

تتيح لك مهمة MediaPipe Pose Landmarker رصد معالم أجسام البشر في صورة أو فيديو. يمكنك استخدام هذه المهمة لتحديد مواضع الجسم الرئيسية وتحليل الوضع و تصنيف الحركات. تستخدِم هذه المهمة نماذج تعلُّم الآلة التي تعمل مع الصور أو الفيديوهات الفردية. تُخرج المهمة معالم وضع الجسم في إحداثيات الصورة وفي إحداثيات العالم الثلاثية الأبعاد.
البدء
ابدأ استخدام هذه المهمة باتّباع دليل التنفيذ المخصّص للمنصّة المستهدَفة. ترشدك هذه الأدلة الخاصة بالنظام الأساسي إلى تنفيذ أساسي لهذه المهمة، بما في ذلك نموذج مقترَح ومثال على الرمز المبرمَج مع خيارات الإعداد المقترَحة:
- Android - مثال على الرمز البرمجي - دليل
- Python - مثال على الرمز البرمجي - الدليل
- الويب - مثال على الرمز البرمجي - الدليل
تفاصيل المهمة
يصف هذا القسم ميزات هذه المهمة ومدخلاتها ومخرجاتها وخيارات الضبط.
الميزات
- معالجة الصور المُدخلة: تشمل المعالجة تدوير الصور وتغيير حجمها وتسويتها وتحويل مساحة الألوان.
- الحدّ الأدنى للنتيجة: فلترة النتائج استنادًا إلى نتائج التوقّعات
| مدخلات المهام | نتائج المهام |
|---|---|
يقبل عنصر وضع المَعلمات أحد أنواع البيانات التالية:
|
يعرض عنصر "مُحدِّد معالم الوضع" النتائج التالية:
|
خيارات الإعدادات
تتضمّن هذه المهمة خيارات الضبط التالية:
| اسم الخيار | الوصف | نطاق القيمة | القيمة التلقائية |
|---|---|---|---|
running_mode |
لضبط وضع التشغيل للمهمة هناك ثلاثة
أوضاع: IMAGE: وضع الإدخالات باستخدام صورة واحدة. VIDEO: وضع الإطارات التي تم فك ترميزها في الفيديو LIVE_STREAM: وضع البث المباشر لبيانات الإدخال ، مثل بيانات الكاميرا في هذا الوضع، يجب استدعاء resultListener لإعداد مستمع لتلقّي النتائج بشكل غير متزامن. |
{IMAGE, VIDEO, LIVE_STREAM} |
IMAGE |
num_poses |
الحد الأقصى لعدد الوضعيات التي يمكن رصدها من خلال أداة وضع علامات على العناصر | Integer > 0 |
1 |
min_pose_detection_confidence |
الحد الأدنى لنتيجة الثقة ليعتبر رصد الوضعان ناجحًا | Float [0.0,1.0] |
0.5 |
min_pose_presence_confidence |
الحد الأدنى لنتيجة الثقة في توفّر الوضع في عملية رصد معالم الوضع | Float [0.0,1.0] |
0.5 |
min_tracking_confidence |
الحد الأدنى لنتيجة الثقة لتتبُّع الوضع ليكون ناجحاً | Float [0.0,1.0] |
0.5 |
output_segmentation_masks |
ما إذا كان عنصر وضع المَعلمات يُخرج قناعًا لتقسيم العناصر للوضع الذي تم رصده | Boolean |
False |
result_callback |
يضبط مستمع النتائج لتلقّي نتائج علامة المَعلمة
بشكل غير متزامن عندما تكون علامة مَعلمة الوضع في وضع البث المباشر.
لا يمكن استخدامها إلا عند ضبط وضع التشغيل على LIVE_STREAM |
ResultListener |
N/A |
النماذج
يستخدم عنصر "وضع علامات على معالم الوضع" سلسلة من النماذج لتوقع معالم الوضع. يرصد النموذج الأول وجود أجسام بشرية في إطار الصورة، ويحدِّد النموذج الثاني مواقع المعالم على الأجسام.
يتم تجميع النماذج التالية معًا في حِزمة نماذج قابلة للتنزيل:
- نموذج رصد الوضع: يرصد وجود الأجسام من خلال رصد بعض معالم الوضع المهمة.
- نموذج علامة موضع الجسم: يضيف ربطًا كاملاً للوضع. يُخرج النموذج تقديرًا لـ 33 مَعلمة ثلاثية الأبعاد لشكل الجسم.
تستخدِم هذه الحِزمة شبكة عصبية تلافعية تشبه MobileNetV2، وهي محسَّنة لتطبيقات اللياقة البدنية في الوقت الفعلي على الجهاز. يستخدم هذا الصيغة من نموذج BlazePose GHUM، وهو مسار نموذجي لتصميم أشكال ثلاثية الأبعاد للأشخاص، لتقدير وضع الجسم الكامل في ثلاثية الأبعاد لأحد الأشخاص في الصور أو الفيديوهات.
| حِزمة النماذج | شكل الإدخال | نوع البيانات | بطاقات النماذج | الإصدارات |
|---|---|---|---|---|
| أداة وضع علامات على معالم الجسم (إصدار خفيف) | أداة رصد الوضع: 224 x 224 x 3 أداة وضع علامات على معالم الوضع: 256 x 256 x 3 |
float 16 | info | أحدث الإصدارات |
| علامة موضع الجسم (كاملة) | أداة رصد الوضع: 224 x 224 x 3 أداة وضع علامات على معالم الوضع: 256 x 256 x 3 |
float 16 | info | أحدث الإصدارات |
| أداة وضع علامات على معالم الجسم (كثيفة) | أداة رصد الوضع: 224 x 224 x 3 أداة وضع علامات على معالم الوضع: 256 x 256 x 3 |
float 16 | info | أحدث المحتوى |
نموذج علامة موضع الوضعية
يتتبّع نموذج علامة موضع الجسم 33 موقعًا لمعالم الجسم، ما يمثّل الموقع التقريبي لأجزاء الجسم التالية:
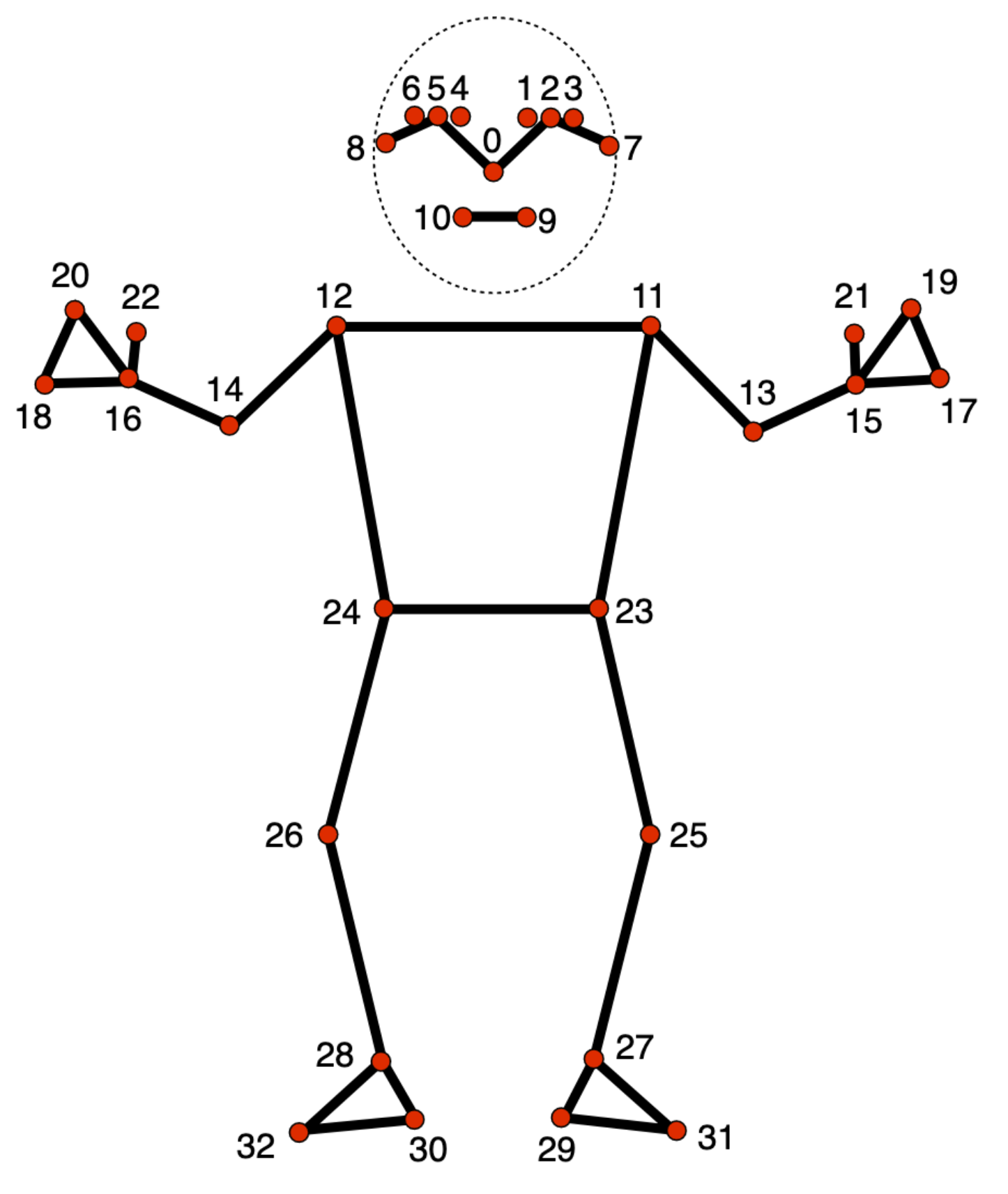
0 - nose
1 - left eye (inner)
2 - left eye
3 - left eye (outer)
4 - right eye (inner)
5 - right eye
6 - right eye (outer)
7 - left ear
8 - right ear
9 - mouth (left)
10 - mouth (right)
11 - left shoulder
12 - right shoulder
13 - left elbow
14 - right elbow
15 - left wrist
16 - right wrist
17 - left pinky
18 - right pinky
19 - left index
20 - right index
21 - left thumb
22 - right thumb
23 - left hip
24 - right hip
25 - left knee
26 - right knee
27 - left ankle
28 - right ankle
29 - left heel
30 - right heel
31 - left foot index
32 - right foot index
تحتوي مخرجات النموذج على كلّ من الإحداثيات العادية (Landmarks) وإحداثيات
الموقع الجغرافي (WorldLandmarks) لكلّ معلم.