Imagen은 Google의 고품질 이미지 생성 모델로, 텍스트 프롬프트에서 사실적이고 고품질 이미지를 생성할 수 있습니다. 생성된 모든 이미지에는 SynthID 워터마크가 포함됩니다. 사용 가능한 Imagen 모델 변형에 대해 자세히 알아보려면 모델 버전 섹션을 참고하세요.
Imagen 모델을 사용하여 이미지 생성
다음은 Imagen 모델로 이미지를 생성하는 방법을 보여주는 예시입니다.
Python
from google import genai
from google.genai import types
from PIL import Image
from io import BytesIO
client = genai.Client()
response = client.models.generate_images(
model='imagen-4.0-generate-001',
prompt='Robot holding a red skateboard',
config=types.GenerateImagesConfig(
number_of_images= 4,
)
)
for generated_image in response.generated_images:
generated_image.image.show()
자바스크립트
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const response = await ai.models.generateImages({
model: 'imagen-4.0-generate-001',
prompt: 'Robot holding a red skateboard',
config: {
numberOfImages: 4,
},
});
let idx = 1;
for (const generatedImage of response.generatedImages) {
let imgBytes = generatedImage.image.imageBytes;
const buffer = Buffer.from(imgBytes, "base64");
fs.writeFileSync(`imagen-${idx}.png`, buffer);
idx++;
}
}
main();
Go
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateImagesConfig{
NumberOfImages: 4,
}
response, _ := client.Models.GenerateImages(
ctx,
"imagen-4.0-generate-001",
"Robot holding a red skateboard",
config,
)
for n, image := range response.GeneratedImages {
fname := fmt.Sprintf("imagen-%d.png", n)
_ = os.WriteFile(fname, image.Image.ImageBytes, 0644)
}
}
REST
curl -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/imagen-4.0-generate-001:predict" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"instances": [
{
"prompt": "Robot holding a red skateboard"
}
],
"parameters": {
"sampleCount": 4
}
}'

Imagen 구성
Imagen은 현재 영어로 된 프롬프트와 다음 매개변수만 지원합니다.
numberOfImages: 생성할 이미지 수입니다 (1~4, 포함). 기본값은 4입니다.imageSize: 생성된 이미지의 크기입니다. Standard 및 Ultra 모델에서만 지원됩니다. 지원되는 값은1K및2K입니다. 기본값은1K입니다.aspectRatio: 생성된 이미지의 가로세로 비율을 변경합니다. 지원되는 값은"1:1","3:4","4:3","9:16","16:9"입니다. 기본값은"1:1"입니다.personGeneration: 모델이 사람 이미지를 생성하도록 허용합니다. 다음 값이 지원됩니다."dont_allow": 사람 이미지 생성을 차단합니다."allow_adult": 성인 이미지를 생성하고 어린이 이미지는 생성하지 않습니다. 이는 기본값입니다."allow_all": 성인과 어린이가 포함된 이미지를 생성합니다.
Imagen 프롬프트 가이드
Imagen 가이드의 이 섹션에서는 텍스트 이미지 변환 프롬프트를 수정하면 다른 결과를 얻을 수 있는 방법을 설명하고 만들 수 있는 이미지의 예를 제공합니다.
프롬프트 작성 기본사항
좋은 프롬프트는 설명적이고 명확하며 의미 있는 키워드와 수정자를 사용합니다. 먼저 주제, 컨텍스트, 스타일을 생각해 보세요.

주제: 프롬프트에서 가장 먼저 고려해야 할 사항은 주제 즉 이미지가 필요한 사물, 사람, 동물 또는 풍경입니다.
컨텍스트 및 배경: 마찬가지로 주제가 배치될 배경 또는 컨텍스트도 중요합니다. 다양한 배경에 주제를 배치해 보세요. 예를 들어 흰색 배경, 실외 또는 실내 환경의 스튜디오가 있습니다.
스타일: 마지막으로 원하는 이미지의 스타일을 추가합니다. 스타일은 일반적(회화, 사진, 스케치)이거나 매우 구체적(파스텔 회화, 목탄 드로잉, 아이소메트릭 3D)일 수 있습니다. 스타일을 결합할 수도 있습니다.
프롬프트의 첫 번째 버전을 작성한 후 원하는 이미지가 나올 때까지 세부정보를 추가하여 프롬프트를 수정합니다. 반복이 중요합니다. 먼저 핵심 아이디어를 설정하고 생성된 이미지가 비전에 가까워질 때까지 핵심 아이디어를 미세 조정하고 확장합니다.

|

|

|
Imagen 모델은 프롬프트가 짧든 길든 상관없이 아이디어를 세부적인 이미지로 변환할 수 있습니다. 반복적인 프롬프트를 통해 비전을 수정하고 완벽한 결과를 얻을 때까지 세부정보를 추가합니다.
|
짧은 프롬프트를 사용하면 이미지를 빠르게 생성할 수 있습니다. 
|
프롬프트를 길게 입력하면 구체적인 세부정보를 추가하고 이미지를 만들 수 있습니다. 
|
Imagen 프롬프트 작성을 위한 추가 도움말:
- 설명적인 언어 사용: 자세한 형용사와 부사를 사용하여 Imagen에서 명확한 그림을 그릴 수 있도록 합니다.
- 맥락 정보 제공: 필요한 경우 AI의 이해를 돕기 위한 배경 정보를 포함합니다.
- 특정 아티스트 또는 스타일 참조: 특정 스타일을 원한다면 특정 아티스트나 예술 운동을 참조하는 것이 도움이 될 수 있습니다.
- 프롬프트 엔지니어링 도구 사용: 프롬프트를 미세 조정하고 최적의 결과를 얻는 데 도움이 되는 프롬프트 엔지니어링 도구 또는 리소스를 살펴보세요.
- 개인 및 그룹 이미지의 얼굴 세부정보 개선: 얼굴 세부정보를 사진의 초점으로 지정합니다 (예: 프롬프트에서 '인물 사진'이라는 단어 사용).
이미지에 텍스트 생성
Imagen 모델은 이미지에 텍스트를 추가할 수 있어 더 창의적인 이미지 생성 가능성을 열어줍니다. 다음 안내에 따라 이 기능을 최대한 활용하세요.
- 확신있게 반복: 원하는 모양이 나올 때까지 이미지를 다시 생성해야 할 수 있습니다. Imagen의 텍스트 통합은 아직 발전 중이며, 여러 번 시도해 보면 최상의 결과를 얻을 수 있습니다.
- 간단하게 유지: 최적의 생성을 위해 텍스트를 25자(영문 기준) 이하로 제한합니다.
여러 문구: 두 개 또는 세 개의 다른 문구를 실험하여 추가 정보를 제공합니다. 더 깔끔한 구성을 위해 구문 수를 3개 이하로 유지하세요.

프롬프트: 'Summerland'라는 텍스트가 굵은 서체로 제목으로 표시된 포스터이며 이 텍스트 아래에 'Summer never felt so good'이라는 슬로건이 있습니다. 배치 안내: Imagen이 지시에 따라 텍스트를 배치하려고 시도할 수 있지만 가끔씩 텍스트가 다르게 배치될 수 있습니다. 이 기능은 지속적으로 개선되고 있습니다.
글꼴 스타일에 영감 주기: 일반적인 글꼴 스타일을 지정하여 Imagen의 선택에 미묘하게 영향을 미칩니다. 글꼴이 정확하게 복제되지 않고 창의적으로 해석될 수 있습니다.
글꼴 크기: 글꼴 크기 또는 크기의 일반적인 표시(예: 작음, 중간, 큼)를 지정하여 글꼴 크기 생성에 영향을 미칩니다.
프롬프트 파라미터화
출력 결과를 더 효과적으로 제어하려면 Imagen에 입력을 파라미터화하는 것이 좋습니다. 예를 들어 고객이 비즈니스용 로고를 생성할 수 있도록 하려는 경우 로고가 항상 단색 배경에서 생성되도록 하려고 합니다. 또한 고객이 메뉴에서 선택할 수 있는 옵션을 제한하려고 합니다.
이 예시에서는 다음과 유사한 파라미터화된 프롬프트를 만들 수 있습니다.
A {logo_style} logo for a {company_area} company on a solid color background. Include the text {company_name}.커스텀 사용자 인터페이스에서 고객은 메뉴를 사용하여 파라미터를 입력할 수 있으며, 선택한 값이 Imagen이 수신하는 프롬프트에 채워집니다.
예를 들면 다음과 같습니다.
프롬프트:
A minimalist logo for a health care company on a solid color background. Include the text Journey.
프롬프트:
A modern logo for a software company on a solid color background. Include the text Silo.
프롬프트:
A traditional logo for a baking company on a solid color background. Include the text Seed.
고급 프롬프트 작성 기법
다음 예시를 사용하여 사진 설명자, 모양 및 재료, 역사적 예술 움직임, 이미지 품질 수정자와 같은 속성에 따라 보다 구체적인 프롬프트를 만드세요.
사진
- 프롬프트에 포함: '...의 사진'
이 스타일을 사용하려면 먼저 Imagen에 사진을 찾고 있음을 명확하게 알리는 키워드를 사용하여 시작합니다. 다음과 같이 프롬프트에 명기합니다. '. . .의 사진'. 예를 들면 다음과 같습니다.

|

|

|
이미지 소스: 각 이미지는 Imagen 4 모델로 해당 텍스트 프롬프트를 사용하여 생성되었습니다.
사진 수정자
다음 예시에서는 여러 사진 관련 수정자와 파라미터를 볼 수 있습니다. 여러 수정자를 결합하여 더 정밀하게 제어할 수 있습니다.
카메라 근접성 - 클로즈업, 멀리서 촬영

프롬프트: 커피 원두의 클로즈업 사진 
프롬프트: 어질러진 주방에 있는 작은 커피 원두 봉지의
축소된 사진카메라 위치 - 공중, 아래에서

프롬프트: 고층 빌딩이 있는 도시의 항공사진 
프롬프트: 아래에서 찍은 파란색 하늘이 보이는 숲 사진 조명 - 자연스럽고, 극적이며, 따뜻하고, 차가운

프롬프트: 현대적인 안락의자의 스튜디오 사진, 자연광 
프롬프트: 현대적인 안락의자의 스튜디오 사진, 극적인 조명 카메라 설정 - 모션 블러, 소프트 포커스, 보케, 인물 사진

프롬프트: 모션 블러 설정으로 차량 내부에서 찍은 초고층 빌딩이 있는 도시의 사진 
프롬프트: 소프트 포커스 설정으로 야간에 찍은 도시의 다리 사진 렌즈 유형 - 35mm, 50mm, 어안, 광각, 매크로

프롬프트: 매크로 렌즈로 찍은 나뭇잎 사진 
프롬프트: 어안 렌즈로 찍은 뉴욕 거리 사진 필름 유형 - 흑백, 폴라로이드

프롬프트: 선글라스를 쓴 강아지의 폴라로이드 사진 
프롬프트: 선글라스를 쓴 강아지의 흑백 사진
이미지 소스: 각 이미지는 Imagen 4 모델로 해당 텍스트 프롬프트를 사용하여 생성되었습니다.
삽화 및 아트
- 프롬프트에 포함: '..의 painting', 또는 '...의 sketch'
아트 스타일은 연필 스케치와 같은 흑백 스타일부터 초현실적인 디지털 아트까지 다양합니다. 예를 들어 다음 이미지는 다양한 스타일에서 동일한 프롬프트를 사용합니다.
"고층 빌딩 배경의 각진 스포티 전기 세단의 [art style or creation technique]"

|

|

|

|

|

|
이미지 소스: 각 이미지는 Imagen 2 모델로 해당 텍스트 프롬프트를 사용하여 생성되었습니다.
모양 및 재료
- 프롬프트에는 '...만든...', '...의 형태로...'가 포함됩니다.
이 기술의 강점 중 하나는 만들기 어렵거나 불가능한 이미지를 만들 수 있다는 것입니다. 예를 들어 회사 로고를 다양한 재료와 질감으로 다시 만들 수 있습니다.

|

|

|
이미지 소스: 각 이미지는 Imagen 4 모델로 해당 텍스트 프롬프트를 사용하여 생성되었습니다.
역사적 아트 참조
- 프롬프트에는 '...스타일로..'가 포함됩니다.
특정 스타일은 수년에 걸쳐 상징으로 자리잡았습니다. 다음은 시도해 볼 수 있는 역사적인 페인팅 또는 아트 스타일에 대한 아이디어입니다.
'[art period or movement] 스타일의 이미지 생성: 풍력 발전소'

|

|

|
이미지 소스: 각 이미지는 Imagen 4 모델로 해당 텍스트 프롬프트를 사용하여 생성되었습니다.
이미지 품질 수정자
특정 키워드를 사용하면 모델에서 고품질 애셋을 찾고 있다는 것을 알 수 있습니다. 품질 수정자의 예시는 다음과 같습니다.
- 일반 수정자 - 고품질, 아름다움, 스타일
- 사진 - 4K, HDR, 스튜디오 사진
- 아트, 삽화 - 전문가, 상세
다음은 품질 수정자가 없는 프롬프트와 품질 수정자가 포함된 동일한 프롬프트의 몇 가지 예시입니다.

|

옥수수대의 아름다운 4k HDR 사진 |
이미지 소스: 각 이미지는 Imagen 4 모델로 해당 텍스트 프롬프트를 사용하여 생성되었습니다.
가로세로 비율
Imagen 이미지 생성을 사용하면 고유한 이미지 가로세로 비율 5개를 설정할 수 있습니다.
- 정사각형(1:1, 기본값) - 표준 정사각형 사진입니다. 이 가로세로 비율의 일반적인 용도는 소셜 미디어 게시물입니다.
전체 화면(4:3) - 이 가로세로 비율은 미디어나 영화에서 일반적으로 사용됩니다. 또한 대부분의 구형(와이드스크린) TV와 중형 카메라의 크기입니다. 1:1에 비해 더 많은 장면을 수평으로 캡처하므로 사진에 선호되는 가로세로 비율이 가능합니다.

프롬프트: 피아노를 연주하는 뮤지션의 손가락 클로즈업, 흑백 영화, 빈티지 (4:3 가로세로 비율) 
프롬프트: 고급 레스토랑 감자 튀김의 전문 스튜디오 사진, 음식 잡지 스타일(가로세로 비율 4:3) 세로 전체 화면(3:4) - 90도 회전된 전체 화면 가로세로 비율입니다. 이 비율에서는 1:1 가로세로 비율과 비교할 때 세로로 더 많은 장면을 캡처할 수 있습니다.

프롬프트: 등산 중인 여성, 가까운 물웅덩이에 부츠가 반사됨, 배경에 큰 산, 광고 스타일, 드라마틱 앵글 (가로세로 비율 3:4) 
프롬프트: 신비한 계곡으로 흐르는 강의 항공 사진 (가로세로 비율 3:4) 와이드스크린(16:9) - 이 비율은 4:3을 대체하며, 현재 TV, 모니터, 휴대전화 화면(가로 모드)에서 가장 일반적으로 사용되는 가로세로 비율입니다. 배경 사진을 더 많이 캡처하려면 이 가로세로 비율을 사용합니다(예: 풍경 사진).

프롬프트: 해변에 앉아 있는 순백색 옷을 입은 남성, 클로즈업, 골든아워 조명 (16:9 가로세로 비율) 세로 모드(9:16) - 이 비율은 회전된 와이드스크린입니다. 이 가로세로 비율은 짧은 형식 동영상 앱(예: YouTube Shorts)에서 인기가 있는 비교적 새로운 가로세로 비율입니다. 건물, 나무, 폭포 또는 기타 유사한 객체와 같이 수직 방향이 강한 긴 객체에 사용합니다.

프롬프트: 거대한 초고층 빌딩의 디지털 렌더링, 현대적, 아름답고 웅장한 일몰 배경 (9:16 가로세로 비율)
실사형 이미지
이미지 생성 모델의 각 버전은 예술적이고 실제 사진과 같은 결과를 혼합해서 제공할 수 있습니다. 프롬프트에서 다음 문구를 사용하여 생성하려는 주제를 기반으로 보다 사실적인 출력을 생성합니다.
| 사용 사례 | 렌즈 유형 | 초점 거리 | 추가 세부정보 |
|---|---|---|---|
| 사람(세로 모드) | Prime, 확대/축소 | 24~35mm | 흑백 촬영, 느와르 촬영, 피사계 심도, 듀오톤(두 가지 색상 언급) |
| 음식, 곤충, 식물(객체, 정물) | 매크로 | 60~105mm | 높은 정밀도, 정밀한 초점, 제어된 조명 |
| 스포츠, 야생 동물(모션) | 망원 확대/축소 | 100~400mm | 빠른 셔터 속도, 동작 또는 움직임 추적 |
| 천문, 가로 모드(광각) | 광각 | 10~24mm | 긴 노출 시간, 선명한 초점, 긴 노출, 잔잔한 물 또는 구름 |
초상화
| 사용 사례 | 렌즈 유형 | 초점 거리 | 추가 세부정보 |
|---|---|---|---|
| 사람(세로 모드) | Prime, 확대/축소 | 24~35mm | 흑백 촬영, 느와르 촬영, 피사계 심도, 듀오톤(두 가지 색상 언급) |
Imagen은 테이블의 여러 키워드를 사용하여 다음과 같은 세로 모드를 생성할 수 있습니다.

|

|

|

|
프롬프트: 여성, 35mm 세로 모드, 파란색 및 회색 듀오톤
모델: imagen-4.0-generate-001

|

|

|

|
프롬프트: 여성, 35mm 세로 모드, 느와르 촬영
모델: imagen-4.0-generate-001
사물
| 사용 사례 | 렌즈 유형 | 초점 거리 | 추가 세부정보 |
|---|---|---|---|
| 음식, 곤충, 식물(객체, 정물) | 매크로 | 60~105mm | 높은 정밀도, 정밀한 초점, 제어된 조명 |
Imagen은 테이블의 여러 키워드를 사용하여 다음과 같은 객체 이미지를 생성할 수 있습니다.

|

|

|

|
프롬프트: 마란타의 잎, 매크로 렌즈, 60mm
모델: imagen-4.0-generate-001

|

|

|

|
프롬프트: 파스타 접시, 100mm 매크로 렌즈
모델: imagen-4.0-generate-001
모션
| 사용 사례 | 렌즈 유형 | 초점 거리 | 추가 세부정보 |
|---|---|---|---|
| 스포츠, 야생 동물(모션) | 망원 확대/축소 | 100~400mm | 빠른 셔터 속도, 동작 또는 움직임 추적 |
Imagen은 테이블의 여러 키워드를 사용하여 다음과 같은 모션 이미지를 생성할 수 있습니다.

|

|
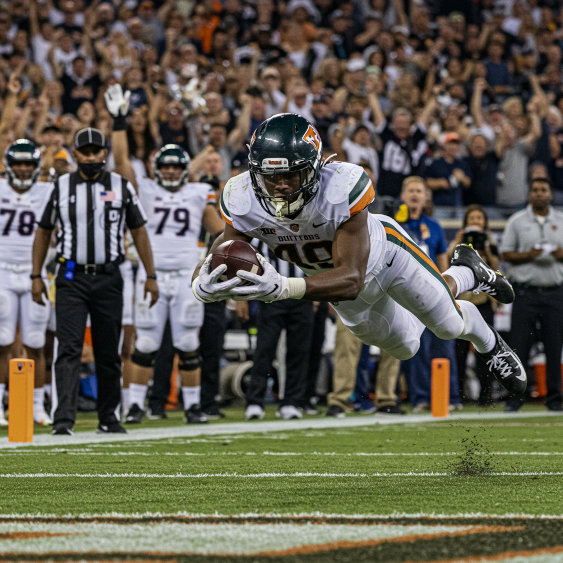
|

|
프롬프트: 승리의 터치다운, 빠른 셔터 속도, 움직임 추적
모델: imagen-4.0-generate-001

|

|

|

|
프롬프트: 숲 속을 달리는 사슴, 빠른 셔터 속도, 움직임 추적
모델: imagen-4.0-generate-001
광각
| 사용 사례 | 렌즈 유형 | 초점 거리 | 추가 세부정보 |
|---|---|---|---|
| 천문, 가로 모드(광각) | 광각 | 10~24mm | 긴 노출 시간, 선명한 초점, 긴 노출, 잔잔한 물 또는 구름 |
Imagen은 테이블의 여러 키워드를 사용하여 다음과 같은 광각 이미지를 생성할 수 있습니다.

|

|

|

|
프롬프트: 광활한 산맥, 가로 모드 광각 10mm
모델: imagen-4.0-generate-001

|

|

|

|
프롬프트: 달 사진, 천체 사진, 광각 10mm
모델: imagen-4.0-generate-001