La API de Gemini proporciona una herramienta de ejecución de código que permite que el modelo genere y ejecute código de Python. Luego, el modelo puede aprender de forma iterativa a partir de los resultados de la ejecución de código hasta llegar a un resultado final. Puedes usar la ejecución de código para crear aplicaciones que se beneficien del razonamiento basado en código. Por ejemplo, puedes usar la ejecución de código para resolver ecuaciones o procesar texto. También puedes usar las bibliotecas incluidas en el entorno de ejecución de código para realizar tareas más especializadas.
Gemini solo puede ejecutar código en Python. Aun así, puedes pedirle a Gemini que genere código en otro lenguaje, pero el modelo no puede usar la herramienta de ejecución de código para ejecutarlo.
Habilita la ejecución de código
Para habilitar la ejecución de código, configura la herramienta de ejecución de código en el modelo. Esto permite que el modelo genere y ejecute código.
Python
from google import genai
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="What is the sum of the first 50 prime numbers? "
"Generate and run code for the calculation, and make sure you get all 50.",
tools=[{"type": "code_execution"}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif step.type == "code_execution_call":
print(step.arguments.code)
elif step.type == "code_execution_result":
print(step.result)
JavaScript
import { GoogleGenAI } from "@google/genai";
const client = new GoogleGenAI({});
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: "What is the sum of the first 50 prime numbers? " +
"Generate and run code for the calculation, and make sure you get all 50.",
tools: [{ type: "code_execution" }]
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
}
}
} else if (step.type === "code_execution_call") {
console.log(step.arguments.code);
} else if (step.type === "code_execution_result") {
console.log(step.result);
}
}
REST
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"input": "What is the sum of the first 50 prime numbers? Generate and run code for the calculation, and make sure you get all 50.",
"tools": [{"type": "code_execution"}]
}'
El resultado podría verse de la siguiente manera, que se formateó para facilitar la lectura:
Okay, I need to calculate the sum of the first 50 prime numbers. Here's how I'll
approach this:
1. **Generate Prime Numbers:** I'll use an iterative method to find prime
numbers. I'll start with 2 and check if each subsequent number is divisible
by any number between 2 and its square root. If not, it's a prime.
2. **Store Primes:** I'll store the prime numbers in a list until I have 50 of
them.
3. **Calculate the Sum:** Finally, I'll sum the prime numbers in the list.
Here's the Python code to do this:
def is_prime(n):
"""Efficiently checks if a number is prime."""
if n <= 1:
return False
if n <= 3:
return True
if n % 2 == 0 or n % 3 == 0:
return False
i = 5
while i * i <= n:
if n % i == 0 or n % (i + 2) == 0:
return False
i += 6
return True
primes = []
num = 2
while len(primes) < 50:
if is_prime(num):
primes.append(num)
num += 1
sum_of_primes = sum(primes)
print(f'{primes=}')
print(f'{sum_of_primes=}')
primes=[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67,
71, 73, 79, 83, 89, 97, 101, 103, 107, 109, 113, 127, 131, 137, 139, 149, 151,
157, 163, 167, 173, 179, 181, 191, 193, 197, 199, 211, 223, 227, 229]
sum_of_primes=5117
The sum of the first 50 prime numbers is 5117.
Este resultado combina varias partes de contenido que el modelo muestra cuando se usa la ejecución de código:
text: Texto intercalado generado por el modelocode_execution_call: Código generado por el modelo que se debe ejecutarcode_execution_result: Resultado del código ejecutable
Ejecución de código con imágenes (Gemini 3)
El modelo Gemini 3 Flash ahora puede escribir y ejecutar código de Python para manipular e inspeccionar imágenes de forma activa.
Casos de uso
- Acercar e inspeccionar: El modelo detecta de forma implícita cuando los detalles son demasiado pequeños (p.ej., leer un indicador distante) y escribe código para recortar y volver a examinar el área con una resolución más alta.
- Matemáticas visuales: El modelo puede ejecutar cálculos de varios pasos con código (p.ej., sumar los artículos de una factura).
- Anotación de imágenes: El modelo puede anotar imágenes para responder preguntas, como dibujar flechas para mostrar relaciones.
Habilita la ejecución de código con imágenes
La ejecución de código con imágenes se admite oficialmente en Gemini 3 Flash. Para activar este comportamiento, habilita la ejecución de código como una herramienta y el pensamiento.
Python
from google import genai
import requests
import base64
from PIL import Image
import io
image_path = "https://goo.gle/instrument-img"
image_bytes = requests.get(image_path).content
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "image", "data": base64.b64encode(image_bytes).decode('\utf-8'), "mime_type": "image/jpeg"},
{"type": "text", "text": "Zoom into the expression pedals and tell me how many pedals are there?"}
],
tools=[{"type": "code_execution"}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
display(Image.open(io.BytesIO(base64.b64decode(content_block.data))))
elif step.type == "code_execution_call":
print(step.arguments.code)
elif step.type == "code_execution_result":
print(step.result)
JavaScript
import { GoogleGenAI } from "@google/genai";
async function main() {
const client = new GoogleGenAI({});
const imageUrl = "https://goo.gle/instrument-img";
const response = await fetch(imageUrl);
const imageArrayBuffer = await response.arrayBuffer();
const base64ImageData = Buffer.from(imageArrayBuffer).toString('base64');
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{
type: "image",
data: base64ImageData,
mime_type: "image/jpeg"
},
{ type: "text", text: "Zoom into the expression pedals and tell me how many pedals are there?" }
],
tools: [{ type: "code_execution" }]
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log("Text:", contentBlock.text);
}
}
} else if (step.type === "code_execution_call") {
console.log(`\nGenerated Code:\n`, step.arguments.code);
} else if (step.type === "code_execution_result") {
console.log(`\nExecution Output:\n`, step.result);
}
}
}
main();
REST
IMG_URL="https://goo.gle/instrument-img"
MODEL="gemini-3.5-flash"
MIME_TYPE=$(curl -sIL "$IMG_URL" | grep -i '^content-type:' | awk -F ': ' '{print $2}' | sed 's/\r$//' | head -n 1)
if [[ -z "$MIME_TYPE" || ! "$MIME_TYPE" == image/* ]]; then
MIME_TYPE="image/jpeg"
fi
if [[ "$(uname)" == "Darwin" ]]; then
IMAGE_B64=$(curl -sL "$IMG_URL" | base64 -b 0)
elif [[ "$(base64 --version 2>&1)" = *"FreeBSD"* ]]; then
IMAGE_B64=$(curl -sL "$IMG_URL" | base64)
else
IMAGE_B64=$(curl -sL "$IMG_URL" | base64 -w0)
fi
# Use jq to create the JSON payload to avoid "Argument list too long" error with large base64 strings
echo -n "$IMAGE_B64" > image_b64.txt
jq -n \
--rawfile b64 image_b64.txt \
--arg mime "$MIME_TYPE" \
'{
model: "gemini-3.5-flash",
input: [
{type: "image", data: $b64, mime_type: $mime},
{type: "text", text: "Zoom into the expression pedals and tell me how many pedals are there?"}
],
tools: [{type: "code_execution"}]
}' > payload.json
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d @payload.json
Usa la ejecución de código en interacciones de varios turnos
También puedes usar la ejecución de código como parte de una conversación de varios turnos con previous_interaction_id.
Python
from google import genai
client = genai.Client()
interaction1 = client.interactions.create(
model="gemini-3.5-flash",
input="I have a math question for you.",
tools=[{"type": "code_execution"}]
)
print(interaction1.output_text)
interaction2 = client.interactions.create(
model="gemini-3.5-flash",
previous_interaction_id=interaction1.id,
input="What is the sum of the first 50 prime numbers? "
"Generate and run code for the calculation, and make sure you get all 50.",
tools=[{"type": "code_execution"}]
)
for step in interaction2.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif step.type == "code_execution_call":
print(step.arguments.code)
elif step.type == "code_execution_result":
print(step.result)
JavaScript
import { GoogleGenAI } from "@google/genai";
const client = new GoogleGenAI({});
const interaction1 = await client.interactions.create({
model: "gemini-3.5-flash",
input: "I have a math question for you.",
tools: [{ type: "code_execution" }]
});
console.log(interaction1.output_text);
const interaction2 = await client.interactions.create({
model: "gemini-3.5-flash",
previous_interaction_id: interaction1.id,
input: "What is the sum of the first 50 prime numbers? " +
"Generate and run code for the calculation, and make sure you get all 50.",
tools: [{ type: "code_execution" }]
});
for (const step of interaction2.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
}
}
} else if (step.type === "code_execution_call") {
console.log(step.arguments.code);
} else if (step.type === "code_execution_result") {
console.log(step.result);
}
}
REST
# First turn
RESPONSE1=$(curl -s -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"input": "I have a math question for you.",
"tools": [{"type": "code_execution"}]
}')
INTERACTION_ID=$(echo $RESPONSE1 | jq -r '.id')
# Second turn with previous_interaction_id
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"previous_interaction_id": "'"$INTERACTION_ID"'",
"input": "What is the sum of the first 50 prime numbers? Generate and run code for the calculation, and make sure you get all 50.",
"tools": [{"type": "code_execution"}]
}'
Entrada y salida (E/S)
A partir de Gemini 2.0 Flash, la ejecución de código admite la entrada de archivos y la salida de gráficos. Con estas capacidades de entrada y salida , puedes subir archivos CSV y de texto, hacer preguntas sobre los archivos y generar gráficos de Matplotlib como parte de la respuesta. Los archivos de salida se muestran como imágenes intercaladas en la respuesta.
Precios de E/S
Cuando usas la E/S de ejecución de código, se te cobra por los tokens de entrada y salida:
Tokens de entrada:
- Instrucción del usuario
Tokens de salida:
- Código generado por el modelo
- Resultado de la ejecución de código en el entorno de código
- Tokens de pensamiento
- Resumen generado por el modelo
Detalles de E/S
Cuando trabajes con la E/S de ejecución de código, ten en cuenta los siguientes detalles técnicos:
- El tiempo de ejecución máximo del entorno de código es de 30 segundos.
- Si el entorno de código genera un error, el modelo puede decidir volver a generar el resultado del código. Esto puede suceder hasta 5 veces.
- El tamaño máximo de entrada de archivos está limitado por la ventana de tokens del modelo. Si subes un archivo que supera la ventana de contexto máxima del modelo, la API mostrará un error.
- La ejecución de código funciona mejor con archivos de texto y CSV.
- El archivo de entrada se puede pasar como datos intercalados o subir con la API de Files, y el archivo de salida siempre se muestra como datos intercalados.
Facturación
No hay cargos adicionales por habilitar la ejecución de código desde la API de Gemini. Se te facturará según la tarifa actual de los tokens de entrada y salida en función del modelo de Gemini que uses.
Estos son algunos aspectos que debes tener en cuenta sobre la facturación de la ejecución de código:
- Solo se te factura una vez por los tokens de entrada que pasas al modelo, y se te factura por los tokens de salida finales que te muestra el modelo.
- Los tokens que representan el código generado se cuentan como tokens de salida. El código generado puede incluir texto y resultados multimodales, como imágenes.
- Los resultados de la ejecución de código también se cuentan como tokens de salida.
El modelo de facturación se muestra en el siguiente diagrama:
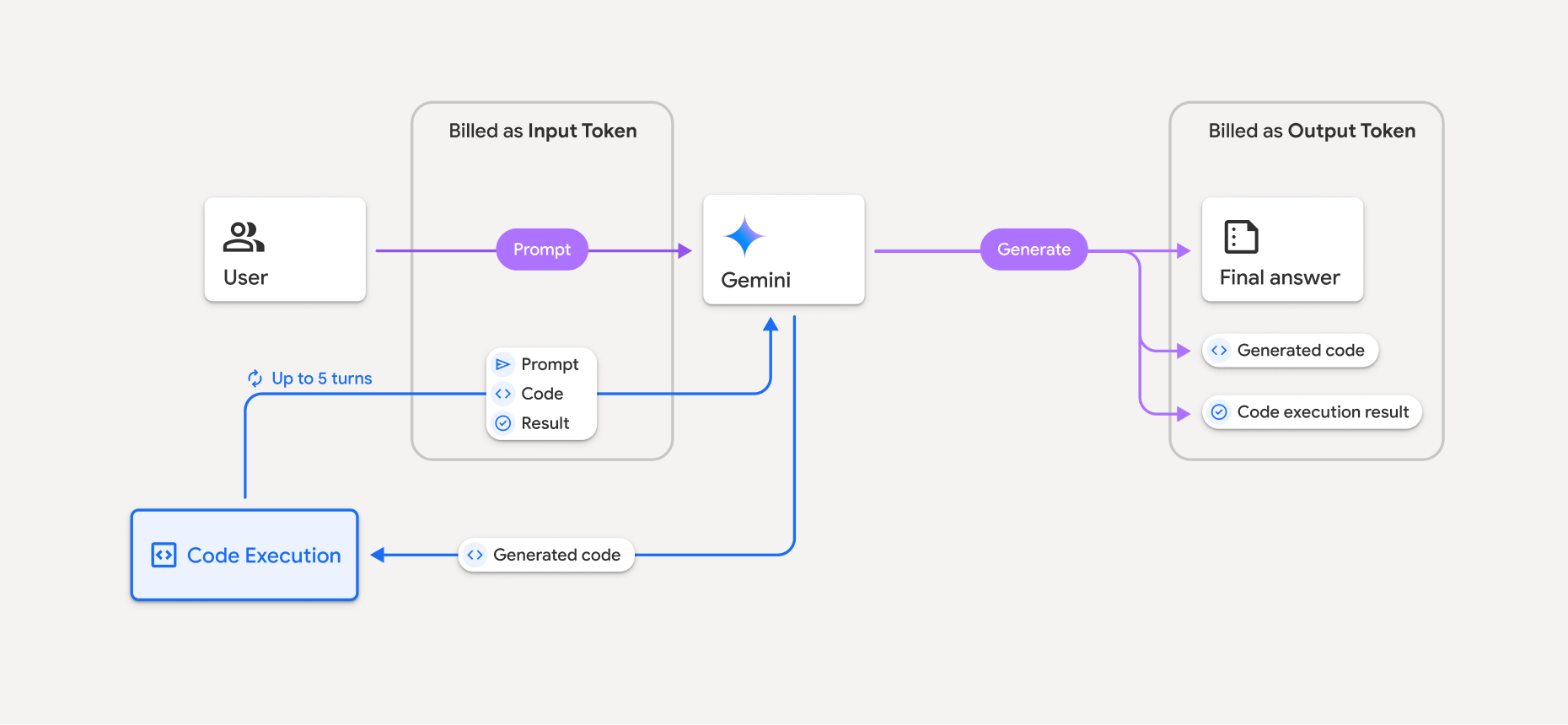
- Se te facturará según la tarifa actual de los tokens de entrada y salida en función del modelo de Gemini que uses.
- Si Gemini usa la ejecución de código cuando genera tu respuesta, la instrucción original, el código generado y el resultado del código ejecutado se etiquetan como tokens intermedios y se facturan como tokens de entrada.
- Luego, Gemini genera un resumen y muestra el código generado, el resultado del código ejecutado y el resumen final. Estos se facturan como tokens de salida.
- La API de Gemini incluye un recuento de tokens intermedios en la respuesta de la API, por lo que sabes por qué obtienes tokens de entrada adicionales más allá de tu instrucción inicial.
Limitaciones
- El modelo solo puede generar y ejecutar código. No puede mostrar otros artefactos, como archivos multimedia.
- En algunos casos, habilitar la ejecución de código puede provocar regresiones en otras áreas del resultado del modelo (por ejemplo, escribir una historia).
- Existe cierta variación en la capacidad de los diferentes modelos para usar la ejecución de código de forma correcta.
Combinaciones de herramientas compatibles
La herramienta de ejecución de código se puede combinar con Fundamentación con la Búsqueda de Google para potenciar casos de uso más complejos.
Los modelos de Gemini 3 admiten la combinación de herramientas integradas (como la ejecución de código) con herramientas personalizadas (llamadas a funciones).
Bibliotecas compatibles
El entorno de ejecución de código incluye las siguientes bibliotecas:
- attrs
- ajedrez
- contourpy
- fpdf
- geopandas
- imageio
- jinja2
- joblib
- jsonschema
- jsonschema-specifications
- lxml
- matplotlib
- mpmath
- numpy
- opencv-python
- openpyxl
- empaquetado
- pandas
- almohada
- protobuf
- pylatex
- pyparsing
- PyPDF2
- python-dateutil
- python-docx
- python-pptx
- reportlab
- scikit-learn
- scipy
- seaborn
- six
- striprtf
- sympy
- tabulate
- tensorflow
- toolz
- xlrd
No puedes instalar tus propias bibliotecas.
¿Qué sigue?
- Prueba
- Obtén información sobre otras herramientas de la API de Gemini: