"
}
]
});
console.log(interaction.output_text);
REST
AUDIO_PATH="path/to/sample.mp3"
if [[ "$(base64 --version 2>&1)" = *"FreeBSD"* ]]; then
B64FLAGS="--input"
else
B64FLAGS="-w0"
fi
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"input": [
{"type": "text", "text": "Describe this audio clip"},
{
"type": "audio",
"data": "'$(base64 $B64FLAGS $AUDIO_PATH)'",
"mime_type": "audio/mp3"
}
]
}'
Satır içi ses verileriyle ilgili notlar: * Maksimum istek boyutu toplam 20 MB'tır (istemler ve tüm dosyalar dahil). * Yeniden kullanmak için dosyayı yükleyin.
Transkript alma
Transkript almak için istemde transkript isteyin:
Python
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "text", "text": "Generate a transcript of the speech."},
{
"type": "audio",
"uri": uploaded_file.uri,
"mime_type": uploaded_file.mime_type
}
]
)
print(interaction.output_text)
JavaScript
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{ type: "text", text: "Generate a transcript of the speech." },
{
type: "audio",
uri: uploadedFile.uri,
mime_type: uploadedFile.mimeType
}
]
});
console.log(interaction.output_text);
Zaman damgalarına bakın
Belirli bölümlere referans vermek için MM:SS biçimini kullanın:
Python
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "text", "text": "Provide a transcript from 02:30 to 03:29."},
{
"type": "audio",
"uri": uploaded_file.uri,
"mime_type": uploaded_file.mime_type
}
]
)
JavaScript
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{ type: "text", text: "Provide a transcript from 02:30 to 03:29." },
{ type: "audio", uri: uploadedFile.uri, mime_type: "audio/mp3" }
]
});
Parça sayma
Ses dosyasındaki jetonları sayma:
Python
response = client.models.count_tokens(
model="gemini-3.5-flash",
contents=[uploaded_file]
)
print(response)
JavaScript
const response = await client.models.countTokens({
model: "gemini-3.5-flash",
contents: [
{ fileData: { fileUri: uploadedFile.uri, mimeType: uploadedFile.mimeType } }
]
});
console.log(response.totalTokens);
Desteklenen ses biçimleri
- WAV -
audio/wav - MP3 -
audio/mp3 - AIFF -
audio/aiff - AAC -
audio/aac - OGG Vorbis -
audio/ogg - FLAC -
audio/flac
Sesle ilgili teknik ayrıntılar
- Jetonlar: Sesin her saniyesi için 32 jeton (1 dakika = 1.920 jeton)
- Konuşma dışı sesler: Gemini, konuşma dışı sesleri (kuş sesi, siren vb.) anlar.
- Maksimum uzunluk: İstem başına 9,5 saatlik ses
- Çözünürlük: 16 kbps'ye düşürülür.
- Kanallar: Çok kanallı ses tek kanalda birleştirilir.
Sırada ne var?
- Files API: Ses dosyalarını yükleme ve yönetme
- Sistem talimatları: Model davranışını özelleştirme
- Yapılandırılmış çıkış: JSON biçiminde transkripsiyon sonuçları alma