L'API Gemini fornisce uno strumento di esecuzione del codice che consente al modello di generare ed eseguire codice Python. Il modello può quindi apprendere in modo iterativo dai risultati dell'esecuzione del codice fino a raggiungere un output finale. Puoi utilizzare l'esecuzione del codice per creare applicazioni che sfruttano il ragionamento basato sul codice. Ad esempio, puoi utilizzare l'esecuzione del codice per risolvere equazioni o elaborare testo. Puoi anche utilizzare le librerie incluse nell'ambiente di esecuzione del codice per eseguire attività più specializzate.
Gemini è in grado di eseguire codice solo in Python. Puoi comunque chiedere a Gemini di generare codice in un'altra lingua, ma il modello non può utilizzare lo strumento di esecuzione del codice per eseguirlo.
Abilitare l'esecuzione del codice
Per abilitare l'esecuzione del codice, configura lo strumento di esecuzione del codice sul modello. In questo modo, il modello può generare ed eseguire codice.
Python
from google import genai
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="What is the sum of the first 50 prime numbers? "
"Generate and run code for the calculation, and make sure you get all 50.",
tools=[{"type": "code_execution"}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif step.type == "code_execution_call":
print(step.arguments.code)
elif step.type == "code_execution_result":
print(step.result)
JavaScript
import { GoogleGenAI } from "@google/genai";
const client = new GoogleGenAI({});
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: "What is the sum of the first 50 prime numbers? " +
"Generate and run code for the calculation, and make sure you get all 50.",
tools: [{ type: "code_execution" }]
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
}
}
} else if (step.type === "code_execution_call") {
console.log(step.arguments.code);
} else if (step.type === "code_execution_result") {
console.log(step.result);
}
}
REST
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"input": "What is the sum of the first 50 prime numbers? Generate and run code for the calculation, and make sure you get all 50.",
"tools": [{"type": "code_execution"}]
}'
L'output potrebbe essere simile al seguente, formattato per una maggiore leggibilità:
Okay, I need to calculate the sum of the first 50 prime numbers. Here's how I'll
approach this:
1. **Generate Prime Numbers:** I'll use an iterative method to find prime
numbers. I'll start with 2 and check if each subsequent number is divisible
by any number between 2 and its square root. If not, it's a prime.
2. **Store Primes:** I'll store the prime numbers in a list until I have 50 of
them.
3. **Calculate the Sum:** Finally, I'll sum the prime numbers in the list.
Here's the Python code to do this:
def is_prime(n):
"""Efficiently checks if a number is prime."""
if n <= 1:
return False
if n <= 3:
return True
if n % 2 == 0 or n % 3 == 0:
return False
i = 5
while i * i <= n:
if n % i == 0 or n % (i + 2) == 0:
return False
i += 6
return True
primes = []
num = 2
while len(primes) < 50:
if is_prime(num):
primes.append(num)
num += 1
sum_of_primes = sum(primes)
print(f'{primes=}')
print(f'{sum_of_primes=}')
primes=[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67,
71, 73, 79, 83, 89, 97, 101, 103, 107, 109, 113, 127, 131, 137, 139, 149, 151,
157, 163, 167, 173, 179, 181, 191, 193, 197, 199, 211, 223, 227, 229]
sum_of_primes=5117
The sum of the first 50 prime numbers is 5117.
Questo output combina diverse parti di contenuti restituite dal modello quando si utilizza l'esecuzione del codice:
text: testo in linea generato dal modellocode_execution_call: codice generato dal modello che deve essere eseguitocode_execution_result: risultato del codice eseguibile
Esecuzione del codice con le immagini (Gemini 3)
Il modello Gemini 3 Flash ora può scrivere ed eseguire codice Python per manipolare e ispezionare attivamente le immagini.
Casi d'uso
- Zoom e ispezione: il modello rileva implicitamente quando i dettagli sono troppo piccoli (ad es. la lettura di un indicatore distante) e scrive codice per ritagliare e riesaminare l'area a una risoluzione più elevata.
- Matematica visiva: il modello può eseguire calcoli in più passaggi utilizzando il codice (ad es. la somma delle voci di riga in una ricevuta).
- Annotazione delle immagini: il modello può annotare le immagini per rispondere alle domande, ad esempio disegnando frecce per mostrare le relazioni.
Abilitare l'esecuzione del codice con le immagini
L'esecuzione del codice con le immagini è supportata ufficialmente in Gemini 3 Flash. Puoi attivare questo comportamento abilitando sia l'esecuzione del codice come strumento sia il ragionamento.
Python
from google import genai
import requests
import base64
from PIL import Image
import io
image_path = "https://goo.gle/instrument-img"
image_bytes = requests.get(image_path).content
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "image", "data": base64.b64encode(image_bytes).decode('utf-8'), "mime_type": "image/jpeg"},
{"type": "text", "text": "Zoom into the expression pedals and tell me how many pedals are there?"}
],
tools=[{"type": "code_execution"}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
img = Image.open(io.BytesIO(base64.b64decode(content_block.data)))
img.show() # or: img.save("output_image.jpg")
elif step.type == "code_execution_call":
print(step.arguments.code)
elif step.type == "code_execution_result":
print(step.result)
JavaScript
import { GoogleGenAI } from "@google/genai";
async function main() {
const client = new GoogleGenAI({});
const imageUrl = "https://goo.gle/instrument-img";
const response = await fetch(imageUrl);
const imageArrayBuffer = await response.arrayBuffer();
const base64ImageData = Buffer.from(imageArrayBuffer).toString('base64');
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{
type: "image",
data: base64ImageData,
mime_type: "image/jpeg"
},
{ type: "text", text: "Zoom into the expression pedals and tell me how many pedals are there?" }
],
tools: [{ type: "code_execution" }]
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log("Text:", contentBlock.text);
}
}
} else if (step.type === "code_execution_call") {
console.log(`\nGenerated Code:\n`, step.arguments.code);
} else if (step.type === "code_execution_result") {
console.log(`\nExecution Output:\n`, step.result);
}
}
}
main();
REST
IMG_URL="https://goo.gle/instrument-img"
MODEL="gemini-3.5-flash"
MIME_TYPE=$(curl -sIL "$IMG_URL" | grep -i '^content-type:' | awk -F ': ' '{print $2}' | sed 's/\r$//' | head -n 1)
if [[ -z "$MIME_TYPE" || ! "$MIME_TYPE" == image/* ]]; then
MIME_TYPE="image/jpeg"
fi
if [[ "$(uname)" == "Darwin" ]]; then
IMAGE_B64=$(curl -sL "$IMG_URL" | base64 -b 0)
elif [[ "$(base64 --version 2>&1)" = *"FreeBSD"* ]]; then
IMAGE_B64=$(curl -sL "$IMG_URL" | base64)
else
IMAGE_B64=$(curl -sL "$IMG_URL" | base64 -w0)
fi
# Use jq to create the JSON payload to avoid "Argument list too long" error with large base64 strings
echo -n "$IMAGE_B64" > image_b64.txt
jq -n \
--rawfile b64 image_b64.txt \
--arg mime "$MIME_TYPE" \
'{
model: "gemini-3.5-flash",
input: [
{type: "image", data: $b64, mime_type: $mime},
{type: "text", text: "Zoom into the expression pedals and tell me how many pedals are there?"}
],
tools: [{type: "code_execution"}]
}' > payload.json
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d @payload.json
Utilizzare l'esecuzione del codice nelle interazioni in più passaggi
Puoi anche utilizzare l'esecuzione del codice nell'ambito di una conversazione in più passaggi utilizzando previous_interaction_id.
Python
from google import genai
client = genai.Client()
interaction1 = client.interactions.create(
model="gemini-3.5-flash",
input="I have a math question for you.",
tools=[{"type": "code_execution"}]
)
print(interaction1.output_text)
interaction2 = client.interactions.create(
model="gemini-3.5-flash",
previous_interaction_id=interaction1.id,
input="What is the sum of the first 50 prime numbers? "
"Generate and run code for the calculation, and make sure you get all 50.",
tools=[{"type": "code_execution"}]
)
for step in interaction2.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif step.type == "code_execution_call":
print(step.arguments.code)
elif step.type == "code_execution_result":
print(step.result)
JavaScript
import { GoogleGenAI } from "@google/genai";
const client = new GoogleGenAI({});
const interaction1 = await client.interactions.create({
model: "gemini-3.5-flash",
input: "I have a math question for you.",
tools: [{ type: "code_execution" }]
});
console.log(interaction1.output_text);
const interaction2 = await client.interactions.create({
model: "gemini-3.5-flash",
previous_interaction_id: interaction1.id,
input: "What is the sum of the first 50 prime numbers? " +
"Generate and run code for the calculation, and make sure you get all 50.",
tools: [{ type: "code_execution" }]
});
for (const step of interaction2.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
}
}
} else if (step.type === "code_execution_call") {
console.log(step.arguments.code);
} else if (step.type === "code_execution_result") {
console.log(step.result);
}
}
REST
# First turn
RESPONSE1=$(curl -s -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"input": "I have a math question for you.",
"tools": [{"type": "code_execution"}]
}')
INTERACTION_ID=$(echo $RESPONSE1 | jq -r '.id')
# Second turn with previous_interaction_id
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"previous_interaction_id": "'"$INTERACTION_ID"'",
"input": "What is the sum of the first 50 prime numbers? Generate and run code for the calculation, and make sure you get all 50.",
"tools": [{"type": "code_execution"}]
}'
Input/output (I/O)
Nei modelli Gemini attuali, come Gemini 3.5 Flash, l'esecuzione del codice supporta l'input di file e l'output di grafici. Utilizzando queste funzionalità di input e output , puoi caricare file CSV e di testo, porre domande sui file e generare grafici Matplotlib come parte della risposta. I file di output vengono restituiti come immagini in linea nella risposta.
Prezzi di I/O
Quando utilizzi l'I/O di esecuzione del codice, ti vengono addebitati i token di input e i token di output:
Token di input:
- Prompt dell'utente
Token di output:
- Codice generato dal modello
- Output di esecuzione del codice nell'ambiente di codice
- Token di ragionamento
- Riepilogo generato dal modello
Dettagli di I/O
Quando lavori con l'I/O di esecuzione del codice, tieni presente i seguenti dettagli tecnici:
- Il runtime massimo dell'ambiente di codice è di 30 secondi.
- Se l'ambiente di codice genera un errore, il modello potrebbe decidere di rigenerare l'output del codice. Questa operazione può essere eseguita fino a 5 volte.
- La dimensione massima del file di input è limitata dalla finestra dei token del modello. Se carichi un file che supera la finestra di contesto massima del modello, l'API restituirà un errore.
- L'esecuzione del codice funziona meglio con file di testo e CSV.
- Il file di input può essere passato come dati in linea o caricato utilizzando l' API Files, mentre il file di output viene sempre restituito come dati in linea.
Fatturazione
Non sono previsti costi aggiuntivi per l'abilitazione dell'esecuzione del codice dall'API Gemini. Ti verrà addebitata la tariffa corrente dei token di input e output in base al modello Gemini che stai utilizzando.
Ecco alcuni altri aspetti da sapere sulla fatturazione per l'esecuzione del codice:
- Ti viene addebitato un solo costo per i token di input che passi al modello e ti vengono addebitati i token di output finali restituiti dal modello.
- I token che rappresentano il codice generato vengono conteggiati come token di output. Il codice generato può includere testo e output multimodale come le immagini.
- Anche i risultati dell'esecuzione del codice vengono conteggiati come token di output.
Il modello di fatturazione è mostrato nel seguente diagramma:
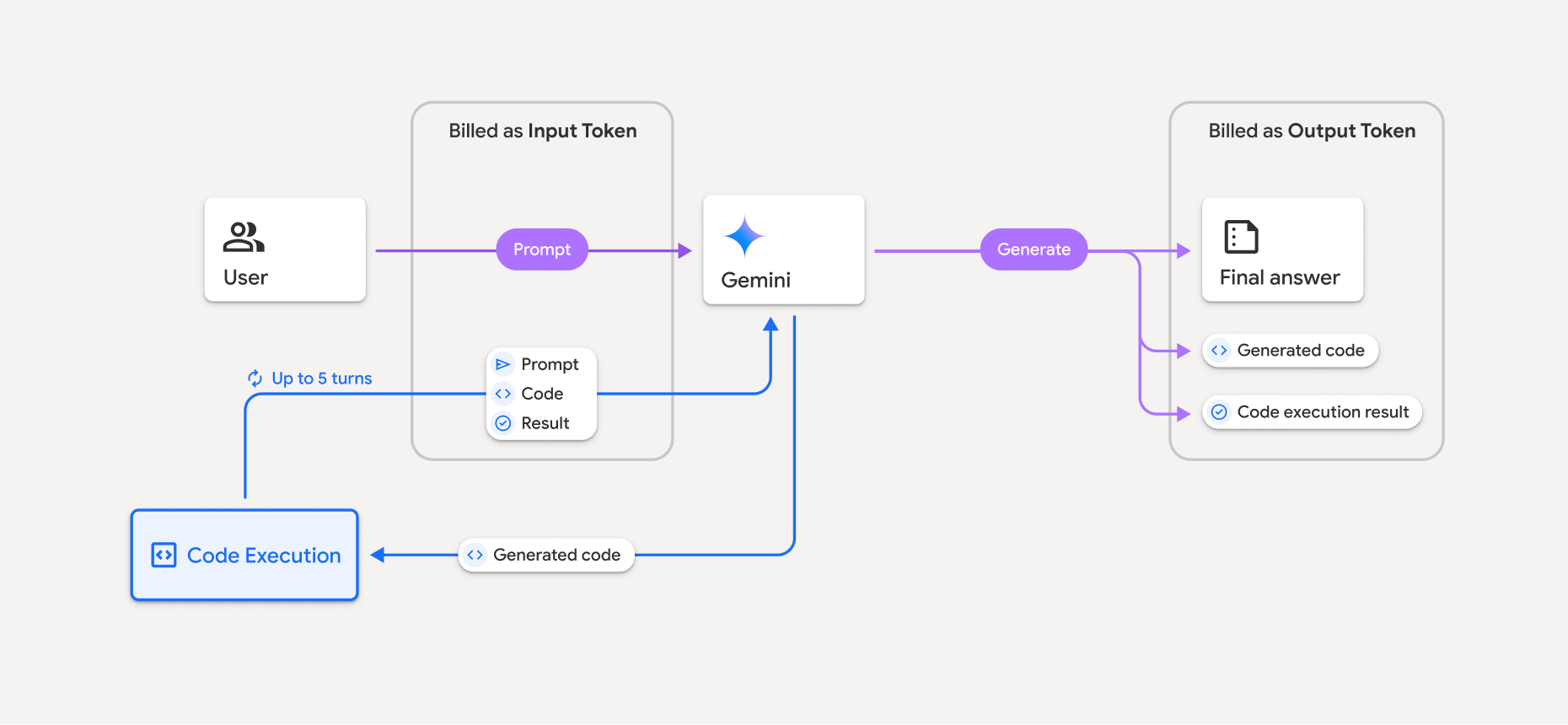
- Ti verrà addebitata la tariffa corrente dei token di input e output in base al modello Gemini che stai utilizzando.
- Se Gemini utilizza l'esecuzione del codice durante la generazione della risposta, il prompt originale, il codice generato e il risultato del codice eseguito vengono etichettati come token intermedi e vengono fatturati come token di input.
- Gemini genera quindi un riepilogo e restituisce il codice generato, il risultato del codice eseguito e il riepilogo finale. Questi vengono fatturati come token di output.
- L'API Gemini include un conteggio dei token intermedi nella risposta dell'API, in modo da sapere perché ricevi token di input aggiuntivi oltre al prompt iniziale.
Limitazioni
- Il modello può solo generare ed eseguire codice. Non può restituire altri artefatti come i file multimediali.
- In alcuni casi, l'abilitazione dell'esecuzione del codice può comportare regressioni in altre aree dell'output del modello (ad esempio, la scrittura di una storia).
- Esiste una certa variazione nella capacità dei diversi modelli di utilizzare l'esecuzione del codice con successo.
Combinazioni di strumenti supportate
Lo strumento di esecuzione del codice può essere combinato con il grounding con la Ricerca Google per supportare casi d'uso più complessi.
I modelli Gemini 3 supportano la combinazione di strumenti integrati (come l'esecuzione del codice) con strumenti personalizzati (chiamata di funzione).
Librerie supportate
L'ambiente di esecuzione del codice include le seguenti librerie:
- attrs
- chess
- contourpy
- fpdf
- geopandas
- imageio
- jinja2
- joblib
- jsonschema
- jsonschema-specifications
- lxml
- matplotlib
- mpmath
- numpy
- opencv-python
- openpyxl
- packaging
- pandas
- pillow
- protobuf
- pylatex
- pyparsing
- PyPDF2
- python-dateutil
- python-docx
- python-pptx
- reportlab
- scikit-learn
- scipy
- seaborn
- six
- striprtf
- sympy
- tabulate
- tensorflow
- toolz
- xlrd
Non puoi installare le tue librerie.
Passaggi successivi
- Prova la guida rapida dell'API Interactions.
- Scopri di più sugli altri strumenti dell'API Gemini: