Gemini 可以同时处理各种类型的输入数据,包括文本、图片和音频。
本指南介绍了如何使用 Files API 处理媒体文件。对于音频文件、图片、视频、文档和其他受支持的文件类型,基本操作是相同的。
如需了解文件提示方面的指导,请参阅文件提示指南部分。
上传文件
您可以使用 Files API 上传媒体文件。当总请求大小(包括文件、文本提示、系统指令等)超过 100 MB 时,请务必使用 Files API。对于 PDF 文件,上限为 50 MB。
以下代码会上传文件,然后在对 interactions.create 的调用中使用该文件。
Python
from google import genai
client = genai.Client()
myfile = client.files.upload(file="path/to/sample.mp3")
interaction = client.interactions.create(
model="gemini-3.6-flash",
input=[
{"type": "text", "text": "Describe this audio clip"},
{"type": "audio", "uri": myfile.uri, "mime_type": myfile.mime_type}
]
)
print(interaction.output_text)
JavaScript
import { GoogleGenAI } from "@google/genai";
const client = new GoogleGenAI({});
async function main() {
const myfile = await client.files.upload({
file: "path/to/sample.mp3",
config: { mime_type: "audio/mpeg" },
});
const interaction = await client.interactions.create({
model: "gemini-3.6-flash",
input: [
{ type: "text", text: "Describe this audio clip" },
{ type: "audio", uri: myfile.uri, mime_type: myfile.mimeType }
]
});
console.log(interaction.output_text);
}
await main();
Go
file, err := client.Files.UploadFromPath(ctx, "path/to/sample.mp3", nil)
if err != nil {
log.Fatal(err)
}
defer client.Files.Delete(ctx, file.Name)
interaction, err := client.Interactions.Create(ctx, "gemini-3.6-flash", &genai.InteractionRequest{
Input: []interface{}{
genai.NewPartFromFile(*file),
genai.NewPartFromText("Describe this audio clip"),
},
}, nil)
if err != nil {
log.Fatal(err)
}
// Print the model's text response
for _, step := range interaction.Steps {
if step.Type == "model_output" {
for _, part := range step.Content {
if part.Type == "text" {
fmt.Println(part.Text)
}
}
}
}
REST
AUDIO_PATH="path/to/sample.mp3"
MIME_TYPE=$(file -b --mime-type "${AUDIO_PATH}")
NUM_BYTES=$(wc -c < "${AUDIO_PATH}")
DISPLAY_NAME=AUDIO
tmp_header_file=upload-header.tmp
# Initial resumable request defining metadata.
# The upload url is in the response headers dump them to a file.
curl "${BASE_URL}/upload/v1beta/files" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-D "${tmp_header_file}" \
-H "X-Goog-Upload-Protocol: resumable" \
-H "X-Goog-Upload-Command: start" \
-H "X-Goog-Upload-Header-Content-Length: ${NUM_BYTES}" \
-H "X-Goog-Upload-Header-Content-Type: ${MIME_TYPE}" \
-H "Content-Type: application/json" \
-d "{'file': {'display_name': '${DISPLAY_NAME}'}}" 2> /dev/null
upload_url=$(grep -i "x-goog-upload-url: " "${tmp_header_file}" | cut -d" " -f2 | tr -d "\r")
rm "${tmp_header_file}"
# Upload the actual bytes.
curl "${upload_url}" \
-H "Content-Length: ${NUM_BYTES}" \
-H "X-Goog-Upload-Offset: 0" \
-H "X-Goog-Upload-Command: upload, finalize" \
--data-binary "@${AUDIO_PATH}" 2> /dev/null > file_info.json
file_uri=$(jq ".file.uri" file_info.json)
echo file_uri=$file_uri
# Now create an interaction using the Interactions API
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.6-flash",
"input": [
{"type": "text", "text": "Describe this audio clip"},
{"type": "audio", "uri": '$file_uri', "mime_type": "'${MIME_TYPE}'"}
]
}' 2> /dev/null > response.json
cat response.json
echo
jq ".outputs[] | select(.type == \"text\") | .text" response.json
获取文件的元数据
您可以调用 files.get 来验证 API 是否已成功存储上传的文件并获取其元数据。
Python
from google import genai
client = genai.Client()
myfile = client.files.upload(file='path/to/sample.mp3')
file_name = myfile.name
myfile = client.files.get(name=file_name)
print(myfile)
JavaScript
import {
GoogleGenAI,
} from "@google/genai";
const client = new GoogleGenAI({});
async function main() {
const myfile = await client.files.upload({
file: "path/to/sample.mp3",
config: { mime_type: "audio/mpeg" },
});
const fileName = myfile.name;
const fetchedFile = await client.files.get({ name: fileName });
console.log(fetchedFile);
}
await main();
Go
file, err := client.Files.UploadFromPath(ctx, "path/to/sample.mp3", nil)
if err != nil {
log.Fatal(err)
}
gotFile, err := client.Files.Get(ctx, file.Name)
if err != nil {
log.Fatal(err)
}
fmt.Println("Got file:", gotFile.Name)
REST
# file_info.json was created in the upload example
name=$(jq -r ".file.name" file_info.json)
# Get the file of interest to check state
curl https://generativelanguage.googleapis.com/v1beta/$name \
-H "x-goog-api-key: $GEMINI_API_KEY" > file_info.json
# Print some information about the file you got
name=$(jq -r ".name" file_info.json)
echo name=$name
file_uri=$(jq -r ".uri" file_info.json)
echo file_uri=$file_uri
列出已上传的文件
以下代码会获取已上传的所有文件的列表:
Python
from google import genai
client = genai.Client()
print('My files:')
for f in client.files.list():
print(' ', f.name)
JavaScript
import {
GoogleGenAI,
} from "@google/genai";
const client = new GoogleGenAI({});
async function main() {
const listResponse = await client.files.list({ config: { pageSize: 10 } });
for await (const file of listResponse) {
console.log(file.name);
}
}
await main();
Go
for file, err := range client.Files.All(ctx) {
if err != nil {
log.Fatal(err)
}
fmt.Println(file.Name)
}
REST
echo "My files: "
curl "https://generativelanguage.googleapis.com/v1beta/files" \
-H "x-goog-api-key: $GEMINI_API_KEY"
删除已上传的文件
文件会在 48 小时后自动删除。您还可以手动删除已上传的文件:
Python
from google import genai
client = genai.Client()
myfile = client.files.upload(file='path/to/sample.mp3')
client.files.delete(name=myfile.name)
JavaScript
import {
GoogleGenAI,
} from "@google/genai";
const client = new GoogleGenAI({});
async function main() {
const myfile = await client.files.upload({
file: "path/to/sample.mp3",
config: { mime_type: "audio/mpeg" },
});
const fileName = myfile.name;
await client.files.delete({ name: fileName });
}
await main();
Go
file, err := client.Files.UploadFromPath(ctx, "path/to/sample.mp3", nil)
if err != nil {
log.Fatal(err)
}
client.Files.Delete(ctx, file.Name)
REST
curl --request "DELETE" https://generativelanguage.googleapis.com/v1beta/$name \
-H "x-goog-api-key: $GEMINI_API_KEY"
使用情况信息
您可以使用 Files API 上传媒体文件并与之互动。通过 Files API,您可以为每个项目存储最多 20 GB 的文件,每个文件的最大大小为 2 GB。文件会存储 48 小时。在此期间,您可以使用该 API 获取有关文件的元数据,但无法下载文件。 在所有已推出 Gemini API 的地区,Files API 均可免费使用。
文件提示策略
本部分提供了有关如何将媒体文件与 Gemini API 的提示搭配使用的指南和最佳实践。
能够在提示中使用各种类型的数据,让您在可以使用 Gemini API 处理的任务方面拥有更大的灵活性。例如,您可以向模型发送一张美食照片,并要求它撰写一篇关于这道美食的简短博文。
| 提示 | 答案 |
|
根据这张图片写一篇简短而引人入胜的博文。其中应包含照片中菜肴的描述,并谈论我的饮食准备之旅。 
|
饮食准备是节省时间和金钱的好方法,还可以帮助您吃得更健康。这道菜肴就是一个很好的例子,它既健康又美味,而且可以提前准备。 这道餐品包含糙米、烤蔬菜和照烧鸡肉。 糙米是一种健康且复杂的碳水化合物,可为您提供持久的能量。烤蔬菜是获取每日所需维生素和矿物质的好方法,照烧鸡肉则是一种美味且富含蛋白质的选择。 这道菜的准备工作也很简单。只需煮好糙米、烤好蔬菜,再做好照烧鸡肉即可。所有食材烹制完毕后,将其分装到备餐容器中,然后放入冰箱冷藏。 这样,您就可以在忙碌的早晨拿上一个容器,然后出门了! 如果您想寻找一种可以提前准备的健康美味餐,那么这款餐食是不错的选择。它富含营养和风味,定能让您感到饱腹和满足。 祝您健康美味的备餐之旅愉快! |
如果您在使用媒体文件的提示中难以获得所需的输出,可以尝试以下策略来帮助您获得所需的结果。以下部分提供了设计方法和问题排查提示,可帮助您改进使用多模态输入的提示。
您可以按照以下最佳实践来改进多模态提示:
-
提示设计基础知识
- 指令应当明确具体:编写清晰且简洁的指令,尽量避免误解。
- 向提示中添加一些示例:使用切实可行的少样本示例来说明您要实现的目标。
- 分步细分:将复杂的任务划分为多个易于管理的子目标,引导模型完成整个过程。
- 指定输出格式:在提示中,要求输出采用所需的格式,如 Markdown、JSON、HTML 等。
- 对于单个图片的提示,首先放置图片:虽然 Gemini 可以按任意顺序处理图片和文字输入,但对于包含单张图片的提示,如果将图片(或视频)放在文本提示前面,效果可能会更好。 但是,对于需要图片与文本高度交织才具有意义的提示,请使用最自然的顺序。
-
排查多模态提示问题
- 如果模型没有从图片的相关部分提取信息:给出提示,说明您希望提示从图片的哪些方面提取信息。
- 如果模型输出过于笼统(没有针对图片或视频输入进行足够的定制):在提示开头,尝试要求模型描述图片或视频,然后再提供任务指令,或尝试要求模型参考图片中的内容。
- 排查哪个部分失败:要求模型描述图片,或要求模型说明其推理,以衡量模型的初步理解。
- 如果您的提示产生幻觉内容:尝试调低温度设置,或要求模型提供较短的说明,以便不太可能推断其他细节。
- 对采样参数调优:尝试不同的温度设置和 Top-k 选择,以调整模型的创造力。
说明应当明确具体
提示在清晰而详细时最成功。如果您考虑获得特定输出,最好在提示中包含该要求,以确保获得所需输出。
对于此机场面板图片,要求模型仅“描述此图片”可能会生成一般性说明。如果您需要模型从图片中解析时间和城市,则可以直接在提示中添加该请求。
| 提示 | 模型回答 |
|---|---|

描述此图片。 |
此图片显示了机场到达和出发信息面板。 |
| 更新后的提示 | 改进后的回答 |
|---|---|
将下图中显示的机场面板中的时间和城市解析为列表。 |
添加一些示例
Gemini 模型可以接受多个输入,它可以将这些输入用作示例来理解所需的输出。添加这些示例有助于模型识别模式,并将给定图片与回答之间的关系应用于新示例。这也称为少量样本学习。
在以下示例中,初始输出以句子形式编写,并且还包含国家/地区(巴西)。假设您需要不同格式或样式的输出,并且只希望输入城市而不是国家/地区。向提示中添加少样本示例可以引导模型以您所需的方式进行回答。
| 提示 | 模型回答 |
|---|---|
 确定城市以及地标。 |
地标是巴西里约热内卢的基督救世主雕像。 |
| 更新后的提示 | 改进后的回答 |
|---|---|
|
确定城市以及地标。 
|
城市:罗马,地标:斗兽场。 |

|
城市:北京,地标:紫禁城 |
|
|
城市:里约热内卢,地标:基督救世主雕像 |
分步细分
对于复杂的任务(例如需要视觉理解和推理的任务),将任务拆分为更小、更直接的步骤可能会很有帮助。或者,如果您在提示中直接要求模型“分步思考”,也可能会很有效。
| 提示 | 模型回答 |
|---|---|

我什么时候会将卫生纸用完? |
您只剩下 3 卷了。 |
| 更新后的提示 | 改进后的回答 |
|---|---|
|
|
数学问题或其他类型的字词问题非常适合要求模型分步思考。
| 提示 | 答案 |
|---|---|
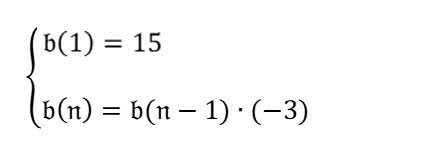
序列中的第 4 项是什么? |
-135 |
模型的回答不正确。改进这种情况的一些方法是要求模型在回答提示之前,先解析问题。
| 提示 | 答案 |
|---|---|
|
首先解析图片中的公式。 然后,根据公式回答“序列中的第 4 项是什么?”。 |
点击可展开结果$$ b(n) = b(n-1) * (-3) $$ $$ b(1) = 15 $$
因此,序列中的第 4 项是 -405。 |
此模型回答是正确的。现在,如需简化回答,您可以要求模型分步思考。
| 更新后的提示 | 改进后的回答 |
|---|---|
|
序列中的第 4 项是什么?请分步思考。 |
第一项是 15。 第二项是 b(1) * (-3) = 15 * (-3) = -45。 第三项是 b(2) * (-3) = -45 * (-3) = 135。 第四项是 b(3) * (-3) = 135 * (-3) = -405。 |
指定输出格式
一个常见问题是模型输出需要采用特定格式(例如 Markdown、JSON、HTML),尤其是在需要由下游任务提取模型输出的情况下。您可以在提示中指示模型生成采用该格式的输出。以下是两个示例:
| 提示 | 模型回答 |
|---|---|
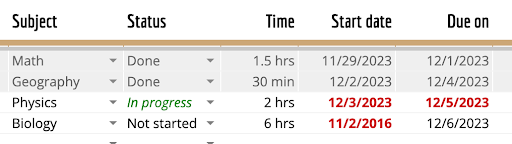
将此图片中的表格解析为 Markdown 格式 |
```none | 学科 | 状态 | 时间 | 开始日期 | 截止日期 | | ------- | ------ | ---- | ---------- | ------ | | 数学 | 完成 | 1.5 小时 | 2023 年 11 月 29 日 | 2023 年 12 月 1 日 | | 地理 | 完成 | 30 分钟 | 2023 年 12 月 2 日 | 2023 年 12 月 4 日 | | 物理 | 进行中 | 2 小时 | 2023 年 12 月 3 日 | 2023 年 12 月 5 日 | | 生物 | 未开始 | 6 小时 | 2016 年 11 月 2 日 | 2023 年 12 月 6 日 | ``` |
| 提示 | 模型回答 |
|---|---|

请提供以下所有属性的列表: 配料、菜系类型、是否为素菜,采用 JSON 格式 |
```json { "ingredients": [ "rice", "shrimp", "clams", "mussels", "peas", "tomatoes", "onions", "garlic", "olive oil", "paprika", "salt", "pepper" ], "type of cuisine": "Spanish", "vegetarian": false } ``` |
首先将图片放在单图片提示中
虽然 Gemini 可以在提示中以任意顺序解读图片和文本,但将单个图片置于文本提示之前可以获得更好的结果。在以下示例中,您会注意到在每个提示中,图片都位于文本之前。
排查多模态提示问题
如果您未收到有用的回答,则可能需要排查提示问题。您可以尝试以下一些策略。
如果模型没有从图片的相关部分提取信息
如需获得更具体的回答,您可以指明您希望提示从图片的哪些方面提取信息以告知其回答。
| 提示 | 模型回答 |
|---|---|

这些尿片可供一个婴儿使用多少天? |
这些尿片可以使用 198 天。 |
| 更新后的提示 | 改进后的回答 |
|---|---|
|
这些尿片可以使用多长时间? 使用包装盒上显示的体重确定孩子的年龄,并使用包装盒中的尿片总数。 用总数除以孩子每天要换的尿片数量。 |
包装盒中有 198 张尿片。包装盒上注明尿片适用于体重 22-37 磅的孩子。 此体重范围内的普通孩子可能在 1 至 2 岁之间。 2 岁的孩子通常每天要换 6 片尿片,因此尿片的使用寿命约为 33 天 (198/6)。 |
如果模型输出过于笼统,没有针对图片输入进行足够的定制
如需帮助模型针对图片定制其回答,请尝试要求它在执行推理任务之前描述图片。
| 提示 | 模型回答 |
|---|---|



这些图片有什么共同之处? |
全部四张图片都是横向摄影的示例。 |
| 更新后的提示 | 改进后的回答 |
|---|---|
|
首先,详细描述每张图片中的内容。这些图片有什么共同之处? |
第一张图片显示一个人正在收拾手提包。第二张图片显示购物中心内空无一人的走廊。第三张图片显示一卷卫生纸。第四张图片显示黑暗汹涌的大海。 这些图片之间的共同之处在于,它们都是临界空间的示例。临界空间是指处于两个其他场所或情景之间的场所或情景。它们通常以一种不确定或模糊的感觉为特征。 第一张图片显示处于居家与旅行之间的人。第二张图片显示两家商店之间的走廊。第三张图片是卫生纸,可以代表浴室。而浴室是私人领域与公共领域之间的过渡空间。它是一个让我们为进入或离开外部世界做好准备的场所。 第四张图片显示介于平静与风暴之间的大海。 临界空间可能既令人兴奋,又令人不安。它们既可以作为崭新开始的场所,也可以作为结束的场所。它们可以是反思的场所,也可以是行动的场所。 |
您也可以尝试明确要求模型参考图片中的内容。
| 更新后的提示 | 改进后的回答 |
|---|---|
|
这些图片有什么共同之处?请在回答中参考图片的内容。 |
所有图片都与旅行相关。第一张图片显示一个人正在收拾手提包,第二张图片显示购物中心空无一人的走廊,第三张图片显示一叠卫生纸,第四张图片显示黑暗汹涌的大海。 这些图片都与旅行相关,因为它们都是人们在旅行时所需要或使用的事物。第一张图片显示一个人正在收拾手提箱,这是人们在旅行时要做的事情。第二张图片显示购物中心内空无一人的走廊,人们经常来到这个场所购买旅行用品。第三张图片显示一叠卫生纸,这是人们在旅行时经常使用的物品。第四张图片显示黑暗汹涌的大海,这是人们在旅行时经常遇到的景象。 |
同样的提示适用于从图片获得创造性输出。在以下包含兔子的示例中,明确要求模型包含图片中的各个方面可以改进输出。
| 提示 | 模型回答 |
|---|---|

您能为我写一首关于此图片的诗歌吗? |
棕色的软软的小兔子, 你啃着又甜又绿的青草, |
| 更新后的提示 | 改进后的回答 |
|---|---|
|
您能为我写一首关于此图片的兼具描述性和戏剧性的诗歌,并在其中包含地点吗? |
小小兔子在绿草坪, 是那在阳光下熠熠生辉的, 小兔子,告诉我吧, 也许是眼前的一切, 小兔子,当你在草地上静静地坐着, 无论是什么,小兔子, |
排查提示的哪个部分失败
很难知道提示失败是否是因为模型一开始不理解图片,或者它是否理解图片但随后没有执行正确的推理步骤。如需区分这些原因,请要求模型描述图片中的内容。
在以下示例中,如果在与茶搭配时,模型以似乎令人惊讶的零食(例如爆米花)作为回答,则可以先进行问题排查,以确定模型是否正确识别出图片中包含茶。
| 提示 | 用于问题排查的提示 |
|---|---|

我在 1 分钟内能拿出什么零食来与此图片中的内容搭配食用? |
描述此图片中的内容。 |
另一种策略是要求模型说明其推理。这有助于您缩小推理失败的部分(如果有)。
| 提示 | 用于问题排查的提示 |
|---|---|
|
我在 1 分钟内能拿出什么零食来与此图片中的内容搭配食用? |
我在 1 分钟内能拿出什么零食来与此图片中的内容搭配食用?请说明原因。 |
后续步骤
- 不妨使用 Google AI Studio 尝试自行撰写多模态提示。
- 如需了解如何使用 Gemini Files API 上传媒体文件并将其纳入提示中,请参阅Vision、音频和文档处理指南。
- 如需获取有关提示设计的更多指导(例如调整采样参数),请参阅提示策略页面。