Google Search से सटीक जानकारी पाने की सुविधा, Gemini मॉडल को रीयल-टाइम में वेब कॉन्टेंट से कनेक्ट करती है और सभी उपलब्ध भाषाओं में काम करती है. इससे Gemini, जानकारी न मिलने की स्थिति के दायरे से बाहर निकलकर ज़्यादा सटीक जवाब और भरोसेमंद सोर्स के रेफ़रंस दे पाता है.
ग्राउंडिंग की मदद से, ऐसे ऐप्लिकेशन बनाए जा सकते हैं जो ये काम कर सकते हैं:
- तथ्यों के हिसाब से जवाब को ज़्यादा सटीक बनाना: मॉडल के गलत जानकारी देने की समस्या को कम करना. इसके लिए, जवाबों को असल दुनिया की जानकारी के आधार पर तैयार करना.
- रीयल-टाइम में जानकारी ऐक्सेस करना: हाल की घटनाओं और विषयों के बारे में सवालों के जवाब पाना.
उद्धरण दें: मॉडल के दावों के सोर्स दिखाकर, उपयोगकर्ताओं का भरोसा जीतें.
Python
from google import genai
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Who won the euro 2024?",
tools=[{"type": "google_search"}]
)
print(interaction.output_text)
JavaScript
import { GoogleGenAI } from "@google/genai";
const client = new GoogleGenAI({});
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: "Who won the euro 2024?",
tools: [{ type: "google_search" }]
});
console.log(interaction.output_text);
REST
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.5-flash",
"input": "Who won the euro 2024?",
"tools": [{"type": "google_search"}]
}'
Google Search से सटीक जानकारी पाने की सुविधा कैसे काम करती है
google_search टूल को चालू करने पर, मॉडल खोज करने, जानकारी को प्रोसेस करने, और उद्धरण देने जैसे सभी काम अपने-आप करता है.
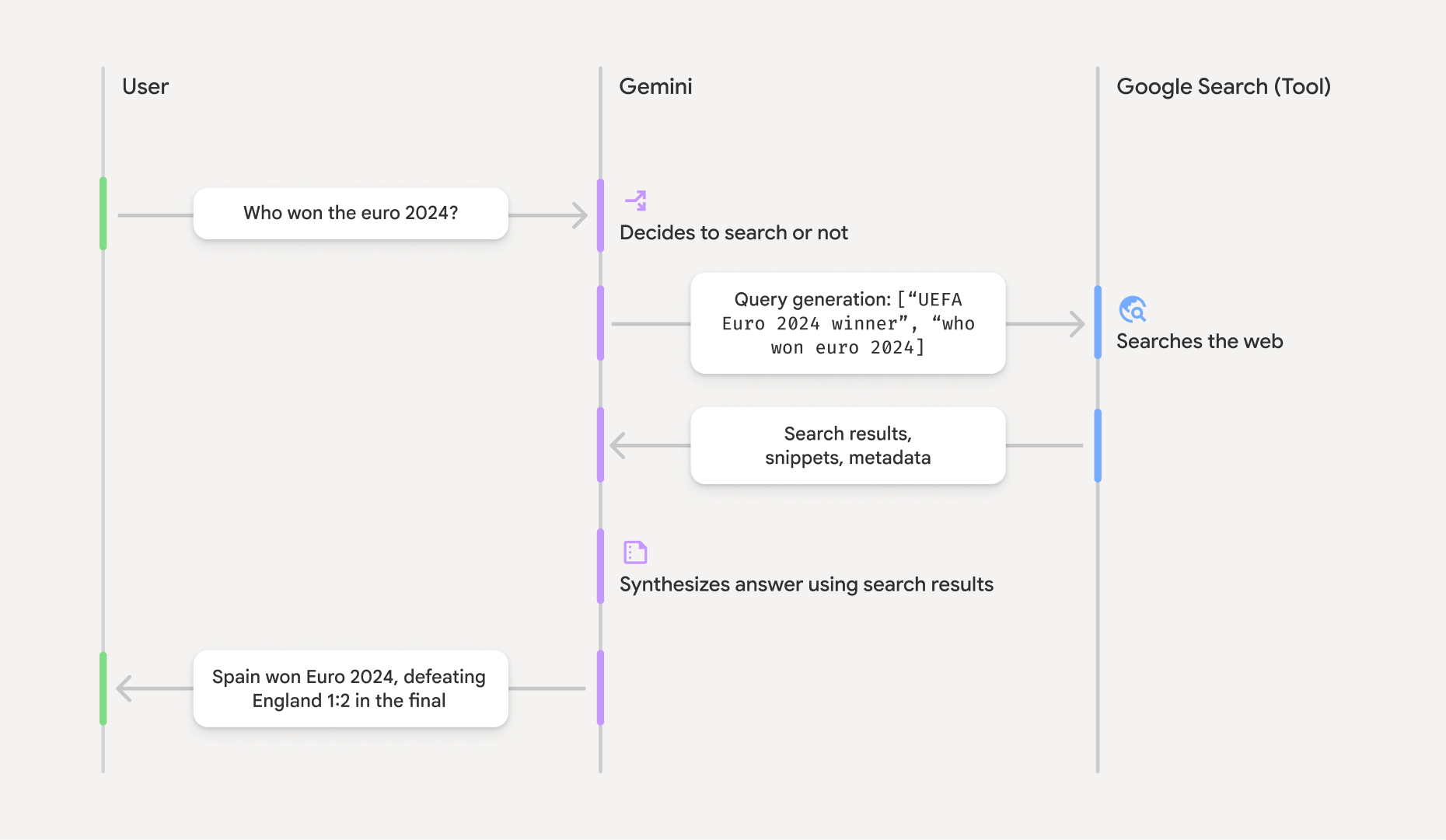
- उपयोगकर्ता का प्रॉम्प्ट: आपका ऐप्लिकेशन, उपयोगकर्ता के प्रॉम्प्ट को Gemini API पर भेजता है. इसके लिए,
google_searchटूल चालू होना चाहिए. - प्रॉम्प्ट का विश्लेषण: मॉडल, प्रॉम्प्ट का विश्लेषण करता है. इससे यह तय किया जाता है कि क्या Google Search से जवाब को बेहतर बनाया जा सकता है.
- Google Search: अगर ज़रूरत होती है, तो मॉडल अपने-आप एक या एक से ज़्यादा सर्च क्वेरी जनरेट करता है और उन्हें पूरा करता है.
- खोज के नतीजों को प्रोसेस करना: मॉडल, खोज के नतीजों को प्रोसेस करता है, जानकारी को इकट्ठा करता है, और जवाब तैयार करता है.
- भरोसेमंद स्रोतों से मिली जानकारी के आधार पर जवाब देना: एपीआई, खोज के नतीजों के आधार पर उपयोगकर्ता को ऐसा जवाब देता है जो समझने में आसान हो. इस जवाब में, मॉडल के टेक्स्ट वाले जवाब के साथ-साथ, इनलाइन
annotationsभी शामिल है. इसमें उद्धरण दिए गए हैं. इसके अलावा, इसमेंgoogle_search_callऔरgoogle_search_resultचरणों के साथ-साथ, खोज क्वेरी और खोज के सुझाव भी दिए गए हैं.
भरोसेमंद स्रोतों से मिले जवाब को समझना
जब किसी जवाब में भरोसेमंद सोर्स से जानकारी ली जाती है, तो मॉडल के टेक्स्ट आउटपुट में, टेक्स्ट कॉन्टेंट ब्लॉक पर सीधे तौर पर इनलाइन annotations शामिल होता है. इन एनोटेशन में, जवाब के कुछ हिस्सों को उनके सोर्स से लिंक करने वाली उद्धरण जानकारी दी जाती है.
{
"steps": [
{
"type": "thought",
"summary": [
{
"type": "text",
"text": "The user is asking for the winner of Euro 2024. I need to search for the result of the Euro 2024 final."
}
],
"signature": "CoMDAXLI2nynRYojJIy6B1Jh9os2crpWLfB0..."
},
{
"type": "google_search_call",
"arguments": {
"queries": ["UEFA Euro 2024 winner"]
}
},
{
"type": "google_search_result",
"call_id": "search_001",
"result": [
{
"search_suggestions": "<!-- HTML and CSS for the search widget -->"
}
]
},
{
"type": "model_output",
"content": [
{
"type": "text",
"text": "Spain won Euro 2024, defeating England 2-1 in the final. This victory marks Spain's record fourth European Championship title.",
"annotations": [
{
"type": "url_citation",
"url": "https://www.aljazeera.com/sports/euro-2024-final",
"title": "aljazeera.com",
"start_index": 0,
"end_index": 56
},
{
"type": "url_citation",
"url": "https://www.uefa.com/euro2024/news/spain-wins-euro-2024",
"title": "uefa.com",
"start_index": 57,
"end_index": 124
}
]
}
]
}
]
}
जवाब में मौजूद मुख्य फ़ील्ड:
google_search_call: इसमें वह खोजqueriesशामिल होती है जिसे मॉडल ने पूरा किया है.google_search_result: इसमेंsearch_suggestionsशामिल होता है. यह आपके यूज़र इंटरफ़ेस (यूआई) में खोज के सुझावों को रेंडर करने के लिए, एचटीएमएल स्निपेट होता है. इस्तेमाल से जुड़ी सभी ज़रूरी शर्तों के बारे में सेवा की शर्तों में बताया गया है.textके साथannotations: मॉडल का सिंथेसाइज़ किया गया जवाब, जिसमें इनलाइन उद्धरण शामिल हैं. हरurl_citationएनोटेशन, टेक्स्ट सेगमेंट को सोर्स यूआरएल से लिंक करता है. टेक्स्ट सेगमेंट कोstart_indexऔरend_indexएट्रिब्यूट से तय किया जाता है. इनलाइन उद्धरण बनाने के लिए, यह कुंजी है.
Google Search से मिली जानकारी का इस्तेमाल, यूआरएल के कॉन्टेक्स्ट वाले टूल के साथ भी किया जा सकता है. इससे, जवाबों में सार्वजनिक वेब डेटा और आपके दिए गए यूआरएल, दोनों से मिली जानकारी शामिल की जा सकती है.
इनलाइन उद्धरणों की मदद से सोर्स एट्रिब्यूट करना
एपीआई, टेक्स्ट कॉन्टेंट ब्लॉक पर इनलाइन url_citation एनोटेशन दिखाता है. इससे आपको यह तय करने का पूरा कंट्रोल मिलता है कि आपको अपने यूज़र इंटरफ़ेस में सोर्स कैसे दिखाने हैं.
हर एनोटेशन में start_index और end_index शामिल होते हैं. इनसे यह पता चलता है कि एनोटेशन में टेक्स्ट के किस हिस्से का हवाला दिया गया है. यहां उन्हें निकालने और दिखाने का तरीका बताया गया है.
Python
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
if content_block.annotations:
print("\nCitations:")
for annotation in content_block.annotations:
if annotation.type == "url_citation":
cited_text = content_block.text[annotation.start_index:annotation.end_index]
print(f" [{annotation.title}]({annotation.url})")
print(f" Cited text: \"{cited_text}\"")
JavaScript
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text') {
console.log(contentBlock.text);
if (contentBlock.annotations) {
console.log("\nCitations:");
for (const annotation of contentBlock.annotations) {
if (annotation.type === 'url_citation') {
const citedText = contentBlock.text.slice(annotation.startIndex, annotation.endIndex);
console.log(` [${annotation.title}](${annotation.url})`);
console.log(` Cited text: "${citedText}"`);
}
}
}
}
}
}
}
आउटपुट में, टेक्स्ट के बाद उसके उद्धरण दिखेंगे:
Spain won Euro 2024, defeating England 2-1 in the final. This victory marks Spain's record fourth European Championship title.
Citations:
[aljazeera.com](https://www.aljazeera.com/sports/euro-2024-final)
Cited text: "Spain won Euro 2024, defeating England 2-1 in the final."
[uefa.com](https://www.uefa.com/euro2024/news/spain-wins-euro-2024)
Cited text: "This victory marks Spain's record fourth European Championship title."
कीमत
Gemini 3 के साथ Google Search की ग्राउंडिंग का इस्तेमाल करने पर, आपके प्रोजेक्ट को हर उस खोज क्वेरी के लिए बिल किया जाता है जिसे मॉडल पूरा करने का फ़ैसला करता है. अगर मॉडल किसी एक प्रॉम्प्ट का जवाब देने के लिए, कई खोज क्वेरी चलाने का फ़ैसला करता है (उदाहरण के लिए, एक ही एपीआई कॉल में "UEFA Euro 2024 winner" और "Spain vs England Euro 2024 final
score" खोजना), तो इसे उस अनुरोध के लिए, टूल के दो बार इस्तेमाल के तौर पर गिना जाएगा. इसके लिए, आपसे शुल्क लिया जाएगा. बिलिंग के लिए, यूनीक क्वेरी की गिनती करते समय, हम वेब सर्च की उन क्वेरी को अनदेखा करते हैं जिनमें कोई शब्द नहीं होता. यह बिलिंग मॉडल सिर्फ़ Gemini 3 मॉडल पर लागू होता है. Gemini 2.5 या इससे पुराने मॉडल के साथ खोज के नतीजों का इस्तेमाल करने पर, आपके प्रोजेक्ट के लिए हर प्रॉम्प्ट के हिसाब से बिल भेजा जाता है.
शुल्क के बारे में ज़्यादा जानकारी के लिए, Gemini API के शुल्क वाला पेज देखें.
इन मॉडल के साथ काम करता है
आपको मॉडल की खास जानकारी वाले पेज पर, सभी सुविधाएं मिल सकती हैं.
| मॉडल | Google Search से सटीक जानकारी पाने की सुविधा |
|---|---|
| Gemini 3.5 Flash | ✔️ |
| Gemini 3.1 Flash की इमेज का प्रीव्यू | ✔️ |
| Gemini 3.1 Pro की झलक | ✔️ |
| Gemini 3 Pro की इमेज की झलक | ✔️ |
| Gemini 3 Flash की झलक | ✔️ |
| Gemini 2.5 Pro | ✔️ |
| Gemini 2.5 Flash | ✔️ |
| Gemini 2.5 Flash-Lite | ✔️ |
| Gemini 2.0 Flash | ✔️ |
इस्तेमाल किए जा सकने वाले टूल कॉम्बिनेशन
ज़्यादा मुश्किल इस्तेमाल के उदाहरणों के लिए, Google Search के साथ ग्राउंडिंग की सुविधा का इस्तेमाल किया जा सकता है. इसके लिए, कोड एक्ज़ीक्यूशन और यूआरएल कॉन्टेक्स्ट जैसे अन्य टूल का इस्तेमाल किया जा सकता है.
Gemini 3 मॉडल, बिल्ट-इन टूल (जैसे कि Google Search की मदद से ज़्यादा जानकारी पाना) को कस्टम टूल (फ़ंक्शन कॉलिंग) के साथ इस्तेमाल करने की सुविधा देते हैं. टूल के कॉम्बिनेशन पेज पर जाकर, इस बारे में ज़्यादा जानें.
आगे क्या करना है
- उपलब्ध अन्य टूल के बारे में जानें. जैसे, फ़ंक्शन कॉलिंग.
- यूआरएल के कॉन्टेक्स्ट वाले टूल का इस्तेमाल करके, प्रॉम्प्ट में यूआरएल जोड़ने का तरीका जानें.