Imagen adalah model pembuatan gambar fidelitas tinggi Google, yang mampu menghasilkan gambar realistis dan berkualitas tinggi dari perintah teks. Semua gambar yang dihasilkan menyertakan watermark SynthID. Untuk mempelajari lebih lanjut varian model Imagen yang tersedia, lihat bagian Versi model.
Membuat gambar menggunakan model Imagen
Contoh ini menunjukkan pembuatan gambar dengan model Imagen:
Python
from google import genai
from google.genai import types
from PIL import Image
from io import BytesIO
client = genai.Client()
response = client.models.generate_images(
model='imagen-4.0-generate-001',
prompt='Robot holding a red skateboard',
config=types.GenerateImagesConfig(
number_of_images= 4,
)
)
for generated_image in response.generated_images:
generated_image.image.show()
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const response = await ai.models.generateImages({
model: 'imagen-4.0-generate-001',
prompt: 'Robot holding a red skateboard',
config: {
numberOfImages: 4,
},
});
let idx = 1;
for (const generatedImage of response.generatedImages) {
let imgBytes = generatedImage.image.imageBytes;
const buffer = Buffer.from(imgBytes, "base64");
fs.writeFileSync(`imagen-${idx}.png`, buffer);
idx++;
}
}
main();
Go
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateImagesConfig{
NumberOfImages: 4,
}
response, _ := client.Models.GenerateImages(
ctx,
"imagen-4.0-generate-001",
"Robot holding a red skateboard",
config,
)
for n, image := range response.GeneratedImages {
fname := fmt.Sprintf("imagen-%d.png", n)
_ = os.WriteFile(fname, image.Image.ImageBytes, 0644)
}
}
REST
curl -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/imagen-4.0-generate-001:predict" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"instances": [
{
"prompt": "Robot holding a red skateboard"
}
],
"parameters": {
"sampleCount": 4
}
}'

Konfigurasi Imagen
Saat ini, Imagen hanya mendukung perintah dalam bahasa Inggris dan parameter berikut:
numberOfImages: Jumlah gambar yang akan dibuat, dari 1 hingga 4 (inklusif). Defaultnya adalah 4.imageSize: Ukuran gambar yang dihasilkan. Fitur ini hanya didukung untuk model Standard dan Ultra. Nilai yang didukung adalah1Kdan2K. Default-nya adalah1K.aspectRatio: Mengubah rasio aspek gambar yang dihasilkan. Nilai yang didukung adalah"1:1","3:4","4:3","9:16", dan"16:9". Defaultnya adalah"1:1".personGeneration: Mengizinkan model membuat gambar orang. Nilai berikut didukung:"dont_allow": Memblokir pembuatan gambar orang."allow_adult": Menghasilkan gambar orang dewasa, tetapi bukan anak-anak. Ini adalah defaultnya."allow_all": Menghasilkan gambar yang menyertakan orang dewasa dan anak-anak.
Panduan perintah Imagen
Bagian panduan Imagen ini menunjukkan cara memodifikasi perintah text-to-image dapat menghasilkan hasil yang berbeda, beserta contoh gambar yang dapat Anda buat.
Dasar-dasar penulisan perintah
Perintah yang baik bersifat deskriptif dan jelas, serta menggunakan kata kunci dan pengubah yang bermakna. Mulailah dengan memikirkan subjek, konteks, dan gaya Anda.

Subjek: Hal pertama yang harus dipikirkan dengan perintah apa pun adalah subjek: objek, orang, hewan, atau pemandangan yang Anda inginkan gambarnya.
Konteks dan latar belakang: Sama pentingnya adalah latar belakang atau konteks tempat subjek akan ditempatkan. Coba tempatkan subjek di berbagai latar belakang. Misalnya, studio dengan latar belakang putih, di luar ruangan, atau di dalam ruangan.
Gaya: Terakhir, tambahkan gaya gambar yang Anda inginkan. Gaya dapat bersifat umum (lukisan, foto, sketsa) atau yang sangat spesifik (lukisan pastel, gambar arang, 3D isometrik). Anda juga dapat menggabungkan gaya.
Setelah menulis versi pertama perintah, perbaiki perintah Anda dengan menambahkan lebih banyak detail hingga Anda mendapatkan gambar yang Anda inginkan. Iterasi itu penting. Mulailah dengan menentukan ide inti Anda, lalu sempurnakan dan kembangkan ide inti tersebut hingga gambar yang dihasilkan mendekati visi Anda.

|

|

|
Model Imagen dapat mengubah ide Anda menjadi gambar yang mendetail, baik perintah Anda singkat maupun panjang dan mendetail. Sempurnakan visi Anda melalui perintah iteratif, tambahkan detail hingga Anda mendapatkan hasil yang sempurna.
|
Perintah singkat memungkinkan Anda membuat gambar dengan cepat. 
|
Dengan perintah yang lebih panjang, Anda dapat menambahkan detail spesifik dan membuat gambar. 
|
Saran tambahan untuk penulisan perintah Imagen:
- Gunakan bahasa deskriptif: Gunakan kata sifat dan kata keterangan yang mendetail untuk menggambarkan situasi yang jelas bagi Imagen.
- Berikan konteks: Jika perlu, sertakan informasi latar belakang untuk membantu AI memahami.
- Merujuk pada artis atau gaya tertentu: Jika Anda memiliki estetika tertentu, merujuk pada artis atau gerakan seni tertentu dapat membantu.
- Gunakan alat prompt engineering: Pertimbangkan untuk mempelajari alat atau referensi prompt engineering untuk membantu Anda menyempurnakan perintah dan mencapai hasil yang optimal.
- Meningkatkan kualitas detail wajah dalam gambar pribadi dan grup Anda: Tentukan detail wajah sebagai fokus foto (misalnya, gunakan kata "potret" dalam perintah).
Membuat teks dalam gambar
Model Imagen dapat menambahkan teks ke dalam gambar, sehingga membuka lebih banyak kemungkinan pembuatan gambar yang kreatif. Gunakan panduan berikut untuk mendapatkan hasil maksimal dari fitur ini:
- Lakukan iterasi dengan percaya diri: Anda mungkin harus membuat ulang gambar hingga Anda mendapatkan tampilan yang diinginkan. Integrasi teks Imagen masih dalam tahap pengembangan, dan terkadang beberapa upaya akan memberikan hasil terbaik.
- Buat tetap singkat: Batasi teks hingga 25 karakter atau kurang untuk generasi yang optimal.
Beberapa frasa: Bereksperimenlah dengan dua atau tiga frasa berbeda untuk memberikan informasi tambahan. Hindari penggunaan lebih dari tiga frasa untuk komposisi yang lebih bersih.

Perintah: Poster dengan teks "Summerland" dalam font tebal sebagai judul, di bawah teks ini terdapat slogan "Summer never felt so good" Penempatan Panduan: Meskipun Imagen dapat mencoba memosisikan teks sesuai arahan, terkadang ada variasi. Fitur ini terus ditingkatkan.
Gaya font Inspire: Tentukan gaya font umum untuk memengaruhi pilihan Imagen secara halus. Jangan mengandalkan replikasi font yang presisi, tetapi harapkan interpretasi kreatif.
Ukuran font: Tentukan ukuran font atau indikasi ukuran umum (misalnya, kecil, sedang, besar) untuk memengaruhi pembuatan ukuran font.
Parameterisasi perintah
Untuk mengontrol hasil output dengan lebih baik, Anda mungkin merasa terbantu dengan memparameterisasi input ke Imagen. Misalnya, Anda ingin pelanggan dapat membuat logo untuk bisnis mereka, dan Anda ingin memastikan logo selalu dibuat dengan latar belakang warna solid. Anda juga ingin membatasi opsi yang dapat dipilih klien dari menu.
Dalam contoh ini, Anda dapat membuat perintah berparameter yang mirip dengan berikut:
A {logo_style} logo for a {company_area} company on a solid color background. Include the text {company_name}.Di antarmuka pengguna kustom Anda, pelanggan dapat memasukkan parameter menggunakan menu, dan nilai yang dipilihnya akan mengisi perintah yang diterima Imagen.
Contoh:
Perintah:
A minimalist logo for a health care company on a solid color background. Include the text Journey.
Perintah:
A modern logo for a software company on a solid color background. Include the text Silo.
Perintah:
A traditional logo for a baking company on a solid color background. Include the text Seed.
Teknik penulisan perintah lanjutan
Gunakan contoh berikut untuk membuat perintah yang lebih spesifik berdasarkan atribut seperti deskripsi fotografi, bentuk dan bahan, gerakan seni historis, dan pengubah kualitas gambar.
Fotografi
- Perintah menyertakan: "Foto..."
Untuk menggunakan gaya ini, mulai dengan menggunakan kata kunci yang dengan jelas memberi tahu Imagen bahwa Anda mencari foto. Mulailah perintah Anda dengan "Foto. . .". Misalnya:

|

|

|
Sumber gambar: Setiap gambar dibuat menggunakan perintah teks yang sesuai dengan model Imagen 4.
Pengubah fotografi
Pada contoh berikut, Anda dapat melihat beberapa pengubah dan parameter khusus fotografi. Anda dapat menggabungkan beberapa pengubah untuk kontrol yang lebih akurat.
Kedekatan Kamera - Jarak dekat, diambil dari jarak jauh

Perintah: Foto jarak dekat biji kopi 
Perintah: Foto diperkecil sekantong kecil biji kopi
di dapur yang berantakanPosisi Kamera - dari atas, dari bawah

Perintah: foto dari atas kota dengan gedung pencakar langit 
Perintah: Foto kanopi hutan dengan langit biru dari bawah Pencahayaan - alami, dramatis, hangat, dingin

Perintah: foto studio kursi berlengan modern, cahaya alami 
Perintah: foto studio kursi berlengan modern, cahaya dramatis Setelan Kamera - motion blur, soft focus, bokeh, potret

Perintah: foto kota dengan gedung pencakar langit dari dalam mobil dengan motion blur 
Perintah: Foto soft focus jembatan di kota perkotaan pada malam hari Jenis lensa - 35 mm, 50 mm, mata ikan, sudut lebar, makro

Perintah: foto daun, lensa makro 
Perintah: fotografi jalanan, kota new york, lensa mata ikan Jenis film - hitam dan putih, polaroid

Perintah: potret polaroid yang memakai kacamata hitam 
Perintah: foto hitam putih yang memakai kacamata hitam
Sumber gambar: Setiap gambar dibuat menggunakan perintah teks yang sesuai dengan model Imagen 4.
Ilustrasi dan seni
- Perintah menyertakan: "painting dari...", "sketch dari..."
Gaya seni bervariasi mulai dari gaya monokrom seperti sketsa pensil, hingga seni digital yang sangat realistis. Misalnya, gambar berikut menggunakan perintah yang sama dengan gaya yang berbeda:
"[art style or creation technique] sedan listrik sporty bersudut dengan pencakar langit di latar belakang"

|

|

|

|

|

|
Sumber gambar: Setiap gambar dibuat menggunakan perintah teks yang sesuai dengan model Imagen 2.
Bentuk dan bahan
- Perintah mencakup: "...terbuat dari...", "...dalam bentuk..."
Salah satu keunggulan teknologi ini adalah Anda dapat membuat citra yang sulit atau tidak mungkin dilakukan. Misalnya, Anda dapat membuat ulang logo perusahaan dengan bahan dan tekstur yang berbeda.

|

|

|
Sumber gambar: Setiap gambar dibuat menggunakan perintah teks yang sesuai dengan model Imagen 4.
Referensi seni bersejarah
- Perintah mencakup: "...dalam gaya..."
Gaya tertentu telah menjadi ikon selama bertahun-tahun. Berikut adalah beberapa ide lukisan sejarah atau gaya seni yang dapat Anda coba.
"buat gambar dengan gaya [art period or movement] : ladang kincir angin"

|

|

|
Sumber gambar: Setiap gambar dibuat menggunakan perintah teks yang sesuai dengan model Imagen 4.
Pengubah kualitas gambar
Kata kunci tertentu dapat memberi tahu model bahwa Anda mencari aset berkualitas tinggi. Contoh pengubah kualitas mencakup hal berikut:
- Pengubah Umum - berkualitas tinggi, indah, bergaya
- Foto - 4K, HDR, Foto Studio
- Seni, Ilustrasi - oleh profesional, mendetail
Berikut adalah beberapa contoh perintah tanpa pengubah kualitas dan perintah yang sama dengan pengubah kualitas.

|

dari sebuah foto batang jagung diambil oleh fotografer profesional |
Sumber gambar: Setiap gambar dibuat menggunakan perintah teks yang sesuai dengan model Imagen 4.
Rasio aspek
Pembuatan gambar Imagen memungkinkan Anda menetapkan lima rasio aspek gambar yang berbeda.
- Persegi (1:1, default) - Foto persegi standar. Penggunaan umum untuk rasio aspek ini mencakup postingan media sosial.
Layar penuh (4:3) - Rasio aspek ini umumnya digunakan dalam media atau film. Dimensi ini juga merupakan dimensi sebagian besar TV lama (non-layar lebar) dan kamera format sedang. Rasio ini menangkap lebih banyak pemandangan secara horizontal (dibandingkan dengan 1:1), sehingga menjadi rasio aspek pilihan untuk fotografi.

Perintah: close up jari seorang musisi yang sedang bermain piano, film hitam putih, vintage (rasio aspek 4:3) 
Perintah: Foto studio profesional kentang goreng untuk restoran kelas atas, dengan gaya majalah makanan (rasio aspek 4:3) Layar penuh potret (3:4) - Ini adalah rasio aspek layar penuh yang diputar 90 derajat. Hal ini memungkinkan Anda merekam lebih banyak adegan secara vertikal dibandingkan dengan rasio aspek 1:1.

Perintah: seorang wanita sedang mendaki, close-up sepatu botnya yang tercermin di genangan air, pegunungan besar di latar belakang, dengan gaya iklan, sudut dramatis (rasio aspek 3:4) 
Perintah: foto dari atas sungai yang mengalir ke atas lembah mistis (rasio aspek 3:4) Layar lebar (16:9) - Rasio ini telah menggantikan 4:3 dan kini menjadi rasio aspek yang paling umum untuk TV, monitor, dan layar ponsel (lanskap). Gunakan rasio aspek ini jika Anda ingin mengambil lebih banyak latar belakang (misalnya, pemandangan indah).

Perintah: seorang pria yang mengenakan pakaian serba putih duduk di pantai, close up, pencahayaan golden hour (rasio aspek 16:9) Potret (9:16) - Rasio ini adalah layar lebar yang diputar. Rasio aspek ini relatif baru dan telah dipopulerkan oleh aplikasi video pendek (misalnya, YouTube Shorts). Gunakan ini untuk objek tinggi dengan orientasi vertikal yang kuat seperti bangunan, pohon, air terjun, atau objek serupa lainnya.

Perintah: rendering digital gedung pencakar langit besar, modern, megah, epik dengan latar belakang matahari terbenam yang indah (rasio aspek 9:16)
Gambar fotorealistik
Model pembuatan gambar versi yang berbeda mungkin menawarkan campuran output artistik dan fotorealistik. Gunakan kata-kata berikut dalam perintah untuk menghasilkan output yang lebih fotorealistik, berdasarkan subjek yang ingin Anda buat.
| Kasus penggunaan | Jenis lensa | Panjang fokus | Detail tambahan |
|---|---|---|---|
| Orang (potret) | Geser, zoom | 24-35mm | film hitam putih, Film noir, Kedalaman bidang, duoton (sebutkan dua warna) |
| Makanan, serangga, tanaman (objek, still life) | Makro | 60-105mm | Detail tinggi, fokus presisi, pencahayaan terkontrol |
| Olahraga, satwa liar (gerakan) | Zoom telefoto | 100-400mm | Kecepatan shutter cepat, Pelacakan tindakan atau gerakan |
| Astronomi, lanskap (sudut lebar) | Sudut lebar | 10-24mm | Waktu eksposur panjang, fokus tajam, eksposur panjang, air atau awan yang halus |
Potret
| Kasus penggunaan | Jenis lensa | Panjang fokus | Detail tambahan |
|---|---|---|---|
| Orang (potret) | Geser, zoom | 24-35mm | film hitam putih, Film noir, Kedalaman bidang, duoton (sebutkan dua warna) |
Dengan menggunakan beberapa kata kunci dari tabel, Imagen dapat membuat potret berikut:

|

|

|

|
Perintah: Potret wanita, 35 mm, duoton biru dan abu-abu
Model: imagen-4.0-generate-001

|

|

|

|
Perintah: Potret wanita 35 mm, film noir
Model: imagen-4.0-generate-001
Objek
| Kasus penggunaan | Jenis lensa | Panjang fokus | Detail tambahan |
|---|---|---|---|
| Makanan, serangga, tanaman (objek, still life) | Makro | 60-105mm | Detail tinggi, fokus presisi, pencahayaan terkontrol |
Dengan menggunakan beberapa kata kunci dari tabel, Imagen dapat membuat gambar objek berikut:

|

|

|

|
Perintah: daun tanaman prayer, lensa makro, 60 mm
Model: imagen-4.0-generate-001

|

|

|

|
Perintah: sepiring pasta, lensa Makro 100 mm
Model: imagen-4.0-generate-001
Gerakan
| Kasus penggunaan | Jenis lensa | Panjang fokus | Detail tambahan |
|---|---|---|---|
| Olahraga, satwa liar (gerakan) | Zoom telefoto | 100-400mm | Kecepatan shutter cepat, Pelacakan tindakan atau gerakan |
Dengan menggunakan beberapa kata kunci dari tabel, Imagen dapat membuat gambar bergerak berikut:

|

|
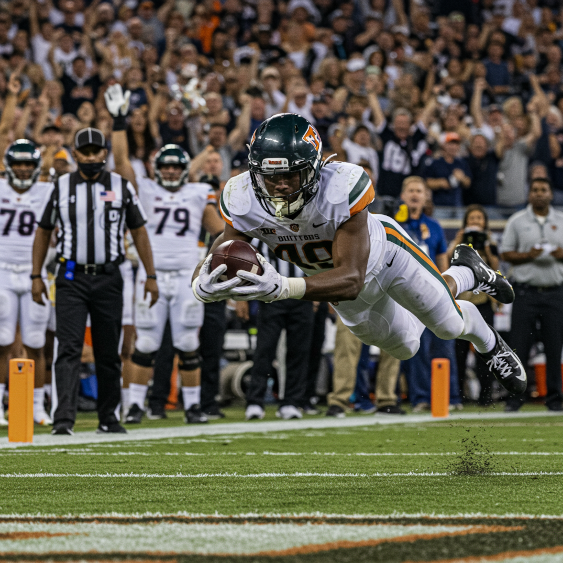
|

|
Perintah: touchdown kemenangan, kecepatan rana cepat, pelacakan gerakan
Model: imagen-4.0-generate-001

|

|

|

|
Perintah: Seekor rusa berlari di hutan, kecepatan shutter cepat, pelacakan gerakan
Model: imagen-4.0-generate-001
Sudut lebar
| Kasus penggunaan | Jenis lensa | Panjang fokus | Detail tambahan |
|---|---|---|---|
| Astronomi, lanskap (sudut lebar) | Sudut lebar | 10-24mm | Waktu eksposur panjang, fokus tajam, eksposur panjang, air atau awan yang halus |
Dengan menggunakan beberapa kata kunci dari tabel, Imagen dapat membuat gambar sudut lebar berikut:

|

|

|

|
Perintah: pegunungan yang luas, lanskap sudut lebar 10 mm
Model: imagen-4.0-generate-001

|

|

|

|
Perintah: foto bulan, fotografi astro, sudut lebar 10 mm
Model: imagen-4.0-generate-001
Versi model
Imagen 4
| Properti | Deskripsi |
|---|---|
| Kode model |
Gemini API
|
| Jenis data yang didukung |
Input Teks Output Gambar |
| Batas token[*] |
Batas token input 480 token (teks) Gambar output 1 hingga 4 (Ultra/Standard/Cepat) |
| Pembaruan terbaru | Juni 2025 |
Imagen 3
Model Imagen 3 telah dinonaktifkan.