Gemini có thể phân tích dữ liệu đầu vào âm thanh và tạo câu trả lời bằng văn bản.
Python
from google import genai
import base64
client = genai.Client()
uploaded_file = client.files.upload(file="path/to/sample.mp3")
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "text", "text": "Describe this audio clip"},
{
"type": "audio",
"uri": uploaded_file.uri,
"mime_type": uploaded_file.mime_type
}
]
)
print(interaction.output_text)
JavaScript
import { GoogleGenAI } from "@google/genai";
const client = new GoogleGenAI({});
const uploadedFile = await client.files.upload({
file: "path/to/sample.mp3",
config: { mime_type: "audio/mp3" }
});
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{type: "text", text: "Describe this audio clip"},
{
type: "audio",
uri: uploadedFile.uri,
mime_type: uploadedFile.mimeType
}
]
});
console.log(interaction.output_text);
REST
# First upload the file, then use the URI:
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"input": [
{"type": "text", "text": "Describe this audio clip"},
{
"type": "audio",
"uri": "YOUR_FILE_URI",
"mime_type": "audio/mp3"
}
]
}'
Tổng quan
Gemini có thể phân tích và hiểu dữ liệu đầu vào âm thanh, đồng thời tạo câu trả lời bằng văn bản, cho phép các trường hợp sử dụng như:
- Mô tả, tóm tắt hoặc trả lời câu hỏi về nội dung âm thanh
- Phiên âm và dịch (lời nói thành văn bản)
- Phân tách người nói (xác định những người nói khác nhau)
- Phát hiện cảm xúc trong lời nói và âm nhạc
- Phân tích các phân khúc cụ thể bằng dấu thời gian
Đối với các tương tác bằng giọng nói và video theo thời gian thực, hãy xem Live API. Đối với các mô hình chuyển lời nói thành văn bản chuyên dụng có hỗ trợ phiên âm theo thời gian thực, hãy sử dụng Google Cloud Speech-to-Text API.
Phiên âm lời nói thành văn bản
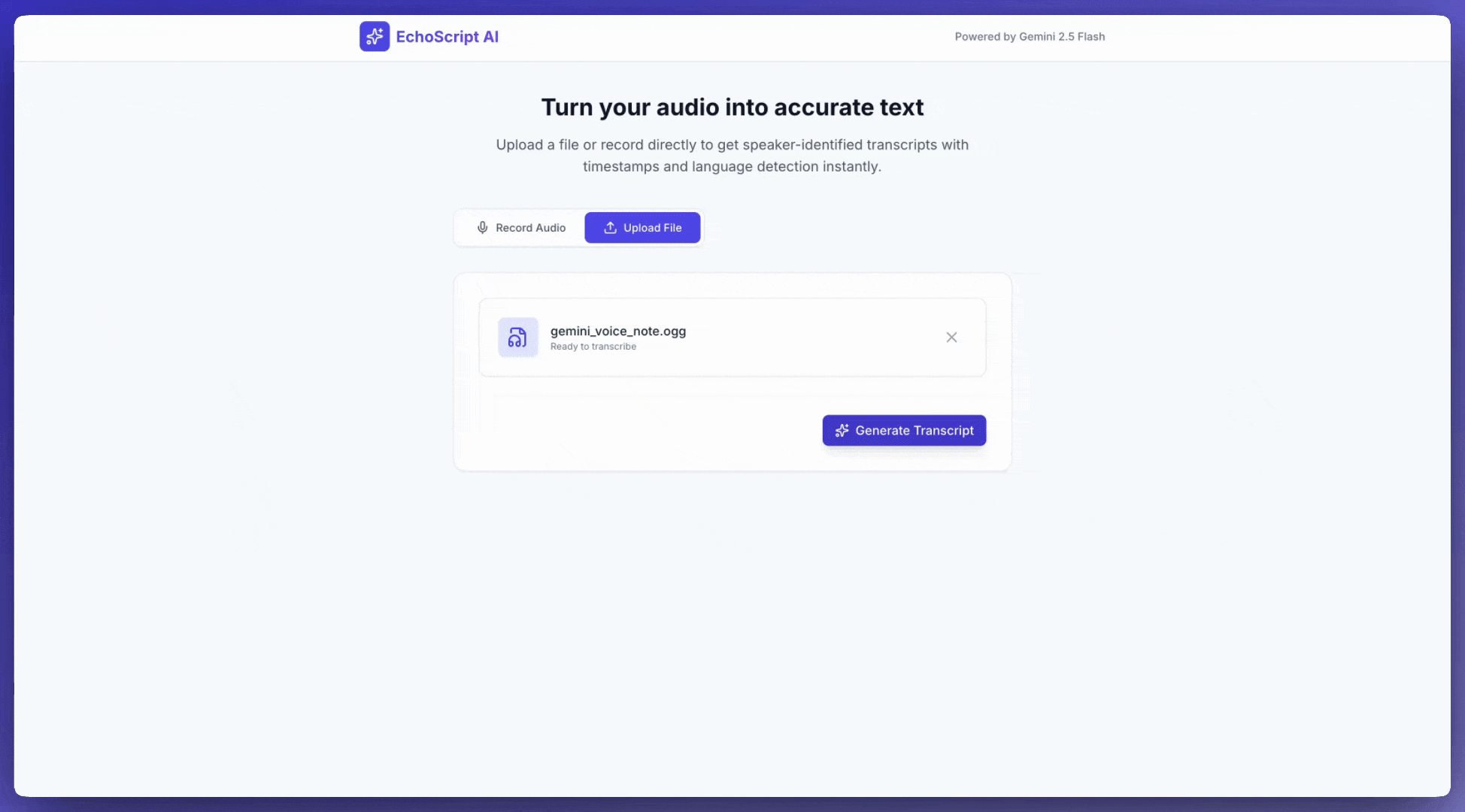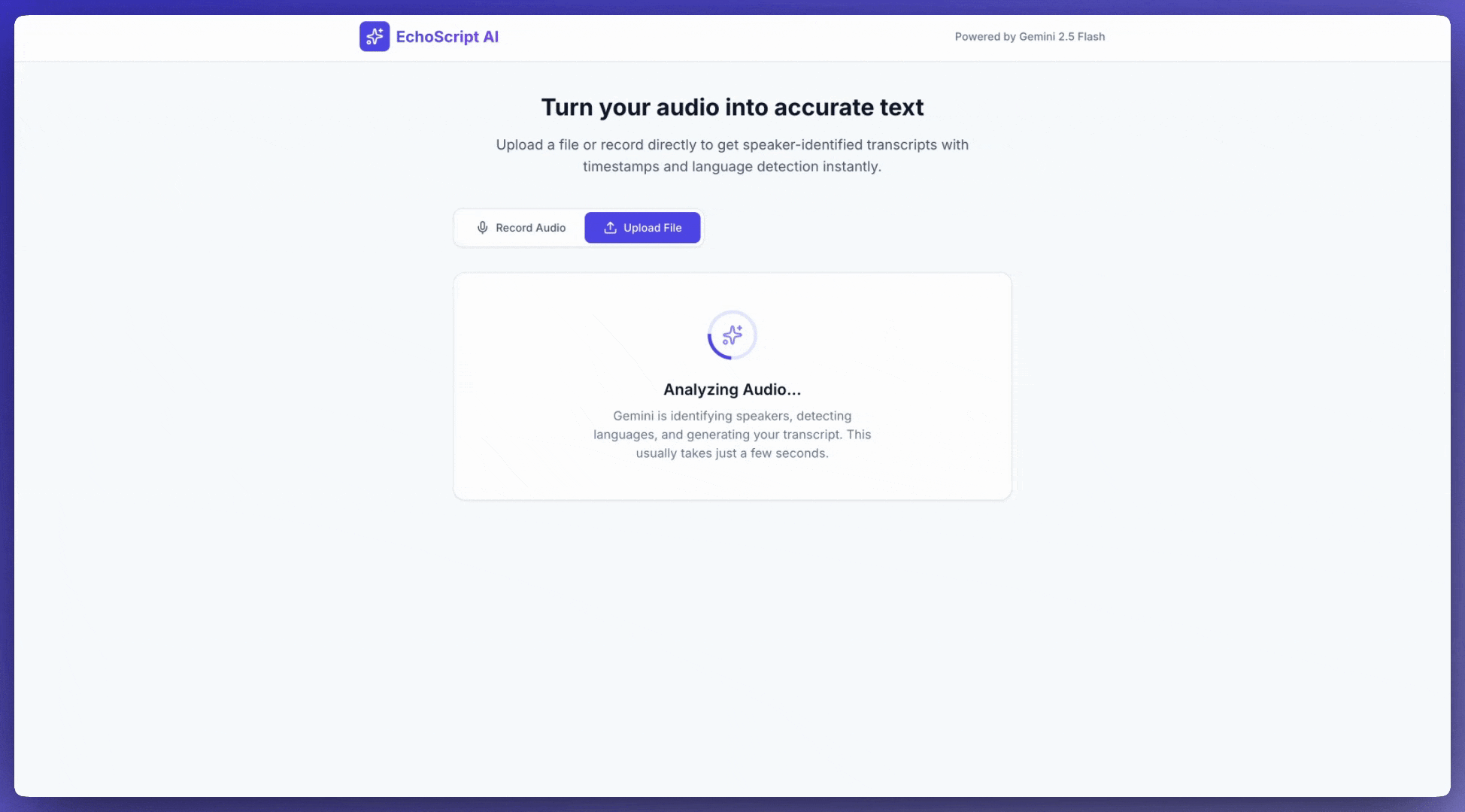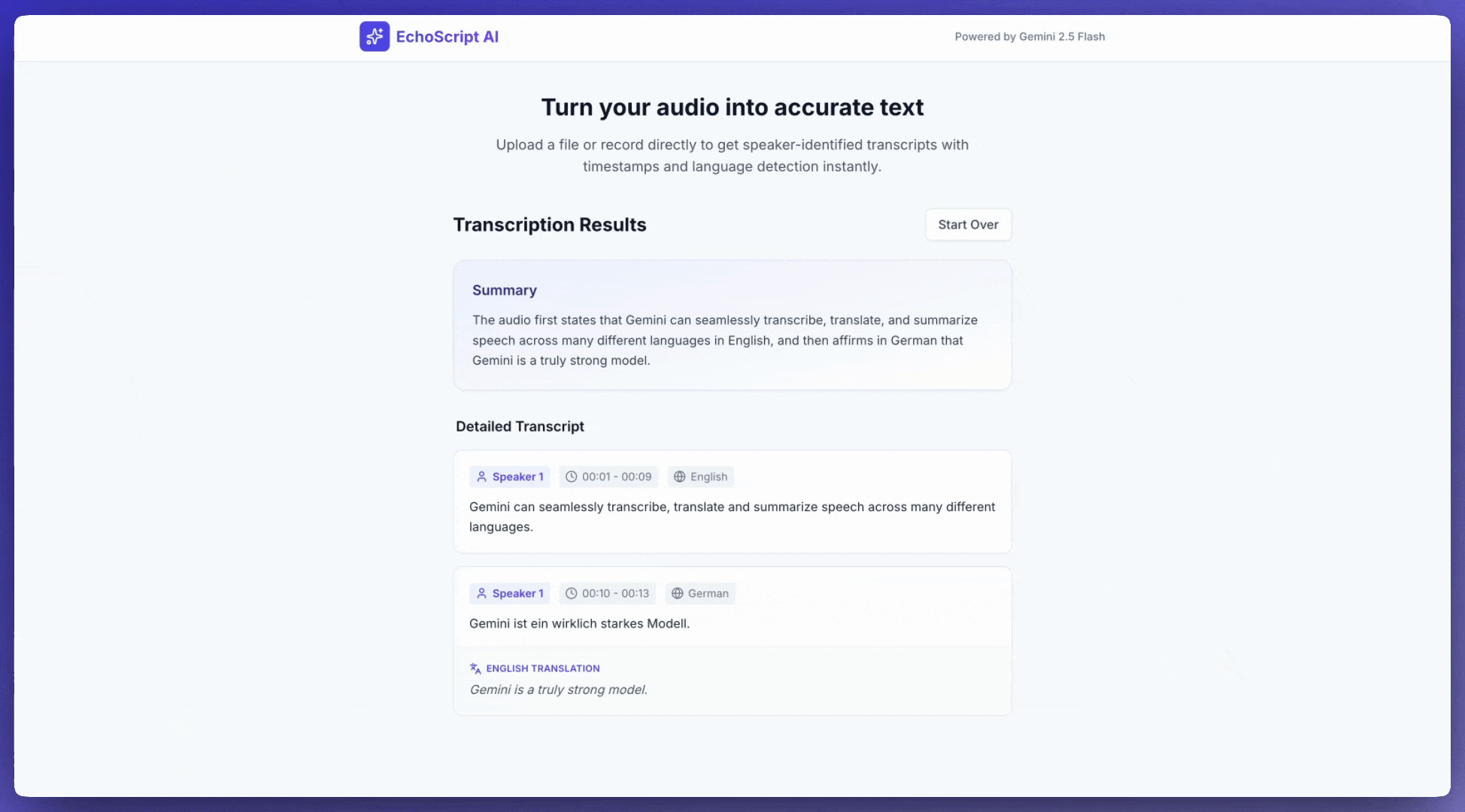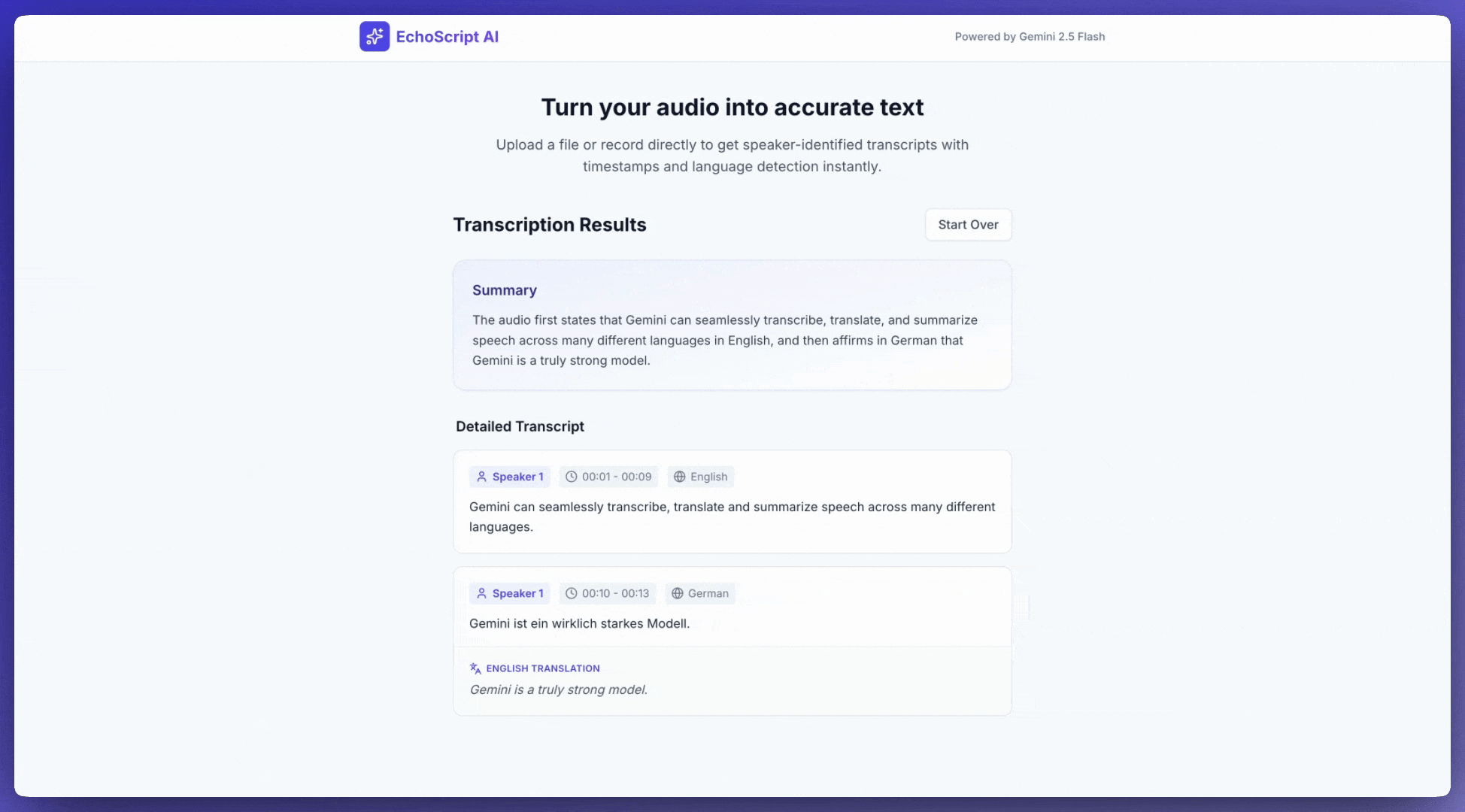
Ví dụ này cho thấy cách phiên âm, dịch và tóm tắt lời nói bằng dấu thời gian, phân tách người nói và phát hiện cảm xúc bằng cách sử dụng kết quả có cấu trúc.
Python
from google import genai
client = genai.Client()
YOUTUBE_URL = "https://www.youtube.com/watch?v=ku-N-eS1lgM"
prompt = """
Process the audio file and generate a detailed transcription.
Requirements:
1. Identify distinct speakers (e.g., Speaker 1, Speaker 2).
2. Provide accurate timestamps for each segment (Format: MM:SS).
3. Detect the primary language of each segment.
4. If not English, provide the English translation.
5. Identify the primary emotion: Happy, Sad, Angry, or Neutral.
6. Provide a brief summary at the beginning.
"""
response_schema = {
"type": "object",
"properties": {
"summary": {"type": "string"},
"segments": {
"type": "array",
"items": {
"type": "object",
"properties": {
"speaker": {"type": "string"},
"timestamp": {"type": "string"},
"content": {"type": "string"},
"language": {"type": "string"},
"emotion": {
"type": "string",
"enum": ["happy", "sad", "angry", "neutral"]
}
},
"required": ["speaker", "timestamp", "content", "emotion"]
}
}
},
"required": ["summary", "segments"]
}
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "video", "uri": YOUTUBE_URL, "mime_type": "video/mp4"},
{"type": "text", "text": prompt}
],
response_format=response_schema,
)
print(interaction.output_text)
JavaScript
import { GoogleGenAI } from "@google/genai";
const client = new GoogleGenAI({});
const YOUTUBE_URL = "https://www.youtube.com/watch?v=ku-N-eS1lgM";
const prompt = `
Process the audio file and generate a detailed transcription.
Requirements:
1. Identify distinct speakers (e.g., Speaker 1, Speaker 2).
2. Provide accurate timestamps for each segment (Format: MM:SS).
3. Detect the primary language of each segment.
4. If not English, provide the English translation.
5. Identify the primary emotion: Happy, Sad, Angry, or Neutral.
6. Provide a brief summary at the beginning.
`;
const responseSchema = {
type: "object",
properties: {
summary: { type: "string" },
segments: {
type: "array",
items: {
type: "object",
properties: {
speaker: { type: "string" },
timestamp: { type: "string" },
content: { type: "string" },
language: { type: "string" },
emotion: {
type: "string",
enum: ["happy", "sad", "angry", "neutral"]
}
},
required: ["speaker", "timestamp", "content", "emotion"]
}
}
},
required: ["summary", "segments"]
};
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{ type: "video", uri: YOUTUBE_URL, mime_type: "video/mp4" },
{ type: "text", text: prompt }
],
response_format: responseSchema,
});
console.log(JSON.parse(interaction.output_text));
REST
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"input": [
{
"type": "video",
"uri": "https://www.youtube.com/watch?v=ku-N-eS1lgM",
"mime_type": "video/mp4"
},
{
"type": "text",
"text": "Transcribe with speaker diarization and emotion detection."
}
],
"response_format": {
"type": "object",
"properties": {
"summary": {"type": "string"},
"segments": {
"type": "array",
"items": {
"type": "object",
"properties": {
"speaker": {"type": "string"},
"timestamp": {"type": "string"},
"content": {"type": "string"},
"emotion": {"type": "string", "enum": ["happy", "sad", "angry", "neutral"]}
}
}
}
}
}
}'
Nhập âm thanh
Bạn có thể cung cấp dữ liệu âm thanh theo những cách sau:
- Tải tệp âm thanh lên trước khi đưa ra yêu cầu.
- Truyền dữ liệu âm thanh cùng dòng với yêu cầu.
Tải tệp âm thanh lên
Sử dụng Files API cho các tệp lớn hơn 20 MB.
Python
from google import genai
client = genai.Client()
uploaded_file = client.files.upload(file="path/to/sample.mp3")
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "text", "text": "Describe this audio clip"},
{
"type": "audio",
"uri": uploaded_file.uri,
"mime_type": uploaded_file.mime_type
}
]
)
print(interaction.output_text)
JavaScript
import { GoogleGenAI } from "@google/genai";
const client = new GoogleGenAI({});
const uploadedFile = await client.files.upload({
file: "path/to/sample.mp3",
config: { mimeType: "audio/mp3" }
});
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{type: "text", text: "Describe this audio clip"},
{
type: "audio",
uri: uploadedFile.uri,
mime_type: uploadedFile.mimeType
}
]
});
console.log(interaction.output_text);
REST
# First upload the file using the Files API, then use the URI:
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"input": [
{"type": "text", "text": "Describe this audio clip"},
{
"type": "audio",
"uri": "YOUR_FILE_URI",
"mime_type": "audio/mp3"
}
]
}'
Truyền dữ liệu âm thanh cùng dòng
Đối với các tệp âm thanh nhỏ có tổng kích thước yêu cầu dưới 20 MB:
Python
from google import genai
import base64
client = genai.Client()
with open('path/to/small-sample.mp3', 'rb') as f:
audio_bytes = f.read()
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "text", "text": "Describe this audio clip"},
{
"type": "audio",
"data": base64.b64encode(audio_bytes).decode('utf-8'),
"mime_type": "audio/mp3"
}
]
)
print(interaction.output_text)
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
const client = new GoogleGenAI({});
const audioData = fs.readFileSync("path/to/small-sample.mp3", {
encoding: "base64"
});
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{type: "text", text: "Describe this audio clip"},
{
type: "audio",
data: audioData,
mime_type: "audio/mp3"
}
]
});
console.log(interaction.output_text);
REST
AUDIO_PATH="path/to/sample.mp3"
if [[ "$(base64 --version 2>&1)" = *"FreeBSD"* ]]; then
B64FLAGS="--input"
else
B64FLAGS="-w0"
fi
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"input": [
{"type": "text", "text": "Describe this audio clip"},
{
"type": "audio",
"data": "'$(base64 $B64FLAGS $AUDIO_PATH)'",
"mime_type": "audio/mp3"
}
]
}'
Lưu ý về dữ liệu âm thanh cùng dòng: * Kích thước yêu cầu tối đa là 20 MB (bao gồm cả lời nhắc và tất cả các tệp) * Để sử dụng lại, hãy tải tệp lên
Lấy bản chép lời
Để lấy bản chép lời, hãy yêu cầu trong lời nhắc:
Python
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "text", "text": "Generate a transcript of the speech."},
{
"type": "audio",
"uri": uploaded_file.uri,
"mime_type": uploaded_file.mime_type
}
]
)
print(interaction.output_text)
JavaScript
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{ type: "text", text: "Generate a transcript of the speech." },
{
type: "audio",
uri: uploadedFile.uri,
mime_type: uploadedFile.mimeType
}
]
});
console.log(interaction.output_text);
Tham khảo dấu thời gian
Sử dụng định dạng MM:SS để tham chiếu đến các phần cụ thể:
Python
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "text", "text": "Provide a transcript from 02:30 to 03:29."},
{
"type": "audio",
"uri": uploaded_file.uri,
"mime_type": uploaded_file.mime_type
}
]
)
JavaScript
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{ type: "text", text: "Provide a transcript from 02:30 to 03:29." },
{ type: "audio", uri: uploadedFile.uri, mime_type: "audio/mp3" }
]
});
Đếm token
Đếm token trong tệp âm thanh:
Python
response = client.models.count_tokens(
model="gemini-3.5-flash",
contents=[uploaded_file]
)
print(response)
JavaScript
const response = await client.models.countTokens({
model: "gemini-3.5-flash",
contents: [
{ fileData: { fileUri: uploadedFile.uri, mimeType: uploadedFile.mimeType } }
]
});
console.log(response.totalTokens);
Định dạng âm thanh được hỗ trợ
- WAV –
audio/wav - MP3 –
audio/mp3 - AIFF –
audio/aiff - AAC –
audio/aac - OGG Vorbis –
audio/ogg - FLAC –
audio/flac
Thông tin kỹ thuật về âm thanh
- Token: 32 token/giây âm thanh (1 phút = 1.920 token)
- Âm thanh không phải lời nói: Gemini hiểu được âm thanh không phải lời nói (tiếng chim hót, tiếng còi báo động, v.v.)
- Thời lượng tối đa: 9,5 giờ âm thanh/lời nhắc
- Độ phân giải: Giảm xuống còn 16 Kbps
- Kênh: Âm thanh đa kênh kết hợp thành một kênh
Bước tiếp theo
- Files API: Tải tệp âm thanh lên và quản lý tệp âm thanh
- Hướng dẫn về hệ thống: Tuỳ chỉnh hành vi của mô hình
- Kết quả có cấu trúc: Nhận kết quả phiên âm ở định dạng JSON