音频理解
Gemini 可以分析音频输入并生成文本回答。
Python
from google import genai
client = genai.Client()
myfile = client.files.upload(file="path/to/sample.mp3")
response = client.models.generate_content(
model="gemini-3.5-flash", contents=["Describe this audio clip", myfile]
)
print(response.text)
JavaScript
import {
GoogleGenAI,
createUserContent,
createPartFromUri,
} from "@google/genai";
const ai = new GoogleGenAI({});
async function main() {
const myfile = await ai.files.upload({
file: "path/to/sample.mp3",
config: { mimeType: "audio/mp3" },
});
const response = await ai.models.generateContent({
model: "gemini-3.5-flash",
contents: createUserContent([
createPartFromUri(myfile.uri, myfile.mimeType),
"Describe this audio clip",
]),
});
console.log(response.text);
}
await main();
Go
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
localAudioPath := "/path/to/sample.mp3"
uploadedFile, _ := client.Files.UploadFromPath(
ctx,
localAudioPath,
nil,
)
parts := []*genai.Part{
genai.NewPartFromText("Describe this audio clip"),
genai.NewPartFromURI(uploadedFile.URI, uploadedFile.MIMEType),
}
contents := []*genai.Content{
genai.NewContentFromParts(parts, genai.RoleUser),
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-3.5-flash",
contents,
nil,
)
fmt.Println(result.Text())
}
REST
AUDIO_PATH="path/to/sample.mp3"
MIME_TYPE=$(file -b --mime-type "${AUDIO_PATH}")
NUM_BYTES=$(wc -c < "${AUDIO_PATH}")
DISPLAY_NAME=AUDIO
tmp_header_file=upload-header.tmp
# Initial resumable request defining metadata.
# The upload url is in the response headers dump them to a file.
curl "https://generativelanguage.googleapis.com/upload/v1beta/files" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-D upload-header.tmp \
-H "X-Goog-Upload-Protocol: resumable" \
-H "X-Goog-Upload-Command: start" \
-H "X-Goog-Upload-Header-Content-Length: ${NUM_BYTES}" \
-H "X-Goog-Upload-Header-Content-Type: ${MIME_TYPE}" \
-H "Content-Type: application/json" \
-d "{'file': {'display_name': '${DISPLAY_NAME}'}}" 2> /dev/null
upload_url=$(grep -i "x-goog-upload-url: " "${tmp_header_file}" | cut -d" " -f2 | tr -d "\r")
rm "${tmp_header_file}"
# Upload the actual bytes.
curl "${upload_url}" \
-H "Content-Length: ${NUM_BYTES}" \
-H "X-Goog-Upload-Offset: 0" \
-H "X-Goog-Upload-Command: upload, finalize" \
--data-binary "@${AUDIO_PATH}" 2> /dev/null > file_info.json
file_uri=$(jq ".file.uri" file_info.json)
echo file_uri=$file_uri
# Now generate content using that file
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.5-flash:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts":[
{"text": "Describe this audio clip"},
{"file_data":{"mime_type": "${MIME_TYPE}", "file_uri": '$file_uri'}}]
}]
}' 2> /dev/null > response.json
cat response.json
echo
jq ".candidates[].content.parts[].text" response.json
概览
Gemini 可以分析和理解音频输入,并生成文本回复,从而实现以下用例:
- 描述、总结音频内容或回答与音频内容相关的问题。
- 提供音频的转写和翻译(语音转文字)。
- 检测语音和音乐中的情绪。
- 分析音频的特定片段,并提供时间戳。
目前,Gemini API 不支持实时转写用例。 如需进行实时语音和视频互动,请参阅 Live API。 如需使用支持实时转写的专用语音转文字模型,请使用 Google Cloud Speech-to-Text API。
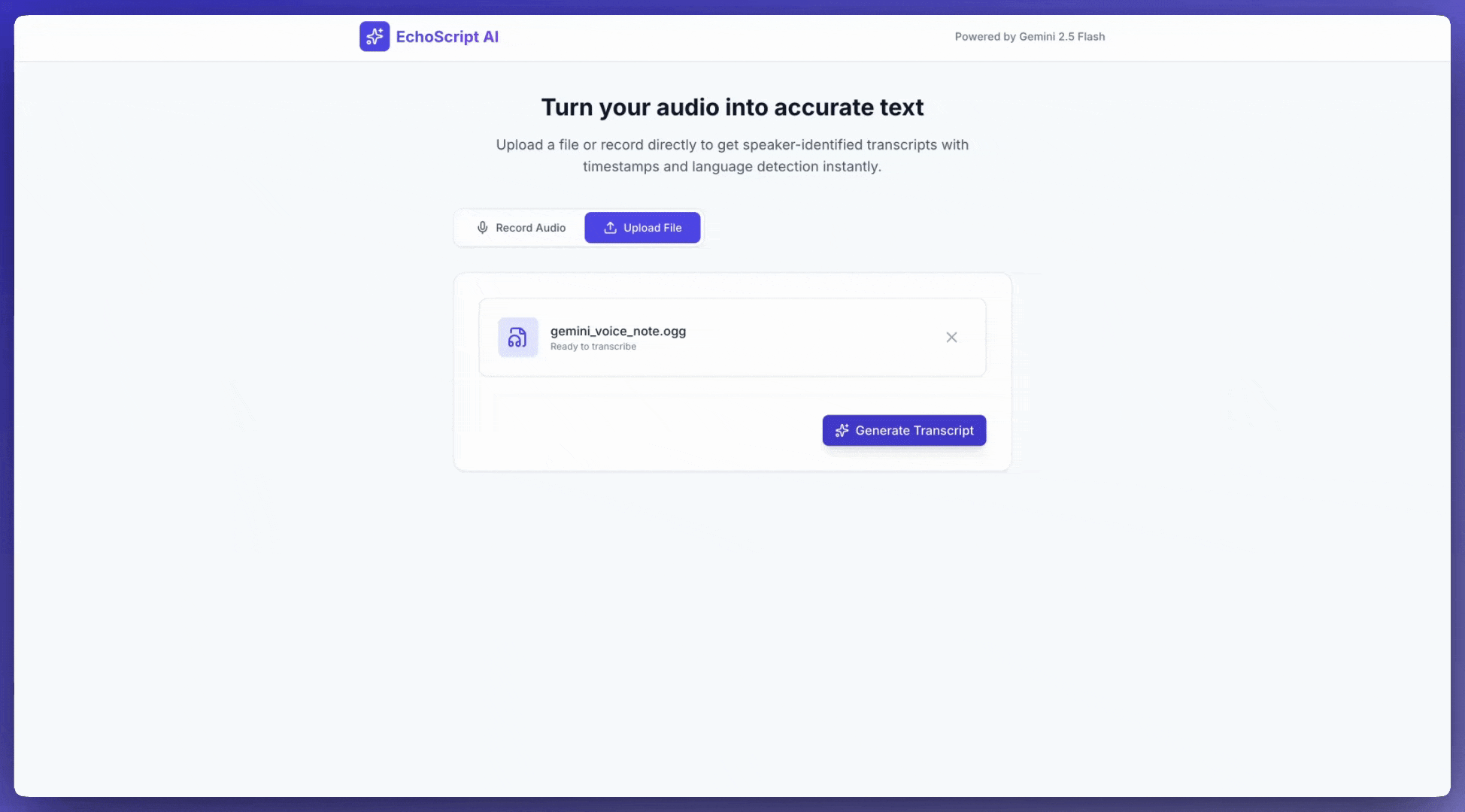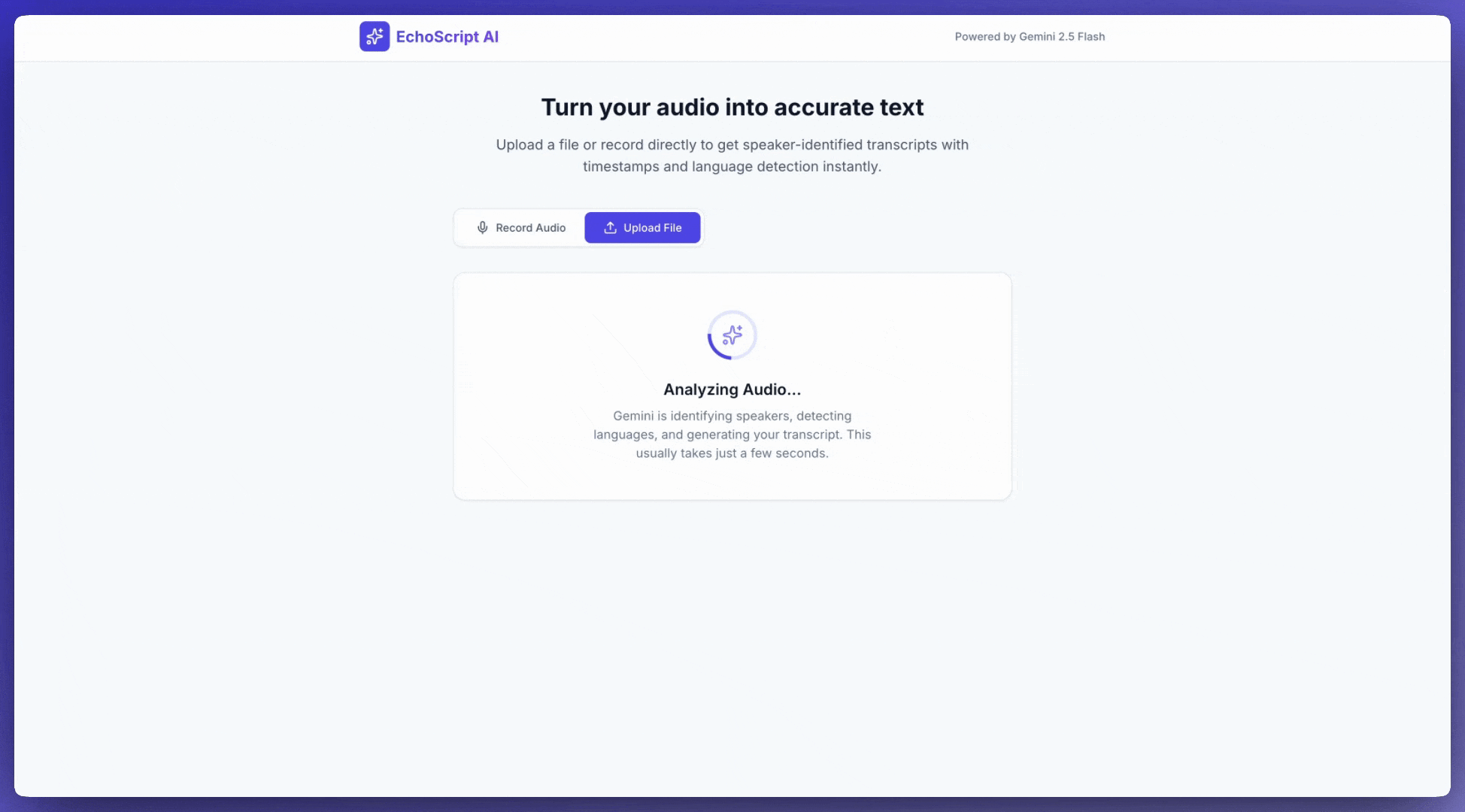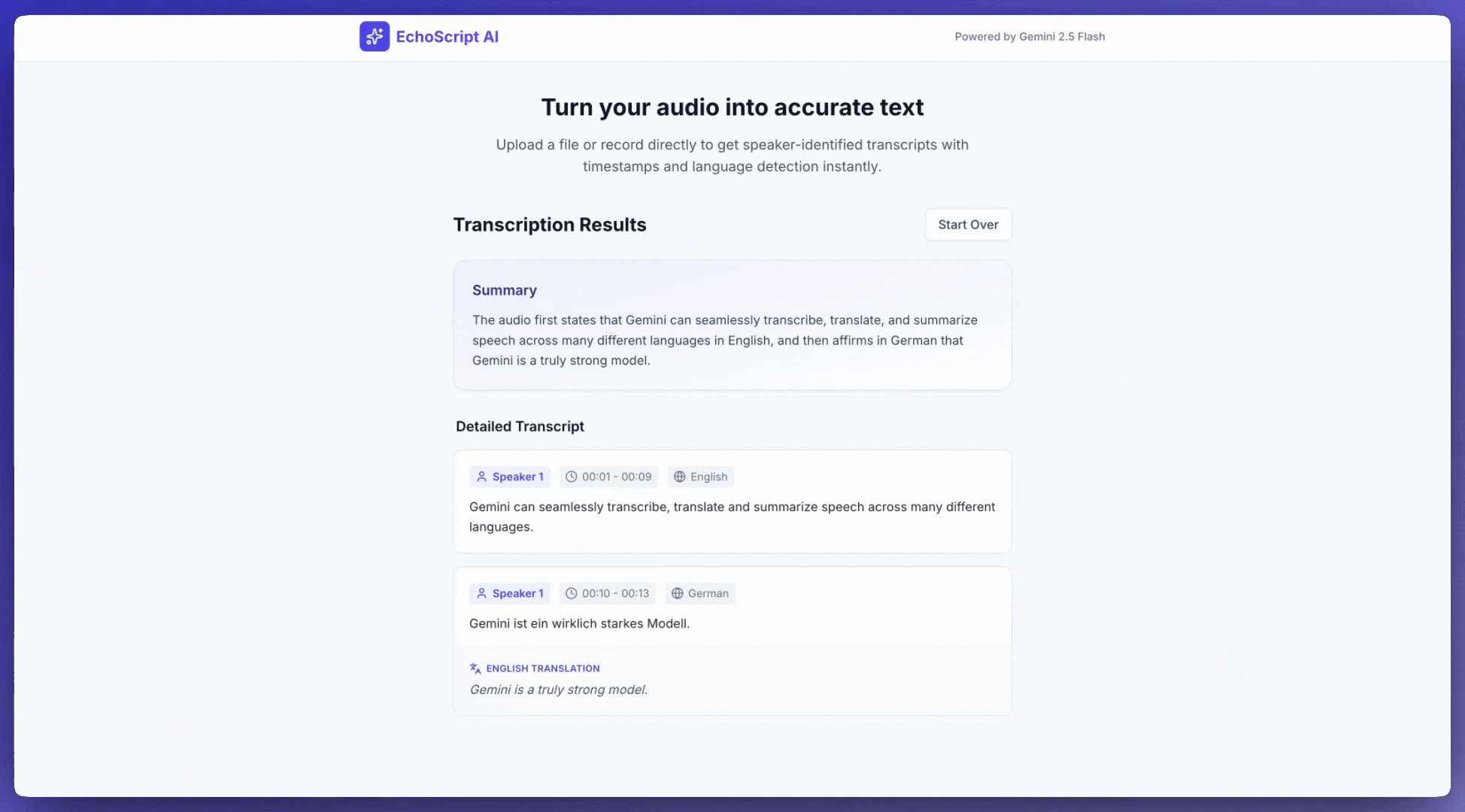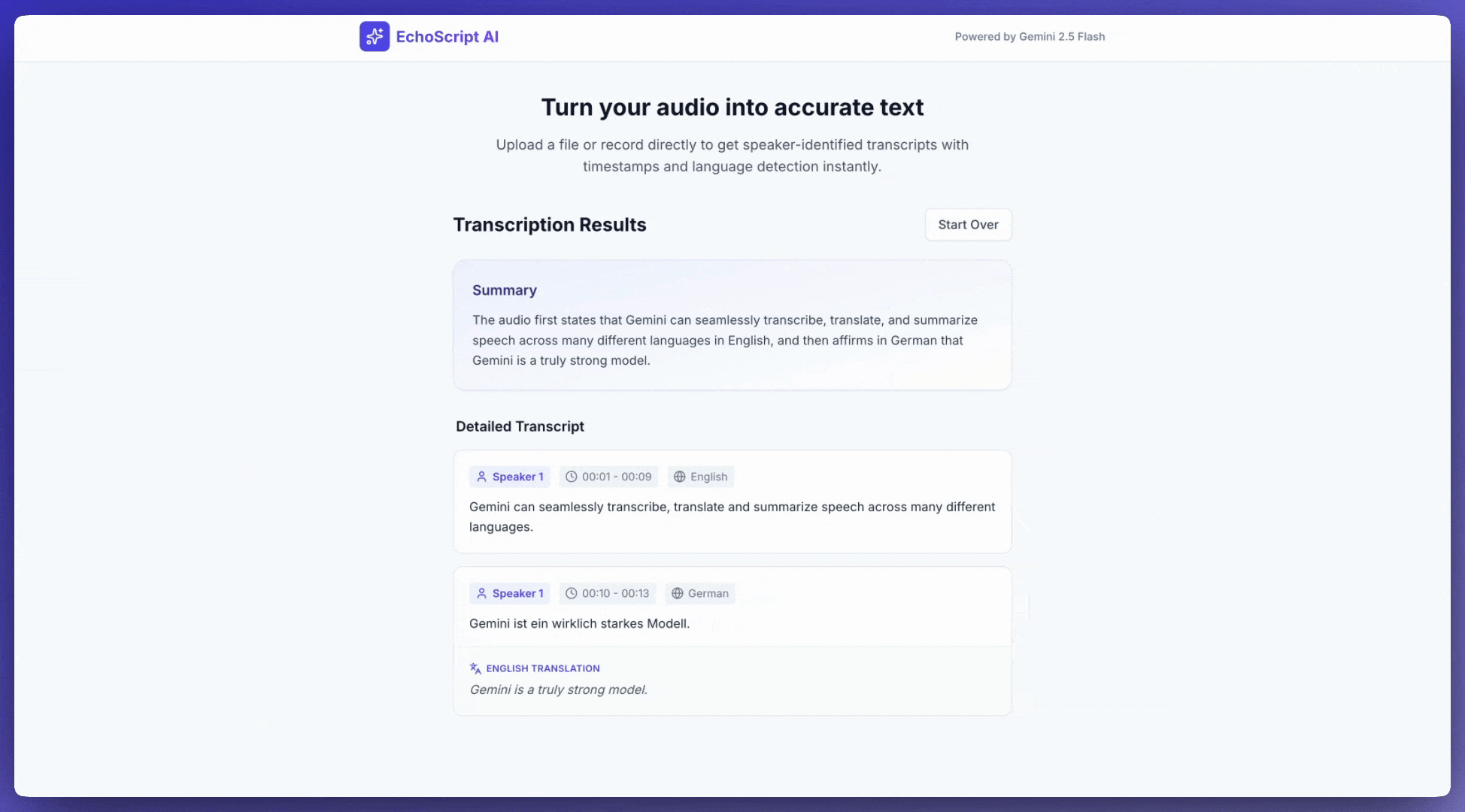
将语音转写为文字
此示例应用展示了如何提示 Gemini API 转写、翻译和总结语音,包括使用结构化输出的时间戳和情绪检测。
Python
from google import genai
from google.genai import types
client = genai.Client()
YOUTUBE_URL = "https://www.youtube.com/watch?v=ku-N-eS1lgM"
def main():
prompt = """
Process the audio file and generate a detailed transcription.
Requirements:
1. Provide accurate timestamps for each segment (Format: MM:SS).
2. Detect the primary language of each segment.
3. If the segment is in a language different than English, also provide the English translation.
4. Identify the primary emotion of the speaker in this segment. You MUST choose exactly one of the following: Happy, Sad, Angry, Neutral.
5. Provide a brief summary of the entire audio at the beginning.
"""
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=[
types.Content(
parts=[
types.Part(
file_data=types.FileData(
file_uri=YOUTUBE_URL
)
),
types.Part(
text=prompt
)
]
)
],
config=types.GenerateContentConfig(
response_format={"text": {"mime_type": "application/json"}},
response_schema=types.Schema(
type=types.Type.OBJECT,
properties={
"summary": types.Schema(
type=types.Type.STRING,
description="A concise summary of the audio content.",
),
"segments": types.Schema(
type=types.Type.ARRAY,
description="List of transcribed segments with timestamp.",
items=types.Schema(
type=types.Type.OBJECT,
properties={
"timestamp": types.Schema(type=types.Type.STRING),
"content": types.Schema(type=types.Type.STRING),
"language": types.Schema(type=types.Type.STRING),
"language_code": types.Schema(type=types.Type.STRING),
"translation": types.Schema(type=types.Type.STRING),
"emotion": types.Schema(
type=types.Type.STRING,
enum=["happy", "sad", "angry", "neutral"]
),
},
required=["timestamp", "content", "language", "language_code", "emotion"],
),
),
},
required=["summary", "segments"],
),
),
)
print(response.text)
if __name__ == "__main__":
main()
JavaScript
import {
GoogleGenAI,
Type
} from "@google/genai";
const ai = new GoogleGenAI({});
const YOUTUBE_URL = "https://www.youtube.com/watch?v=ku-N-eS1lgM";
async function main() {
const prompt = `
Process the audio file and generate a detailed transcription.
Requirements:
1. Provide accurate timestamps for each segment (Format: MM:SS).
2. Detect the primary language of each segment.
3. If the segment is in a language different than English, also provide the English translation.
4. Identify the primary emotion of the speaker in this segment. You MUST choose exactly one of the following: Happy, Sad, Angry, Neutral.
5. Provide a brief summary of the entire audio at the beginning.
`;
const Emotion = {
Happy: 'happy',
Sad: 'sad',
Angry: 'angry',
Neutral: 'neutral'
};
const response = await ai.models.generateContent({
model: "gemini-3.5-flash",
contents: {
parts: [
{
fileData: {
fileUri: YOUTUBE_URL,
},
},
{
text: prompt,
},
],
},
config: {
responseFormat: { text: { mimeType: "application/json" } },
responseSchema: {
type: Type.OBJECT,
properties: {
summary: {
type: Type.STRING,
description: "A concise summary of the audio content.",
},
segments: {
type: Type.ARRAY,
description: "List of transcribed segments with timestamp.",
items: {
type: Type.OBJECT,
properties: {
timestamp: { type: Type.STRING },
content: { type: Type.STRING },
language: { type: Type.STRING },
language_code: { type: Type.STRING },
translation: { type: Type.STRING },
emotion: {
type: Type.STRING,
enum: Object.values(Emotion)
},
},
required: ["timestamp", "content", "language", "language_code", "emotion"],
},
},
},
required: ["summary", "segments"],
},
},
});
const json = JSON.parse(response.text);
console.log(json);
}
await main();
REST
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.5-flash:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [
{
"parts": [
{
"file_data": {
"file_uri": "https://www.youtube.com/watch?v=ku-N-eS1lgM",
"mime_type": "video/mp4"
}
},
{
"text": "Process the audio file and generate a detailed transcription.\n\nRequirements:\n1. Provide accurate timestamps for each segment (Format: MM:SS).\n2. Detect the primary language of each segment.\n3. If the segment is in a language different than English, also provide the English translation.\n4. Identify the primary emotion of the speaker in this segment. You MUST choose exactly one of the following: Happy, Sad, Angry, Neutral.\n5. Provide a brief summary of the entire audio at the beginning."
}
]
}
],
"generation_config": {
"response_format": {"text": {"mime_type": "application/json"}},
"response_schema": {
"type": "OBJECT",
"properties": {
"summary": {
"type": "STRING",
"description": "A concise summary of the audio content."
},
"segments": {
"type": "ARRAY",
"description": "List of transcribed segments with timestamp.",
"items": {
"type": "OBJECT",
"properties": {
"timestamp": { "type": "STRING" },
"content": { "type": "STRING" },
"language": { "type": "STRING" },
"language_code": { "type": "STRING" },
"translation": { "type": "STRING" },
"emotion": {
"type": "STRING",
"enum": ["happy", "sad", "angry", "neutral"]
}
},
"required": ["timestamp", "content", "language", "language_code", "emotion"]
}
}
},
"required": ["summary", "segments"]
}
}
}' 2> /dev/null > response.json
cat response.json
echo
jq ".candidates[].content.parts[].text" response.json
您只需点击一个按钮,即可提示 AI Studio Build 创建一个与此转写应用示例类似的应用。
输入音频
您可以通过以下方式向 Gemini 提供音频数据:
如需了解其他文件输入方法,请参阅文件输入方法指南。
上传音频文件
您可以使用 Files API 上传音频文件。 当总请求大小(包括文件、文本提示、系统指令等)超过 20 MB 时,请务必使用 Files API。
以下代码会上传音频文件,然后在对 generateContent 的调用中使用该文件。
Python
from google import genai
client = genai.Client()
myfile = client.files.upload(file="path/to/sample.mp3")
response = client.models.generate_content(
model="gemini-3.5-flash", contents=["Describe this audio clip", myfile]
)
print(response.text)
JavaScript
import {
GoogleGenAI,
createUserContent,
createPartFromUri,
} from "@google/genai";
const ai = new GoogleGenAI({});
async function main() {
const myfile = await ai.files.upload({
file: "path/to/sample.mp3",
config: { mimeType: "audio/mp3" },
});
const response = await ai.models.generateContent({
model: "gemini-3.5-flash",
contents: createUserContent([
createPartFromUri(myfile.uri, myfile.mimeType),
"Describe this audio clip",
]),
});
console.log(response.text);
}
await main();
Go
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
localAudioPath := "/path/to/sample.mp3"
uploadedFile, _ := client.Files.UploadFromPath(
ctx,
localAudioPath,
nil,
)
parts := []*genai.Part{
genai.NewPartFromText("Describe this audio clip"),
genai.NewPartFromURI(uploadedFile.URI, uploadedFile.MIMEType),
}
contents := []*genai.Content{
genai.NewContentFromParts(parts, genai.RoleUser),
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-3.5-flash",
contents,
nil,
)
fmt.Println(result.Text())
}
REST
AUDIO_PATH="path/to/sample.mp3"
MIME_TYPE=$(file -b --mime-type "${AUDIO_PATH}")
NUM_BYTES=$(wc -c < "${AUDIO_PATH}")
DISPLAY_NAME=AUDIO
tmp_header_file=upload-header.tmp
# Initial resumable request defining metadata.
# The upload url is in the response headers dump them to a file.
curl "https://generativelanguage.googleapis.com/upload/v1beta/files" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-D upload-header.tmp \
-H "X-Goog-Upload-Protocol: resumable" \
-H "X-Goog-Upload-Command: start" \
-H "X-Goog-Upload-Header-Content-Length: ${NUM_BYTES}" \
-H "X-Goog-Upload-Header-Content-Type: ${MIME_TYPE}" \
-H "Content-Type: application/json" \
-d "{'file': {'display_name': '${DISPLAY_NAME}'}}" 2> /dev/null
upload_url=$(grep -i "x-goog-upload-url: " "${tmp_header_file}" | cut -d" " -f2 | tr -d "\r")
rm "${tmp_header_file}"
# Upload the actual bytes.
curl "${upload_url}" \
-H "Content-Length: ${NUM_BYTES}" \
-H "X-Goog-Upload-Offset: 0" \
-H "X-Goog-Upload-Command: upload, finalize" \
--data-binary "@${AUDIO_PATH}" 2> /dev/null > file_info.json
file_uri=$(jq ".file.uri" file_info.json)
echo file_uri=$file_uri
# Now generate content using that file
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.5-flash:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts":[
{"text": "Describe this audio clip"},
{"file_data":{"mime_type": "${MIME_TYPE}", "file_uri": '$file_uri'}}]
}]
}' 2> /dev/null > response.json
cat response.json
echo
jq ".candidates[].content.parts[].text" response.json
如需详细了解如何处理媒体文件,请参阅 Files API。
内嵌传递音频数据
您可以将内嵌音频数据传递给 generateContent,而不是上传音频文件:
Python
from google import genai
from google.genai import types
with open('path/to/small-sample.mp3', 'rb') as f:
audio_bytes = f.read()
client = genai.Client()
response = client.models.generate_content(
model='gemini-3.5-flash',
contents=[
'Describe this audio clip',
types.Part.from_bytes(
data=audio_bytes,
mime_type='audio/mp3',
)
]
)
print(response.text)
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
const ai = new GoogleGenAI({});
const base64AudioFile = fs.readFileSync("path/to/small-sample.mp3", {
encoding: "base64",
});
const contents = [
{ text: "Please summarize the audio." },
{
inlineData: {
mimeType: "audio/mp3",
data: base64AudioFile,
},
},
];
const response = await ai.models.generateContent({
model: "gemini-3.5-flash",
contents: contents,
});
console.log(response.text);
Go
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
audioBytes, _ := os.ReadFile("/path/to/small-sample.mp3")
parts := []*genai.Part{
genai.NewPartFromText("Describe this audio clip"),
&genai.Part{
InlineData: &genai.Blob{
MIMEType: "audio/mp3",
Data: audioBytes,
},
},
}
contents := []*genai.Content{
genai.NewContentFromParts(parts, genai.RoleUser),
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-3.5-flash",
contents,
nil,
)
fmt.Println(result.Text())
}
关于内嵌音频数据,请注意以下几点:
- 请求大小上限为 20 MB,其中包括文本提示、系统指令和内嵌提供的文件。如果文件的大小会导致总请求大小超过 20 MB,请使用 Files API 上传音频文件以供请求使用。
- 如果您要多次使用某个音频样本,最好上传音频文件。
获取转写内容
如需获取音频数据的转写内容,只需在提示中提出要求即可:
Python
from google import genai
client = genai.Client()
myfile = client.files.upload(file='path/to/sample.mp3')
prompt = 'Generate a transcript of the speech.'
response = client.models.generate_content(
model='gemini-3.5-flash',
contents=[prompt, myfile]
)
print(response.text)
JavaScript
import {
GoogleGenAI,
createUserContent,
createPartFromUri,
} from "@google/genai";
const ai = new GoogleGenAI({});
const myfile = await ai.files.upload({
file: "path/to/sample.mp3",
config: { mimeType: "audio/mpeg" },
});
const result = await ai.models.generateContent({
model: "gemini-3.5-flash",
contents: createUserContent([
createPartFromUri(myfile.uri, myfile.mimeType),
"Generate a transcript of the speech.",
]),
});
console.log("result.text=", result.text);
Go
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
localAudioPath := "/path/to/sample.mp3"
uploadedFile, _ := client.Files.UploadFromPath(
ctx,
localAudioPath,
nil,
)
parts := []*genai.Part{
genai.NewPartFromText("Generate a transcript of the speech."),
genai.NewPartFromURI(uploadedFile.URI, uploadedFile.MIMEType),
}
contents := []*genai.Content{
genai.NewContentFromParts(parts, genai.RoleUser),
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-3.5-flash",
contents,
nil,
)
fmt.Println(result.Text())
}
参考时间戳
您可以使用 MM:SS 格式的时间戳来引用音频文件的特定部分。例如,以下提示请求生成一份包含以下内容的转写
- 从文件开头 2 分 30 秒处开始。
结束时间为从文件开头算起的 3 分 29 秒。
Python
# Create a prompt containing timestamps.
prompt = "Provide a transcript of the speech from 02:30 to 03:29."
JavaScript
// Create a prompt containing timestamps.
const prompt = "Provide a transcript of the speech from 02:30 to 03:29."
Go
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
localAudioPath := "/path/to/sample.mp3"
uploadedFile, _ := client.Files.UploadFromPath(
ctx,
localAudioPath,
nil,
)
parts := []*genai.Part{
genai.NewPartFromText("Provide a transcript of the speech " +
"between the timestamps 02:30 and 03:29."),
genai.NewPartFromURI(uploadedFile.URI, uploadedFile.MIMEType),
}
contents := []*genai.Content{
genai.NewContentFromParts(parts, genai.RoleUser),
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-3.5-flash",
contents,
nil,
)
fmt.Println(result.Text())
}
统计 token 数量
调用 countTokens 方法可获取音频文件中的 token 数量。例如:
Python
from google import genai
client = genai.Client()
response = client.models.count_tokens(
model='gemini-3.5-flash',
contents=[myfile]
)
print(response)
JavaScript
import {
GoogleGenAI,
createUserContent,
createPartFromUri,
} from "@google/genai";
const ai = new GoogleGenAI({});
const myfile = await ai.files.upload({
file: "path/to/sample.mp3",
config: { mimeType: "audio/mpeg" },
});
const countTokensResponse = await ai.models.countTokens({
model: "gemini-3.5-flash",
contents: createUserContent([
createPartFromUri(myfile.uri, myfile.mimeType),
]),
});
console.log(countTokensResponse.totalTokens);
Go
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
localAudioPath := "/path/to/sample.mp3"
uploadedFile, _ := client.Files.UploadFromPath(
ctx,
localAudioPath,
nil,
)
parts := []*genai.Part{
genai.NewPartFromURI(uploadedFile.URI, uploadedFile.MIMEType),
}
contents := []*genai.Content{
genai.NewContentFromParts(parts, genai.RoleUser),
}
tokens, _ := client.Models.CountTokens(
ctx,
"gemini-3.5-flash",
contents,
nil,
)
fmt.Printf("File %s is %d tokens\n", localAudioPath, tokens.TotalTokens)
}
支持的音频格式
Gemini 支持以下音频格式 MIME 类型:
- WAV -
audio/wav - MP3 -
audio/mp3 - AIFF -
audio/aiff - AAC -
audio/aac - OGG Vorbis -
audio/ogg - FLAC -
audio/flac
有关音频的技术详细信息
- Gemini 将每秒音频表示为 32 个 token;例如,1 分钟的音频表示为 1,920 个 token。
- Gemini 可以“理解”非语音成分,例如鸟鸣声或警报声。
- 单个提示中支持的音频数据时长上限为 9.5 小时。Gemini 不限制单个提示中的音频文件数量;不过,单个提示中所有音频文件的总时长不得超过 9.5 小时。
- Gemini 会将音频文件下采样到 16 Kbps 的数据分辨率。
- 如果音频源包含多个声道,Gemini 会将这些声道合并为一个声道。
后续步骤
本指南介绍了如何根据音频数据生成文本。如需了解详情,请参阅以下资源: