
Rodzina modeli sztucznej inteligencji (AI) Gemini została opracowana z myślą o obsługiwaniu różnych typów danych wejściowych, w tym tekstu, obrazów i dźwięku. Ponieważ modele te mogą obsługiwać więcej niż 1 typ lub tryb danych, nazywamy je modelami multimodalnymi lub określamy jako modele multimodalne.
Z tego przewodnika dowiesz się, jak pracować z plikami multimedialnymi za pomocą interfejsu Files API. Podstawowe operacje są takie same w przypadku plików audio, obrazów, filmów, dokumentów i innych obsługiwanych typów plików.
Wskazówki dotyczące promptów plików znajdziesz w sekcji Wskazówki dotyczące promptów plików.
Prześlij plik
Do przesłania pliku multimedialnego możesz użyć interfejsu Files API. Zawsze używaj interfejsu Files API, gdy łączny rozmiar żądania (w tym pliki, prompt tekstowy, instrukcje systemu itp.) przekracza 20 MB.
Poniższy kod przesyła plik, a potem używa go w wywołaniu funkcji generateContent.
Python
from google import genai
client = genai.Client(api_key="GOOGLE_API_KEY")
myfile = client.files.upload(file="path/to/sample.mp3")
response = client.models.generate_content(
model="gemini-2.0-flash", contents=["Describe this audio clip", myfile]
)
print(response.text)
JavaScript
import {
GoogleGenAI,
createUserContent,
createPartFromUri,
} from "@google/genai";
const ai = new GoogleGenAI({ apiKey: "GOOGLE_API_KEY" });
async function main() {
const myfile = await ai.files.upload({
file: "path/to/sample.mp3",
config: { mimeType: "audio/mpeg" },
});
const response = await ai.models.generateContent({
model: "gemini-2.0-flash",
contents: createUserContent([
createPartFromUri(myfile.uri, myfile.mimeType),
"Describe this audio clip",
]),
});
console.log(response.text);
}
await main();
Przeczytaj
file, err := client.UploadFileFromPath(ctx, "path/to/sample.mp3", nil)
if err != nil {
log.Fatal(err)
}
defer client.DeleteFile(ctx, file.Name)
model := client.GenerativeModel("gemini-2.0-flash")
resp, err := model.GenerateContent(ctx,
genai.FileData{URI: file.URI},
genai.Text("Describe this audio clip"))
if err != nil {
log.Fatal(err)
}
printResponse(resp)
REST
AUDIO_PATH="path/to/sample.mp3"
MIME_TYPE=$(file -b --mime-type "${AUDIO_PATH}")
NUM_BYTES=$(wc -c < "${AUDIO_PATH}")
DISPLAY_NAME=AUDIO
tmp_header_file=upload-header.tmp
# Initial resumable request defining metadata.
# The upload url is in the response headers dump them to a file.
curl "${BASE_URL}/upload/v1beta/files?key=${GOOGLE_API_KEY}" \
-D upload-header.tmp \
-H "X-Goog-Upload-Protocol: resumable" \
-H "X-Goog-Upload-Command: start" \
-H "X-Goog-Upload-Header-Content-Length: ${NUM_BYTES}" \
-H "X-Goog-Upload-Header-Content-Type: ${MIME_TYPE}" \
-H "Content-Type: application/json" \
-d "{'file': {'display_name': '${DISPLAY_NAME}'}}" 2> /dev/null
upload_url=$(grep -i "x-goog-upload-url: " "${tmp_header_file}" | cut -d" " -f2 | tr -d "\r")
rm "${tmp_header_file}"
# Upload the actual bytes.
curl "${upload_url}" \
-H "Content-Length: ${NUM_BYTES}" \
-H "X-Goog-Upload-Offset: 0" \
-H "X-Goog-Upload-Command: upload, finalize" \
--data-binary "@${AUDIO_PATH}" 2> /dev/null > file_info.json
file_uri=$(jq ".file.uri" file_info.json)
echo file_uri=$file_uri
# Now generate content using that file
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-2.0-flash:generateContent?key=$GOOGLE_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts":[
{"text": "Describe this audio clip"},
{"file_data":{"mime_type": "${MIME_TYPE}", "file_uri": '$file_uri'}}]
}]
}' 2> /dev/null > response.json
cat response.json
echo
jq ".candidates[].content.parts[].text" response.json
Pobieranie metadanych pliku
Aby sprawdzić, czy interfejs API poprawnie zapisał przesłany plik, i uzyskać jego metadane, wywołaj funkcję files.get.
Python
myfile = client.files.upload(file='path/to/sample.mp3')
file_name = myfile.name
myfile = client.files.get(name=file_name)
print(myfile)
JavaScript
const myfile = await ai.files.upload({
file: "path/to/sample.mp3",
config: { mimeType: "audio/mpeg" },
});
const fileName = myfile.name;
const fetchedFile = await ai.files.get({ name: fileName });
console.log(fetchedFile);
Przeczytaj
file, err := client.UploadFileFromPath(ctx, "path/to/sample.mp3", nil)
if err != nil {
log.Fatal(err)
}
gotFile, err := client.GetFile(ctx, file.Name)
if err != nil {
log.Fatal(err)
}
fmt.Println("Got file:", gotFile.Name)
REST
# file_info.json was created in the upload example
name=$(jq ".file.name" file_info.json)
# Get the file of interest to check state
curl https://generativelanguage.googleapis.com/v1beta/files/$name > file_info.json
# Print some information about the file you got
name=$(jq ".file.name" file_info.json)
echo name=$name
file_uri=$(jq ".file.uri" file_info.json)
echo file_uri=$file_uri
Lista przesłanych plików
Możesz przesłać wiele plików za pomocą interfejsu Files API. Poniższy kod pobiera listę wszystkich przesłanych plików:
Python
print('My files:')
for f in client.files.list():
print(' ', f.name)
JavaScript
const listResponse = await ai.files.list({ config: { pageSize: 10 } });
for await (const file of listResponse) {
console.log(file.name);
}
Przeczytaj
iter := client.ListFiles(ctx)
for {
ifile, err := iter.Next()
if err == iterator.Done {
break
}
if err != nil {
log.Fatal(err)
}
fmt.Println(ifile.Name)
}
REST
echo "My files: "
curl "https://generativelanguage.googleapis.com/v1beta/files?key=$GOOGLE_API_KEY"
Usuwanie przesłanych plików
Pliki są automatycznie usuwane po 48 godzinach. Możesz też ręcznie usunąć przesłany plik:
Python
myfile = client.files.upload(file='path/to/sample.mp3')
client.files.delete(name=myfile.name)
JavaScript
const myfile = await ai.files.upload({
file: "path/to/sample.mp3",
config: { mimeType: "audio/mpeg" },
});
const fileName = myfile.name;
await ai.files.delete({ name: fileName });
Przeczytaj
file, err := client.UploadFileFromPath(ctx, "path/to/sample.mp3", nil)
if err != nil {
log.Fatal(err)
}
client.DeleteFile(ctx, file.Name)
REST
curl --request "DELETE" https://generativelanguage.googleapis.com/v1beta/files/$name?key=$GOOGLE_API_KEY
Informacje o korzystaniu
Interfejsu Files API możesz używać do przesyłania plików multimedialnych i interakcji z nimi. Interfejs Files API umożliwia przechowywanie do 20 GB plików na projekt, przy czym maksymalny rozmiar pojedynczego pliku to 2 GB. Pliki są przechowywane przez 48 godzin. W tym czasie możesz używać interfejsu API do uzyskiwania metadanych dotyczących plików, ale nie możesz ich pobierać. Interfejs Files API jest dostępny bezpłatnie we wszystkich regionach, w których dostępny jest interfejs Gemini API.
Strategie dotyczące promptów w plikach
W tej sekcji znajdziesz wskazówki i sprawdzone metody dotyczące używania plików multimedialnych w promptach dla interfejsu Gemini API.
Możliwość używania różnych typów danych w promptach daje Ci większą elastyczność w zakresie zadań, które możesz wykonywać za pomocą Gemini API. Możesz na przykład wysłać modelowi zdjęcie pysznego posiłku i poprosić go o napisanie krótkiego bloga na jego temat.
| Prompt | Odpowiedź |
|
Napisz na podstawie tego zdjęcia krótki, angażujący post na bloga. Powinien zawierać opis posiłku na zdjęciu i opowiadać o przygotowaniu posiłku. 
|
Przygotowywanie posiłków to świetny sposób na oszczędność czasu i pieniędzy, a także na zdrowsze odżywianie się. Ten posiłek to świetny przykład zdrowego i smacznego posiłku, który można łatwo przygotować z wyprzedzeniem. Danie składa się z brązowego ryżu, pieczonego warzywa i kurczaka teriyaki. Brązowy ryż to zdrowy i złożony węglowodan, który zapewni Ci długotrwały zapas energii. Pieczone warzywa to świetny sposób na codzienną porcję witamin i minerałów, a kurczak teriyaki to pyszna opcja bogata w białko. To danie jest też bardzo łatwe do przygotowania. Wystarczy ugotować brązowy ryż, upiec warzywa i przygotować kurczaka teriyaki. Po ugotowaniu podziel je na pojemniki na posiłki i włóż do lodówki. Możesz wtedy wziąć pojemnik i iść do pracy w pracowite poranki. Jeśli szukasz zdrowego i smacznego posiłku, który można łatwo przygotować z wyprzedzeniem, ta opcja jest dla Ciebie. Jest on pełen składników odżywczych i smaku, a także zapewni Ci uczucie sytości i zadowolenia. Zdrowe i pyszne przygotowanie posiłków |
Jeśli masz problem z uzyskaniem oczekiwanego wyjścia z promptów, które używają plików multimedialnych, możesz skorzystać z kilku strategii, które pomogą Ci uzyskać pożądane wyniki. W następnych sekcjach znajdziesz wskazówki dotyczące projektowania i rozwiązywania problemów z promptami, które korzystają z danych wejściowych multimodalnych.
Aby ulepszyć prompty multimodalne, postępuj zgodnie z tymi sprawdzonymi metodami:
-
Podstawy projektowania promptów
- Podaj szczegółowe instrukcje: stwórz jasne i zwięzłe instrukcje, które nie będą budzić wątpliwości.
- Dodaj kilka przykładów do promptu: użyj realistycznych przykładów z kilku zdjęć, aby zilustrować, czego chcesz dokonać.
- Podziel zadanie na etapy: podziel skomplikowane zadania na łatwe do wykonania podrzędne cele, aby ułatwić modelowi realizację procesu.
- Określ format wyjściowy: w promptach podaj format wyjściowy, np. markdown, JSON, HTML itp.
- W przypadku promptów z jednym obrazem umieść obraz na początku: Gemini może przetwarzać dane wejściowe w dowolnej kolejności, ale w przypadku promptów zawierających jeden obraz lepiej jest umieścić ten obraz (lub film) przed promptem tekstowym. Jednak w przypadku promptów, które wymagają, aby obrazy były mocno przeplatane tekstem, aby miały sens, użyj dowolnej kolejności, która wydaje Ci się najbardziej naturalna.
-
Rozwiązywanie problemów z promptem multimodalnym
- Jeśli model nie pobiera informacji z odpowiedniej części obrazu: podaj wskazówki dotyczące tego, z których aspektów obrazu chcesz, aby prompt pobierał informacje.
- Jeśli wyniki modelu są zbyt ogólne (nie są odpowiednio dostosowane do obrazu lub filmu): na początku prompta poproś model o opisanie obrazu lub filmu, zanim podasz instrukcje dotyczące zadania, albo poproś model o odniesienie się do tego, co jest na obrazie.
- Aby sprawdzić, która część nie działa: poproś model o opisanie obrazu lub wyjaśnienie jego rozumowania, aby ocenić jego wstępne zrozumienie.
- Jeśli prompt generuje treści halucynogenne: spróbuj zmniejszyć ustawienie temperatury lub poprosić model o krótsze opisy, aby zmniejszyć prawdopodobieństwo ekstrapolowania dodatkowych szczegółów.
- Dostosowywanie parametrów próbkowania: eksperymentuj z różnymi ustawieniami temperatury i wyboru top-k, aby dostosować kreatywność modelu.
Unikaj ogólników w instrukcjach
Prompty są najskuteczniejsze, gdy są jasne i szczegółowe. Jeśli masz na myśli konkretny wynik, lepiej jest uwzględnić to wymaganie w promptach, aby mieć pewność, że uzyskasz oczekiwany wynik.
W przypadku tego zdjęcia tablicy lotniskowej model może wygenerować ogólny opis, jeśli poprosimy go tylko o „opis tego zdjęcia”. Jeśli chcesz, aby model przeanalizował godzinę i miasto na podstawie obrazu, możesz uwzględnić to żądanie bezpośrednio w promptzie.
| Prompt | Odpowiedź modelu |
|---|---|
 Opisz ten obraz. |
Obraz przedstawia tablicę przylotów i odlotów na lotnisku. |
| Zaktualizowany prompt | Ulepszona odpowiedź |
|---|---|
Przeanalizuj czas i miasto z tablicy lotniska widocznej na tym obrazie i zapisz je na liście. |
Dodaj kilka przykładów
Model Gemini może przyjmować wiele danych wejściowych, które może wykorzystać jako przykłady do zrozumienia pożądanego wyniku. Dodanie tych przykładów może pomóc modelowi w rozpoznaniu wzorców i założeniu związku między danymi obrazami a odpowiedziami na nowy przykład. Jest to tzw. uczenie się z niewielką ilością danych.
W przykładzie poniżej początkowe dane wyjściowe są zapisane w formie zdania i zawierają kraj (Brazylia). Załóżmy, że chcesz uzyskać dane w innym formacie lub stylu i że chcesz uwzględnić tylko miasto, a nie kraj. Dodanie do promptu przykładów typu „few-shot” może sprawić, że model będzie odpowiadać w chcący sposób.
| Prompt | Odpowiedź modelu |
|---|---|
 Określ miasto i obiekt. |
To pomnik Chrystusa Zbawiciela w Rio de Janeiro w Brazylii. |
| Zaktualizowany prompt | Ulepszona odpowiedź |
|---|---|
|
Określ miasto i obiekt. 
|
miasto: Rzym, zabytek: Koloseum. |

|
miasto: Pekin, zabytek: Zakazane Miasto |
|
|
miasto: Rio de Janeiro, punkt orientacyjny: Statua Chrystusa Zbawiciela |
Szczegółowy opis
W przypadku złożonych zadań, które wymagają zarówno zrozumienia wizualnego, jak i rozumowania, warto podzielić zadanie na mniejsze, bardziej przejrzyste kroki. Możesz też poprosić model o „myślenie krok po kroku”.
| Prompt | Odpowiedź modelu |
|---|---|
 Kiedy skończy mi się papier toaletowy? |
Wkrótce zostaną Ci tylko 3 rolki. |
| Zaktualizowany prompt | Ulepszona odpowiedź |
|---|---|
|
|
Zadania matematyczne lub inne rodzaje zadań tekstowych to świetne kandydatury do zmuszenia modelu do myślenia krok po kroku.
| Prompt | Odpowiedź |
|---|---|
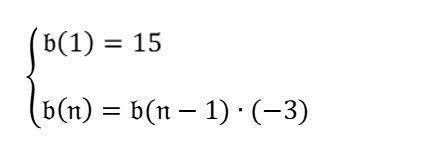
Jaki jest 4. wyraz w ciągu? |
-135 |
Odpowiedź z modelu jest nieprawidłowa. Aby to poprawić, możesz poprosić model o przeanalizowanie problemu przed udzieleniem odpowiedzi.
| Prompt | Odpowiedź |
|---|---|
Najpierw przeanalizuj formułę na obrazie. Następnie na podstawie formuły odpowiedz na pytanie „Jaki jest 4. wyraz w sekwencji?”. |
Kliknij, aby rozwinąć wynik\( b(n) = b(n-1) * (-3) \) \( b(1) = 15 \)
\( b(4) = b(4-1) * (-3) \) \( b(4) = b(3) * (-3) \) \( b(3) = b(3-1) * (-3) \) \( b(3) = b(2) * (-3) \) \( b(2) = b(2-1) * (-3) \) \( b(2) = b(1) * (-3) \) \( b(2) = 15 * (-3) \) \( b(2) = -45 \) \( b(3) = b(2) * (-3) \) \( b(3) = -45 * (-3) \) \( b(3) = 135 \) \( b(4) = b(3) * (-3) \) \( b(4) = 135 * (-3) \) \( b(4) = -405 \) Dlatego 4. wyraz w ciągu to -405. |
Ta odpowiedź modelu jest poprawna. Aby była jeszcze bardziej przejrzysta, możesz poprosić model o podanie kroków.
| Zaktualizowany prompt | Ulepszona odpowiedź |
|---|---|
Jaki jest 4. wyraz w ciągu? Zastanów się nad tym krok po kroku. |
Pierwszy termin to 15. Drugi składnik to b(1) * (-3) = 15 * (-3) = -45. Trzeci składnik to b(2) * (-3) = -45 * (-3) = 135. Czwarty składnik to b(3) * (-3) = 135 * (-3) = -405. |
Określ format wyjściowy
Typowym problemem jest konieczność uzyskania danych wyjściowych modelu w określonym formacie (np. markdown, JSON, HTML), zwłaszcza jeśli dane wyjściowe modelu muszą zostać przetworzone przez kolejne zadanie. Możesz spróbować wygenerować dane wyjściowe w tym formacie, instruując model w promptach. Oto 2 przykłady:
| Prompt | Odpowiedź modelu |
|---|---|
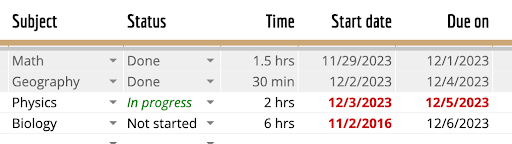 Przeanalizuj tabelę na tym obrazie i przekształć ją do formatu Markdown |
| Temat | Stan | Czas | Data rozpoczęcia | Termin | | ------- | ------ | ---- | --------- | ------ | | Math | Done | 1.5 hrs | 11/29/2023 | 12/1/2023 | | Geografia | Gotowe | 30 min | 2/12/2023 r. | 4/12/2023 r. | | Fizyka | W toku | 2 godz. | 3.12.2023 r. | 5.12.2023 r. | | Biologia | Nie rozpoczęto | 6 godzin | 2/11/2016 r. | 6/12/2023 r. | |
| Prompt | Odpowiedź modelu |
|---|---|

Podaj listę wszystkich tych atrybutów: składniki, rodzaj kuchni, informacje o tym, czy danie jest wegetariańskie, w formacie JSON |
|
W przypadku promptów z pojedynczym obrazem umieść obraz na pierwszym miejscu
Gemini może interpretować obraz i tekst w dowolnej kolejności w promptach, ale umieszczenie obrazu przed promptem tekstowym może przynieść lepsze wyniki. W tych przykładach obraz pojawia się przed tekstem w każdym promptzie.
Rozwiązywanie problemów z promptem multimodalnym
Jeśli nie otrzymujesz przydatnych odpowiedzi, być może trzeba będzie rozwiązać problem z promptem. Oto kilka strategii, które możesz wypróbować.
Jeśli model nie pobiera informacji z odpowiedniej części obrazu
Aby uzyskać bardziej szczegółową odpowiedź, możesz wskazać, które aspekty obrazu mają być wykorzystane do jej udzielenia.
| Prompt | Odpowiedź modelu |
|---|---|
 Ile dni te pieluchy wystarczą dziecku? |
Pampersy wystarczą na 198 dni. |
| Zaktualizowany prompt | Ulepszona odpowiedź |
|---|---|
|
Jak długo starczą te pieluchy? Aby określić wiek dziecka, użyj wagi podanej na opakowaniu, a aby określić łączną liczbę pieluch w opakowaniu, użyj liczby pieluch w opakowaniu. Podziel łączną liczbę przez liczbę pieluch, które dziecko zużywa dziennie. |
Pudełko zawiera 198 pielusz. Na opakowaniu podano, że pieluchy są przeznaczone dla dzieci o masie ciała 10–17 kg. Średnie dziecko o takiej wadze ma 1–2 lata. Dziecko w wieku 2 lat zazwyczaj zużywa 6 pieluch dziennie, więc pieluchy wystarczą na około 33 dni (198/6). |
Jeśli wyniki modelu są zbyt ogólne i nie są wystarczająco dostosowane do danych wejściowych w postaci obrazu
Aby pomóc modelowi dostosować odpowiedź do obrazów, poproś go o opisanie obrazów przed wykonaniem zadania rozumowania.
| Prompt | Odpowiedź modelu |
|---|---|



Co łączy te obrazy? |
Wszystkie 4 obrazy to przykłady fotografii krajobrazowej. |
| Zaktualizowany prompt | Ulepszona odpowiedź |
|---|---|
|
Najpierw szczegółowo opisz, co znajduje się na każdym obrazie. Co łączy te obrazy? |
Pierwsze zdjęcie przedstawia osobę pakującą walizkę. Drugi obraz przedstawia pusty korytarz w centrum handlowym. Trzeci obraz przedstawia rolkę papieru toaletowego. Czwarty obraz przedstawia ciemne i burzowe morze. Wszystkie te obrazy przedstawiają miejsca na pograniczu. Liminal spaces to miejsca lub sytuacje, które znajdują się pomiędzy dwoma innymi miejscami lub sytuacjami. Często są niejasne lub niepewne. Pierwszy obraz pokazuje osobę w domu i w podróży. Drugi obraz przedstawia korytarz między 2 sklepami. Trzeci obraz przedstawia papier toaletowy, który może symbolizować łazienkę. Łazienka to przestrzeń przejściowa pomiędzy sferą prywatną a publiczną. To miejsce, w którym przygotowujemy się do wejścia do świata zewnętrznego lub opuszczenia go. Czwarty obraz przedstawia morze, które nie jest ani spokojne, ani sztormowe. Przestrzeń liminalna może być ekscytująca, ale też niepokojąca. Mogą być miejscem nowych początków lub miejscem zakończeń. Mogą być miejscem na zastanowienie się lub miejscem na działanie. |
Możesz też wyraźnie poprosić model o odniesienie się do tego, co znajduje się na obrazie.
| Zaktualizowany prompt | Ulepszona odpowiedź |
|---|---|
|
Co łączy te obrazy? W odpowiedzi odwołuj się do tego, co widać na obrazach. |
Wszystkie obrazy są związane z podróżami. Pierwsze zdjęcie przedstawia osobę pakującą walizkę, drugie pusty korytarz w centrum handlowym, trzecie stos papieru toaletowego, a czwarte ciemne i burzowe morze. Wszystkie te obrazy są związane z podróżami, ponieważ przedstawiają rzeczy, których ludzie potrzebują lub których używają podczas podróży. Pierwszy obraz przedstawia osobę pakującą walizkę, co jest czymś, co ludzie robią, gdy wyjeżdżają w podróż. Drugie zdjęcie przedstawia pusty korytarz w centrum handlowym, gdzie ludzie często kupują rzeczy na podróże. Trzecie zdjęcie przedstawia stos papieru toaletowego, którego ludzie często używają w podróży. Czwarty obraz przedstawia ciemne i burzliwe morze, z którym ludzie często się spotykają podczas podróży. |
Te same wskazówki dotyczą również kreacji utworzonych na podstawie obrazów. W tym przykładzie z królikiem wyraźne poproszenie modelu o uwzględnienie aspektów z obrazu może poprawić wynik.
| Prompt | Odpowiedź modelu |
|---|---|

Czy możesz napisać wiersz o tym obrazie? |
Mały króliczek, taki puszysty i brązowy, Smakujesz trawy, tak zielonej i słodkiej, |
| Zaktualizowany prompt | Ulepszona odpowiedź |
|---|---|
|
Czy możesz napisać opisowy i dramatyczny wiersz o tym obrazie, uwzględniając w nim lokalizację? |
Little bunny on the green, Czy to oceaniczny błękit, Mały króliku, powiedz mi szczerze, Może to ogromna przestrzeń, Little bunny, I wonder what you dream, Niezależnie od tego, co to jest, mały króliku, |
Rozwiązywanie problemów z nieudanym promptem
Trudno jest stwierdzić, czy prompt nie zadziałał, ponieważ model nie zrozumiał obrazu, czy też zrozumiał go, ale nie wykonał potem prawidłowych czynności. Aby rozróżnić te powody, poproś model o opisanie tego, co znajduje się na obrazie.
W tym przykładzie, jeśli model odpowiada, że do herbaty pasuje przekąska, która wydaje się zaskakująca (np. popcorn), możesz najpierw rozwiązać problem, aby sprawdzić, czy model prawidłowo rozpoznał, że obraz zawiera herbatę.
| Prompt | Prośba o rozwiązanie problemu |
|---|---|
 Jaki przekąska mogę przygotować w 1 minutę, która będzie pasować do tego dania? |
Opisz, co znajduje się na tym obrazie. |
Inną strategią jest poproszenie modelu o wyjaśnienie jego rozumowania. Dzięki temu możesz określić, który element rozumowania zawodzi (jeśli w ogóle zawodzi).
| Prompt | Prośba o rozwiązanie problemu |
|---|---|
Jaki przekąska mogę przygotować w 1 minutę, która będzie pasować do tego dania? |
Jaki przekąska mogę przygotować w 1 minutę, która będzie pasować do tego dania? W jaki sposób? |
Co dalej?
- Spróbuj napisać własne prompty multimodalne za pomocą Google AI Studio.
- Informacje o używaniu interfejsu Gemini Files API do przesyłania plików multimedialnych i umieszczania ich w promptach znajdziesz w instrukcjach dotyczących Vision, Audio i przetwarzania dokumentów.
- Więcej wskazówek dotyczących projektowania promptów, np. dostosowywanie parametrów próbkowania, znajdziesz na stronie Strategie dotyczące promptów.