
A tarefa do MediaPipe Gesture Recognizer permite reconhecer gestos com as mãos em tempo real e fornece os resultados de gestos com as mãos reconhecidos e os pontos de referência das mãos detectadas. Estas instruções mostram como usar o Gesture Recognizer para apps da Web e JavaScript.
Para ver essa tarefa em ação, confira a demonstração. Para mais informações sobre os recursos, modelos e opções de configuração dessa tarefa, consulte a visão geral.
Exemplo de código
O exemplo de código do Gesture Recognizer oferece uma implementação completa dessa tarefa em JavaScript para sua referência. Esse código ajuda a testar a tarefa e começar a criar seu próprio app de reconhecimento de gestos. É possível visualizar, executar e editar o Gesture Recognizer exemplo usando apenas o navegador da Web.
Configuração
Esta seção descreve as etapas principais para configurar seu ambiente de desenvolvimento especificamente para usar o Gesture Recognizer. Para informações gerais sobre como configurar seu ambiente de desenvolvimento da Web e JavaScript, incluindo requisitos de versão da plataforma, consulte o Guia de configuração para a Web.
Pacotes JavaScript
O código do Gesture Recognizer está disponível no pacote @mediapipe/tasks-vision
NPM do MediaPipe. Você pode
encontrar e fazer o download dessas bibliotecas seguindo as instruções no
Guia de configuração da plataforma.
Você pode instalar os pacotes necessários pelo NPM usando o seguinte comando:
npm install @mediapipe/tasks-vision
Se você quiser importar o código da tarefa por um serviço de rede de fornecimento de conteúdo (CDN)
, adicione o seguinte código na tag <head> no arquivo HTML:
<!-- You can replace JSDeliver with another CDN if you prefer to -->
<head>
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision/vision_bundle.mjs"
crossorigin="anonymous"></script>
</head>
Modelo
A tarefa do MediaPipe Gesture Recognizer requer um modelo treinado compatível com ela. Para mais informações sobre os modelos treinados disponíveis para o Gesture Recognizer, consulte a seção Modelos da visão geral da tarefa.
Selecione e faça o download do modelo e armazene-o no diretório do projeto:
<dev-project-root>/app/shared/models/
Criar a tarefa
Use uma das funções createFrom...() do Gesture Recognizer para preparar a tarefa para executar inferências. Use a função createFromModelPath() com um caminho relativo ou absoluto para o arquivo modelo treinado.
Se o modelo já estiver carregado na memória, use o método createFromModelBuffer().
O exemplo de código abaixo demonstra o uso da função createFromOptions() para configurar a tarefa. A função createFromOptions permite personalizar o Gesture Recognizer com opções de configuração. Para mais informações sobre as opções de configuração, consulte Opções de configuração.
O código a seguir demonstra como criar e configurar a tarefa com opções personalizadas:
// Create task for image file processing:
const vision = await FilesetResolver.forVisionTasks(
// path/to/wasm/root
"https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision@latest/wasm "
);
const gestureRecognizer = await GestureRecognizer.createFromOptions(vision, {
baseOptions: {
modelAssetPath: "https://storage.googleapis.com/mediapipe-tasks/gesture_recognizer/gesture_recognizer.task"
},
numHands: 2
});
Opções de configuração
Essa tarefa tem as seguintes opções de configuração para aplicativos da Web:
| Nome da opção | Descrição | Intervalo de valor | Valor padrão |
|---|---|---|---|
runningMode |
Define o modo de execução da tarefa. Há dois
modos: IMAGE: o modo para entradas de imagem única. VIDEO: o modo para frames decodificados de um vídeo ou em uma transmissão ao vivo de dados de entrada, como de uma câmera. |
{IMAGE, VIDEO} |
IMAGE |
num_hands |
O número máximo de mãos que podem ser detectadas por
GestureRecognizer.
|
Any integer > 0 |
1 |
min_hand_detection_confidence |
A pontuação de confiança mínima para que a detecção de mãos seja considerada bem-sucedida no modelo de detecção de palmas. | 0.0 - 1.0 |
0.5 |
min_hand_presence_confidence |
A pontuação de confiança mínima da pontuação de presença de mãos no modelo de detecção de pontos de referência de mãos. No modo de vídeo e de transmissão ao vivo do Gesture Recognizer, se a pontuação de confiança de presença de mãos do modelo de pontos de referência de mãos estiver abaixo desse limite, ele vai acionar o modelo de detecção de palmas. Caso contrário, um algoritmo leve de captura de movimentos das mãos será usado para determinar a localização das mãos para a detecção de pontos de referência subsequente. | 0.0 - 1.0 |
0.5 |
min_tracking_confidence |
A pontuação de confiança mínima para que a captura de movimentos das mãos seja considerada bem-sucedida. Esse é o limite de IoU da caixa delimitadora entre as mãos no frame atual e no último. No modo de vídeo e de transmissão do Gesture Recognizer, se o rastreamento falhar, o Gesture Recognizer vai acionar a detecção de mãos. Caso contrário, a detecção de mãos será ignorada. | 0.0 - 1.0 |
0.5 |
canned_gestures_classifier_options |
Opções para configurar o comportamento do classificador de gestos enlatados. Os gestos enlatados são ["None", "Closed_Fist", "Open_Palm", "Pointing_Up", "Thumb_Down", "Thumb_Up", "Victory", "ILoveYou"] |
|
|
custom_gestures_classifier_options |
Opções para configurar o comportamento do classificador de gestos personalizados. |
|
|
Preparar dados
O Gesture Recognizer pode reconhecer gestos em imagens em qualquer formato compatível com o navegador host. A tarefa também processa a pré-processamento de entrada de dados, incluindo redimensionamento, rotação e normalização de valores. Para reconhecer gestos em vídeos, use a API para processar rapidamente um frame por vez, usando o carimbo de data/hora do frame para determinar quando os gestos ocorrem no vídeo.
Executar a tarefa
O Gesture Recognizer usa os recognize() (com o modo de execução 'image') e
recognizeForVideo() (com o modo de execução 'video') métodos para acionar
inferências. A tarefa processa os dados, tenta reconhecer gestos com as mãos e informa os resultados.
O código a seguir demonstra como executar o processamento com o modelo de tarefa:
Imagem
const image = document.getElementById("image") as HTMLImageElement; const gestureRecognitionResult = gestureRecognizer.recognize(image);
Vídeo
await gestureRecognizer.setOptions({ runningMode: "video" }); let lastVideoTime = -1; function renderLoop(): void { const video = document.getElementById("video"); if (video.currentTime !== lastVideoTime) { const gestureRecognitionResult = gestureRecognizer.recognizeForVideo(video); processResult(gestureRecognitionResult); lastVideoTime = video.currentTime; } requestAnimationFrame(() => { renderLoop(); }); }
As chamadas para os métodos recognize() e recognizeForVideo() do Gesture Recognizer são executadas de forma síncrona e bloqueiam a linha de execução da interface do usuário. Se você reconhecer gestos em frames de vídeo da câmera de um dispositivo, cada reconhecimento vai bloquear a linha de execução principal. Para evitar isso, implemente workers da Web para executar os métodos recognize() e recognizeForVideo() em outra linha de execução.
Para uma implementação mais completa da execução de uma tarefa do Gesture Recognizer, consulte o exemplo.
Processar e mostrar resultados
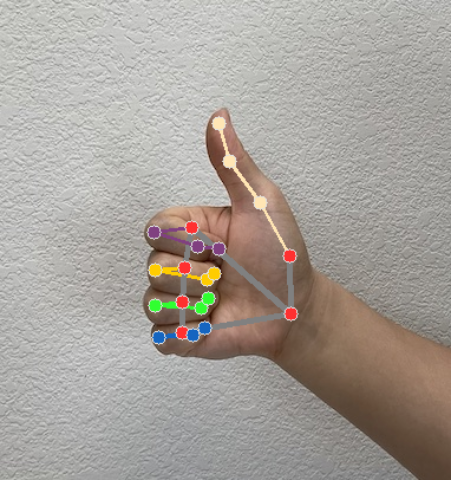
O Gesture Recognizer gera um objeto de resultado de detecção de gestos para cada execução de reconhecimento. O objeto de resultado contém pontos de referência de mãos em coordenadas de imagem, pontos de referência de mãos em coordenadas mundiais, mão dominante(esquerda/direita) e categorias de gestos de mãos detectadas.
Confira a seguir um exemplo dos dados de saída dessa tarefa:
O GestureRecognizerResult resultante contém quatro componentes, e cada componente é uma matriz, em que cada elemento contém o resultado detectado de uma única mão detectada.
Mão dominante
A mão dominante representa se as mãos detectadas são esquerda ou direita.
Gestos
As categorias de gestos reconhecidas das mãos detectadas.
Pontos de referência
Há 21 pontos de referência de mãos, cada um composto de coordenadas
x,yez. As coordenadasxeysão normalizadas para [0,0, 1,0] pela largura e altura da imagem, respectivamente. A coordenadazrepresenta a profundidade do ponto de referência, com a profundidade no pulso sendo a origem. Quanto menor o valor, mais próximo o ponto de referência está da câmera. A magnitude dezusa aproximadamente a mesma escala quex.Pontos de referência mundiais
Os 21 pontos de referência de mãos também são apresentados em coordenadas mundiais. Cada ponto de referência é composto por
x,yez, representando coordenadas 3D do mundo real em metros com a origem no centro geométrico da mão.
GestureRecognizerResult:
Handedness:
Categories #0:
index : 0
score : 0.98396
categoryName : Left
Gestures:
Categories #0:
score : 0.76893
categoryName : Thumb_Up
Landmarks:
Landmark #0:
x : 0.638852
y : 0.671197
z : -3.41E-7
Landmark #1:
x : 0.634599
y : 0.536441
z : -0.06984
... (21 landmarks for a hand)
WorldLandmarks:
Landmark #0:
x : 0.067485
y : 0.031084
z : 0.055223
Landmark #1:
x : 0.063209
y : -0.00382
z : 0.020920
... (21 world landmarks for a hand)
As imagens a seguir mostram uma visualização da saída da tarefa:
Para uma implementação mais completa da criação de uma tarefa do Gesture Recognizer, consulte o exemplo.