
Обработка запросов клиентов, включая электронные письма, является необходимой частью ведения многих предприятий, но она быстро может стать непосильной задачей. Приложив немного усилий, модели искусственного интеллекта (ИИ), такие как Gemma, могут помочь упростить эту работу.
Каждый бизнес обрабатывает запросы, такие как электронные письма, немного по-разному, поэтому важно уметь адаптировать такие технологии, как генеративный ИИ, к потребностям вашего бизнеса. Этот проект решает конкретную проблему извлечения информации о заказах из электронных писем, отправленных в пекарню, в структурированные данные, чтобы их можно было быстро добавить в систему обработки заказов. Используя от 10 до 20 примеров запросов и желаемый результат, вы можете настроить модель Gemma для обработки электронных писем от ваших клиентов, быстрого ответа и интеграции с существующими бизнес-системами. Этот проект построен как шаблон приложения ИИ, который вы можете расширять и адаптировать, чтобы извлечь пользу из моделей Gemma для вашего бизнеса.
Видеообзор проекта и способов его расширения, включая советы от разработчиков, можно посмотреть в видеоролике « Business Email AI Assistant Build with Google AI». Вы также можете ознакомиться с кодом проекта в репозитории Gemma Cookbook . В противном случае, вы можете начать расширять проект, следуя приведенным ниже инструкциям.
Обзор
В этом руководстве вы узнаете, как настроить, запустить и расширить приложение-помощник для работы с электронной почтой, созданное с использованием Gemma, Python и Flask. Проект предоставляет базовый веб-интерфейс пользователя, который вы можете модифицировать в соответствии со своими потребностями. Приложение предназначено для извлечения данных из электронных писем клиентов и преобразования их в структуру для вымышленной пекарни. Вы можете использовать этот шаблон приложения для любой бизнес-задачи, требующей ввода и вывода текста.
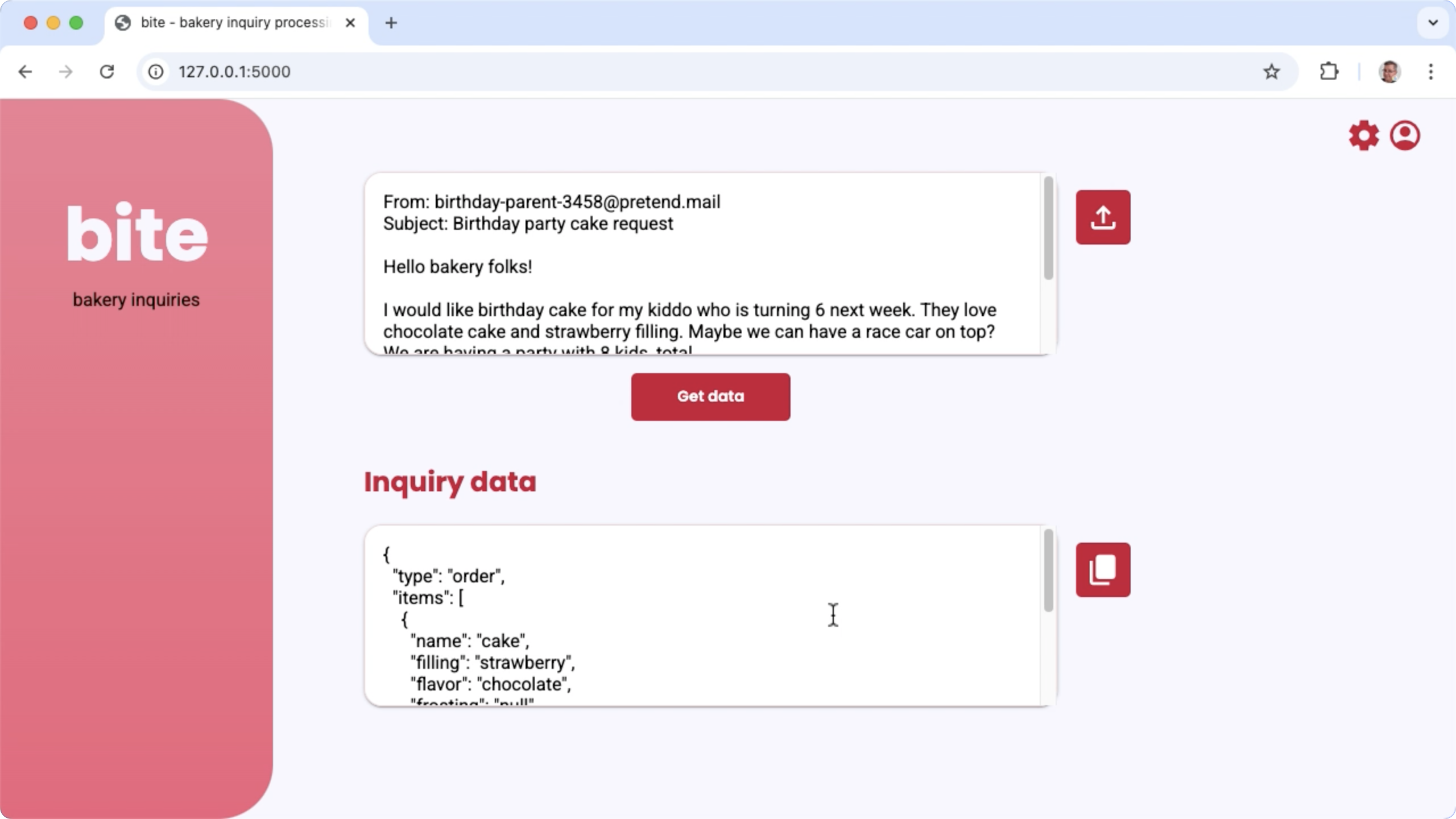
Рисунок 1. Пользовательский интерфейс проекта для обработки запросов по электронной почте от пекарни.
Требования к оборудованию
Запустите этот процесс настройки на компьютере с графическим процессором (GPU) или тензорным процессором (TPU) и достаточным объемом памяти GPU или TPU для хранения существующей модели, а также данных для настройки. Для запуска конфигурации настройки в этом проекте вам потребуется около 16 ГБ памяти GPU, примерно такой же объем обычной оперативной памяти и минимум 50 ГБ дискового пространства.
Для настройки модели Gemma в рамках этого руководства можно использовать среду Colab с графическим процессором T4 . Если вы создаете этот проект на виртуальной машине Google Cloud, настройте ее в соответствии со следующими требованиями:
- Для запуска этого проекта требуется графический процессор NVIDIA T4 (рекомендуется NVIDIA L4 или выше).
- Операционная система : выберите вариант «Глубокое обучение на Linux» , а именно виртуальную машину глубокого обучения с CUDA 12.3 M124 и предустановленными драйверами для графического процессора.
- Размер загрузочного диска : выделите не менее 50 ГБ дискового пространства для ваших данных, моделей и вспомогательного программного обеспечения.
Настройка проекта
Эти инструкции помогут вам подготовить проект к разработке и тестированию. Общие шаги по настройке включают установку необходимого программного обеспечения, клонирование проекта из репозитория кода, настройку нескольких переменных среды, установку библиотек Python и тестирование веб-приложения.
Установка и настройка
В этом проекте используется Python 3 и виртуальные среды ( venv ) для управления пакетами и запуска приложения. Приведенные ниже инструкции по установке предназначены для хост-машины под управлением Linux.
Для установки необходимого программного обеспечения:
Установите Python 3 и пакет виртуальной среды
venvдля Python:sudo apt update sudo apt install git pip python3-venv
Клонируйте проект
Загрузите код проекта на свой компьютер для разработки. Для получения исходного кода проекта вам потребуется система контроля версий Git .
Чтобы скачать код проекта:
Клонируйте репозиторий Git, используя следующую команду:
git clone https://github.com/google-gemini/gemma-cookbook.gitПри желании настройте локальный репозиторий Git на использование разреженного извлечения (sparse checkout), чтобы у вас оставались только файлы проекта:
cd gemma-cookbook/ git sparse-checkout set Demos/business-email-assistant/ git sparse-checkout init --cone
Установите библиотеки Python.
Установите библиотеки Python, активировав виртуальную среду Python venv , чтобы управлять пакетами и зависимостями Python. Убедитесь, что вы активировали виртуальную среду Python перед установкой библиотек Python с помощью установщика pip . Для получения дополнительной информации об использовании виртуальных сред Python см. документацию по Python venv .
Для установки библиотек Python:
В окне терминала перейдите в каталог
business-email-assistant:cd Demos/business-email-assistant/Настройте и активируйте виртуальную среду Python (venv) для этого проекта:
python3 -m venv venv source venv/bin/activateУстановите необходимые для этого проекта библиотеки Python с помощью скрипта
setup_python:./setup_python.sh
Установите переменные среды
Для запуска этого проекта требуется несколько переменных окружения, включая имя пользователя Kaggle и токен API Kaggle. У вас должна быть учетная запись Kaggle, и вы должны запросить доступ к моделям Gemma, чтобы иметь возможность их загрузить. Для этого проекта вам нужно добавить ваше имя пользователя Kaggle и токен API Kaggle в два файла .env , которые будут считываться веб-приложением и программой настройки соответственно.
Чтобы установить переменные среды:
- Получите свое имя пользователя Kaggle и ключ токена, следуя инструкциям в документации Kaggle .
- Получите доступ к модели Gemma, следуя инструкциям по получению доступа к Gemma на странице настройки Gemma .
- Создайте файлы переменных окружения для проекта, создав текстовый файл
.envв каждом из указанных мест в клонированной копии проекта:email-processing-webapp/.env model-tuning/.env
После создания текстовых файлов
.envдобавьте в оба файла следующие настройки:KAGGLE_USERNAME=<YOUR_KAGGLE_USERNAME_HERE> KAGGLE_KEY=<YOUR_KAGGLE_KEY_HERE>
Запустите и протестируйте приложение.
После завершения установки и настройки проекта запустите веб-приложение, чтобы убедиться в правильности его настройки. Это следует сделать для базовой проверки перед редактированием проекта для собственного использования.
Для запуска и тестирования проекта:
В окне терминала перейдите в каталог
email-processing-webapp:cd business-email-assistant/email-processing-webapp/Запустите приложение с помощью скрипта
run_app:./run_app.shПосле запуска веб-приложения программный код выводит URL-адрес, по которому можно перейти на сайт и протестировать его. Обычно этот адрес выглядит следующим образом:
http://127.0.0.1:5000/В веб-интерфейсе нажмите кнопку «Получить данные» под первым полем ввода, чтобы получить ответ от модели.
Первый ответ от модели после запуска приложения занимает больше времени, поскольку ей необходимо завершить этапы инициализации при первом запуске генерации. Последующие запросы и генерация в уже запущенном веб-приложении завершаются за меньшее время.
Расширьте возможности приложения
После запуска приложения вы можете расширить его функциональность, изменив пользовательский интерфейс и бизнес-логику, чтобы оно работало для задач, актуальных для вас или вашего бизнеса. Вы также можете изменить поведение модели Gemma, используя код приложения, изменив компоненты запроса, который приложение отправляет модели генеративного ИИ.
Приложение предоставляет модели инструкции вместе с входными данными от пользователя, а также полный запрос модели. Вы можете изменять эти инструкции, чтобы изменить поведение модели, например, указать имена параметров и структуру генерируемого JSON. Более простой способ изменить поведение модели — предоставить дополнительные инструкции или указания для ответа модели, например, указать, что сгенерированные ответы не должны содержать никакого форматирования Markdown.
Чтобы изменить инструкции командной строки:
- В проекте разработки откройте файл кода
business-email-assistant/email-processing-webapp/app.py. В коде
app.pyдобавьте дополнительные инструкции к функцииget_prompt()::def get_prompt(): return """ Extract the relevant details of this request and return them in JSON code, with no additional markdown formatting:\n"""
В этом примере в инструкции добавляется фраза "без дополнительного форматирования Markdown".
Предоставление дополнительных подсказок может существенно повлиять на сгенерированный результат и требует значительно меньше усилий для реализации. Вам следует сначала попробовать этот метод, чтобы убедиться, что вы сможете получить желаемое поведение от модели. Однако использование подсказок для изменения поведения модели Gemma имеет свои ограничения. В частности, общее ограничение на количество входных токенов модели, которое составляет 8192 токена для Gemma 2, требует от вас баланса между подробными подсказками и размером новых предоставляемых данных, чтобы оставаться в пределах этого лимита.
Настройте модель
Рекомендуется выполнять тонкую настройку модели Gemma, чтобы добиться от нее более надежной работы при решении конкретных задач. В частности, если вы хотите, чтобы модель генерировала JSON с определенной структурой, включая параметры с определенными именами, следует настроить модель именно для такого поведения. В зависимости от задачи, которую должна выполнять модель, базовую функциональность можно реализовать с помощью 10-20 примеров. В этом разделе руководства объясняется, как настроить и выполнить тонкую настройку модели Gemma для конкретной задачи.
В следующих инструкциях описано, как выполнить тонкую настройку в среде виртуальной машины, однако вы также можете выполнить эту настройку с помощью соответствующей записной книжки Colab для этого проекта.
Требования к оборудованию
Требования к вычислительным ресурсам для тонкой настройки такие же, как и для остальной части проекта. Вы можете запустить операцию настройки в среде Colab с использованием среды выполнения T4 GPU , если ограничите количество входных токенов до 256 и размер пакета до 1.
Подготовка данных
Прежде чем начать настройку модели Gemma, необходимо подготовить данные для настройки. При настройке модели для конкретной задачи вам потребуется набор примеров запросов и ответов. Эти примеры должны показывать текст запроса без каких-либо инструкций и ожидаемый текст ответа. Для начала следует подготовить набор данных, содержащий около 10 примеров. Эти примеры должны представлять все возможные запросы и идеальные ответы. Убедитесь, что запросы и ответы не повторяются, так как это может привести к повторяющимся ответам модели и неспособности адекватно адаптироваться к изменениям в запросах. Если вы настраиваете модель для получения структурированного формата данных, убедитесь, что все предоставленные ответы строго соответствуют желаемому формату выходных данных. В следующей таблице показаны несколько примеров записей из набора данных этого примера кода:
| Запрос | Ответ |
|---|---|
| Здравствуйте, Indian Bakery Central! У вас случайно нет в наличии 10 пенд и 30 бунди ладду? Также, продаете ли вы торты с ванильной глазурью и шоколадным вкусом? Мне нужен торт диаметром 6 дюймов. | { "type": "inquiry", "items": [ { "name": "pendas", "quantity": 10 }, { "name": "bundi ladoos", "quantity": 30 }, { "name": "cake", "filling": null, "frosting": "vanilla", "flavor": "chocolate", "size": "6 in" } ] } |
| Я увидел ваше заведение на Google Maps. Вы продаете джеллаби и гулаб джамун? | { "type": "inquiry", "items": [ { "name": "jellabi", "quantity": null }, { "name": "gulab jamun", "quantity": null } ] } |
Таблица 1. Частичный список набора данных для настройки инструмента извлечения данных электронной почты пекарни.
Формат и загрузка данных
Вы можете хранить данные для настройки в любом удобном формате, включая записи в базе данных, файлы JSON, CSV или текстовые файлы, при условии, что у вас есть возможность извлекать эти записи с помощью кода Python. В этом проекте файлы JSON считываются из каталога data в массив объектов-словарей. В этом примере программы настройки набор данных загружается в модуль model-tuning/main.py с помощью функции prepare_tuning_dataset() :
def prepare_tuning_dataset():
# collect data from JSON files
prompt_data = read_json_files_to_dicts("./data")
...
Как уже упоминалось ранее, вы можете хранить набор данных в удобном формате, при условии, что вы можете получить запросы вместе с соответствующими ответами и собрать их в текстовую строку, которая используется в качестве записи для настройки.
Собрать записи настройки
Для фактического процесса настройки программа объединяет каждый запрос и ответ в одну строку, содержащую инструкции запроса и содержимое ответа. Затем программа настройки разбивает строку на токены для использования моделью. Код для формирования записи настройки можно увидеть в функции prepare_tuning_dataset() модуля model-tuning/main.py , как показано ниже:
def prepare_tuning_dataset():
...
# prepare data for tuning
tuning_dataset = []
template = "{instruction}\n{response}"
for prompt in prompt_data:
tuning_dataset.append(template.format(instruction=prompt["prompt"],
response=prompt["response"]))
return tuning_dataset
Эта функция принимает данные в качестве входных и форматирует их, добавляя перенос строки между инструкцией и ответом.
Сгенерировать веса модели
После того, как данные для настройки будут подготовлены и загружены, вы можете запустить программу настройки. В этом примере процесса настройки используется библиотека Keras NLP для настройки модели с помощью метода адаптации низкого ранга (LoRA), который генерирует новые веса модели. По сравнению с настройкой с полной точностью, использование LoRA значительно эффективнее с точки зрения использования памяти, поскольку оно аппроксимирует изменения весов модели. Затем вы можете наложить эти аппроксимированные веса на существующие веса модели, чтобы изменить поведение модели.
Для выполнения процедуры настройки и расчета новых весов:
В окне терминала перейдите в каталог
model-tuning/.cd business-email-assistant/model-tuning/Запустите процесс настройки с помощью скрипта
tune_model:./tune_model.sh
Процесс настройки занимает несколько минут в зависимости от доступных вычислительных ресурсов. После успешного завершения программа настройки записывает новые файлы весов *.h5 в каталог model-tuning/weights в следующем формате:
gemma2-2b_inquiry_tuned_4_epoch##.lora.h5
Поиск неисправностей
Если настройка не завершится успешно, вероятны две причины:
- Ошибка "Недостаточно памяти или исчерпаны ресурсы" : эти ошибки возникают, когда процесс настройки запрашивает память, превышающую доступную память графического процессора или центрального процессора. Убедитесь, что веб-приложение не запущено во время выполнения процесса настройки. Если вы выполняете настройку на устройстве с 16 ГБ памяти графического процессора, убедитесь, что параметр
token_limitустановлен на 256 , а параметрbatch_size— на 1 . - Драйверы графического процессора не установлены или несовместимы с JAX : Для процесса настройки требуется, чтобы на вычислительном устройстве были установлены аппаратные драйверы, совместимые с версией библиотек JAX . Для получения более подробной информации см. документацию по установке JAX .
Развернуть настроенную модель
В процессе настройки генерируется несколько весов на основе данных настройки и общего количества эпох, заданного в приложении для настройки. По умолчанию программа настройки генерирует 3 файла весов модели, по одному для каждой эпохи настройки. Каждая последующая эпоха настройки создает веса, которые более точно воспроизводят результаты данных настройки. Вы можете увидеть показатели точности для каждой эпохи в выводе терминала процесса настройки, как показано ниже:
...
8/8 ━━━━━━━━━━━━━━━━━━━━ 121s 195ms/step - loss: 0.5432 - sparse_categorical_accuracy: 0.5982
Epoch 2/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 194ms/step - loss: 0.3320 - sparse_categorical_accuracy: 0.6966
Epoch 3/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 192ms/step - loss: 0.2135 - sparse_categorical_accuracy: 0.7848
Хотя желательно, чтобы точность была относительно высокой, около 0,80, не следует допускать её чрезмерного повышения или приближения к 1,00, поскольку это означает, что веса приблизились к переобучению на данных для настройки. В этом случае модель плохо работает с запросами, которые значительно отличаются от примеров настройки. По умолчанию скрипт развертывания выбирает веса 3-й эпохи, точность которых обычно составляет около 0,80.
Для развертывания сгенерированных весов в веб-приложении:
В окне терминала перейдите в каталог
model-tuning:cd business-email-assistant/model-tuning/Запустите процесс настройки с помощью скрипта
deploy_weights:./deploy_weights.sh
После выполнения этого скрипта в каталоге email-processing-webapp/weights/ должен появиться новый файл *.h5 .
Протестируйте новую модель
После того, как вы развернете новые веса в приложении, пришло время протестировать обновленную модель. Для этого вы можете перезапустить веб-приложение и сгенерировать ответ.
Для запуска и тестирования проекта:
В окне терминала перейдите в каталог
email-processing-webapp:cd business-email-assistant/email-processing-webapp/Запустите приложение с помощью скрипта
run_app:./run_app.shПосле запуска веб-приложения программный код выводит URL-адрес, по которому можно перейти и протестировать приложение; обычно этот адрес выглядит следующим образом:
http://127.0.0.1:5000/В веб-интерфейсе нажмите кнопку «Получить данные» под первым полем ввода, чтобы получить ответ от модели.
Вы успешно настроили и развернули модель Gemma в приложении! Поэкспериментируйте с приложением и попытайтесь определить пределы возможностей генерации настроенной модели для вашей задачи. Если вы обнаружите сценарии, в которых модель работает плохо, добавьте некоторые из этих запросов в список примеров данных для настройки, добавив запрос и предоставив идеальный ответ. Затем повторно запустите процесс настройки, повторно разверните новые веса и протестируйте результат.
Дополнительные ресурсы
Более подробную информацию об этом проекте можно найти в репозитории кода Gemma Cookbook . Если вам нужна помощь в разработке приложения или вы хотите сотрудничать с другими разработчиками, загляните на сервер Discord сообщества разработчиков Google . Больше проектов Build with Google AI вы найдете в видеоплейлисте .