
Gemini ファミリーの人工知能(AI)モデルは、テキスト、画像、音声など、さまざまな種類の入力データを処理するように構築されています。これらのモデルは複数の種類またはモードのデータを処理できるため、Gemini モデルはマルチモーダル モデルと呼ばれ、マルチモーダル機能を備えていると説明されます。
このページでは、Gemini API のプロンプトでメディア ファイルを使用する際のガイダンスとベスト プラクティスについて説明します。Gemini Files API を使用してメディア ファイルをアップロードし、プロンプトに含める方法については、Vision、音声、ドキュメント処理のガイドをご覧ください。
プロンプト付きのメディア ファイルを使用する
プロンプトでさまざまな種類のデータを使用できるため、Gemini API で対処できるタスクの柔軟性が向上します。たとえば、おいしい食事の写真をモデルに送信し、その食事に関する短いブログを作成するようモデルに依頼できます。
| プロンプト | レスポンス |
|
この写真に基づいて、魅力的な短いブログ投稿を書いてください。写真に写っている食事の説明と、私がミールプレップ(食事の作り置き)を始めた経緯について説明する必要があります。 
|
ミールプレップは、時間とお金の節約につながり、健康的な食生活にも役立ちます。この食事は、前もって簡単に準備できる、健康的でおいしい食事の良い例です。 この食事には、玄米、ロースト野菜、チキン照り焼きが含まれています。 玄米は健康的で複雑な炭水化物であり、持続的なエネルギーを供給します。ロースト野菜は、毎日のビタミンとミネラルを摂取するのに最適な方法です。チキン照りは、おいしくタンパク質が豊富なオプションです。 この食事は準備も簡単です。玄米を炊き、野菜を焼き、チキンの照り焼きを調理するだけです。すべて調理したら、食事準備用コンテナに分けて冷蔵庫に保存します。コンテナを手に入れて、忙しい朝を過ごしましょう。 事前に簡単に準備できる、健康的で美味しい食事をお探しなら、この食事は最適な選択肢です。栄養と風味に満ち溢れ、満腹感と満足感を味わえます。 健康的で美味しい食事作りをサポートします。 |
メディアによるプロンプトの戦略
メディア ファイルを使用するプロンプトから目的の出力を取得できない場合は、目的の結果を得るのに役立つ戦略がいくつかあります。以降のセクションでは、マルチモーダル入力を使用するプロンプトを改善するための設計アプローチとトラブルシューティングのヒントについて説明します。
マルチモーダル プロンプトは、次のベスト プラクティスに沿って改善できます。
-
プロンプト設計の基礎
- 指示を具体的にする: 誤解を招かないように明確で簡潔な指示を記述します。
- プロンプトにいくつかの例を加える: 現実的な数個の例を使用して実現したいことを示します。
- 小さいステップに分ける: 複雑なタスクを扱いやすい中間目標に分割して、プロセスに沿ってモデルを導きます。
- 出力形式を指定する: プロンプトで、必要とする形式(マークダウン、JSON、HTML など)で出力することを指示します。
- 単一画像のプロンプトではまず画像を配置する: Gemini は、画像とテキストの入力をどのような順序でも処理できますが、単一画像のプロンプトの場合は、対象の画像をテキストのプロンプトよりも前に配置することでパフォーマンスが向上する可能性があります。
-
マルチモーダル プロンプトのトラブルシューティング
- モデルが画像の該当箇所から情報を抽出していない場合: プロンプトで画像のどの部分から情報を引き出してほしいかについてのヒントを出してください。
- モデルの出力内容が一般的すぎる(画像に十分対応していない)場合: プロンプトの冒頭で、タスクの指示を出す前にモデルに画像について説明するよう求めるか、画像の内容に言及するよう求めてみてください。
プロンプト設計の基礎
このセクションでは、前のセクションで説明したベスト プラクティスについて詳しく説明します。
注: 次の Gemini の例のモデル結果は、実行ごとに異なる可能性があります。
指示を具体的にする
プロンプトは、明確かつ詳細である場合に最も良い結果が出ます。特定の出力を想定している場合は、必要な出力を確実に得られるように、その要件をプロンプトに含めることをおすすめします。
プロンプトのインテントは、作成したユーザーからは明確であるように見えても、実際には仕様上あいまいになっている場合があります。モデルの動作をカスタマイズするには、プロンプトがどのように(誤って)解釈されるかを考慮し、与えた指示が具体的で明確であることを確認してください。誤解の余地を最小限にする
下に示す空港の発着表示板の画像の場合、「この画像について説明する」ようにモデルにリクエストすると、漠然とした説明が生成される可能性があります。モデルによって画像から時刻と都市が抽出されることを必要とする場合は、そのリクエストをプロンプトに直接追加します。
| プロンプト | モデルのレスポンス |
|---|---|
 この画像を説明してください。 |
この画像は、空港の発着表示板を示しています。 |
| 更新されたプロンプト | 改善されたレスポンス |
|---|---|
この画像にある空港の発着表示板の時刻と都市を抽出してリストにしてください。 |
例をいくつか追加する
この Gemini モデルはさまざまな入力を受け付け、その入力を例として使用するとユーザーが必要とする出力を理解できます。こうした例を追加することでモデルがパターンを識別できるようになり、指定された画像とレスポンスの関係を新しい例に適用できます。これは「少数ショット」学習とも呼ばれます。
下の例では、最初の出力が文章形式で記述されており、国(ブラジル)も含まれています。別の形式やスタイルで出力し、国ではなく都市のみを出力したいとします。プロンプトに少数ショットの例を追加すると、モデルを意図したとおりに応答するように誘導できます。
| プロンプト | モデルのレスポンス |
|---|---|
 ランドマークに一致する都市を特定してください。 |
このランドマークは、ブラジルのリオデジャネイロにあるコルコバードのキリスト像です。 |
| 更新されたプロンプト | 改善されたレスポンス |
|---|---|
|
ランドマークに一致する都市を特定してください。 
|
都市: ローマ、ランドマーク: コロッセオ。 |

|
都市: 北京、ランドマーク: 紫禁城 |
|
|
都市: リオデジャネイロ、ランドマーク: コルコバードのキリスト像 |
順を追って説明する
視覚的な理解と推論の両方を必要とするような複雑なタスクの場合は、タスクをより小さく、より簡単なステップに分割することが有効です。また、プロンプトの中でモデルに直接「順を追って考える」ように指示することも効果的な場合があります。
| プロンプト | モデルのレスポンス |
|---|---|
 トイレット ペーパーは、いつ使い切りますか? |
間もなくです。あと 3 ロールしかありません。 |
| 更新されたプロンプト | 改善されたレスポンス |
|---|---|
|
|
数学の問題や他の種類の言葉の問題は、モデルに順を追って考えることを求めるのに適しています。
| プロンプト | レスポンス |
|---|---|
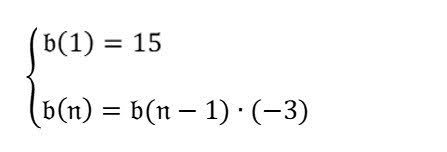
数列の第 4 項は何ですか? |
-135 |
モデルからのレスポンスが正しくありません。これを改善するには、プロンプトに答える前に問題を解析するようにモデルに求める方法があります。
| プロンプト | レスポンス |
|---|---|
まず、画像内の数式を解析します。 次に、数式に基づいて、「数列の第 4 項は何ですか?」に答えます。 |
クリックして結果を拡大$$ b(n) = b(n-1) * (-3) $$ $$ b(1) = 15 $$
$$ b(4) = b(4-1) * (-3) $$ $$ b(4) = b(3) * (-3) $$ $$ b(3) = b(3-1) * (-3) $$ $$ b(3) = b(2) * (-3) $$ $$ b(2) = b(2-1) * (-3) $$ $$ b(2) = b(1) * (-3) $$ $$ b(2) = 15 * (-3) $$ $$ b(2) = -45 $$ $$ b(3) = b(2) * (-3) $$ $$ b(3) = -45 * (-3) $$ $$ b(3) = 135 $$ $$ b(4) = b(3) * (-3) $$ $$ b(4) = 135 * (-3) $$ $$ b(4) = -405 $$ したがって、数列の第 4 項は -405 です。 |
このモデルのレスポンスは正確ですが、レスポンスをさらに合理化するには、モデルに順を追って考えるように依頼します。
| 更新されたプロンプト | 改善されたレスポンス |
|---|---|
数列の第 4 項は何ですか?順を追って考えてください。 |
最初の項は 15 です。 第 2 項は、b(1) × (-3) = 15 × (-3) = -45 です。 第 3 項は、b(2) × (-3) = -45 × (-3) = 135 です。 第 4 項は、b(3) × (-3) = 135 × (-3) = -405 です。 |
出力形式を指定してみる
よくある問題は、モデル出力を特定の形式(マークダウン、JSON、HTML など)にする必要があることです。特に、モデルの出力を下流のタスクで取り込む必要がある場合に発生します。プロンプトの中でモデルにそのように指示することで、その形式での出力を試みることができます。以下に 2 つの例を示します。
| プロンプト | モデルのレスポンス |
|---|---|
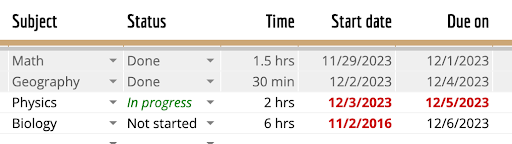 この画像の表を解析してマークダウン形式に変換してください。 |
| 科目 | ステータス | 時間 | 開始日 | 期限: | | ------- | ------ | ---- | --------- | ------ | | 数学 | 完了 | 1.5 時間 | 2023 年 11 月 29 日 | 2023 年 12 月 1 日 | | 地理 | 完了 | 30 分 | 2023 年 12 月 2 日 | 2023 年 12 月 4 日 | | 物理 | 進行中 | 2 時間 | 2023 年 12 月 3 日 | 2023 年 12 月 5 日 | | 生物 | 未開始 | 6 時間 | 2016 年 11 月 2 日 | 2023 年 12 月 6 日 | |
| プロンプト | モデルのレスポンス |
|---|---|

次の属性をすべてリストアップしてください。 材料、料理の種類、ベジタリアンかどうか、JSON 形式 |
|
単一画像のプロンプトではまず画像を配置する
Gemini は、プロンプト内の画像とテキストをどのような順序でも解釈できますが、テキスト プロンプトの前に画像を 1 つ配置するとより良い結果が得られる場合があります。以下の例では、それぞれのプロンプトにおいて、テキストの前に画像があることを確認できます。
マルチモーダル プロンプトのトラブルシューティング
役に立つレスポンスが得られない場合は、プロンプトのトラブルシューティングが必要かもしれません。以下にいくつかの方法を示します。
モデルが画像の該当部分から情報を引き出していない場合
より具体的なレスポンスを得るには、プロンプトへのレスポンスに必要な情報を、画像のどの部分から引き出すかを指定します。
| プロンプト | モデルのレスポンス |
|---|---|
 このおむつは赤ちゃんに何日使えますか? |
おむつは、なくなるまで 198 日使用できます。 |
| 更新されたプロンプト | 改善されたレスポンス |
|---|---|
|
この紙おむつは、どのくらいで使い切りますか? 箱に記載されている体重から子どもの年齢を割り出し、箱に入っているおむつの総数を使用してください。 合計数を、子どもが 1 日あたりに使用するおむつの数で割ってください。 |
箱には 198 枚のおむつが入っています。箱には、おむつが 22~37 ポンドの子ども用であると書かれています。 この体重の範囲にある子どもの平均年齢は 1~2 歳であると考えられます。 通常、2 歳の子どもは 1 日あたり 6 枚のおむつを使用するため、おむつは約 33 日間(198÷6)使用できます。 |
モデルの出力が漠然としすぎて、画像の入力に十分対応できない場合
モデルが画像に応じてレスポンスを調整できるようにするため、推論タスクを実行する前に、画像について説明するよう指示してみます。
| プロンプト | モデルのレスポンス |
|---|---|



これらの画像の共通点は何ですか? |
4 枚の画像はいずれも風景写真のサンプルです。 |
| 更新されたプロンプト | 改善されたレスポンス |
|---|---|
|
まず、それぞれの画像の内容を詳しく説明してください。これらの画像の共通点は何ですか? |
1 つ目の画像にはスーツケースに荷物を詰めている人物が写っています。2 つ目の画像にはショッピング モールの何もない廊下が写っています。3 つ目の画像にはトイレット ペーパーが写っています。4 つ目の画像には暗く荒れ狂う海が写っています。 これらの画像の共通点は、どれもリミナル スペースの例であるということです。リミナル スペースとは、他の 2 つの場所や状況の間にある場所や状況のことです。多くの場合、不確実性やあいまいさによって特徴付けられます。 1 つ目の画像は、自宅にいるときと旅行中の人物を写しています。2 つ目の画像は 2 つの店舗の間にある廊下が写されています。3 つ目の画像はトイレット ペーパーの画像で、バスルームの可能性もあります。トイレは、プライベートなスペースと共用スペースの間の過渡的なスペースです。そこは、外の世界に出入りするための準備をする場所です。 4 つ目の画像は、凪の状態と嵐の状態の間にある海を示しています。 リミナル スペースは刺激的でもあり、不安でもあります。新たな始まりの場所にもなれば、終わりの場所にもなります。内省の場所にもなれば、行動の場所にもなります。 |
また、画像の内容に言及するように明示的にモデルに指示することもできます。
| 更新されたプロンプト | 改善されたレスポンス |
|---|---|
|
これらの画像の共通点は何ですか?レスポンスでは、画像の内容を参考にしてください。 |
画像はすべて旅行に関連しています。1 つ目の画像にはスーツケースに荷物を詰めている人物が写っています。2 つ目の画像にはショッピング モールの何もない廊下が写っています。3 つ目の画像には積み重ねたトイレット ペーパーが写っています。4 つ目の画像には暗く荒れ狂う海が写っています。 これらの画像はすべて、人々が旅行するときに必要なもの、または使用するものであるため、すべて旅行に関連しています。1 つ目の画像には、スーツケースに荷物を詰めている人が写っています。これは、旅行に出かける人が行うことです。2 つ目の画像には、ショッピング モール内の何もない廊下が写っています。ショッピング モールは、旅行用品を購入するために訪れることが多い場所です。3 つ目の画像には、積み重ねたトイレット ペーパーが写っています。トイレット ペーパーは、人が旅行中によく使用するものです。4 つ目の画像には、暗い荒れ狂う海が写っています。これは、人が旅行中によく遭遇する場面です。 |
画像からクリエイティブな出力を得たい場合も、同じアプローチが有効です。ウサギを使った次の例では、画像の特徴を含めるようにモデルに明示的に依頼すると、出力を改善できます。
| プロンプト | モデルのレスポンス |
|---|---|

この画像について詩を書いてもらえますか? |
柔らかくて茶色い小さなウサギ、 君は草をかじってる、とても青々としていて甘い、 |
| 更新されたプロンプト | 改善されたレスポンス |
|---|---|
|
この画像について、叙述的で印象的な詩を書き、場所も含めてもらえますか? |
草原にいる小さなウサギ、 それは海の青、 小さいウサギさん、本当のことを教えてください、 きっと、あらゆる存在の壮大さだね、 小さなウサギさん、どんな夢を見ているの? 君の夢が何であれ、小さいウサギさん、 |
プロンプトの失敗した部分に対するトラブルシューティング
プロンプトが失敗したのは、モデルがそもそも画像を理解していなかったからなのか、それとも画像は理解していたものの、その後に正しい推論の手順を実行しなかったからなのかを判断することは困難です。
これらの理由を区別するには、モデルに画像内にあるものを説明してもらいます。
下の例では、お茶と組み合わせると意外に思えるおやつ(ポップコーンなど)をモデルが返す場合に、まずトラブルシューティングを行い、画像にお茶が含まれていることをモデルが正しく認識しているかどうかを判断します。
| プロンプト | トラブルシューティング用のプロンプト |
|---|---|
 1 分で作ることができるおやつで、これに合うものは何ですか? |
この画像にあるものを説明してください。 |
もう 1 つの方法は、モデルにその推論を説明してもらうことです。そうすることで、推論が破綻した部分を絞り込むことができます。
| プロンプト | トラブルシューティング用のプロンプト |
|---|---|
1 分で作ることができるおやつで、これに合うものは何ですか? |
1 分で作ることができるおやつで、これに合うものは何ですか?理由を説明してください。 |
サンプリング パラメータのチューニング
各リクエストでは、マルチモーダル プロンプトだけでなく、サンプリング パラメータのセットもモデルに送信します。このモデルは、パラメータ値によって異なる結果を生成できます。さまざまなパラメータを試して、タスクに最適な値を取得します。最もよく調整されるパラメータは次のとおりです。
- 温度
- トップ P
- トップ K
温度
温度は、トップ P とトップ K が適用されたときにレスポンスを生成するサンプリングに使用されます。温度は、トークン選択のランダム性の度合いを制御します。温度が低いほど、自由度や創造性を抑えた決定的なレスポンスが求められるプロンプトに適しています。一方、温度が高いと、より多様で創造的な結果を導くことができます。温度 0 は決定的であり、最も高い確率のレスポンスが常に選択されることを意味します。
ほとんどのユースケースでは、温度 0.4 から始めることをおすすめします。よりクリエイティブな結果が必要な場合は、温度を上げてみてください。明確なハルシネーションが見られる場合は、温度を下げてみてください。
Top-K
トップ K は、モデルが出力用にトークンを選択する方法を変更します。トップ K が 1 の場合、次に選択されるトークンは、モデルの語彙内のすべてのトークンで最も確率の高いものであることになります(グリーディ デコードとも呼ばれます)。トップ K が 3 の場合は、最も確率が高い上位 3 つのトークンから次のトークンが選択されることになります(温度を使用します)。
トークン選択のそれぞれのステップで、最も高い確率を持つ Top-K のトークンがサンプリングされます。その後、トークンはトップ P に基づいてさらにフィルタリングされ、最終的なトークンは温度サンプリングを用いて選択されます。
ランダムなレスポンスを減らしたい場合は小さい値を、ランダムなレスポンスを増やしたい場合は大きい値を指定します。トップ K のデフォルト値は 32 です。
トップ P
トップ P は、モデルが出力用にトークンを選択する方法を変更します。トークンは、確率の合計がトップ P 値に等しくなるまで、確率の高いもの(トップ K を参照)から低いものへと選択されます。たとえば、トークン A、B、C の確率が 0.6、0.3、0.1 で、トップ P が 0.9 だとします。このとき、モデルは次のトークンとして A か B を温度を使って選択し、C は候補から外します。
ランダムなレスポンスを減らしたい場合は小さい値を、ランダムなレスポンスを増やしたい場合は大きい値を指定します。トップ P のデフォルト値は 1.0 です。
次のステップ
- Google AI Studio を使用して、独自のマルチモーダル プロンプトを作成してみてください。
- プロンプト設計の詳細なガイダンスについては、プロンプト戦略のページをご覧ください。