O Gemini Robotics-ER 1.6 é um modelo de visão-linguagem (VLM) que traz os recursos de agente do Gemini para a robótica. Ele foi projetado para raciocínio avançado no mundo físico, permitindo que os robôs interpretem dados visuais complexos, façam raciocínio espacial e planejem ações com base em comandos de linguagem natural.
Se você estava usando o Gemini Robotics-ER 1.5, comece a usar o modelo 1.6
substituindo o nome do modelo de model="gemini-robotics-er-1.5-preview"
para model="gemini-robotics-er-1.6-preview" na chamada de API.
Principais recursos e benefícios:
- Autonomia avançada:os robôs podem raciocinar, se adaptar e responder a mudanças em ambientes abertos.
- Interação em linguagem natural:facilita o uso de robôs ao permitir a atribuição de tarefas complexas usando linguagem natural.
- Orquestração de tarefas:desestrutura comandos de linguagem natural em subtarefas e se integra aos controladores e comportamentos de robôs atuais para concluir tarefas de longo prazo.
- Recursos versáteis:localiza e identifica objetos, entende as relações entre eles, planeja movimentos e trajetórias e interpreta cenas dinâmicas.
Este documento descreve o que o modelo faz e mostra vários exemplos que destacam as capacidades de agente do modelo.
Se quiser começar agora, teste o modelo no Google AI Studio.
Segurança
Embora o Gemini Robotics-ER 1.6 tenha sido criado com foco na segurança, é sua responsabilidade manter um ambiente seguro ao redor do robô. Os modelos de IA generativa podem cometer erros, e os robôs físicos podem causar danos. A segurança é uma prioridade, e tornar os modelos de IA generativa seguros quando usados com robótica do mundo real é uma área ativa e essencial da nossa pesquisa. Para saber mais, acesse a página de segurança de robótica do Google DeepMind.
Introdução: encontrar objetos em uma cena
O exemplo a seguir demonstra um caso de uso comum de robótica. Ele mostra como
transmitir uma imagem e um comando de texto ao modelo usando o método
generateContent
para receber uma lista de objetos identificados com os respectivos pontos 2D.
O modelo retorna pontos para itens identificados em uma imagem, retornando
coordenadas e rótulos 2D normalizados.
É possível usar essa saída com uma API de robótica ou chamar um modelo de visão-linguagem-ação (VLA) ou qualquer outra função definida pelo usuário de terceiros para gerar ações que um robô possa realizar.
Python
from google import genai
from google.genai import types
PROMPT = """
Point to no more than 10 items in the image. The label returned
should be an identifying name for the object detected.
The answer should follow the json format: [{"point": <point>,
"label": <label1>}, ...]. The points are in [y, x] format
normalized to 0-1000.
"""
client = genai.Client()
# Load your image
with open("my-image.png", 'rb') as f:
image_bytes = f.read()
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/png',
),
PROMPT
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
REST
# First, ensure you have the image file locally.
# Encode the image to base64
IMAGE_BASE64=$(base64 -w 0 my-image.png)
curl -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-robotics-er-1.6-preview:generateContent \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [
{
"parts": [
{
"inlineData": {
"mimeType": "image/png",
"data": "'"${IMAGE_BASE64}"'"
}
},
{
"text": "Point to no more than 10 items in the image. The label returned should be an identifying name for the object detected. The answer should follow the json format: [{\"point\": [y, x], \"label\": <label1>}, ...]. The points are in [y, x] format normalized to 0-1000."
}
]
}
],
"generationConfig": {
"temperature": 0.5,
"thinkingConfig": {
"thinkingBudget": 0
}
}
}'
A saída será uma matriz JSON que contém objetos, cada um com um point (coordenadas [y, x] normalizadas) e um label que identifica o objeto.
JSON
[
{"point": [376, 508], "label": "small banana"},
{"point": [287, 609], "label": "larger banana"},
{"point": [223, 303], "label": "pink starfruit"},
{"point": [435, 172], "label": "paper bag"},
{"point": [270, 786], "label": "green plastic bowl"},
{"point": [488, 775], "label": "metal measuring cup"},
{"point": [673, 580], "label": "dark blue bowl"},
{"point": [471, 353], "label": "light blue bowl"},
{"point": [492, 497], "label": "bread"},
{"point": [525, 429], "label": "lime"}
]
A imagem a seguir é um exemplo de como esses pontos podem ser mostrados:

Como funciona
O Gemini Robotics-ER 1.6 permite que seus robôs contextualizem e trabalhem no mundo físico usando a compreensão espacial. Ele usa comandos de linguagem natural e entradas de imagem/vídeo/áudio para:
- Entender objetos e o contexto da cena: identifica objetos e raciocina sobre a relação deles com a cena, incluindo as possibilidades de interação.
- Entender instruções de tarefas: interpreta tarefas dadas em linguagem natural, como "encontre a banana".
- Raciocínio espacial e temporal: entender sequências de ações e como os objetos interagem com uma cena ao longo do tempo.
- Forneça saída estruturada: retorna coordenadas (pontos ou caixas delimitadoras) que representam locais de objetos.
Isso permite que os robôs "vejam" e "entendam" o ambiente de maneira programática.
O Gemini Robotics-ER 1.6 também é um agente, o que significa que ele pode dividir tarefas complexas (como "coloque a maçã na tigela") em subtarefas para orquestrar tarefas de longo prazo:
- Sequenciar subtarefas: decompõe comandos em uma sequência lógica de etapas.
- Chamadas de função/execução de código: executa etapas chamando suas funções/ferramentas de robô atuais ou executando o código gerado.
Leia mais sobre como a chamada de função com o Gemini funciona na página de chamada de função.
Como usar o orçamento de pensamento com o Gemini Robotics-ER 1.6
O Gemini Robotics ER 1.6 tem um orçamento de raciocínio flexível que dá controle sobre as compensações de latência e acurácia. Para tarefas de compreensão espacial, como detecção de objetos, o modelo pode alcançar alta performance com um pequeno orçamento de pensamento. Tarefas de raciocínio mais complexas, como contagem e estimativa de peso, se beneficiam de um orçamento de pensamento maior. Assim, você pode equilibrar a necessidade de respostas de baixa latência com resultados de alta precisão para tarefas mais desafiadoras.
Para saber mais sobre os orçamentos de pensamento, consulte a página de recursos principais de Pensamento.
Raciocínio espacial padrão
Os exemplos a seguir demonstram tarefas de percepção robótica e raciocínio espacial usando comandos de linguagem natural, que vão desde apontar e encontrar objetos em uma imagem até planejar trajetórias. Para simplificar, os snippets de código nestes exemplos foram reduzidos para mostrar apenas o comando e a chamada para a API generate_content.
O código executável completo e outros exemplos podem ser encontrados no Robotics cookbook (link em inglês).
Apontar para objetos
Apontar e encontrar objetos em imagens ou frames de vídeo é um caso de uso comum para modelos de visão e linguagem (VLMs, na sigla em inglês) em robótica. O exemplo a seguir pede ao modelo para encontrar objetos específicos em uma imagem e retornar as coordenadas deles.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
queries = [
"bread",
"starfruit",
"banana",
]
prompt = f"""
Get all points matching the following objects: {', '.join(queries)}. The
label returned should be an identifying name for the object detected.
The answer should follow the json format:
[{{"point": , "label": }}, ...]. The points are in
[y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
A saída seria semelhante ao exemplo de introdução, um JSON contendo as coordenadas dos objetos encontrados e os rótulos deles.
[
{"point": [671, 317], "label": "bread"},
{"point": [738, 307], "label": "bread"},
{"point": [702, 237], "label": "bread"},
{"point": [629, 307], "label": "bread"},
{"point": [833, 800], "label": "bread"},
{"point": [609, 663], "label": "banana"},
{"point": [770, 483], "label": "starfruit"}
]

Use o comando a seguir para pedir ao modelo que interprete categorias abstratas, como "fruta", em vez de objetos específicos e localize todas as instâncias na imagem.
Python
prompt = f"""
Get all points for fruit. The label returned should be an identifying
name for the object detected.
""" + """The answer should follow the json format:
[{"point": <point>, "label": <label1>}, ...]. The points are in
[y, x] format normalized to 0-1000."""
Acesse a página compreensão de imagens para conhecer outras técnicas de processamento de imagens.
Como rastrear objetos em um vídeo
O Gemini Robotics-ER 1.6 também pode analisar frames de vídeo para rastrear objetos ao longo do tempo. Consulte Entradas de vídeo para ver uma lista dos formatos de vídeo compatíveis.
Este é o comando básico usado para encontrar objetos específicos em cada frame analisado pelo modelo:
Python
# Define the objects to find
queries = [
"pen (on desk)",
"pen (in robot hand)",
"laptop (opened)",
"laptop (closed)",
]
base_prompt = f"""
Point to the following objects in the provided image: {', '.join(queries)}.
The answer should follow the json format:
[{{"point": , "label": }}, ...].
The points are in [y, x] format normalized to 0-1000.
If no objects are found, return an empty JSON list [].
"""
A saída mostra uma caneta e um laptop sendo rastreados nos frames do vídeo.
![]()
Para conferir o código executável completo, consulte o Robotics cookbook.
Detecção de objetos e caixas delimitadoras
Além de pontos únicos, o modelo também pode retornar caixas delimitadoras 2D, fornecendo uma região retangular que envolve um objeto.
Este exemplo solicita caixas delimitadoras 2D para objetos identificáveis em uma mesa. O modelo é instruído a limitar a saída a 25 objetos e a nomear várias instâncias de forma exclusiva.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Return bounding boxes as a JSON array with labels. Never return masks
or code fencing. Limit to 25 objects. Include as many objects as you
can identify on the table.
If an object is present multiple times, name them according to their
unique characteristic (colors, size, position, unique characteristics, etc..).
The format should be as follows: [{"box_2d": [ymin, xmin, ymax, xmax],
"label": <label for the object>}] normalized to 0-1000. The values in
box_2d must only be integers
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
A seguir, mostramos as caixas retornadas do modelo.
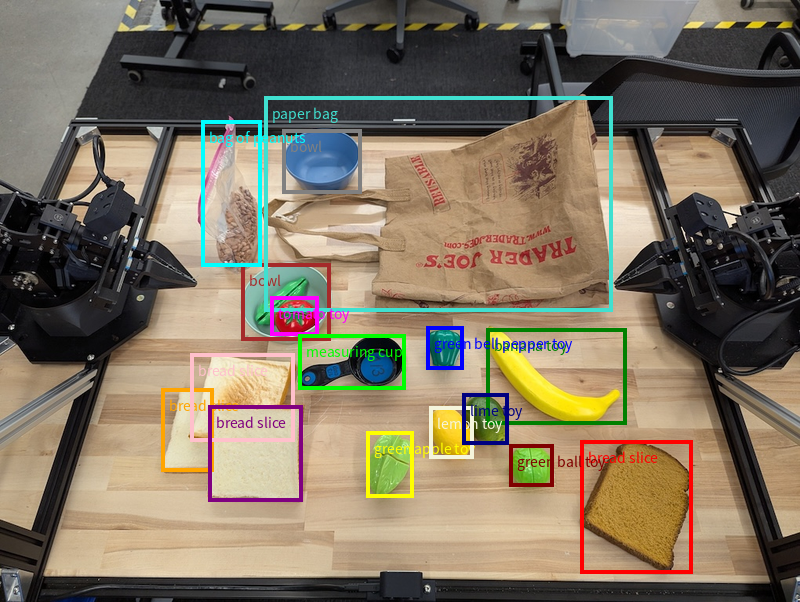
Para conferir o código executável completo, consulte o Robotics cookbook (em inglês). A página Compreensão de imagens também tem outros exemplos de tarefas visuais, como detecção de objetos e caixas delimitadoras.
Trajetórias
O Gemini Robotics-ER 1.6 pode gerar sequências de pontos que definem uma trajetória, útil para orientar o movimento do robô.
Este exemplo pede uma trajetória para mover uma caneta vermelha até um organizador, incluindo o ponto de partida e uma série de pontos intermediários.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
points_data = []
prompt = """
Place a point on the red pen, then 15 points for the trajectory of
moving the red pen to the top of the organizer on the left.
The points should be labeled by order of the trajectory, from '0'
(start point at left hand) to <n> (final point)
The answer should follow the json format:
[{"point": <point>, "label": <label1>}, ...].
The points are in [y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
)
)
print(image_response.text)
A resposta é um conjunto de coordenadas que descrevem a trajetória do caminho que a caneta vermelha precisa seguir para concluir a tarefa de movê-la para cima do organizador:
[
{"point": [550, 610], "label": "0"},
{"point": [500, 600], "label": "1"},
{"point": [450, 590], "label": "2"},
{"point": [400, 580], "label": "3"},
{"point": [350, 550], "label": "4"},
{"point": [300, 520], "label": "5"},
{"point": [250, 490], "label": "6"},
{"point": [200, 460], "label": "7"},
{"point": [180, 430], "label": "8"},
{"point": [160, 400], "label": "9"},
{"point": [140, 370], "label": "10"},
{"point": [120, 340], "label": "11"},
{"point": [110, 320], "label": "12"},
{"point": [105, 310], "label": "13"},
{"point": [100, 305], "label": "14"},
{"point": [100, 300], "label": "15"}
]

Recursos agênticos
Os exemplos a seguir demonstram o raciocínio robótico avançado usando os recursos de agente do modelo, especificamente a execução de código. Nesses cenários, o modelo pode decidir escrever e executar código Python para manipular imagens (como zoom, corte ou rotação) para resolver ambiguidades ou melhorar a precisão antes de responder.
Detecção de objetos (zoom e corte)
O exemplo a seguir demonstra como usar a execução de código para ampliar e cortar uma imagem para uma visualização mais clara ao detectar objetos e retornar caixas delimitadoras.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('sorting.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
Return JSON in the format {label: val, y: val, x: val, y2: val, x2: val} for
the compostable objects in this scene. Please Zoom and crop the image for a
clearer view. Return an annotated image of the final result with the bounding
boxes drawn on it to the API caller as a part of your process.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
A saída do modelo seria semelhante a esta:
[
{"label": "compostable", "y": 256, "x": 482, "y2": 295, "x2": 546},
{"label": "compostable", "y": 317, "x": 478, "y2": 350, "x2": 542},
{"label": "compostable", "y": 586, "x": 556, "y2": 668, "x2": 595},
{"label": "compostable", "y": 463, "x": 669, "y2": 511, "x2": 718},
{"label": "compostable", "y": 178, "x": 565, "y2": 250, "x2": 609}
]
A seguir, mostramos as caixas retornadas do modelo.

Ler um medidor analógico e aplicar a lógica
O exemplo a seguir demonstra como usar o modelo para ler um medidor analógico e realizar cálculos de tempo. Ele usa uma instrução do sistema para gerar uma saída JSON.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('clock.jpg', 'rb') as f:
image_bytes = f.read()
q_time = """
Tell me what the value is. Please respond in the following JSON format:\n {\n "hours": X,\n "minutes": Y,\n}. Zoom in or crop as necessary to confirm location of the clock hands.
"""
system_instruction = "Be precise. When JSON is requested, reply with ONLY that JSON (no preface, no code block)."
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
system_instruction + " " + q_time
],
config = types.GenerateContentConfig(
temperature=1.0,
)
)
print(response.text)
Confira abaixo um exemplo de entrada de imagem.

A saída do modelo seria semelhante a esta:
Time Response: {
"hours": 12,
"minutes": 44
}
Medir fluido em um recipiente
O exemplo a seguir mostra como usar a execução de código para ler um medidor e calcular o nível de líquido como uma porcentagem.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('meter.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
How full is the meter of liquid?
To read it,
1) Find the points for the top of the sight window, bottom of the sight window and the liquid level, formatted as [y, x] with values ranging from 0-1000;
2) Use math to determine the liquid level as a percentage;
3) Output "Answer: ??" on a separate line, where ?? is a number without % or unit.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
Esta é a imagem ampliada da entrada.

Ler marcações em uma placa de circuito
O exemplo a seguir demonstra como usar a execução de código para ler texto em um chip de placa de circuito, permitindo que o modelo faça zoom, corte e gire a imagem conforme necessário.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('circuit_board.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = "What is the number on the ESMT chip? Zoom, crop, and rotate if needed."
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
Esta é a imagem ampliada da entrada.

Anotação de imagem
O exemplo a seguir demonstra como usar a execução de código para anotar uma imagem (por exemplo, desenhando setas para instruções de descarte) e retornar a imagem modificada.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('sorting.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
Look at this image and return it as an annotated version using arrows of
different colors to represent which items should go in which bins for
disposal. You must return the final image to the API caller.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
Confira abaixo um exemplo de entrada de imagem.

A saída do modelo seria semelhante a esta:
The annotated image shows the suggested disposal locations for the items on the table:
- **Green bin (Compost/Organic)**: Green chili, red chili, grapes, and cherries.
- **Blue bin (Recycling)**: Yellow crushed can and plastic container.
- **Black bin (Trash)**: Chocolate bar wrapper, Welch's packet, and white tissue.
Orquestração
O Gemini Robotics-ER 1.6 pode realizar planejamento de tarefas e raciocínio espacial de nível superior, inferindo ações ou identificando locais ideais com base na compreensão contextual para orquestrar tarefas de longo prazo.
Abrir espaço para um laptop
Este exemplo mostra como o Gemini Robotics-ER pode raciocinar sobre um espaço. O comando pede que o modelo identifique qual objeto precisa ser movido para criar espaço para outro item.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Point to the object that I need to remove to make room for my laptop
The answer should follow the json format: [{"point": <point>,
"label": <label1>}, ...]. The points are in [y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
A resposta contém uma coordenada 2D do objeto que responde à pergunta do usuário, neste caso, o objeto que deve ser movido para abrir espaço para um laptop.
[
{"point": [672, 301], "label": "The object that I need to remove to make room for my laptop"}
]

Como preparar um almoço
O modelo também pode fornecer instruções para tarefas de várias etapas e apontar objetos relevantes para cada etapa. Este exemplo mostra como o modelo planeja uma série de etapas para preparar uma lancheira.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-of-lunch.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Explain how to pack the lunch box and lunch bag. Point to each
object that you refer to. Each point should be in the format:
[{"point": [y, x], "label": }], where the coordinates are
normalized between 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
A resposta desse comando é um conjunto de instruções detalhadas sobre como embalar uma lancheira com base na entrada de imagem.
Imagem de entrada

Saída do modelo
Based on the image, here is a plan to pack the lunch box and lunch bag:
1. **Pack the fruit into the lunch box.** Place the [apple](apple), [banana](banana), [red grapes](red grapes), and [green grapes](green grapes) into the [blue lunch box](blue lunch box).
2. **Add the spoon to the lunch box.** Put the [blue spoon](blue spoon) inside the lunch box as well.
3. **Close the lunch box.** Secure the lid on the [blue lunch box](blue lunch box).
4. **Place the lunch box inside the lunch bag.** Put the closed [blue lunch box](blue lunch box) into the [brown lunch bag](brown lunch bag).
5. **Pack the remaining items into the lunch bag.** Place the [blue snack bar](blue snack bar) and the [brown snack bar](brown snack bar) into the [brown lunch bag](brown lunch bag).
Here is the list of objects and their locations:
* [{"point": [899, 440], "label": "apple"}]
* [{"point": [814, 363], "label": "banana"}]
* [{"point": [727, 470], "label": "red grapes"}]
* [{"point": [675, 608], "label": "green grapes"}]
* [{"point": [706, 529], "label": "blue lunch box"}]
* [{"point": [864, 517], "label": "blue spoon"}]
* [{"point": [499, 401], "label": "blue snack bar"}]
* [{"point": [614, 705], "label": "brown snack bar"}]
* [{"point": [448, 501], "label": "brown lunch bag"}]
Como chamar uma API de robô personalizada
Este exemplo demonstra a orquestração de tarefas com uma API de robô personalizada. Ele apresenta uma API simulada projetada para uma operação de coleta e colocação. A tarefa é pegar um bloco azul e colocar em uma tigela laranja:

Assim como nos outros exemplos desta página, o código executável completo está disponível no Robotics cookbook (em inglês).
A primeira etapa é localizar os dois itens com o seguinte comando:
Python
prompt = """
Locate and point to the blue block and the orange bowl. The label
returned should be an identifying name for the object detected.
The answer should follow the json format: [{"point": <point>, "label": <label1>}, ...].
The points are in [y, x] format normalized to 0-1000.
"""
A resposta do modelo inclui as coordenadas normalizadas do bloco e da tigela:
[
{"point": [389, 252], "label": "orange bowl"},
{"point": [727, 659], "label": "blue block"}
]
Este exemplo usa a seguinte API de robô simulado:
Python
def move(x, y, high):
print(f"moving to coordinates: {x}, {y}, {15 if high else 5}")
def setGripperState(opened):
print("Opening gripper" if opened else "Closing gripper")
def returnToOrigin():
print("Returning to origin pose")
A próxima etapa é chamar uma sequência de funções da API com a lógica necessária para executar a ação. O comando a seguir inclui uma descrição da API do robô que o modelo deve usar ao orquestrar essa tarefa.
Python
prompt = f"""
You are a robotic arm with six degrees-of-freedom. You have the
following functions available to you:
def move(x, y, high):
# moves the arm to the given coordinates. The boolean value 'high' set
to True means the robot arm should be lifted above the scene for
avoiding obstacles during motion. 'high' set to False means the robot
arm should have the gripper placed on the surface for interacting with
objects.
def setGripperState(opened):
# Opens the gripper if opened set to true, otherwise closes the gripper
def returnToOrigin():
# Returns the robot to an initial state. Should be called as a cleanup
operation.
The origin point for calculating the moves is at normalized point
y={robot_origin_y}, x={robot_origin_x}. Use this as the new (0,0) for
calculating moves, allowing x and y to be negative.
Perform a pick and place operation where you pick up the blue block at
normalized coordinates ({block_x}, {block_y}) (relative coordinates:
{block_relative_x}, {block_relative_y}) and place it into the orange
bowl at normalized coordinates ({bowl_x}, {bowl_y})
(relative coordinates: {bowl_relative_x}, {bowl_relative_y}).
Provide the sequence of function calls as a JSON list of objects, where
each object has a "function" key (the function name) and an "args" key
(a list of arguments for the function).
Also, include your reasoning before the JSON output.
For example:
Reasoning: To pick up the block, I will first move the arm to a high
position above the block, open the gripper, move down to the block,
close the gripper, lift the arm, move to a high position above the bowl,
move down to the bowl, open the gripper, and then lift the arm back to
a high position.
"""
A seguir, mostramos uma possível saída do modelo com base no comando e na API de robô simulada. A saída inclui o processo de pensamento do modelo e as tarefas que ele planejou como resultado. Ela também mostra a saída das chamadas de função do robô que o modelo sequenciou.
Reasoning: To perform the pick and place operation, I will first move the
robotic arm to a high position above the blue block to ensure clearance. Then, I
will open the gripper in preparation for grasping. Next, I will lower the arm to
the surface level to position the gripper around the block and close the gripper
to secure it. After picking up the block, I will lift the arm to clear the
surface and move towards the orange bowl, maintaining a high position to avoid
collisions. Once positioned above the bowl, I will lower the arm to place the
block inside. I will then open the gripper to release the block. Finally, I will
lift the arm out of the bowl and call `returnToOrigin` to reset the robot's
state.
[
{
"function": "move",
"args": [
163,
427,
true
]
},
{
"function": "setGripperState",
"args": [
true
]
},
{
"function": "move",
"args": [
163,
427,
false
]
},
{
"function": "setGripperState",
"args": [
false
]
},
{
"function": "move",
"args": [
163,
427,
true
]
},
{
"function": "move",
"args": [
-247,
90,
true
]
},
{
"function": "move",
"args": [
-247,
90,
false
]
},
{
"function": "setGripperState",
"args": [
true
]
},
{
"function": "move",
"args": [
-247,
90,
true
]
},
{
"function": "returnToOrigin",
"args": []
}
]
Executing Function Calls:
moving to coordinates: 163, 427, 15
Opening gripper
moving to coordinates: 163, 427, 5
Closing gripper
moving to coordinates: 163, 427, 15
moving to coordinates: -247, 90, 15
moving to coordinates: -247, 90, 5
Opening gripper
moving to coordinates: -247, 90, 15
Returning to origin pose
Práticas recomendadas
Para otimizar o desempenho e a acurácia dos seus aplicativos de robótica, é fundamental entender como interagir com o modelo do Gemini de maneira eficaz. Esta seção descreve as práticas recomendadas e as principais estratégias para criar comandos, processar dados visuais e estruturar tarefas para alcançar os resultados mais confiáveis.
Use uma linguagem clara e simples.
Use linguagem natural: o modelo do Gemini foi desenvolvido para entender linguagem natural e conversacional. Estruture seus comandos de forma semanticamente clara e que reflita como uma pessoa daria instruções naturalmente.
Use terminologia do dia a dia: prefira uma linguagem comum e cotidiana em vez de jargões técnicos ou especializados. Se o modelo não estiver respondendo como esperado a um determinado termo, tente reformular com um sinônimo mais comum.
Otimize a entrada visual.
Aumentar o zoom para ver detalhes: ao lidar com objetos pequenos ou difíceis de discernir em uma foto mais ampla, use uma função de caixa delimitadora para isolar o objeto de interesse. Em seguida, corte a imagem para essa seleção e envie a nova imagem focada para o modelo para uma análise mais detalhada.
Teste a iluminação e a cor: a percepção do modelo pode ser afetada por condições de iluminação difíceis e contraste de cores ruim.
Divida problemas complexos em etapas menores. Ao abordar cada etapa menor individualmente, você pode orientar o modelo para um resultado mais preciso e bem-sucedido.
Melhorar a acurácia por consenso. Para tarefas que exigem um alto grau de precisão, é possível consultar o modelo várias vezes com o mesmo comando. Ao fazer a média dos resultados retornados, você chega a um "consenso" que geralmente é mais preciso e confiável.
Limitações
Considere as seguintes limitações ao desenvolver com o Gemini Robotics-ER 1.6:
- Status da prévia:no momento, o modelo está em prévia. As APIs e capacidades podem mudar, e talvez não sejam adequadas para aplicativos críticos de produção sem testes completos.
- Latência:consultas complexas, entradas de alta resolução ou
thinking_budgetextensos podem aumentar os tempos de processamento. - Alucinações:assim como todos os modelos de linguagem grandes, o Gemini Robotics-ER 1.6 pode ocasionalmente "alucinar" ou fornecer informações incorretas, especialmente para comandos ambíguos ou entradas fora da distribuição.
- Dependência da qualidade do comando:a qualidade da saída do modelo depende muito da clareza e da especificidade do comando de entrada. Comandos vagos ou mal estruturados podem levar a resultados abaixo do ideal.
- Custo computacional:executar o modelo, principalmente com entradas de vídeo ou
thinking_budgetalto, consome recursos computacionais e gera custos. Consulte a página Pensamento para mais detalhes. - Tipos de entrada:consulte os tópicos a seguir para saber mais sobre as limitações de cada modo.
Aviso de privacidade
Você reconhece que os modelos mencionados neste documento (os "Modelos de robótica") usam dados de vídeo e áudio para operar e mover seu hardware de acordo com suas instruções. Portanto, você pode operar os Modelos de robótica de forma que dados de pessoas identificáveis, como voz, imagens e dados de semelhança ("Dados pessoais"), sejam coletados por eles. Se você optar por operar os modelos de robótica de uma maneira que colete dados pessoais, concorda em não permitir que pessoas identificáveis interajam ou estejam presentes na área ao redor dos modelos de robótica, a menos que essas pessoas tenham sido suficientemente notificadas e consentido com o fato de que seus dados pessoais podem ser fornecidos e usados pelo Google conforme descrito nos Termos Adicionais de Serviço da API Gemini, disponíveis em https://ai.google.dev/gemini-api/terms (os "Termos"), incluindo de acordo com a seção intitulada "Como o Google usa seus dados". Você vai garantir que esse aviso permita a coleta e o uso de dados pessoais conforme descrito nos Termos e vai empregar todos os esforços comercialmente razoáveis para minimizar a coleta e a distribuição de dados pessoais usando técnicas como desfoque de rosto e operando os modelos de robótica em áreas sem pessoas identificáveis, na medida do possível.
Preços
Para informações detalhadas sobre preços e regiões disponíveis, consulte a página de preços.
Versões do modelo
Pré-lançamento do Robotics-ER 1.6
| Propriedade | Descrição |
|---|---|
| Código do modelo | gemini-robotics-er-1.6-preview |
| Tipos de dados aceitos |
Entradas (link em inglês) Texto, imagens, vídeo, áudio Saída Texto |
| Limites de tokens [*] |
Limite de tokens de entrada 131.072 Limite de token de saída 65.536 |
| Recursos | incompatível Compatível Compatível Compatível Compatível Compatível Compatível incompatível incompatível Compatível Compatível Compatível Compatível |
| Opções de consumo |
Compatível Compatível Compatível |
| Versões |
|
| Última atualização | Dezembro de 2025 |
| Limite de conhecimento | Janeiro de 2025 |
Próximas etapas
- Conheça outros recursos e continue testando diferentes comandos e entradas para descobrir mais aplicações do Gemini Robotics-ER 1.6. Consulte o Colab de introdução à robótica para mais exemplos.
- Saiba como os modelos de robótica do Gemini foram criados pensando na segurança na página de segurança de robótica do Google DeepMind.
- Leia sobre as atualizações mais recentes dos modelos do Gemini Robotics na página de destino do Gemini Robotics.