Gemini API, uygulamanızın daha kısıtlayıcı veya daha az kısıtlayıcı bir güvenlik yapılandırması gerektirip gerektirmediğini belirlemek için prototip oluşturma aşamasında ayarlayabileceğiniz güvenlik ayarları sunar. Belirli içerik türlerini kısıtlamak veya bunlara izin vermek için bu ayarları dört filtre kategorisinde düzenleyebilirsiniz.
Bu kılavuzda, Gemini API'nin güvenlik ayarlarını ve filtrelemeyi nasıl işlediği ve uygulamanızın güvenlik ayarlarını nasıl değiştirebileceğiniz açıklanmaktadır.
Güvenlik filtreleri
Gemini API'nin ayarlanabilir güvenlik filtreleri aşağıdaki kategorileri kapsar:
| Kategori | Açıklama |
|---|---|
| Taciz | Kimliği ve/veya korunan özellikleri hedef alan olumsuz veya zararlı yorumlar |
| Nefret söylemi | Kaba, saygısız veya küfürlü içerik |
| Müstehcen | Cinsel eylemlere veya diğer müstehcen içeriklere referanslar içeriyor. |
| Tehlikeli | Zararlı eylemleri teşvik eden, kolaylaştıran veya destekleyen içerikler |
Bu kategoriler HarmCategory içinde tanımlanır. Kullanım alanınıza göre ayarlamalar yapmak için bu filtreleri kullanabilirsiniz. Örneğin, video oyunu diyaloğu oluşturuyorsanız oyunun doğası gereği Tehlikeli olarak derecelendirilen daha fazla içeriğe izin vermeyi kabul edebilirsiniz.
Ayarlanabilir güvenlik filtrelerine ek olarak, Gemini API'de çocukların güvenliğini tehlikeye atan içerikler gibi temel zararlara karşı yerleşik korumalar bulunur. Bu tür zararlar her zaman engellenir ve ayarlanamaz.
İçerik güvenliği filtreleme düzeyi
Gemini API, içeriğin güvenli olmama olasılık düzeyini HIGH, MEDIUM, LOW veya NEGLIGIBLE olarak sınıflandırır.
Gemini API, içeriğin güvenli olmama olasılığına göre içeriği engeller. İçeriğin ne kadar zararlı olduğu dikkate alınmaz. Zararın ciddiyeti yüksek olsa bile bazı içeriklerin güvenli olmama olasılığı düşük olabilir. Bu nedenle, bu durumu göz önünde bulundurmak önemlidir. Örneğin, şu cümleleri karşılaştıralım:
- Robot bana yumruk attı.
- Robot beni doğradı.
İlk cümle, güvenli olmama olasılığının daha yüksek olmasına neden olabilir ancak ikinci cümlenin şiddet açısından daha ciddi olduğunu düşünebilirsiniz. Bu nedenle, son kullanıcılara zarar vermeyi en aza indirirken temel kullanım alanlarınızı desteklemek için uygun engelleme düzeyinin ne olduğunu dikkatlice test etmeniz ve değerlendirmeniz önemlidir.
İstek başına güvenlik filtreleme
API'ye yaptığınız her istek için güvenlik ayarlarını düzenleyebilirsiniz. İstek gönderdiğinizde içerik analiz edilir ve içeriğe güvenlik derecesi atanır. Güvenlik derecelendirmesi, zarar sınıflandırmasının kategorisini ve olasılığını içerir. Örneğin, içerik taciz kategorisinin yüksek olasılıkla güvenli olmaması nedeniyle engellendiyse döndürülen güvenlik derecelendirmesinde kategori HARASSMENT'ya eşit olur ve zarar olasılığı HIGH olarak ayarlanır.
Modelin doğasında bulunan güvenlik nedeniyle ek filtreler varsayılan olarak Kapalı'dır. Bu ayarları etkinleştirmeyi seçerseniz sistemi, güvenli olmama olasılığına göre içerikleri engelleyecek şekilde yapılandırabilirsiniz. Varsayılan model davranışı çoğu kullanım alanını kapsar. Bu nedenle, bu ayarları yalnızca uygulamanızda tutarlılık gerekiyorsa değiştirmeniz gerekir.
Aşağıdaki tabloda, her kategori için ayarlayabileceğiniz engelleme ayarları açıklanmaktadır. Örneğin, Nefret söylemi kategorisi için engelleme ayarını Birkaçını engelle olarak belirlerseniz nefret söylemi içeriği olma olasılığı yüksek olan her şey engellenir. Ancak olasılığı daha düşük olan her şeye izin verilir.
| Eşik (Google AI Studio) | Eşik (API) | Açıklama |
|---|---|---|
| Kapalı | OFF |
Güvenlik filtresini devre dışı bırakma |
| Hiçbirini engelleme | BLOCK_NONE |
Güvenli olmayan içerik olasılığına bakılmaksızın her zaman göster |
| Birkaçını engelle | BLOCK_ONLY_HIGH |
İçeriğin güvenli olmama olasılığı yüksekse engelle |
| Bazılarını engelleme | BLOCK_MEDIUM_AND_ABOVE |
İçeriğin güvenli olmama olasılığı orta veya yüksekse engelle |
| Çoğunu engelle | BLOCK_LOW_AND_ABOVE |
İçeriğin güvenli olmama olasılığı düşük, orta veya yüksekse engelle |
| Yok | HARM_BLOCK_THRESHOLD_UNSPECIFIED |
Eşik belirtilmemişse varsayılan eşik kullanılarak engellenir. |
Eşik ayarlanmazsa Gemini 2.5 ve 3 modelleri için varsayılan engelleme eşiği Kapalı olur.
Bu ayarları, üretken hizmete yaptığınız her istek için belirleyebilirsiniz.
Ayrıntılar için HarmBlockThreshold API referansına bakın.
Güvenlikle ilgili geri bildirim
generateContent
güvenlik geri bildirimi içeren
GenerateContentResponse döndürür.
İstem geri bildirimi, promptFeedback'e dahil edilir. promptFeedback.blockReason ayarlanmışsa istemin içeriği engellenmiştir.
Yanıta aday geri bildirimi Candidate.finishReason ve Candidate.safetyRatings içinde yer alır. Yanıt içeriği engellendiyse ve finishReason SAFETY ise daha fazla bilgi için safetyRatings öğesini inceleyebilirsiniz. Engellenen içerik geri yüklenmez.
Güvenlik ayarlarını düzenleme
Bu bölümde, hem Google AI Studio'da hem de kodunuzda güvenlik ayarlarının nasıl düzenleneceği açıklanmaktadır.
Google AI Studio
Güvenlik ayarlarını Google AI Studio'da yapabilirsiniz.
Çalıştırma ayarları panelindeki Gelişmiş ayarlar bölümünde Güvenlik ayarları'nı tıklayarak Çalıştırma güvenlik ayarları modalını açın. Modalda, kaydırma çubuklarını kullanarak güvenlik kategorisine göre içerik filtreleme düzeyini ayarlayabilirsiniz:
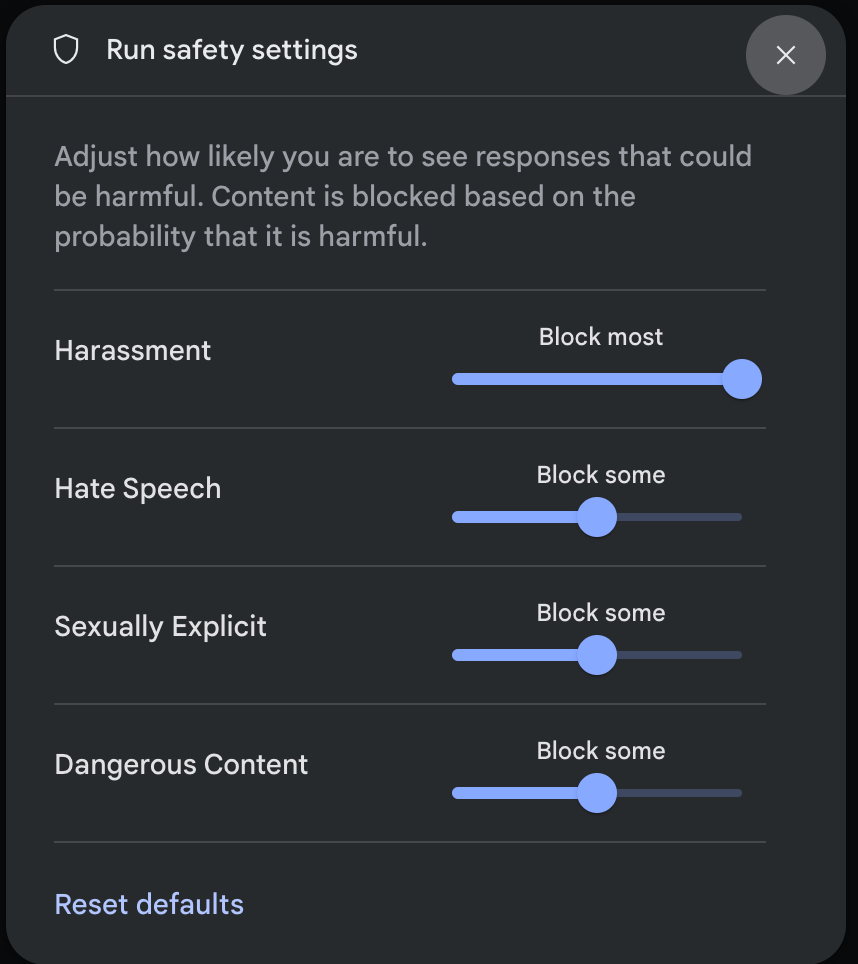
İstek gönderdiğinizde (ör. modele soru sorarak) isteğin içeriği engellenirse İçerik engellendi mesajı gösterilir. Daha fazla ayrıntı görmek için işaretçiyi İçerik engellendi metninin üzerine getirin. Böylece kategori ve zararlı olma olasılığı sınıflandırmasını görebilirsiniz.
Kod örnekleri
Aşağıdaki kod snippet'inde, GenerateContent görüşmenizde güvenlik ayarlarının nasıl yapılacağı gösterilmektedir. Bu, nefret söylemi (HARM_CATEGORY_HATE_SPEECH) kategorisinin eşiğini belirler. Bu kategoriyi BLOCK_LOW_AND_ABOVE olarak ayarladığınızda, nefret söylemi olma olasılığı düşük veya yüksek olan tüm içerikler engellenir. Eşik ayarlarını anlamak için İstek başına güvenlik filtreleme başlıklı makaleyi inceleyin.
Python
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.5-flash",
contents="Some potentially unsafe prompt",
config=types.GenerateContentConfig(
safety_settings=[
types.SafetySetting(
category=types.HarmCategory.HARM_CATEGORY_HATE_SPEECH,
threshold=types.HarmBlockThreshold.BLOCK_LOW_AND_ABOVE,
),
]
)
)
print(response.text)
Go
package main
import (
"context"
"fmt"
"log"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateContentConfig{
SafetySettings: []*genai.SafetySetting{
{
Category: "HARM_CATEGORY_HATE_SPEECH",
Threshold: "BLOCK_LOW_AND_ABOVE",
},
},
}
response, err := client.Models.GenerateContent(
ctx,
"gemini-3.5-flash",
genai.Text("Some potentially unsafe prompt."),
config,
)
if err != nil {
log.Fatal(err)
}
fmt.Println(response.Text())
}
JavaScript
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({});
const safetySettings = [
{
category: "HARM_CATEGORY_HATE_SPEECH",
threshold: "BLOCK_LOW_AND_ABOVE",
},
];
async function main() {
const response = await ai.models.generateContent({
model: "gemini-3.5-flash",
contents: "Some potentially unsafe prompt.",
config: {
safetySettings: safetySettings,
},
});
console.log(response.text);
}
await main();
Java
SafetySetting hateSpeechSafety = new SafetySetting(HarmCategory.HATE_SPEECH,
BlockThreshold.LOW_AND_ABOVE);
GenerativeModel gm = new GenerativeModel(
"gemini-3.5-flash",
BuildConfig.apiKey,
null, // generation config is optional
Arrays.asList(hateSpeechSafety)
);
GenerativeModelFutures model = GenerativeModelFutures.from(gm);
REST
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.5-flash:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"safetySettings": [
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_LOW_AND_ABOVE"}
],
"contents": [{
"parts":[{
"text": "'\''Some potentially unsafe prompt.'\''"
}]
}]
}'
Sonraki adımlar
- API'nin tamamı hakkında daha fazla bilgi edinmek için API referansına bakın.
- LLM'lerle geliştirme yaparken güvenlikle ilgili dikkat edilmesi gereken noktalar hakkında genel bilgi edinmek için güvenlik kılavuzunu inceleyin.
- Jigsaw ekibinin olasılık ve önem düzeyini değerlendirme hakkındaki makalesinden daha fazla bilgi edinin.
- Perspective API gibi güvenlik çözümlerine katkıda bulunan ürünler hakkında daha fazla bilgi edinin. * Bu güvenlik ayarlarını kullanarak toksisite sınıflandırıcı oluşturabilirsiniz. Başlamak için sınıflandırma örneğine bakın.