Gemini Robotics-ER 1.6 یک مدل زبان بینایی (VLM) است که قابلیتهای عاملمحور Gemini را به رباتیک میآورد. این مدل برای استدلال پیشرفته در دنیای فیزیکی طراحی شده است و به رباتها اجازه میدهد دادههای بصری پیچیده را تفسیر کنند، استدلال فضایی انجام دهند و اقدامات را از طریق دستورات زبان طبیعی برنامهریزی کنند.
توجه داشته باشید که اگر از Gemini Robotics-ER 1.5 استفاده میکردید، میتوانید با جایگزینی نام مدل از model="gemini-robotics-er-1.5-preview" به model="gemini-robotics-er-1.6-preview" در فراخوانی API، استفاده از مدل ۱.۶ را شروع کنید.
ویژگیها و مزایای کلیدی:
- خودمختاری پیشرفته: رباتها میتوانند در محیطهای باز، استدلال کنند، سازگار شوند و به تغییرات پاسخ دهند.
- تعامل با زبان طبیعی: با فعال کردن انجام وظایف پیچیده با استفاده از زبان طبیعی، استفاده از رباتها را آسانتر میکند.
- هماهنگسازی وظایف: دستورات زبان طبیعی را به زیروظایف تجزیه میکند و با کنترلکنندهها و رفتارهای موجود ربات ادغام میشود تا وظایف بلندمدت را انجام دهد.
- قابلیتهای چندمنظوره: اشیاء را مکانیابی و شناسایی میکند، روابط اشیاء را درک میکند، برای گرفتن و مسیر حرکت آنها برنامهریزی میکند و صحنههای پویا را تفسیر میکند.
این سند شرح میدهد که این مدل چه کاری انجام میدهد و شما را با چندین مثال آشنا میکند که قابلیتهای عاملانهی این مدل را برجسته میکند.
اگر میخواهید مستقیماً شروع کنید، میتوانید مدل را در Google AI Studio امتحان کنید.
در استودیوی هوش مصنوعی گوگل امتحان کنید
ایمنی
اگرچه Gemini Robotics-ER 1.6 با در نظر گرفتن ایمنی ساخته شده است، اما مسئولیت حفظ محیط امن در اطراف ربات بر عهده شماست. مدلهای هوش مصنوعی مولد میتوانند اشتباه کنند و رباتهای فیزیکی میتوانند باعث آسیب شوند. ایمنی یک اولویت است و ایمنسازی مدلهای هوش مصنوعی مولد هنگام استفاده با رباتیک دنیای واقعی، یک حوزه فعال و حیاتی از تحقیقات ما است. برای کسب اطلاعات بیشتر، به صفحه ایمنی رباتیک Google DeepMind مراجعه کنید.
شروع کار: پیدا کردن اشیاء در یک صحنه
مثال زیر یک مورد استفاده رایج در رباتیک را نشان میدهد. این مثال نشان میدهد که چگونه میتوان با استفاده از متد generateContent یک تصویر و یک متن را به مدل ارسال کرد تا لیستی از اشیاء شناسایی شده به همراه نقاط دوبعدی مربوطهشان را دریافت کرد. مدل، نقاط مربوط به مواردی را که در یک تصویر شناسایی کرده است، به همراه مختصات و برچسبهای دوبعدی نرمال شده آنها، برمیگرداند.
شما میتوانید از این خروجی با یک API رباتیک استفاده کنید یا یک مدل بینایی-زبان-عمل (VLA) یا هر تابع تعریفشده توسط کاربر شخص ثالث دیگری را فراخوانی کنید تا اقداماتی را برای انجام توسط ربات ایجاد کنید.
پایتون
from google import genai
from google.genai import types
PROMPT = """
Point to no more than 10 items in the image. The label returned
should be an identifying name for the object detected.
The answer should follow the json format: [{"point": <point>,
"label": <label1>}, ...]. The points are in [y, x] format
normalized to 0-1000.
"""
client = genai.Client()
# Load your image
with open("my-image.png", 'rb') as f:
image_bytes = f.read()
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/png',
),
PROMPT
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
استراحت
# First, ensure you have the image file locally.
# Encode the image to base64
IMAGE_BASE64=$(base64 -w 0 my-image.png)
curl -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-robotics-er-1.6-preview:generateContent \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [
{
"parts": [
{
"inlineData": {
"mimeType": "image/png",
"data": "'"${IMAGE_BASE64}"'"
}
},
{
"text": "Point to no more than 10 items in the image. The label returned should be an identifying name for the object detected. The answer should follow the json format: [{\"point\": [y, x], \"label\": <label1>}, ...]. The points are in [y, x] format normalized to 0-1000."
}
]
}
],
"generationConfig": {
"temperature": 0.5,
"thinkingConfig": {
"thinkingBudget": 0
}
}
}'
خروجی یک آرایه JSON حاوی اشیاء خواهد بود که هر کدام دارای یک point (مختصات نرمال شده [y, x] ) و یک label شناسایی کننده شیء هستند.
جیسون
[
{"point": [376, 508], "label": "small banana"},
{"point": [287, 609], "label": "larger banana"},
{"point": [223, 303], "label": "pink starfruit"},
{"point": [435, 172], "label": "paper bag"},
{"point": [270, 786], "label": "green plastic bowl"},
{"point": [488, 775], "label": "metal measuring cup"},
{"point": [673, 580], "label": "dark blue bowl"},
{"point": [471, 353], "label": "light blue bowl"},
{"point": [492, 497], "label": "bread"},
{"point": [525, 429], "label": "lime"}
]
تصویر زیر نمونهای از نحوه نمایش این نقاط است:

چگونه کار میکند؟
Gemini Robotics-ER 1.6 به رباتهای شما اجازه میدهد تا با استفاده از درک فضایی، دنیای فیزیکی را درک کرده و در آن کار کنند. این نرمافزار با دریافت ورودی تصویر/ویدئو/صوت و زبان طبیعی، موارد زیر را انجام میدهد:
- درک اشیاء و زمینه صحنه : اشیاء را شناسایی میکند و دلایل ارتباط آنها با صحنه، از جمله کاراییهای آنها را بیان میکند.
- دستورالعملهای انجام وظیفه را میفهمد : وظایف داده شده به زبان طبیعی، مانند «موز را پیدا کن» را تفسیر میکند.
- استدلال مکانی و زمانی : توالی اعمال و نحوه تعامل اشیاء با یک صحنه در طول زمان را درک کنید.
- ارائه خروجی ساختاریافته : مختصات (نقاط یا کادرهای محصورکننده) نشاندهنده مکانهای شیء را برمیگرداند.
این امر رباتها را قادر میسازد تا محیط خود را به صورت برنامهریزیشده «ببینند» و «درک» کنند.
Gemini Robotics-ER 1.6 همچنین عاملگرا است، به این معنی که میتواند وظایف پیچیده (مانند "سیب را در کاسه قرار دهید") را به وظایف فرعی تقسیم کند تا وظایف بلندمدت را هماهنگ کند:
- توالیبندی زیروظایف : دستورات را به یک توالی منطقی از مراحل تجزیه میکند.
- فراخوانی توابع/اجرای کد : مراحل را با فراخوانی توابع/ابزارهای ربات موجود یا اجرای کد تولید شده اجرا میکند.
برای اطلاعات بیشتر در مورد نحوه فراخوانی تابع با Gemini، به صفحه فراخوانی تابع مراجعه کنید.
استفاده از بودجه فکری با Gemini Robotics-ER 1.6
Gemini Robotics-ER 1.6 دارای یک بودجه تفکر انعطافپذیر است که به شما امکان کنترل بر روی بدهبستانهای تأخیر در مقابل دقت را میدهد. برای وظایف درک فضایی مانند تشخیص اشیاء، این مدل میتواند با یک بودجه تفکر کوچک به عملکرد بالایی دست یابد. وظایف استدلال پیچیدهتر مانند شمارش و تخمین وزن از یک بودجه تفکر بزرگتر بهرهمند میشوند. این به شما امکان میدهد تا نیاز به پاسخهای با تأخیر کم را با نتایج با دقت بالا برای وظایف چالشبرانگیزتر متعادل کنید.
برای کسب اطلاعات بیشتر در مورد بودجهبندیهای متفکرانه، به صفحه قابلیتهای اصلی متفکرانه مراجعه کنید.
استدلال مکانی استاندارد
مثالهای زیر وظایف مربوط به ادراک رباتیک و استدلال فضایی را با استفاده از دستورات زبان طبیعی نشان میدهند، از اشاره کردن و یافتن اشیاء در یک تصویر گرفته تا برنامهریزی مسیرها. برای سادگی، قطعه کدهای موجود در این مثالها به گونهای کاهش یافتهاند که فقط دستورات و فراخوانی API مربوط به generate_content را نشان دهند.
کد کامل قابل اجرا و همچنین مثالهای اضافی را میتوانید در کتاب آشپزی رباتیک پیدا کنید.
اشاره به اشیاء
اشاره کردن و پیدا کردن اشیاء در تصاویر یا فریمهای ویدیویی، یک مورد استفاده رایج برای مدلهای بینایی و زبان (VLM) در رباتیک است. مثال زیر از مدل میخواهد که اشیاء خاصی را در یک تصویر پیدا کند و مختصات آنها را برگرداند.
پایتون
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
queries = [
"bread",
"starfruit",
"banana",
]
prompt = f"""
Get all points matching the following objects: {', '.join(queries)}. The
label returned should be an identifying name for the object detected.
The answer should follow the json format:
[{{"point": , "label": }}, ...]. The points are in
[y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
خروجی مشابه مثال شروع کار خواهد بود، یک JSON حاوی مختصات اشیاء یافت شده و برچسبهای آنها.
[
{"point": [671, 317], "label": "bread"},
{"point": [738, 307], "label": "bread"},
{"point": [702, 237], "label": "bread"},
{"point": [629, 307], "label": "bread"},
{"point": [833, 800], "label": "bread"},
{"point": [609, 663], "label": "banana"},
{"point": [770, 483], "label": "starfruit"}
]

از دستور زیر برای درخواست از مدل جهت تفسیر دستههای انتزاعی مانند "میوه" به جای اشیاء خاص و یافتن تمام نمونهها در تصویر استفاده کنید.
پایتون
prompt = f"""
Get all points for fruit. The label returned should be an identifying
name for the object detected.
""" + """The answer should follow the json format:
[{"point": <point>, "label": <label1>}, ...]. The points are in
[y, x] format normalized to 0-1000."""
برای سایر تکنیکهای پردازش تصویر، به صفحه درک تصویر مراجعه کنید.
ردیابی اشیاء در یک ویدیو
Gemini Robotics-ER 1.6 همچنین میتواند فریمهای ویدیویی را برای ردیابی اشیاء در طول زمان تجزیه و تحلیل کند. برای مشاهده لیست فرمتهای ویدیویی پشتیبانی شده، به ورودیهای ویدیویی مراجعه کنید.
دستور پایه زیر برای یافتن اشیاء خاص در هر فریمی که مدل تجزیه و تحلیل میکند، استفاده میشود:
پایتون
# Define the objects to find
queries = [
"pen (on desk)",
"pen (in robot hand)",
"laptop (opened)",
"laptop (closed)",
]
base_prompt = f"""
Point to the following objects in the provided image: {', '.join(queries)}.
The answer should follow the json format:
[{{"point": , "label": }}, ...].
The points are in [y, x] format normalized to 0-1000.
If no objects are found, return an empty JSON list [].
"""
خروجی، حرکت یک خودکار و لپتاپ را در فریمهای ویدیویی نشان میدهد.
![]()
برای کد کامل قابل اجرا، به کتاب آشپزی رباتیک مراجعه کنید.
تشخیص شیء و جعبههای محدودکننده
فراتر از نقاط منفرد، این مدل همچنین میتواند جعبههای مرزی دوبعدی را برگرداند و یک ناحیه مستطیلی محصورکننده یک شیء را ارائه دهد.
این مثال، کادرهای مرزی دوبعدی را برای اشیاء قابل شناسایی روی یک جدول درخواست میکند. به مدل دستور داده شده است که خروجی را به ۲۵ شیء محدود کند و چندین نمونه را به صورت منحصر به فرد نامگذاری کند.
پایتون
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Return bounding boxes as a JSON array with labels. Never return masks
or code fencing. Limit to 25 objects. Include as many objects as you
can identify on the table.
If an object is present multiple times, name them according to their
unique characteristic (colors, size, position, unique characteristics, etc..).
The format should be as follows: [{"box_2d": [ymin, xmin, ymax, xmax],
"label": <label for the object>}] normalized to 0-1000. The values in
box_2d must only be integers
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
در ادامه، جعبههای برگردانده شده از مدل نمایش داده میشوند.
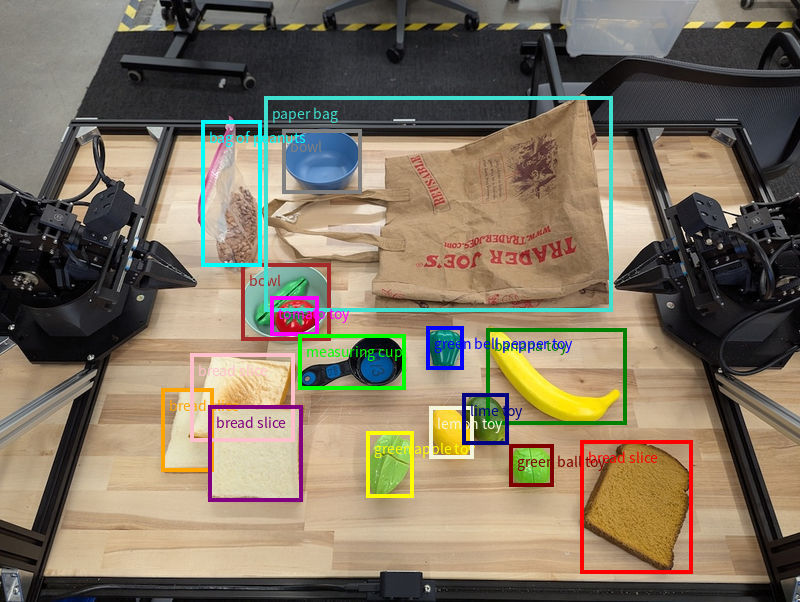
برای کد کامل قابل اجرا، به کتاب آشپزی رباتیک مراجعه کنید. صفحه درک تصویر همچنین مثالهای بیشتری از وظایف بصری مانند تشخیص اشیا و مثالهای کادر محصورکننده دارد.
مسیرها
Gemini Robotics-ER 1.6 میتواند توالیهایی از نقاط را ایجاد کند که یک مسیر را تعریف میکنند و برای هدایت حرکت ربات مفید هستند.
این مثال یک مسیر برای حرکت یک خودکار قرمز به یک سازماندهنده، شامل نقطه شروع و مجموعهای از نقاط میانی، درخواست میکند.
پایتون
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
points_data = []
prompt = """
Place a point on the red pen, then 15 points for the trajectory of
moving the red pen to the top of the organizer on the left.
The points should be labeled by order of the trajectory, from '0'
(start point at left hand) to <n> (final point)
The answer should follow the json format:
[{"point": <point>, "label": <label1>}, ...].
The points are in [y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
)
)
print(image_response.text)
پاسخ، مجموعهای از مختصات است که مسیر مسیری را که خودکار قرمز باید برای تکمیل وظیفه حرکت دادن آن روی سازماندهنده دنبال کند، توصیف میکند:
[
{"point": [550, 610], "label": "0"},
{"point": [500, 600], "label": "1"},
{"point": [450, 590], "label": "2"},
{"point": [400, 580], "label": "3"},
{"point": [350, 550], "label": "4"},
{"point": [300, 520], "label": "5"},
{"point": [250, 490], "label": "6"},
{"point": [200, 460], "label": "7"},
{"point": [180, 430], "label": "8"},
{"point": [160, 400], "label": "9"},
{"point": [140, 370], "label": "10"},
{"point": [120, 340], "label": "11"},
{"point": [110, 320], "label": "12"},
{"point": [105, 310], "label": "13"},
{"point": [100, 305], "label": "14"},
{"point": [100, 300], "label": "15"}
]

قابلیتهای عاملمحور
مثالهای زیر استدلال رباتیک پیشرفته را با استفاده از قابلیتهای عاملمحور مدل، بهویژه اجرای کد ، نشان میدهند. در این سناریوها، مدل میتواند تصمیم بگیرد که کد پایتون را برای دستکاری تصاویر (مانند بزرگنمایی، برش یا چرخش) بنویسد و اجرا کند تا ابهامات را برطرف کند یا دقت را قبل از پاسخ دادن بهبود بخشد.
تشخیص اشیا (بزرگنمایی و برش)
مثال زیر نحوه استفاده از اجرای کد برای بزرگنمایی و برش تصویر برای نمای واضحتر هنگام تشخیص اشیاء و بازگرداندن کادرهای محصورکننده را نشان میدهد.
پایتون
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('sorting.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
Return JSON in the format {label: val, y: val, x: val, y2: val, x2: val} for
the compostable objects in this scene. Please Zoom and crop the image for a
clearer view. Return an annotated image of the final result with the bounding
boxes drawn on it to the API caller as a part of your process.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
خروجی مدل مشابه زیر خواهد بود:
[
{"label": "compostable", "y": 256, "x": 482, "y2": 295, "x2": 546},
{"label": "compostable", "y": 317, "x": 478, "y2": 350, "x2": 542},
{"label": "compostable", "y": 586, "x": 556, "y2": 668, "x2": 595},
{"label": "compostable", "y": 463, "x": 669, "y2": 511, "x2": 718},
{"label": "compostable", "y": 178, "x": 565, "y2": 250, "x2": 609}
]
در ادامه، جعبههای برگردانده شده از مدل نمایش داده میشوند.

خواندن یک گیج آنالوگ و اعمال منطق
مثال زیر نحوه استفاده از مدل برای خواندن یک گیج آنالوگ و انجام محاسبات زمان را نشان میدهد. این مدل از یک دستورالعمل سیستمی برای اعمال خروجی JSON استفاده میکند.
پایتون
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('clock.jpg', 'rb') as f:
image_bytes = f.read()
q_time = """
Tell me what the value is. Please respond in the following JSON format:\n {\n "hours": X,\n "minutes": Y,\n}. Zoom in or crop as necessary to confirm location of the clock hands.
"""
system_instruction = "Be precise. When JSON is requested, reply with ONLY that JSON (no preface, no code block)."
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
system_instruction + " " + q_time
],
config = types.GenerateContentConfig(
temperature=1.0,
)
)
print(response.text)
در ادامه نمونهای از ورودی تصویر آمده است.

خروجی مدل مشابه زیر خواهد بود:
Time Response: {
"hours": 12,
"minutes": 44
}
مایع را در ظرف اندازه گیری کنید
مثال زیر نحوه استفاده از اجرای کد برای خواندن کنتور و محاسبه سطح مایع به صورت درصد را نشان میدهد.
پایتون
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('meter.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
How full is the meter of liquid?
To read it,
1) Find the points for the top of the sight window, bottom of the sight window and the liquid level, formatted as [y, x] with values ranging from 0-1000;
2) Use math to determine the liquid level as a percentage;
3) Output "Answer: ??" on a separate line, where ?? is a number without % or unit.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
تصویر بزرگنمایی شده ورودی در زیر آمده است.

خواندن علائم روی برد مدار چاپی
مثال زیر نحوه استفاده از اجرای کد برای خواندن متن روی تراشه برد مدار را نشان میدهد و به مدل اجازه میدهد تصویر را در صورت نیاز بزرگنمایی، برش و چرخش دهد.
پایتون
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('circuit_board.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = "What is the number on the ESMT chip? Zoom, crop, and rotate if needed."
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
تصویر بزرگنمایی شده ورودی در زیر آمده است.

حاشیهنویسی تصویر
مثال زیر نحوه استفاده از اجرای کد برای حاشیهنویسی یک تصویر (مثلاً رسم فلش برای دستورالعملهای دفع) و بازگرداندن تصویر اصلاحشده را نشان میدهد.
پایتون
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('sorting.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
Look at this image and return it as an annotated version using arrows of
different colors to represent which items should go in which bins for
disposal. You must return the final image to the API caller.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
در ادامه نمونهای از ورودی تصویر آمده است.

خروجی مدل مشابه زیر خواهد بود:
The annotated image shows the suggested disposal locations for the items on the table:
- **Green bin (Compost/Organic)**: Green chili, red chili, grapes, and cherries.
- **Blue bin (Recycling)**: Yellow crushed can and plastic container.
- **Black bin (Trash)**: Chocolate bar wrapper, Welch's packet, and white tissue.
ارکستراسیون
Gemini Robotics-ER 1.6 میتواند برنامهریزی وظایف و استدلال مکانی سطح بالا را انجام دهد، اقدامات را استنتاج کند یا مکانهای بهینه را بر اساس درک زمینهای برای هماهنگسازی وظایف بلندمدت شناسایی کند.
ایجاد فضای کافی برای لپتاپ
این مثال نشان میدهد که چگونه Gemini Robotics-ER میتواند در مورد یک فضا استدلال کند. این اعلان از مدل میخواهد که مشخص کند کدام شیء باید جابجا شود تا فضا برای یک مورد دیگر ایجاد شود.
پایتون
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Point to the object that I need to remove to make room for my laptop
The answer should follow the json format: [{"point": <point>,
"label": <label1>}, ...]. The points are in [y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
پاسخ شامل مختصات دوبعدی شیء است که به سوال کاربر پاسخ میدهد، در این مورد، شیءای که باید حرکت کند تا جایی برای لپتاپ ایجاد شود.
[
{"point": [672, 301], "label": "The object that I need to remove to make room for my laptop"}
]

بسته بندی ناهار
این مدل همچنین میتواند دستورالعملهایی برای کارهای چند مرحلهای ارائه دهد و برای هر مرحله به اشیاء مربوطه اشاره کند. این مثال نشان میدهد که چگونه مدل مجموعهای از مراحل را برای بستهبندی یک کیسه ناهار برنامهریزی میکند.
پایتون
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-of-lunch.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Explain how to pack the lunch box and lunch bag. Point to each
object that you refer to. Each point should be in the format:
[{"point": [y, x], "label": }], where the coordinates are
normalized between 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
پاسخ این سوال، مجموعهای از دستورالعملهای گام به گام در مورد نحوه بستهبندی کیسه ناهار از ورودی تصویر است.
تصویر ورودی

خروجی مدل
Based on the image, here is a plan to pack the lunch box and lunch bag:
1. **Pack the fruit into the lunch box.** Place the [apple](apple), [banana](banana), [red grapes](red grapes), and [green grapes](green grapes) into the [blue lunch box](blue lunch box).
2. **Add the spoon to the lunch box.** Put the [blue spoon](blue spoon) inside the lunch box as well.
3. **Close the lunch box.** Secure the lid on the [blue lunch box](blue lunch box).
4. **Place the lunch box inside the lunch bag.** Put the closed [blue lunch box](blue lunch box) into the [brown lunch bag](brown lunch bag).
5. **Pack the remaining items into the lunch bag.** Place the [blue snack bar](blue snack bar) and the [brown snack bar](brown snack bar) into the [brown lunch bag](brown lunch bag).
Here is the list of objects and their locations:
* [{"point": [899, 440], "label": "apple"}]
* [{"point": [814, 363], "label": "banana"}]
* [{"point": [727, 470], "label": "red grapes"}]
* [{"point": [675, 608], "label": "green grapes"}]
* [{"point": [706, 529], "label": "blue lunch box"}]
* [{"point": [864, 517], "label": "blue spoon"}]
* [{"point": [499, 401], "label": "blue snack bar"}]
* [{"point": [614, 705], "label": "brown snack bar"}]
* [{"point": [448, 501], "label": "brown lunch bag"}]
فراخوانی یک API ربات سفارشی
این مثال، هماهنگسازی وظایف را با یک API ربات سفارشی نشان میدهد. این مثال یک API شبیهسازی شده را معرفی میکند که برای عملیات برداشتن و گذاشتن طراحی شده است. وظیفه این است که یک بلوک آبی را برداشته و آن را در یک کاسه نارنجی قرار دهید:

مشابه سایر مثالهای این صفحه، کد کامل قابل اجرا در کتاب آشپزی رباتیک موجود است.
اولین قدم این است که هر دو مورد را با استفاده از دستور زیر پیدا کنید:
پایتون
prompt = """
Locate and point to the blue block and the orange bowl. The label
returned should be an identifying name for the object detected.
The answer should follow the json format: [{"point": <point>, "label": <label1>}, ...].
The points are in [y, x] format normalized to 0-1000.
"""
پاسخ مدل شامل مختصات نرمالشده بلوک و کاسه است:
[
{"point": [389, 252], "label": "orange bowl"},
{"point": [727, 659], "label": "blue block"}
]
این مثال از API ربات شبیهسازیشدهی زیر استفاده میکند:
پایتون
def move(x, y, high):
print(f"moving to coordinates: {x}, {y}, {15 if high else 5}")
def setGripperState(opened):
print("Opening gripper" if opened else "Closing gripper")
def returnToOrigin():
print("Returning to origin pose")
مرحله بعدی فراخوانی دنبالهای از توابع API به همراه منطق لازم برای اجرای عمل است. اعلان زیر شامل توضیحی از API ربات است که مدل باید هنگام تنظیم این وظیفه از آن استفاده کند.
پایتون
prompt = f"""
You are a robotic arm with six degrees-of-freedom. You have the
following functions available to you:
def move(x, y, high):
# moves the arm to the given coordinates. The boolean value 'high' set
to True means the robot arm should be lifted above the scene for
avoiding obstacles during motion. 'high' set to False means the robot
arm should have the gripper placed on the surface for interacting with
objects.
def setGripperState(opened):
# Opens the gripper if opened set to true, otherwise closes the gripper
def returnToOrigin():
# Returns the robot to an initial state. Should be called as a cleanup
operation.
The origin point for calculating the moves is at normalized point
y={robot_origin_y}, x={robot_origin_x}. Use this as the new (0,0) for
calculating moves, allowing x and y to be negative.
Perform a pick and place operation where you pick up the blue block at
normalized coordinates ({block_x}, {block_y}) (relative coordinates:
{block_relative_x}, {block_relative_y}) and place it into the orange
bowl at normalized coordinates ({bowl_x}, {bowl_y})
(relative coordinates: {bowl_relative_x}, {bowl_relative_y}).
Provide the sequence of function calls as a JSON list of objects, where
each object has a "function" key (the function name) and an "args" key
(a list of arguments for the function).
Also, include your reasoning before the JSON output.
For example:
Reasoning: To pick up the block, I will first move the arm to a high
position above the block, open the gripper, move down to the block,
close the gripper, lift the arm, move to a high position above the bowl,
move down to the bowl, open the gripper, and then lift the arm back to
a high position.
"""
در ادامه، خروجی احتمالی مدل بر اساس اعلان و API ربات آزمایشی نشان داده شده است. این خروجی شامل فرآیند تفکر مدل و وظایفی است که به عنوان نتیجه برنامهریزی شده است. همچنین خروجی فراخوانیهای تابع ربات که مدل به ترتیب با هم انجام داده است را نشان میدهد.
Reasoning: To perform the pick and place operation, I will first move the
robotic arm to a high position above the blue block to ensure clearance. Then, I
will open the gripper in preparation for grasping. Next, I will lower the arm to
the surface level to position the gripper around the block and close the gripper
to secure it. After picking up the block, I will lift the arm to clear the
surface and move towards the orange bowl, maintaining a high position to avoid
collisions. Once positioned above the bowl, I will lower the arm to place the
block inside. I will then open the gripper to release the block. Finally, I will
lift the arm out of the bowl and call `returnToOrigin` to reset the robot's
state.
[
{
"function": "move",
"args": [
163,
427,
true
]
},
{
"function": "setGripperState",
"args": [
true
]
},
{
"function": "move",
"args": [
163,
427,
false
]
},
{
"function": "setGripperState",
"args": [
false
]
},
{
"function": "move",
"args": [
163,
427,
true
]
},
{
"function": "move",
"args": [
-247,
90,
true
]
},
{
"function": "move",
"args": [
-247,
90,
false
]
},
{
"function": "setGripperState",
"args": [
true
]
},
{
"function": "move",
"args": [
-247,
90,
true
]
},
{
"function": "returnToOrigin",
"args": []
}
]
Executing Function Calls:
moving to coordinates: 163, 427, 15
Opening gripper
moving to coordinates: 163, 427, 5
Closing gripper
moving to coordinates: 163, 427, 15
moving to coordinates: -247, 90, 15
moving to coordinates: -247, 90, 5
Opening gripper
moving to coordinates: -247, 90, 15
Returning to origin pose
بهترین شیوهها
برای بهینهسازی عملکرد و دقت برنامههای رباتیک شما، درک چگونگی تعامل مؤثر با مدل Gemini بسیار مهم است. این بخش، بهترین شیوهها و استراتژیهای کلیدی برای ایجاد دستورالعملها، مدیریت دادههای بصری و ساختاردهی وظایف را برای دستیابی به قابل اعتمادترین نتایج، تشریح میکند.
از زبان واضح و ساده استفاده کنید.
زبان طبیعی را بپذیرید : مدل Gemini برای درک زبان طبیعی و محاورهای طراحی شده است. دستورالعملهای خود را به گونهای ساختار دهید که از نظر معنایی واضح باشد و نحوه ارائه دستورالعملها توسط یک فرد به طور طبیعی را منعکس کند.
از اصطلاحات روزمره استفاده کنید : به جای اصطلاحات فنی یا تخصصی، زبان رایج و روزمره را انتخاب کنید. اگر مدل آنطور که انتظار میرود به یک اصطلاح خاص پاسخ نمیدهد، سعی کنید آن را با یک مترادف رایجتر جایگزین کنید.
ورودی بصری را بهینه کنید.
بزرگنمایی برای جزئیات : هنگام کار با اشیایی که کوچک هستند یا تشخیص آنها در یک نمای بازتر دشوار است، از تابع کادر محدودکننده برای جداسازی شیء مورد نظر استفاده کنید. سپس میتوانید تصویر را به این قسمت برش داده و تصویر جدید و فوکوس شده را برای تجزیه و تحلیل دقیقتر به مدل ارسال کنید.
آزمایش با نورپردازی و رنگ : درک مدل میتواند تحت تأثیر شرایط نوری چالشبرانگیز و کنتراست رنگ ضعیف قرار گیرد.
مشکلات پیچیده را به مراحل کوچکتر تقسیم کنید. با پرداختن به هر مرحله کوچکتر به صورت جداگانه، میتوانید مدل را به سمت نتیجهای دقیقتر و موفقتر هدایت کنید.
بهبود دقت از طریق اجماع. برای کارهایی که به دقت بالایی نیاز دارند، میتوانید چندین بار با همان دستور، مدل را پرسوجو کنید. با میانگینگیری از نتایج برگشتی، میتوانید به یک «اجماع» برسید که اغلب دقیقتر و قابل اعتمادتر است.
محدودیتها
هنگام توسعه با Gemini Robotics-ER 1.6، محدودیتهای زیر را در نظر بگیرید:
- وضعیت پیشنمایش: این مدل در حال حاضر در مرحله پیشنمایش است. APIها و قابلیتها ممکن است تغییر کنند و بدون آزمایش کامل، ممکن است برای برنامههای حیاتی در مرحله تولید مناسب نباشد.
- تأخیر: پرسوجوهای پیچیده، ورودیهای با وضوح بالا یا
thinking_budgetگسترده میتوانند منجر به افزایش زمان پردازش شوند. - توهمات: مانند تمام مدلهای زبانی بزرگ، Gemini Robotics-ER 1.6 میتواند گاهی اوقات "توهم" ایجاد کند یا اطلاعات نادرستی ارائه دهد، به خصوص برای دستورات مبهم یا ورودیهای خارج از توزیع.
- وابستگی به کیفیت دستور: کیفیت خروجی مدل به شدت به وضوح و اختصاصی بودن دستور ورودی وابسته است. دستورهای مبهم یا با ساختار ضعیف میتوانند منجر به نتایج نامطلوب شوند.
- هزینه محاسباتی: اجرای مدل، به خصوص با ورودیهای ویدیویی یا
thinking_budgetبالا، منابع محاسباتی را مصرف میکند و هزینههایی را به همراه دارد. برای جزئیات بیشتر به صفحه Thinking مراجعه کنید. - انواع ورودی: برای جزئیات بیشتر در مورد محدودیتهای هر حالت، به مباحث زیر مراجعه کنید.
اطلاعیه حریم خصوصی
شما تصدیق میکنید که مدلهای ارجاعشده در این سند ("مدلهای رباتیک") از دادههای ویدیویی و صوتی برای کار و جابجایی سختافزار شما مطابق با دستورالعملهای شما استفاده میکنند. بنابراین، شما میتوانید مدلهای رباتیک را به گونهای اداره کنید که دادههای افراد قابل شناسایی، مانند صدا، تصویر و دادههای شباهت ("دادههای شخصی")، توسط مدلهای رباتیک جمعآوری شود. اگر تصمیم بگیرید که مدلهای رباتیک را به روشی که دادههای شخصی را جمعآوری میکند، اداره کنید، موافقت میکنید که به هیچ فرد قابل شناسایی اجازه تعامل یا حضور در منطقه اطراف مدلهای رباتیک را نخواهید داد، مگر اینکه و تا زمانی که این افراد قابل شناسایی به اندازه کافی از این واقعیت که دادههای شخصی آنها ممکن است توسط گوگل ارائه و استفاده شود، همانطور که در شرایط خدمات اضافی Gemini API که در https://ai.google.dev/gemini-api/terms ("شرایط") آمده است، از جمله مطابق با بخش "نحوه استفاده گوگل از دادههای شما" ذکر شده است، مطلع شده و رضایت خود را اعلام کرده باشند. شما تضمین خواهید کرد که چنین اطلاعیهای، جمعآوری و استفاده از دادههای شخصی را طبق مفاد مندرج در شرایط، مجاز میداند و با استفاده از تکنیکهایی مانند محو کردن چهره و اجرای مدلهای رباتیک در مناطقی که افراد قابل شناسایی در آنها حضور ندارند، تا حد امکان، تلاشهای تجاری معقولی را برای به حداقل رساندن جمعآوری و توزیع دادههای شخصی به کار خواهید گرفت.
قیمتگذاری
برای اطلاعات دقیق در مورد قیمت گذاری و مناطق موجود، به صفحه قیمت گذاری مراجعه کنید.
نسخههای مدل
پیشنمایش Robotics-ER 1.6
| ملک | توضیحات |
|---|---|
| کد مدل | gemini-robotics-er-1.6-preview |
| انواع داده پشتیبانی شده را | ورودیها متن، تصویر، ویدئو، صدا خروجی متن |
| محدودیتهای توکن [*] | محدودیت توکن ورودی ۱۳۱,۰۷۲ محدودیت توکن خروجی ۶۵,۵۳۶ |
| قابلیتهای | پشتیبانی نمیشود پشتیبانی شده پشتیبانی شده پشتیبانی شده پشتیبانی شده پشتیبانی شده اتصال به زمین با نقشههای گوگل پشتیبانی شده پشتیبانی نمیشود پشتیبانی نمیشود پشتیبانی شده پشتیبانی شده پشتیبانی شده پشتیبانی شده |
| گزینههای مصرف | پشتیبانی شده پشتیبانی شده پشتیبانی شده |
| نسخه |
|
| آخرین بهروزرسانی | دسامبر ۲۰۲۵ |
| حد آستانه دانش | ژانویه ۲۰۲۵ |
مراحل بعدی
- قابلیتهای دیگر را بررسی کنید و به آزمایش با دستورالعملها و ورودیهای مختلف ادامه دهید تا کاربردهای بیشتری برای Gemini Robotics-ER 1.6 کشف کنید. برای مثالهای بیشتر به آزمایشگاه شروع رباتیک مراجعه کنید.
- برای کسب اطلاعات بیشتر در مورد چگونگی ساخت مدلهای Gemini Robotics با در نظر گرفتن ایمنی، به صفحه ایمنی رباتیک Google DeepMind مراجعه کنید.
- برای اطلاع از آخرین بهروزرسانیهای مدلهای Gemini Robotics، به صفحه اصلی Gemini Robotics مراجعه کنید.