

MediaPipe Pose Landmarker टास्क की मदद से, किसी इमेज या वीडियो में मानव शरीर के लैंडमार्क का पता लगाया जा सकता है. इस टास्क का इस्तेमाल करके, शरीर की मुख्य जगहों की पहचान की जा सकती है, मुद्रा का विश्लेषण किया जा सकता है, और गतिविधियों को अलग-अलग कैटगरी में बांटा जा सकता है. यह टास्क, मशीन लर्निंग (एमएल) मॉडल का इस्तेमाल करता है, जो एक इमेज या वीडियो के साथ काम करते हैं. यह टास्क, इमेज के निर्देशांक और दुनिया के थ्री-डाइमेंशनल निर्देशांक में, बॉडी पॉज़ के लैंडमार्क दिखाता है.
शुरू करें
अपने टारगेट प्लैटफ़ॉर्म के लिए, लागू करने की गाइड का पालन करके, इस टास्क का इस्तेमाल शुरू करें. प्लैटफ़ॉर्म के हिसाब से बनी इन गाइड में, इस टास्क को लागू करने का बुनियादी तरीका बताया गया है. इनमें सुझाया गया मॉडल और सुझाए गए कॉन्फ़िगरेशन विकल्पों के साथ कोड का उदाहरण भी शामिल है:
- Android - कोड का उदाहरण - गाइड
- Python - कोड का उदाहरण - गाइड
- वेब - कोड का उदाहरण - गाइड
टास्क की जानकारी
इस सेक्शन में, इस टास्क की सुविधाओं, इनपुट, आउटपुट, और कॉन्फ़िगरेशन के विकल्पों के बारे में बताया गया है.
सुविधाएं
- इनपुट इमेज प्रोसेसिंग - प्रोसेसिंग में इमेज को घुमाना, उसका साइज़ बदलना, सामान्य करना, और कलर स्पेस कन्वर्ज़न शामिल है.
- स्कोर थ्रेशोल्ड - अनुमान के स्कोर के आधार पर नतीजे फ़िल्टर करें.
| टास्क के इनपुट | टास्क के आउटपुट |
|---|---|
पोज़ लैंडमार्कर, इनमें से किसी एक डेटा टाइप का इनपुट स्वीकार करता है:
|
पोज़ लैंडमार्कर ये नतीजे दिखाता है:
|
कॉन्फ़िगरेशन के विकल्प
इस टास्क के लिए, कॉन्फ़िगरेशन के ये विकल्प उपलब्ध हैं:
| विकल्प का नाम | ब्यौरा | वैल्यू की रेंज | डिफ़ॉल्ट मान |
|---|---|---|---|
running_mode |
टास्क के लिए रनिंग मोड सेट करता है. इसके तीन मोड हैं: IMAGE: एक इमेज इनपुट के लिए मोड. वीडियो: किसी वीडियो के डिकोड किए गए फ़्रेम के लिए मोड. LIVE_STREAM: कैमरे से मिले इनपुट डेटा की लाइव स्ट्रीम के लिए मोड. इस मोड में, नतीजे असींक्रोनस तरीके से पाने के लिए, एक listener सेट अप करने के लिए, resultListener को कॉल करना होगा. |
{IMAGE, VIDEO, LIVE_STREAM} |
IMAGE |
num_poses |
पोज़ लैंडमार्कर की मदद से, ज़्यादा से ज़्यादा कितने पोज़ का पता लगाया जा सकता है. | Integer > 0 |
1 |
min_pose_detection_confidence |
पोज़ का पता लगाने के लिए, कम से कम इतना कॉन्फ़िडेंस स्कोर होना चाहिए. | Float [0.0,1.0] |
0.5 |
min_pose_presence_confidence |
पोज़ लैंडमार्क की पहचान करने की सुविधा में, पोज़ की मौजूदगी के कम से कम कॉन्फ़िडेंस स्कोर का मतलब है. | Float [0.0,1.0] |
0.5 |
min_tracking_confidence |
पोज़ ट्रैकिंग के लिए कम से कम कॉन्फ़िडेंस स्कोर, जिसे सफल माना जाता है. | Float [0.0,1.0] |
0.5 |
output_segmentation_masks |
पोज़ लैंडमार्कर, पहचाने गए पोज़ के लिए सेगमेंटेशन मास्क दिखाता है या नहीं. | Boolean |
False |
result_callback |
जब पोज़ लैंडमार्कर लाइव स्ट्रीम मोड में हो, तब लैंडमार्कर के नतीजे पाने के लिए रिज़ल्ट लिसनर को असिंक्रोनस तरीके से सेट करता है.
इसका इस्तेमाल सिर्फ़ तब किया जा सकता है, जब रनिंग मोड को LIVE_STREAM पर सेट किया गया हो |
ResultListener |
N/A |
मॉडल
पोज़ लैंडमार्कर, पोज़ के लैंडमार्क का अनुमान लगाने के लिए मॉडल की सीरीज़ का इस्तेमाल करता है. पहला मॉडल, इमेज फ़्रेम में इंसानों की मौजूदगी का पता लगाता है और दूसरा मॉडल, शरीर पर मौजूद लैंडमार्क की जगहों का पता लगाता है.
यहां दिए गए मॉडल, डाउनलोड किए जा सकने वाले मॉडल बंडल में एक साथ पैकेज किए गए हैं:
- पोज़ का पता लगाने वाला मॉडल: यह कुछ खास पोज़ के लैंडमार्क की मदद से, शरीर की मौजूदगी का पता लगाता है.
- पोज़ लैंडमार्कर मॉडल: पोज़ की पूरी मैपिंग जोड़ता है. मॉडल, 33 थ्री-डाइमेंशनल पोज़ लैंडमार्क का अनुमान दिखाता है.
यह बंडल, MobileNetV2 जैसे कॉन्वोल्यूशनल न्यूरल नेटवर्क का इस्तेमाल करता है. साथ ही, इसे डिवाइस पर रीयल-टाइम फ़िटनेस ऐप्लिकेशन के लिए ऑप्टिमाइज़ किया गया है. BlazePose मॉडल का यह वैरिएंट, GHUM का इस्तेमाल करता है. यह एक 3D मॉडलिंग पाइपलाइन है, जो किसी व्यक्ति की इमेज या वीडियो में, उसके शरीर के 3D पोज़ का अनुमान लगाती है.
| मॉडल बंडल | इनपुट का आकार | डेटा टाइप | मॉडल कार्ड | वर्शन |
|---|---|---|---|---|
| पोज़ लैंडमार्कर (लाइट) | पोज़ डिटेक्टर: 224 x 224 x 3 पोज़ लैंडमार्कर: 256 x 256 x 3 |
फ़्लोट 16 | जानकारी | हाल ही के अपडेट |
| पोज़ लैंडमार्कर (पूरा) | पोज़ डिटेक्टर: 224 x 224 x 3 पोज़ लैंडमार्कर: 256 x 256 x 3 |
फ़्लोट 16 | जानकारी | हाल ही के अपडेट |
| पोज़ लैंडमार्कर (ज़्यादा मेमोरी का इस्तेमाल करता है) | पोज़ डिटेक्टर: 224 x 224 x 3 पोज़ लैंडमार्कर: 256 x 256 x 3 |
फ़्लोट 16 | जानकारी | हाल ही के अपडेट |
पोज़ लैंडमार्कर मॉडल
पोज़ लैंडमार्क मॉडल, शरीर के 33 लैंडमार्क की जगहों को ट्रैक करता है. इससे, शरीर के इन हिस्सों की अनुमानित जगह का पता चलता है:
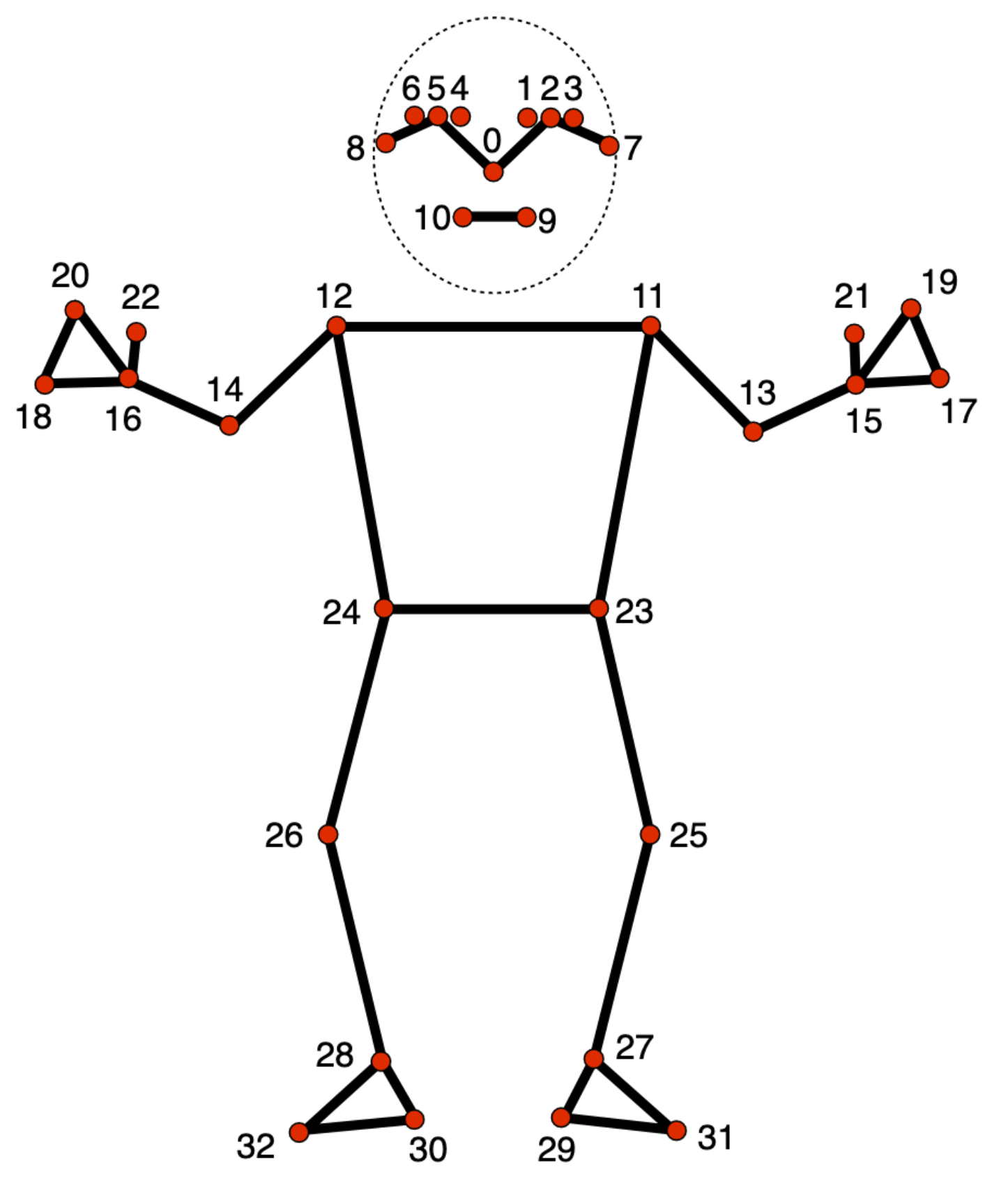
0 - nose
1 - left eye (inner)
2 - left eye
3 - left eye (outer)
4 - right eye (inner)
5 - right eye
6 - right eye (outer)
7 - left ear
8 - right ear
9 - mouth (left)
10 - mouth (right)
11 - left shoulder
12 - right shoulder
13 - left elbow
14 - right elbow
15 - left wrist
16 - right wrist
17 - left pinky
18 - right pinky
19 - left index
20 - right index
21 - left thumb
22 - right thumb
23 - left hip
24 - right hip
25 - left knee
26 - right knee
27 - left ankle
28 - right ankle
29 - left heel
30 - right heel
31 - left foot index
32 - right foot index
मॉडल के आउटपुट में, हर लैंडमार्क के लिए नॉर्मलाइज़ किए गए कोऑर्डिनेट (Landmarks) और वर्ल्ड
कोऑर्डिनेट (WorldLandmarks), दोनों शामिल होते हैं.