Gemini Robotics-ER 1.6 là một mô hình thị giác-ngôn ngữ (VLM) mang các khả năng của tác nhân AI của Gemini vào lĩnh vực robot học. Mô hình này được thiết kế để suy luận nâng cao trong thế giới thực, cho phép robot diễn giải dữ liệu hình ảnh phức tạp, thực hiện suy luận không gian và lập kế hoạch hành động từ các lệnh bằng ngôn ngữ tự nhiên.
Xin lưu ý rằng nếu đang sử dụng Gemini Robotics-ER 1.5, bạn có thể bắt đầu sử dụng mô hình 1.6 bằng cách thay thế tên mô hình từ model="gemini-robotics-er-1.5-preview" thành model="gemini-robotics-er-1.6-preview" trong lệnh gọi API.
Các tính năng và lợi ích chính:
- Tăng cường khả năng tự chủ: Robot có thể suy luận, thích ứng và phản hồi những thay đổi trong môi trường mở.
- Tương tác bằng ngôn ngữ tự nhiên: Giúp người dùng dễ dàng sử dụng robot hơn bằng cách cho phép chỉ định các nhiệm vụ phức tạp bằng ngôn ngữ tự nhiên.
- Điều phối tác vụ: Phân tích các lệnh bằng ngôn ngữ tự nhiên thành các tác vụ phụ và tích hợp với các bộ điều khiển cũng như hành vi hiện có của robot để hoàn thành các tác vụ trong thời gian dài.
- Khả năng linh hoạt: Định vị và xác định các đối tượng, hiểu mối quan hệ giữa các đối tượng, lập kế hoạch nắm bắt và quỹ đạo, đồng thời diễn giải các cảnh động.
Tài liệu này mô tả những việc mà mô hình này có thể làm và giới thiệu cho bạn một số ví dụ minh hoạ các khả năng của tác nhân AI của mô hình này.
Nếu muốn bắt đầu ngay, bạn có thể dùng thử mô hình này trong Google AI Studio.
Dùng thử trong Google AI Studio
An toàn
Mặc dù Gemini Robotics-ER 1.6 được xây dựng với mục tiêu đảm bảo an toàn, nhưng bạn vẫn phải có trách nhiệm duy trì một môi trường an toàn xung quanh robot. Các mô hình AI tạo sinh có thể mắc lỗi và robot thực có thể gây hư hỏng. An toàn là ưu tiên hàng đầu và việc đảm bảo an toàn cho các mô hình AI tạo sinh khi sử dụng với robot trong thế giới thực là một lĩnh vực nghiên cứu quan trọng và đang được chúng tôi tích cực triển khai. Để tìm hiểu thêm, hãy truy cập vào trang an toàn về robot của Google DeepMind.
Bắt đầu: Tìm các đối tượng trong một cảnh
Ví dụ sau đây minh hoạ một trường hợp sử dụng phổ biến trong lĩnh vực robot học. Ví dụ này cho thấy cách truyền một hình ảnh và một câu lệnh văn bản đến mô hình bằng phương thức generateContent để nhận danh sách các đối tượng được nhận dạng cùng với các điểm 2D tương ứng.
Mô hình này trả về các điểm cho những mục mà mô hình xác định được trong một hình ảnh, trả về nhãn và toạ độ 2D được chuẩn hoá của các mục đó.
Bạn có thể sử dụng đầu ra này với một API robot hoặc gọi một mô hình hành động-ngôn ngữ-thị giác (VLA) hoặc bất kỳ hàm do người dùng xác định nào khác của bên thứ ba để tạo hành động cho robot thực hiện.
Python
from google import genai
from google.genai import types
PROMPT = """
Point to no more than 10 items in the image. The label returned
should be an identifying name for the object detected.
The answer should follow the json format: [{"point": <point>,
"label": <label1>}, ...]. The points are in [y, x] format
normalized to 0-1000.
"""
client = genai.Client()
# Load your image
with open("my-image.png", 'rb') as f:
image_bytes = f.read()
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/png',
),
PROMPT
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
REST
# First, ensure you have the image file locally.
# Encode the image to base64
IMAGE_BASE64=$(base64 -w 0 my-image.png)
curl -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-robotics-er-1.6-preview:generateContent \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [
{
"parts": [
{
"inlineData": {
"mimeType": "image/png",
"data": "'"${IMAGE_BASE64}"'"
}
},
{
"text": "Point to no more than 10 items in the image. The label returned should be an identifying name for the object detected. The answer should follow the json format: [{\"point\": [y, x], \"label\": <label1>}, ...]. The points are in [y, x] format normalized to 0-1000."
}
]
}
],
"generationConfig": {
"temperature": 0.5,
"thinkingConfig": {
"thinkingBudget": 0
}
}
}'
Đầu ra sẽ là một mảng JSON chứa các đối tượng, mỗi đối tượng có một point (toạ độ [y, x] được chuẩn hoá) và một label xác định đối tượng.
JSON
[
{"point": [376, 508], "label": "small banana"},
{"point": [287, 609], "label": "larger banana"},
{"point": [223, 303], "label": "pink starfruit"},
{"point": [435, 172], "label": "paper bag"},
{"point": [270, 786], "label": "green plastic bowl"},
{"point": [488, 775], "label": "metal measuring cup"},
{"point": [673, 580], "label": "dark blue bowl"},
{"point": [471, 353], "label": "light blue bowl"},
{"point": [492, 497], "label": "bread"},
{"point": [525, 429], "label": "lime"}
]
Hình ảnh sau đây là ví dụ về cách hiển thị các điểm này:

Cách hoạt động
Gemini Robotics-ER 1.6 cho phép robot của bạn đưa ra bối cảnh và hoạt động trong thế giới thực bằng cách sử dụng khả năng hiểu biết về không gian. Công cụ này nhận dữ liệu đầu vào là hình ảnh/video/âm thanh và câu lệnh bằng ngôn ngữ tự nhiên để:
- Hiểu được các đối tượng và bối cảnh của cảnh: Xác định các đối tượng và lý do về mối quan hệ của các đối tượng đó với cảnh, bao gồm cả khả năng của các đối tượng.
- Hiểu hướng dẫn về nhiệm vụ: Diễn giải các nhiệm vụ được đưa ra bằng ngôn ngữ tự nhiên, chẳng hạn như "tìm quả chuối".
- Lý luận về không gian và thời gian: Hiểu trình tự hành động và cách các đối tượng tương tác với một cảnh theo thời gian.
- Cung cấp đầu ra có cấu trúc: Trả về toạ độ (điểm hoặc khung hình chữ nhật) biểu thị vị trí của đối tượng.
Điều này cho phép robot "nhìn" và "hiểu" môi trường của chúng một cách có lập trình.
Gemini Robotics-ER 1.6 cũng có khả năng hành động như một tác nhân, tức là có thể chia nhỏ các tác vụ phức tạp (chẳng hạn như "đặt quả táo vào bát") thành các tác vụ phụ để điều phối các tác vụ trong thời gian dài:
- Sắp xếp các bước của lệnh: Phân tách các lệnh thành một chuỗi các bước hợp lý.
- Lệnh gọi hàm/Thực thi mã: Thực thi các bước bằng cách gọi các hàm/công cụ hiện có của robot hoặc thực thi mã được tạo.
Đọc thêm về cách tính năng gọi hàm hoạt động với Gemini trên trang Gọi hàm.
Sử dụng ngân sách tư duy với Gemini Robotics-ER 1.6
Gemini Robotics-ER 1.6 có ngân sách tư duy linh hoạt, giúp bạn kiểm soát sự đánh đổi giữa độ trễ và độ chính xác. Đối với các tác vụ hiểu không gian như phát hiện đối tượng, mô hình có thể đạt được hiệu suất cao với ngân sách suy nghĩ nhỏ. Các tác vụ suy luận phức tạp hơn như đếm và ước tính trọng lượng sẽ được hưởng lợi từ ngân sách tư duy lớn hơn. Điều này giúp bạn cân bằng nhu cầu về phản hồi có độ trễ thấp với kết quả có độ chính xác cao cho các tác vụ khó hơn.
Để tìm hiểu thêm về ngân sách tư duy, hãy xem trang Tư duy về các chức năng cốt lõi.
Suy luận không gian tiêu chuẩn
Các ví dụ sau đây minh hoạ các nhiệm vụ về nhận thức của robot và suy luận không gian bằng cách sử dụng câu lệnh bằng ngôn ngữ tự nhiên, từ việc chỉ và tìm vật thể trong hình ảnh đến việc lập kế hoạch cho quỹ đạo. Để đơn giản hoá, các đoạn mã trong những ví dụ này đã được rút gọn để chỉ hiển thị câu lệnh và lệnh gọi đến API generate_content.
Bạn có thể tìm thấy đoạn mã có thể chạy đầy đủ cũng như các ví dụ khác trong Sổ tay về robot học.
Chỉ vào vật thể
Chỉ và tìm vật thể trong hình ảnh hoặc khung hình video là một trường hợp sử dụng phổ biến đối với các mô hình thị giác và ngôn ngữ (VLM) trong ngành robot học. Ví dụ sau đây yêu cầu mô hình tìm các đối tượng cụ thể trong một hình ảnh và trả về toạ độ của các đối tượng đó.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
queries = [
"bread",
"starfruit",
"banana",
]
prompt = f"""
Get all points matching the following objects: {', '.join(queries)}. The
label returned should be an identifying name for the object detected.
The answer should follow the json format:
[{{"point": , "label": }}, ...]. The points are in
[y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
Đầu ra sẽ tương tự như ví dụ về cách bắt đầu, một tệp JSON chứa toạ độ của các đối tượng được tìm thấy và nhãn của các đối tượng đó.
[
{"point": [671, 317], "label": "bread"},
{"point": [738, 307], "label": "bread"},
{"point": [702, 237], "label": "bread"},
{"point": [629, 307], "label": "bread"},
{"point": [833, 800], "label": "bread"},
{"point": [609, 663], "label": "banana"},
{"point": [770, 483], "label": "starfruit"}
]

Sử dụng câu lệnh sau để yêu cầu mô hình diễn giải các danh mục trừu tượng như "trái cây" thay vì các đối tượng cụ thể và xác định vị trí của tất cả các thực thể trong hình ảnh.
Python
prompt = f"""
Get all points for fruit. The label returned should be an identifying
name for the object detected.
""" + """The answer should follow the json format:
[{"point": <point>, "label": <label1>}, ...]. The points are in
[y, x] format normalized to 0-1000."""
Hãy truy cập vào trang hiểu hình ảnh để biết các kỹ thuật xử lý hình ảnh khác.
Theo dõi đối tượng trong video
Gemini Robotics-ER 1.6 cũng có thể phân tích các khung hình video để theo dõi các đối tượng theo thời gian. Hãy xem phần Đầu vào video để biết danh sách các định dạng video được hỗ trợ.
Sau đây là câu lệnh cơ bản được dùng để tìm các đối tượng cụ thể trong mỗi khung hình mà mô hình phân tích:
Python
# Define the objects to find
queries = [
"pen (on desk)",
"pen (in robot hand)",
"laptop (opened)",
"laptop (closed)",
]
base_prompt = f"""
Point to the following objects in the provided image: {', '.join(queries)}.
The answer should follow the json format:
[{{"point": , "label": }}, ...].
The points are in [y, x] format normalized to 0-1000.
If no objects are found, return an empty JSON list [].
"""
Đầu ra cho thấy một cây bút và máy tính xách tay đang được theo dõi trên các khung hình video.
![]()
Để xem toàn bộ mã có thể chạy, hãy xem Sổ tay về robot học.
Phát hiện đối tượng và khung hình chữ nhật
Ngoài các điểm đơn lẻ, mô hình này cũng có thể trả về các khung hình chữ nhật 2D, cung cấp một vùng hình chữ nhật bao quanh một đối tượng.
Ví dụ này yêu cầu hộp giới hạn 2D cho các đối tượng có thể nhận dạng trên một chiếc bàn. Mô hình được hướng dẫn giới hạn đầu ra ở 25 đối tượng và đặt tên riêng cho nhiều thực thể.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Return bounding boxes as a JSON array with labels. Never return masks
or code fencing. Limit to 25 objects. Include as many objects as you
can identify on the table.
If an object is present multiple times, name them according to their
unique characteristic (colors, size, position, unique characteristics, etc..).
The format should be as follows: [{"box_2d": [ymin, xmin, ymax, xmax],
"label": <label for the object>}] normalized to 0-1000. The values in
box_2d must only be integers
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
Sau đây là các hộp được trả về từ mô hình.
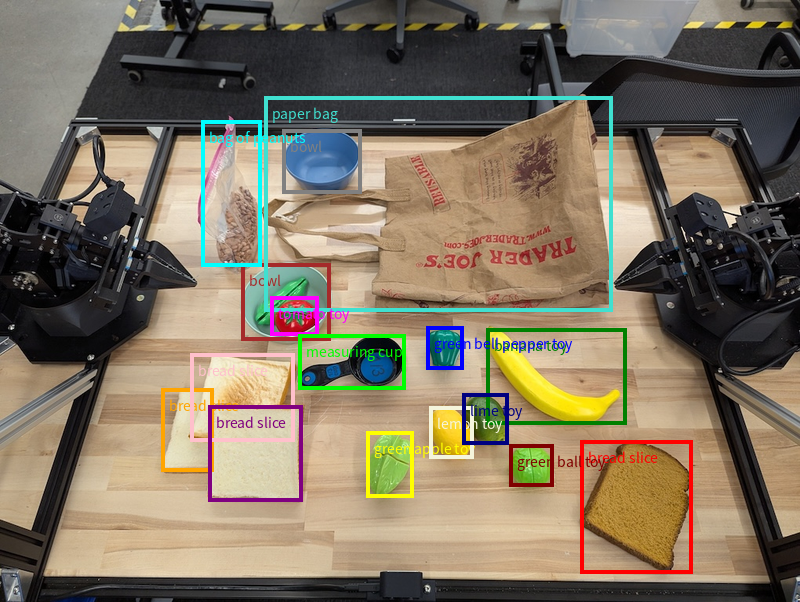
Để xem mã có thể chạy đầy đủ, hãy xem Sổ tay về robot học. Trang Hiểu hình ảnh cũng có các ví dụ khác về những tác vụ trực quan như phát hiện đối tượng và ví dụ về khung hình chữ nhật.
Quỹ đạo
Gemini Robotics-ER 1.6 có thể tạo ra các chuỗi điểm xác định quỹ đạo, hữu ích cho việc hướng dẫn chuyển động của robot.
Ví dụ này yêu cầu một quỹ đạo để di chuyển bút đỏ đến một hộp đựng, bao gồm cả điểm bắt đầu và một loạt điểm trung gian.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
points_data = []
prompt = """
Place a point on the red pen, then 15 points for the trajectory of
moving the red pen to the top of the organizer on the left.
The points should be labeled by order of the trajectory, from '0'
(start point at left hand) to <n> (final point)
The answer should follow the json format:
[{"point": <point>, "label": <label1>}, ...].
The points are in [y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
)
)
print(image_response.text)
Phản hồi là một tập hợp các toạ độ mô tả quỹ đạo của đường dẫn mà bút màu đỏ phải đi theo để hoàn thành nhiệm vụ di chuyển bút lên trên cùng của trình sắp xếp:
[
{"point": [550, 610], "label": "0"},
{"point": [500, 600], "label": "1"},
{"point": [450, 590], "label": "2"},
{"point": [400, 580], "label": "3"},
{"point": [350, 550], "label": "4"},
{"point": [300, 520], "label": "5"},
{"point": [250, 490], "label": "6"},
{"point": [200, 460], "label": "7"},
{"point": [180, 430], "label": "8"},
{"point": [160, 400], "label": "9"},
{"point": [140, 370], "label": "10"},
{"point": [120, 340], "label": "11"},
{"point": [110, 320], "label": "12"},
{"point": [105, 310], "label": "13"},
{"point": [100, 305], "label": "14"},
{"point": [100, 300], "label": "15"}
]

Khả năng của tác nhân AI
Các ví dụ sau đây minh hoạ khả năng suy luận nâng cao của robot bằng cách sử dụng các khả năng của tác nhân AI của mô hình, cụ thể là thực thi mã. Trong những trường hợp này, mô hình có thể quyết định viết và thực thi mã Python để thao tác với hình ảnh (chẳng hạn như phóng to, cắt hoặc xoay) nhằm giải quyết sự mơ hồ hoặc cải thiện độ chính xác trước khi trả lời.
Phát hiện đối tượng (Thu phóng và cắt)
Ví dụ sau đây minh hoạ cách sử dụng tính năng thực thi mã để thu phóng và cắt ảnh nhằm có chế độ xem rõ ràng hơn khi phát hiện các đối tượng và trả về các hộp giới hạn.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('sorting.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
Return JSON in the format {label: val, y: val, x: val, y2: val, x2: val} for
the compostable objects in this scene. Please Zoom and crop the image for a
clearer view. Return an annotated image of the final result with the bounding
boxes drawn on it to the API caller as a part of your process.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
Đầu ra của mô hình sẽ tương tự như sau:
[
{"label": "compostable", "y": 256, "x": 482, "y2": 295, "x2": 546},
{"label": "compostable", "y": 317, "x": 478, "y2": 350, "x2": 542},
{"label": "compostable", "y": 586, "x": 556, "y2": 668, "x2": 595},
{"label": "compostable", "y": 463, "x": 669, "y2": 511, "x2": 718},
{"label": "compostable", "y": 178, "x": 565, "y2": 250, "x2": 609}
]
Sau đây là các hộp được trả về từ mô hình.

Đọc đồng hồ đo analog và áp dụng logic
Ví dụ sau đây minh hoạ cách sử dụng mô hình để đọc đồng hồ đo tương tự và thực hiện các phép tính thời gian. Công cụ này sử dụng một chỉ dẫn hệ thống để thực thi đầu ra JSON.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('clock.jpg', 'rb') as f:
image_bytes = f.read()
q_time = """
Tell me what the value is. Please respond in the following JSON format:\n {\n "hours": X,\n "minutes": Y,\n}. Zoom in or crop as necessary to confirm location of the clock hands.
"""
system_instruction = "Be precise. When JSON is requested, reply with ONLY that JSON (no preface, no code block)."
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
system_instruction + " " + q_time
],
config = types.GenerateContentConfig(
temperature=1.0,
)
)
print(response.text)
Sau đây là một ví dụ về dữ liệu đầu vào hình ảnh.

Đầu ra của mô hình sẽ tương tự như sau:
Time Response: {
"hours": 12,
"minutes": 44
}
Đo chất lỏng trong một bình chứa
Ví dụ sau đây cho biết cách sử dụng tính năng thực thi mã để đọc đồng hồ đo và tính toán mức chất lỏng theo tỷ lệ phần trăm.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('meter.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
How full is the meter of liquid?
To read it,
1) Find the points for the top of the sight window, bottom of the sight window and the liquid level, formatted as [y, x] with values ranging from 0-1000;
2) Use math to determine the liquid level as a percentage;
3) Output "Answer: ??" on a separate line, where ?? is a number without % or unit.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
Sau đây là hình ảnh đầu vào được phóng to.

Đọc các dấu hiệu trên bảng mạch
Ví dụ sau đây minh hoạ cách sử dụng tính năng thực thi mã để đọc văn bản trên một chip bảng mạch, cho phép mô hình thu phóng, cắt và xoay hình ảnh khi cần.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('circuit_board.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = "What is the number on the ESMT chip? Zoom, crop, and rotate if needed."
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
Sau đây là hình ảnh đầu vào được phóng to.

Chú thích hình ảnh
Ví dụ sau đây minh hoạ cách sử dụng tính năng thực thi mã để chú thích một hình ảnh (ví dụ: vẽ mũi tên cho hướng dẫn xử lý) và trả về hình ảnh đã sửa đổi.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('sorting.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
Look at this image and return it as an annotated version using arrows of
different colors to represent which items should go in which bins for
disposal. You must return the final image to the API caller.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
Sau đây là một ví dụ về dữ liệu đầu vào hình ảnh.

Đầu ra của mô hình sẽ tương tự như sau:
The annotated image shows the suggested disposal locations for the items on the table:
- **Green bin (Compost/Organic)**: Green chili, red chili, grapes, and cherries.
- **Blue bin (Recycling)**: Yellow crushed can and plastic container.
- **Black bin (Trash)**: Chocolate bar wrapper, Welch's packet, and white tissue.
Phối khí
Gemini Robotics-ER 1.6 có thể thực hiện lập kế hoạch cho công việc và suy luận không gian ở cấp độ cao hơn, suy luận các hành động hoặc xác định vị trí tối ưu dựa trên khả năng hiểu ngữ cảnh để điều phối các công việc trong thời gian dài.
Tạo không gian cho máy tính xách tay
Ví dụ này minh hoạ cách Gemini Robotics-ER có thể suy luận về một không gian. Câu lệnh yêu cầu mô hình xác định đối tượng nào cần được di chuyển để tạo không gian cho một mục khác.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Point to the object that I need to remove to make room for my laptop
The answer should follow the json format: [{"point": <point>,
"label": <label1>}, ...]. The points are in [y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
Phản hồi chứa toạ độ 2D của đối tượng trả lời câu hỏi của người dùng, trong trường hợp này là đối tượng cần di chuyển để nhường chỗ cho máy tính xách tay.
[
{"point": [672, 301], "label": "The object that I need to remove to make room for my laptop"}
]

Chuẩn bị bữa trưa
Mô hình này cũng có thể cung cấp hướng dẫn cho các tác vụ nhiều bước và chỉ đến các đối tượng có liên quan cho từng bước. Ví dụ này cho thấy cách mô hình lên kế hoạch cho một loạt các bước để đóng gói túi đựng bữa trưa.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-of-lunch.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Explain how to pack the lunch box and lunch bag. Point to each
object that you refer to. Each point should be in the format:
[{"point": [y, x], "label": }], where the coordinates are
normalized between 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
Câu trả lời cho câu lệnh này là một bộ hướng dẫn từng bước về cách đóng gói một túi đựng bữa trưa từ dữ liệu đầu vào là hình ảnh.
Hình ảnh đầu vào

Đầu ra của mô hình
Based on the image, here is a plan to pack the lunch box and lunch bag:
1. **Pack the fruit into the lunch box.** Place the [apple](apple), [banana](banana), [red grapes](red grapes), and [green grapes](green grapes) into the [blue lunch box](blue lunch box).
2. **Add the spoon to the lunch box.** Put the [blue spoon](blue spoon) inside the lunch box as well.
3. **Close the lunch box.** Secure the lid on the [blue lunch box](blue lunch box).
4. **Place the lunch box inside the lunch bag.** Put the closed [blue lunch box](blue lunch box) into the [brown lunch bag](brown lunch bag).
5. **Pack the remaining items into the lunch bag.** Place the [blue snack bar](blue snack bar) and the [brown snack bar](brown snack bar) into the [brown lunch bag](brown lunch bag).
Here is the list of objects and their locations:
* [{"point": [899, 440], "label": "apple"}]
* [{"point": [814, 363], "label": "banana"}]
* [{"point": [727, 470], "label": "red grapes"}]
* [{"point": [675, 608], "label": "green grapes"}]
* [{"point": [706, 529], "label": "blue lunch box"}]
* [{"point": [864, 517], "label": "blue spoon"}]
* [{"point": [499, 401], "label": "blue snack bar"}]
* [{"point": [614, 705], "label": "brown snack bar"}]
* [{"point": [448, 501], "label": "brown lunch bag"}]
Gọi một API rô-bốt tuỳ chỉnh
Ví dụ này minh hoạ việc điều phối tác vụ bằng một API robot tuỳ chỉnh. Thư viện này giới thiệu một API mô phỏng được thiết kế cho hoạt động chọn và đặt. Việc cần làm là nhặt một khối màu xanh dương và đặt vào một chiếc bát màu cam:

Tương tự như các ví dụ khác trên trang này, mã có thể chạy đầy đủ có trong Sổ tay về robot học.
Bước đầu tiên là xác định vị trí của cả hai mục bằng câu lệnh sau:
Python
prompt = """
Locate and point to the blue block and the orange bowl. The label
returned should be an identifying name for the object detected.
The answer should follow the json format: [{"point": <point>, "label": <label1>}, ...].
The points are in [y, x] format normalized to 0-1000.
"""
Phản hồi của mô hình bao gồm toạ độ được chuẩn hoá của khối và bát:
[
{"point": [389, 252], "label": "orange bowl"},
{"point": [727, 659], "label": "blue block"}
]
Ví dụ này sử dụng API robot mô phỏng sau:
Python
def move(x, y, high):
print(f"moving to coordinates: {x}, {y}, {15 if high else 5}")
def setGripperState(opened):
print("Opening gripper" if opened else "Closing gripper")
def returnToOrigin():
print("Returning to origin pose")
Bước tiếp theo là gọi một chuỗi các hàm API với logic cần thiết để thực thi thao tác. Câu lệnh sau đây bao gồm nội dung mô tả về API robot mà mô hình nên sử dụng khi điều phối tác vụ này.
Python
prompt = f"""
You are a robotic arm with six degrees-of-freedom. You have the
following functions available to you:
def move(x, y, high):
# moves the arm to the given coordinates. The boolean value 'high' set
to True means the robot arm should be lifted above the scene for
avoiding obstacles during motion. 'high' set to False means the robot
arm should have the gripper placed on the surface for interacting with
objects.
def setGripperState(opened):
# Opens the gripper if opened set to true, otherwise closes the gripper
def returnToOrigin():
# Returns the robot to an initial state. Should be called as a cleanup
operation.
The origin point for calculating the moves is at normalized point
y={robot_origin_y}, x={robot_origin_x}. Use this as the new (0,0) for
calculating moves, allowing x and y to be negative.
Perform a pick and place operation where you pick up the blue block at
normalized coordinates ({block_x}, {block_y}) (relative coordinates:
{block_relative_x}, {block_relative_y}) and place it into the orange
bowl at normalized coordinates ({bowl_x}, {bowl_y})
(relative coordinates: {bowl_relative_x}, {bowl_relative_y}).
Provide the sequence of function calls as a JSON list of objects, where
each object has a "function" key (the function name) and an "args" key
(a list of arguments for the function).
Also, include your reasoning before the JSON output.
For example:
Reasoning: To pick up the block, I will first move the arm to a high
position above the block, open the gripper, move down to the block,
close the gripper, lift the arm, move to a high position above the bowl,
move down to the bowl, open the gripper, and then lift the arm back to
a high position.
"""
Sau đây là kết quả đầu ra có thể có của mô hình dựa trên câu lệnh và API rô-bốt mô phỏng. Kết quả đầu ra bao gồm quy trình suy nghĩ của mô hình và các nhiệm vụ mà mô hình đã lên kế hoạch. Nó cũng cho thấy đầu ra của các lệnh gọi hàm rô-bốt mà mô hình đã sắp xếp theo trình tự.
Reasoning: To perform the pick and place operation, I will first move the
robotic arm to a high position above the blue block to ensure clearance. Then, I
will open the gripper in preparation for grasping. Next, I will lower the arm to
the surface level to position the gripper around the block and close the gripper
to secure it. After picking up the block, I will lift the arm to clear the
surface and move towards the orange bowl, maintaining a high position to avoid
collisions. Once positioned above the bowl, I will lower the arm to place the
block inside. I will then open the gripper to release the block. Finally, I will
lift the arm out of the bowl and call `returnToOrigin` to reset the robot's
state.
[
{
"function": "move",
"args": [
163,
427,
true
]
},
{
"function": "setGripperState",
"args": [
true
]
},
{
"function": "move",
"args": [
163,
427,
false
]
},
{
"function": "setGripperState",
"args": [
false
]
},
{
"function": "move",
"args": [
163,
427,
true
]
},
{
"function": "move",
"args": [
-247,
90,
true
]
},
{
"function": "move",
"args": [
-247,
90,
false
]
},
{
"function": "setGripperState",
"args": [
true
]
},
{
"function": "move",
"args": [
-247,
90,
true
]
},
{
"function": "returnToOrigin",
"args": []
}
]
Executing Function Calls:
moving to coordinates: 163, 427, 15
Opening gripper
moving to coordinates: 163, 427, 5
Closing gripper
moving to coordinates: 163, 427, 15
moving to coordinates: -247, 90, 15
moving to coordinates: -247, 90, 5
Opening gripper
moving to coordinates: -247, 90, 15
Returning to origin pose
Các phương pháp hay nhất
Để tối ưu hoá hiệu suất và độ chính xác của các ứng dụng robot, bạn cần phải hiểu cách tương tác hiệu quả với mô hình Gemini. Phần này trình bày các phương pháp hay nhất và chiến lược chính để tạo câu lệnh, xử lý dữ liệu trực quan và cấu trúc hoá các tác vụ nhằm đạt được kết quả đáng tin cậy nhất.
Sử dụng ngôn từ rõ ràng và đơn giản.
Sử dụng ngôn ngữ tự nhiên: Mô hình Gemini được thiết kế để hiểu ngôn ngữ tự nhiên, ngôn ngữ đàm thoại. Hãy xây dựng câu lệnh theo cách rõ ràng về mặt ngữ nghĩa và phản ánh cách một người sẽ tự nhiên đưa ra chỉ dẫn.
Sử dụng thuật ngữ hằng ngày: Chọn ngôn ngữ thông thường, hằng ngày thay vì biệt ngữ kỹ thuật hoặc chuyên ngành. Nếu mô hình không phản hồi một cụm từ cụ thể như mong đợi, hãy thử diễn đạt lại bằng một từ đồng nghĩa phổ biến hơn.
Tối ưu hoá dữ liệu đầu vào trực quan.
Phóng to để xem chi tiết: Khi xử lý các đối tượng nhỏ hoặc khó phân biệt trong một bức ảnh rộng, hãy dùng chức năng khung viền để tách biệt đối tượng mà bạn quan tâm. Sau đó, bạn có thể cắt hình ảnh theo lựa chọn này và gửi hình ảnh mới, tập trung vào mô hình để phân tích chi tiết hơn.
Thử nghiệm với ánh sáng và màu sắc: Cảm nhận của mô hình có thể bị ảnh hưởng bởi điều kiện ánh sáng khó khăn và độ tương phản màu kém.
Chia các vấn đề phức tạp thành các bước nhỏ hơn. Bằng cách giải quyết từng bước nhỏ riêng lẻ, bạn có thể hướng dẫn mô hình đạt được kết quả chính xác và thành công hơn.
Cải thiện độ chính xác thông qua sự đồng thuận. Đối với những tác vụ đòi hỏi độ chính xác cao, bạn có thể truy vấn mô hình nhiều lần bằng cùng một câu lệnh. Bằng cách tính trung bình các kết quả trả về, bạn có thể đạt được "sự đồng thuận" thường chính xác và đáng tin cậy hơn.
Các điểm hạn chế
Hãy cân nhắc những hạn chế sau đây khi phát triển bằng Gemini Robotics-ER 1.6:
- Trạng thái xem trước: Mô hình hiện đang ở trạng thái Xem trước. Các API và chức năng có thể thay đổi và có thể không phù hợp với các ứng dụng quan trọng trong quá trình sản xuất nếu không được kiểm thử kỹ lưỡng.
- Độ trễ: Các truy vấn phức tạp, dữ liệu đầu vào có độ phân giải cao hoặc
thinking_budgetcó dung lượng lớn có thể làm tăng thời gian xử lý. - Ảo tưởng: Giống như mọi mô hình ngôn ngữ lớn, Gemini Robotics-ER 1.6 đôi khi có thể "ảo tưởng" hoặc cung cấp thông tin không chính xác, đặc biệt là đối với những câu lệnh mơ hồ hoặc đầu vào nằm ngoài phạm vi phân phối.
- Phụ thuộc vào chất lượng câu lệnh: Chất lượng đầu ra của mô hình phụ thuộc rất nhiều vào độ rõ ràng và tính cụ thể của câu lệnh đầu vào. Câu lệnh mơ hồ hoặc có cấu trúc kém có thể dẫn đến kết quả không tối ưu.
- Chi phí điện toán: Việc chạy mô hình, đặc biệt là với dữ liệu đầu vào là video hoặc
thinking_budgetcó độ phân giải cao, sẽ tiêu tốn tài nguyên điện toán và phát sinh chi phí. Hãy xem trang Tư duy để biết thêm thông tin chi tiết. - Loại dữ liệu đầu vào: Xem các chủ đề sau để biết thông tin chi tiết về hạn chế đối với từng chế độ.
Thông báo về quyền riêng tư
Bạn xác nhận rằng các mô hình được đề cập trong tài liệu này ("Mô hình robot") tận dụng dữ liệu video và âm thanh để hoạt động và di chuyển phần cứng theo hướng dẫn của bạn. Do đó, bạn có thể vận hành Các mô hình robot sao cho Các mô hình robot sẽ thu thập dữ liệu của những người có thể nhận dạng, chẳng hạn như dữ liệu giọng nói, hình ảnh và dữ liệu về hình ảnh khuôn mặt ("Dữ liệu cá nhân"). Nếu chọn vận hành Các mô hình robot theo cách thu thập Dữ liệu cá nhân, bạn đồng ý rằng bạn sẽ không cho phép bất kỳ cá nhân nào có thể nhận dạng tương tác hoặc xuất hiện trong khu vực xung quanh Các mô hình robot, trừ phi và cho đến khi những cá nhân có thể nhận dạng đó được thông báo đầy đủ và đồng ý với việc Dữ liệu cá nhân của họ có thể được Google cung cấp và sử dụng như được nêu trong Điều khoản dịch vụ bổ sung về Gemini API tại https://ai.google.dev/gemini-api/terms ("Điều khoản"), kể cả theo phần "Cách Google sử dụng dữ liệu của bạn". Bạn sẽ đảm bảo rằng thông báo đó cho phép thu thập và sử dụng dữ liệu cá nhân như được nêu trong Điều khoản, đồng thời bạn sẽ nỗ lực một cách hợp lý về phương diện thương mại để giảm thiểu việc thu thập và phân phối dữ liệu cá nhân bằng cách sử dụng các kỹ thuật như làm mờ khuôn mặt và vận hành Mô hình robot ở những khu vực không có người có thể nhận dạng được trong phạm vi có thể thực hiện được.
Giá
Để biết thông tin chi tiết về giá và các khu vực có cung cấp dịch vụ, hãy tham khảo trang định giá.
Phiên bản mô hình
Robotics-ER 1.6 Preview
| Thuộc tính | Mô tả |
|---|---|
| Mã kiểu máy | gemini-robotics-er-1.6-preview |
| Các loại dữ liệu được hỗ trợ |
Thông tin đầu vào Văn bản, hình ảnh, video, âm thanh Đầu ra Văn bản |
| Giới hạn mã thông báo[*] |
Giới hạn mã thông báo đầu vào 131.072 Giới hạn mã thông báo đầu ra 65.536 |
| Chức năng | Không được hỗ trợ Được hỗ trợ Được hỗ trợ Được hỗ trợ Được hỗ trợ Được hỗ trợ Được hỗ trợ Không được hỗ trợ Không được hỗ trợ Tìm trong phần liên kết thực tế Được hỗ trợ Được hỗ trợ Được hỗ trợ Được hỗ trợ |
| Các lựa chọn thưởng thức nội dung |
Được hỗ trợ Được hỗ trợ Được hỗ trợ |
| Phiên bản |
|
| Thông tin cập nhật mới nhất | Tháng 12 năm 2025 |
| Điểm cắt kiến thức | Tháng 1 năm 2025 |
Các bước tiếp theo
- Khám phá các khả năng khác và tiếp tục thử nghiệm nhiều câu lệnh cũng như dữ liệu đầu vào để khám phá thêm các ứng dụng cho Gemini Robotics-ER 1.6. Hãy xem Colab về cách bắt đầu sử dụng Robotics để biết thêm ví dụ.
- Tìm hiểu về cách các mô hình Gemini Robotics được xây dựng chú trọng đến sự an toàn, hãy truy cập vào trang an toàn về robot của Google DeepMind.
- Đọc thông tin cập nhật mới nhất về các mô hình Gemini Robotics trên trang đích của Gemini Robotics.