

Tugas MediaPipe Pose Landmarker memungkinkan Anda mendeteksi penanda tubuh manusia dalam gambar atau video. Anda dapat menggunakan tugas ini untuk mengidentifikasi lokasi tubuh utama, menganalisis postur, dan mengategorikan gerakan. Tugas ini menggunakan model machine learning (ML) yang berfungsi dengan satu gambar atau video. Tugas ini menghasilkan penanda pose tubuh dalam koordinat gambar dan dalam koordinat dunia 3 dimensi.
Mulai
Mulai gunakan tugas ini dengan mengikuti panduan penerapan untuk platform target Anda. Panduan khusus platform ini akan memandu Anda dalam penerapan dasar tugas ini, termasuk model yang direkomendasikan, dan contoh kode dengan opsi konfigurasi yang direkomendasikan:
- Android - Contoh kode - Panduan
- Python - Contoh kode - Panduan
- Web - Contoh kode - Panduan
Detail tugas
Bagian ini menjelaskan kemampuan, input, output, dan opsi konfigurasi tugas ini.
Fitur
- Pemrosesan gambar input - Pemrosesan mencakup rotasi gambar, pengubahan ukuran, normalisasi, dan konversi ruang warna.
- Batas skor - Memfilter hasil berdasarkan skor prediksi.
| Input tugas | Output tugas |
|---|---|
Pose Landmarker menerima input dari salah satu jenis data berikut:
|
Pose Landmarker menghasilkan output berikut:
|
Opsi konfigurasi
Tugas ini memiliki opsi konfigurasi berikut:
| Nama Opsi | Deskripsi | Rentang Nilai | Nilai Default |
|---|---|---|---|
running_mode |
Menetapkan mode berjalan untuk tugas. Ada tiga
mode: GAMBAR: Mode untuk input gambar tunggal. VIDEO: Mode untuk frame video yang didekode. LIVE_STREAM: Mode untuk live stream data input, seperti dari kamera. Dalam mode ini, resultListener harus dipanggil untuk menyiapkan pemroses guna menerima hasil secara asinkron. |
{IMAGE, VIDEO, LIVE_STREAM} |
IMAGE |
num_poses |
Jumlah maksimum pose yang dapat dideteksi oleh Pose Landmarker. | Integer > 0 |
1 |
min_pose_detection_confidence |
Skor keyakinan minimum agar deteksi pose dianggap berhasil. | Float [0.0,1.0] |
0.5 |
min_pose_presence_confidence |
Skor keyakinan minimum dari skor kehadiran postur dalam deteksi penanda postur. | Float [0.0,1.0] |
0.5 |
min_tracking_confidence |
Skor keyakinan minimum agar pelacakan postur dianggap berhasil. | Float [0.0,1.0] |
0.5 |
output_segmentation_masks |
Apakah Pose Landmarker menghasilkan mask segmentasi untuk postur yang terdeteksi. | Boolean |
False |
result_callback |
Menetapkan pemroses hasil untuk menerima hasil penanda secara asinkron saat Pose Landmarker berada dalam mode live stream.
Hanya dapat digunakan jika mode berjalan disetel ke LIVE_STREAM |
ResultListener |
N/A |
Model
Pose Landmarker menggunakan serangkaian model untuk memprediksi penanda pose. Model pertama mendeteksi keberadaan tubuh manusia dalam bingkai gambar, dan model kedua menemukan penanda pada tubuh.
Model berikut dikemas bersama ke dalam paket model yang dapat didownload:
- Model deteksi pose: mendeteksi kehadiran tubuh dengan beberapa penanda pose utama.
- Model penanda pose: menambahkan pemetaan lengkap pose. Model ini mengeluarkan estimasi 33 penanda pose 3 dimensi.
Paket ini menggunakan jaringan saraf konvolusi yang mirip dengan MobileNetV2 dan dioptimalkan untuk aplikasi kebugaran real-time di perangkat. Varian dari model BlazePose ini menggunakan GHUM, pipeline pemodelan bentuk manusia 3D, untuk memperkirakan pose tubuh 3D lengkap seseorang dalam gambar atau video.
| Paket model | Bentuk input | Jenis data | Kartu Model | Versi |
|---|---|---|---|---|
| Pose landmarker (lite) | Detektor pose: 224 x 224 x 3 Penanda pose: 256 x 256 x 3 |
float 16 | info | Terbaru |
| Penanda pose (Lengkap) | Detektor pose: 224 x 224 x 3 Penanda pose: 256 x 256 x 3 |
float 16 | info | Terbaru |
| Penanda posisi pose (Beban berat) | Detektor pose: 224 x 224 x 3 Penanda pose: 256 x 256 x 3 |
float 16 | info | Terbaru |
Model penanda pose
Model penanda pose melacak 33 lokasi penanda tubuh, yang mewakili perkiraan lokasi bagian tubuh berikut:
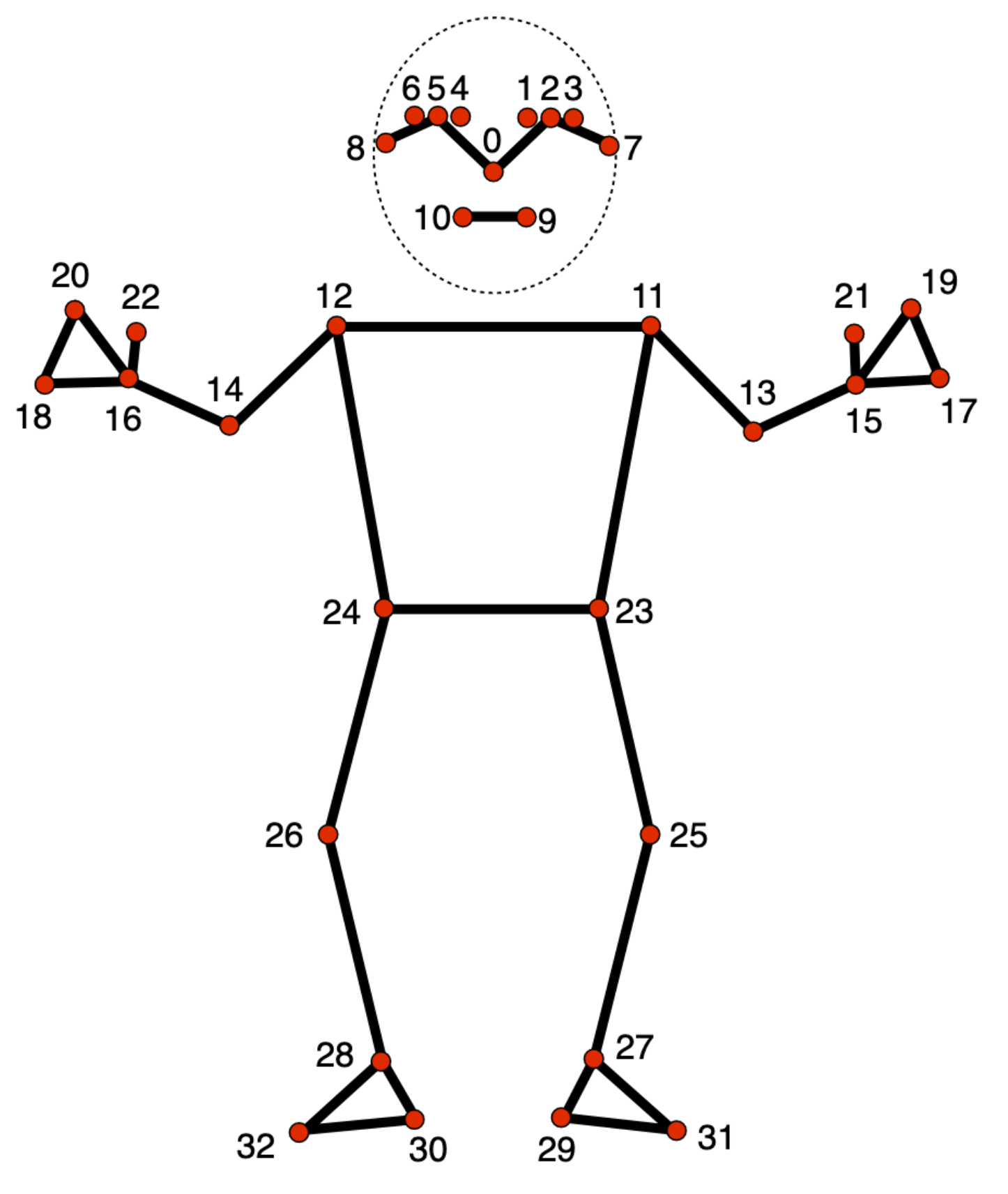
0 - nose
1 - left eye (inner)
2 - left eye
3 - left eye (outer)
4 - right eye (inner)
5 - right eye
6 - right eye (outer)
7 - left ear
8 - right ear
9 - mouth (left)
10 - mouth (right)
11 - left shoulder
12 - right shoulder
13 - left elbow
14 - right elbow
15 - left wrist
16 - right wrist
17 - left pinky
18 - right pinky
19 - left index
20 - right index
21 - left thumb
22 - right thumb
23 - left hip
24 - right hip
25 - left knee
26 - right knee
27 - left ankle
28 - right ankle
29 - left heel
30 - right heel
31 - left foot index
32 - right foot index
Output model berisi koordinat ternormalisasi (Landmarks) dan koordinat
dunia (WorldLandmarks) untuk setiap penanda.