
Đánh giá song song đã trở thành một chiến lược phổ biến để đánh giá chất lượng và độ an toàn của câu trả lời từ các mô hình ngôn ngữ lớn (LLM). Cạnh nhau phép so sánh để chọn giữa hai mô hình khác nhau, hai lời nhắc cho cùng một mô hình hoặc thậm chí hai cách điều chỉnh khác nhau của một mô hình. Tuy nhiên, phân tích thủ công các kết quả so sánh song song với nhau theo cách thủ công có thể rườm rà và phức tạp là tẻ nhạt.
Trình so sánh LLM là một ứng dụng web có chức năng đồng hành Thư viện Python giúp bạn phân tích có thể mở rộng hiệu quả hơn về các đánh giá song song với hình ảnh tương tác. Trình so sánh LLM giúp bạn:
Xem điểm khác biệt về hiệu suất của mô hình: Bạn có thể phân tách các câu trả lời để xác định các tập hợp con của dữ liệu đánh giá, trong đó có kết quả có ý nghĩa khác nhau giữa hai mô hình.
Tìm hiểu lý do khiến hiệu suất khác nhau: Thông thường, bạn sẽ có một chính sách về việc đánh giá hiệu suất và mức độ tuân thủ của mô hình. Quá trình đánh giá song song giúp tự động hoá việc tuân thủ chính sách các đánh giá và giải thích lý do cho mô hình nào có khả năng tuân thủ chính sách. Trình so sánh LLM tóm tắt những lý do này thành một số chủ đề và làm nổi bật mô hình nào phù hợp hơn với từng chủ đề.
Kiểm tra sự khác biệt về kết quả của mô hình như thế nào: Bạn có thể tìm hiểu thêm về cách đầu ra từ hai mô hình khác nhau thông qua nội dung tích hợp sẵn và do người dùng xác định hàm so sánh. Công cụ này có thể làm nổi bật các mẫu cụ thể trong văn bản mà mô hình đã tạo, cung cấp một điểm neo rõ ràng để hiểu được sự khác biệt giữa các mô hình.
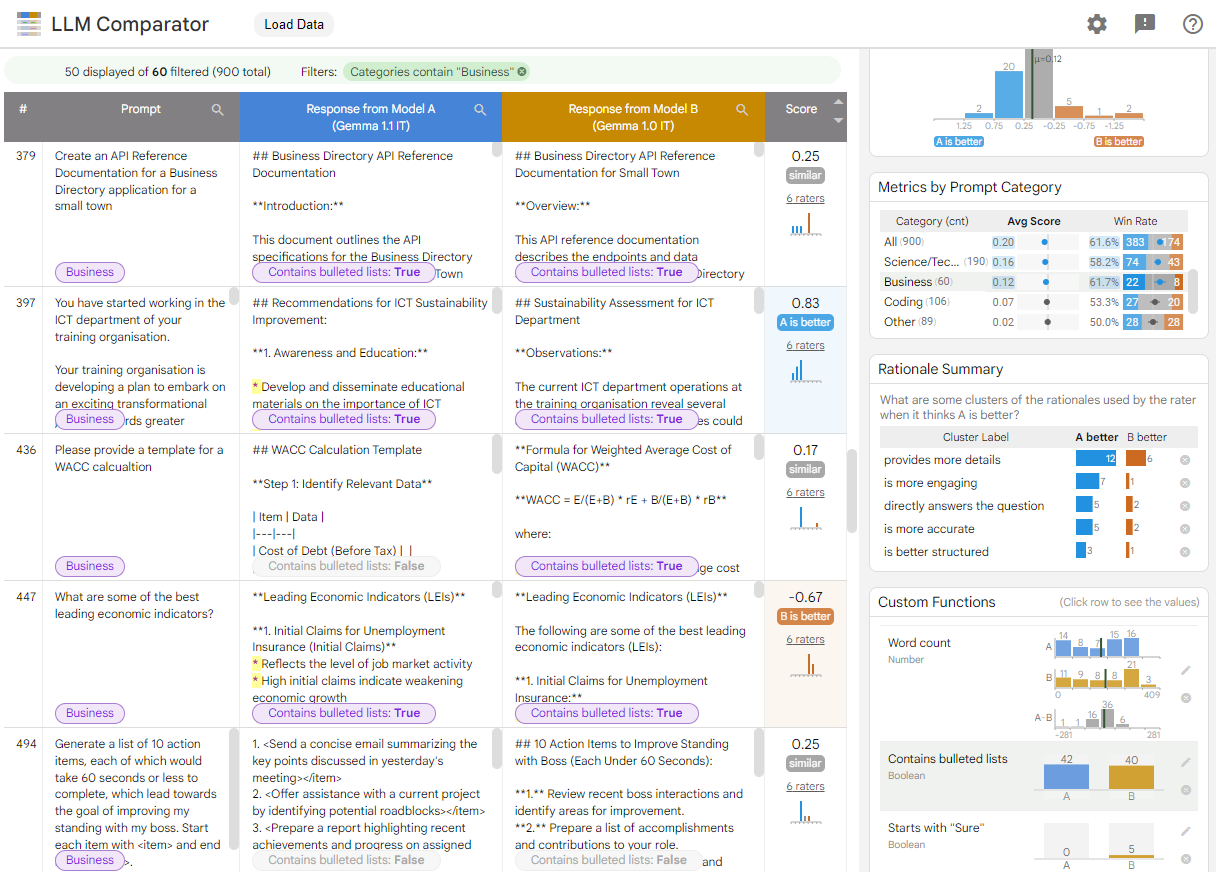
Hình 1. Giao diện Trình so sánh LLM cho thấy bảng so sánh mô hình Gemma Instruction 7B phiên bản 1.1 với phiên bản 1.0
Trình so sánh LLM giúp bạn phân tích kết quả đánh giá song song. Công cụ này tóm tắt hiệu suất của mô hình theo nhiều góc độ một cách trực quan, đồng thời cho phép bạn kiểm tra tương tác các kết quả của từng mô hình để hiểu rõ hơn.
Tự khám phá Trình so sánh LLM:
- Bản minh hoạ này so sánh hiệu suất của Gemma Instruct 7B phiên bản 1.1 với Gemma Instruct 7B phiên bản 1.0 trên tập dữ liệu Chatbot Arena Conversations.
- Sổ tay Colab này sử dụng thư viện Python để chạy một quy trình đánh giá song song nhỏ bằng Vertex AI API và tải kết quả vào ứng dụng LLM Comparator trong một ô.
Để biết thêm thông tin về Trình so sánh LLM, hãy xem bài viết nghiên cứu và Kho lưu trữ GitHub.