
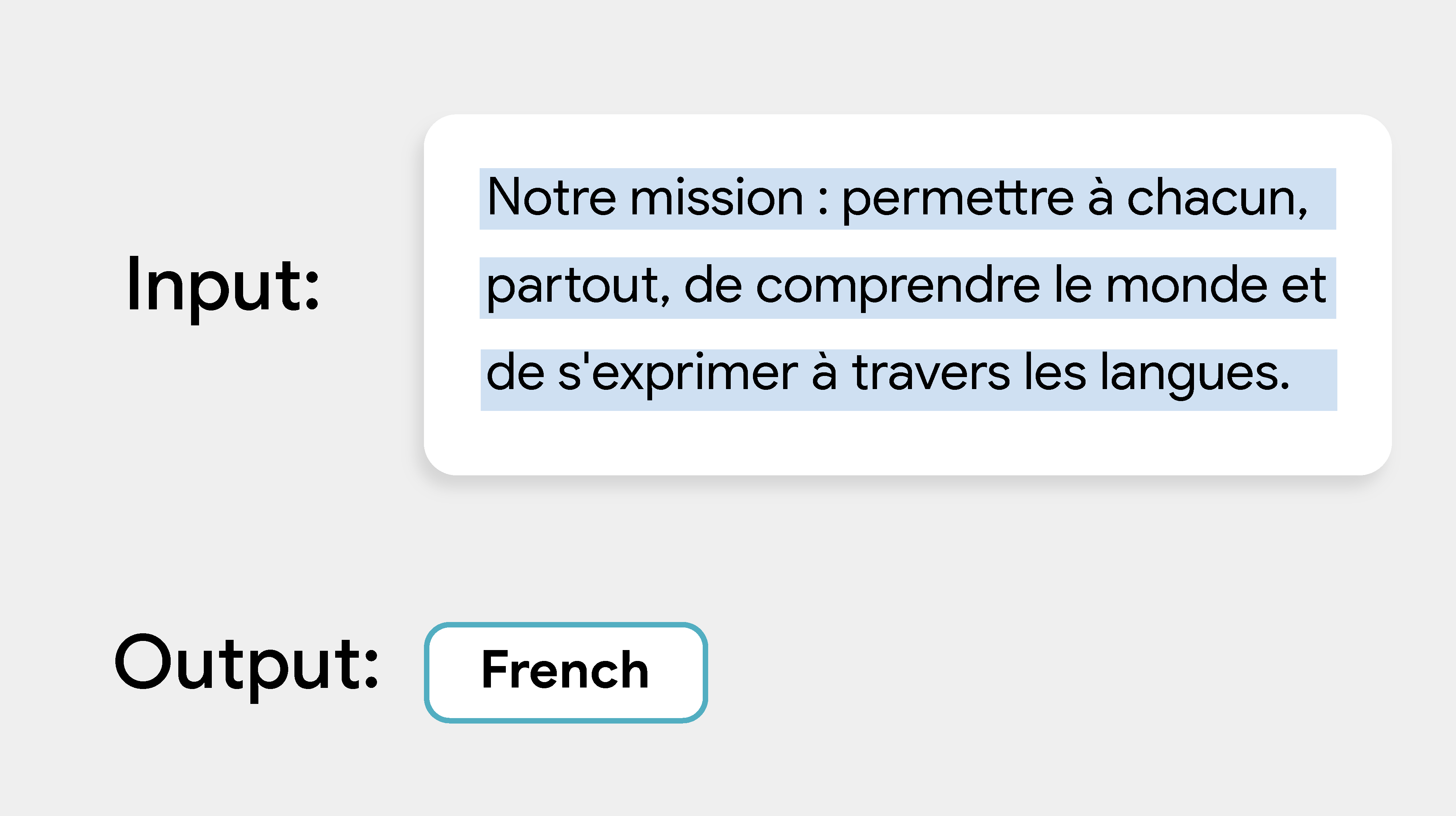
تتيح لك مهمة "أداة رصد اللغة" من MediaPipe تحديد لغة مقطع نصي. تعمل هذه ال tâche على بيانات النص باستخدام نموذج تعلُّم الآلة (ML) وتُخرج قائمة بالتوقعات، حيث يتألّف كلّ توقّع من رمز لغة ISO 639-1 ومقدار احتمالية.
البدء
ابدأ استخدام هذه المهمة باتّباع أحد أدلة التنفيذ هذه ل منصّتك المستهدفة. ترشدك هذه الأدلة الخاصة بالنظام الأساسي إلى تنفيذ أساسي لهذه المهمة، بما في ذلك نموذج مقترَح ومثال على الرمز المبرمَج مع خيارات الإعداد المقترَحة:
- Android - مثال على الرمز البرمجي - الدليل
- Python - مثال على الرمز البرمجي - الدليل
- الويب - مثال على الرمز البرمجي - الدليل
تفاصيل المهمة
يصف هذا القسم ميزات هذه المهمة ومدخلاتها ومخرجاتها وخيارات الضبط.
الميزات
- الحدّ الأدنى للنتيجة: فلترة النتائج استنادًا إلى نتائج التوقّعات
- القائمة المسموح بها والقائمة المحظورة للتصنيف: حدِّد الفئات التي تم رصدها.
| مدخلات المهام | نتائج المهام |
|---|---|
يقبل "أداة رصد اللغة" نوع بيانات الإدخال التالي:
|
يعرض "أداة رصد اللغة" قائمة بالتوقّعات التي تتضمّن ما يلي:
|
خيارات الإعدادات
تتضمّن هذه المهمة خيارات الضبط التالية:
| اسم الخيار | الوصف | نطاق القيمة | القيمة التلقائية |
|---|---|---|---|
max_results |
تُستخدَم لضبط الحد الأقصى الاختياري لعدد اقتراحات اللغات التي تحقّق أعلى الدرجات والتي تريد عرضها. إذا كانت هذه القيمة أقل من الصفر، يتم عرض جميع النتائج المتاحة. | أي أرقام موجبة | -1 |
score_threshold |
تُستخدَم لضبط الحدّ الأدنى لنتيجة التوقّع الذي يتجاوز الحدّ الأدنى المقدَّم في البيانات الوصفية للنموذج (إن توفّرت). ويتم رفض النتائج التي تقلّ عن هذه القيمة. | أيّ عائمة | لم يتم الضبط |
category_allowlist |
لضبط القائمة الاختيارية لرموز اللغات المسموح بها. إذا لم تكن فارغة، سيتمّ ترشيح توقّعات اللغة التي لا يتضمّن رمز لغتها هذه المجموعة. هذا الخيار غير متوافق مع
category_denylist، ويؤدي استخدام كليهما إلى ظهور خطأ. |
أي سلاسل | لم يتم الضبط |
category_denylist |
لضبط القائمة الاختيارية لرموز اللغات غير المسموح بها. إذا كانت هذه المجموعة غير فارغة، سيتم فلترة اقتراحات اللغة التي يحتوي رمز لغتها على هذه المجموعة. هذا الخيار غير متوافق مع الخيار category_allowlist، ويؤدي استخدام كليهما إلى حدوث خطأ. |
أي سلاسل | لم يتم الضبط |
النماذج
نقدّم نموذجًا تلقائيًا مقترَحًا عند بدء التطوير باستخدام هذه المهمة.
نموذج أداة رصد اللغة (إجراء مقترَح)
تم تصميم هذا النموذج ليكون خفيفًا (315 كيلوبايت) ويستخدم بنية تصنيف الشبكات العصبية المستندة إلى التضمين. يحدِّد النموذج اللغة باستخدام رمز ISO 639-1 للّغة، ويمكنه التعرّف على 110 لغة. للحصول على قائمة باللغات المتوافقة مع النموذج، اطّلِع على ملف التصنيف، الذي يسرد اللغات حسب رمزها ISO 639-1.
| اسم الطراز | شكل الإدخال | نوع التقريب | بطاقة النموذج | الإصدارات |
|---|---|---|---|---|
| أداة رصد اللغة | سلسلة UTF-8 | none (float32) | info | الأحدث |
مقاييس أداء المهام
في ما يلي مقاييس أداء المهام لعملية المعالجة بأكملها استنادًا إلى نماذج pretrained المدرَّبة مسبقًا أعلاه. نتيجة وقت الاستجابة هي متوسط وقت الاستجابة على هاتف Pixel 6 باستخدام وحدة المعالجة المركزية / وحدة معالجة الرسومات.
| اسم النموذج | وقت استجابة وحدة المعالجة المركزية | وقت استجابة وحدة معالجة الرسومات |
|---|---|---|
| أداة رصد اللغة | 0.31 ملي ثانية | - |