Gemini API memungkinkan Retrieval-Augmented Generation ("RAG") melalui alat Penelusuran File. Penelusuran File mengimpor, membagi, dan mengindeks data Anda untuk memungkinkan pengambilan informasi yang relevan dengan cepat berdasarkan perintah yang diberikan. Informasi yang diambil ini kemudian digunakan sebagai konteks untuk model, sehingga model dapat memberikan jawaban yang lebih akurat dan relevan. Penelusuran file juga dapat
menyediakan kemampuan multimodal dengan embedding teks yang didukung oleh
gemini-embedding-001, dan embedding gambar/multimodal yang didukung oleh gemini-embedding-2.
Penyimpanan file dan pembuatan sematan pada waktu kueri gratis, dan Anda hanya akan membayar pembuatan sematan saat pertama kali mengindeks file dan biaya token input / output model Gemini yang normal. Paradigma penagihan baru ini membuat Alat Penelusuran File lebih mudah dan hemat biaya untuk dibangun dan diskalakan. Lihat bagian harga untuk mengetahui detailnya.
Mengupload langsung ke penyimpanan Penelusuran File
Contoh ini menunjukkan cara mengupload file secara langsung ke penyimpanan penelusuran file:
Python
from google import genai
from google.genai import types
import time
client = genai.Client()
file_search_store = client.file_search_stores.create(
config={
'display_name': 'your-fileSearchStore-name',
'embedding_model': 'models/gemini-embedding-2'
}
)
operation = client.file_search_stores.upload_to_file_search_store(
file='sample.txt',
file_search_store_name=file_search_store.name,
config={
'display_name' : 'display-file-name',
}
)
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Can you tell me about [insert question]",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
if content_block.annotations:
print("\nSources:")
for annotation in content_block.annotations:
if annotation.type == "file_citation":
print(f" - {annotation.file_name}: {annotation.source}")
JavaScript
import { GoogleGenAI } from '@google/genai';
const ai = new GoogleGenAI({});
async function run() {
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: 'your-fileSearchStore-name',
embeddingModel: 'models/gemini-embedding-2'
}
});
let operation = await ai.fileSearchStores.uploadToFileSearchStore({
file: 'file.txt',
fileSearchStoreName: fileSearchStore.name,
config: {
displayName: 'file-name',
}
});
while (!operation.done) {
await new Promise(resolve => setTimeout(resolve, 5000));
operation = await ai.operations.get({ operation });
}
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Can you tell me about [insert question]",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name]
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text') {
console.log(contentBlock.text);
if (contentBlock.annotations) {
console.log("\nSources:");
for (const annotation of contentBlock.annotations) {
if (annotation.type === 'file_citation') {
console.log(` - ${annotation.file_name}: ${annotation.source}`);
}
}
}
}
}
}
}
}
run();
REST
# 1. Create a File Search store
curl -X POST "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=$GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"displayName": "your-file-search-store-name",
"embeddingModel": "models/gemini-embedding-2"
}' > store_res.json
FILE_SEARCH_STORE_NAME=$(jq -r ".name" store_res.json)
# 2. Upload directly to File Search store using resumable upload
NUM_BYTES=$(wc -c < "sample.txt")
curl "https://generativelanguage.googleapis.com/upload/v1beta/fileSearchStores/$FILE_SEARCH_STORE_NAME:uploadToFileSearchStore?key=$GEMINI_API_KEY" \
-D upload-header.tmp \
-H "X-Goog-Upload-Protocol: resumable" \
-H "X-Goog-Upload-Command: start" \
-H "X-Goog-Upload-Header-Content-Length: $NUM_BYTES" \
-H "X-Goog-Upload-Header-Content-Type: text/plain" \
-H "Content-Type: application/json" \
-d '{"displayName": "sample.txt"}' 2> /dev/null
upload_url=$(grep -i "x-goog-upload-url: " upload-header.tmp | cut -d" " -f2 | tr -d "\r")
rm upload-header.tmp
curl "${upload_url}" \
-H "Content-Length: $NUM_BYTES" \
-H "X-Goog-Upload-Offset: 0" \
-H "X-Goog-Upload-Command: upload, finalize" \
--data-binary "@sample.txt" 2> /dev/null > upload_response.json
cat upload_response.json
# 3. Query using the File Search store
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.5-flash",
"input": "Can you tell me about [insert question]",
"tools": [{
"type": "file_search",
"file_search_store_names": ["'"$FILE_SEARCH_STORE_NAME"'"]
}]
}'
Lihat referensi API untuk uploadToFileSearchStore untuk mengetahui informasi selengkapnya.
Mengimpor file
Atau, Anda dapat mengupload file yang ada dan mengimpornya ke penyimpanan penelusuran file Anda:
Python
from google import genai
from google.genai import types
import time
client = genai.Client()
sample_file = client.files.upload(file='sample.txt', config={'display_name': 'display_file_name'})
file_search_store = client.file_search_stores.create(
config={
'display_name': 'your-fileSearchStore-name',
'embedding_model': 'models/gemini-embedding-2'
}
)
operation = client.file_search_stores.import_file(
file_search_store_name=file_search_store.name,
file_name=sample_file.name
)
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Can you tell me about [insert question]",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
JavaScript
import { GoogleGenAI } from '@google/genai';
const ai = new GoogleGenAI({});
async function run() {
const sampleFile = await ai.files.upload({
file: 'sample.txt',
config: { displayName: 'file-name' }
});
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: 'your-fileSearchStore-name',
embeddingModel: 'models/gemini-embedding-2'
}
});
let operation = await ai.fileSearchStores.importFile({
fileSearchStoreName: fileSearchStore.name,
fileName: sampleFile.name
});
while (!operation.done) {
await new Promise(resolve => setTimeout(resolve, 5000));
operation = await ai.operations.get({ operation: operation });
}
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Can you tell me about [insert question]",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name]
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text') {
console.log(contentBlock.text);
}
}
}
}
}
run();
REST
# 1. Upload file using the Files API
NUM_BYTES=$(wc -c < "sample.txt")
curl "https://generativelanguage.googleapis.com/upload/v1beta/files?key=$GEMINI_API_KEY" \
-D upload-header.tmp \
-H "X-Goog-Upload-Protocol: resumable" \
-H "X-Goog-Upload-Command: start" \
-H "X-Goog-Upload-Header-Content-Length: $NUM_BYTES" \
-H "X-Goog-Upload-Header-Content-Type: text/plain" \
-H "Content-Type: application/json" \
-d '{"file": {"displayName": "sample.txt"}}' 2> /dev/null
upload_url=$(grep -i "x-goog-upload-url: " upload-header.tmp | cut -d" " -f2 | tr -d "\r")
rm upload-header.tmp
curl "${upload_url}" \
-H "Content-Length: $NUM_BYTES" \
-H "X-Goog-Upload-Offset: 0" \
-H "X-Goog-Upload-Command: upload, finalize" \
--data-binary "@sample.txt" 2> /dev/null > file_info.json
FILE_NAME=$(jq -r ".file.name" file_info.json)
# 2. Create a File Search store
curl -X POST "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=$GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"displayName": "your-file-search-store-name",
"embeddingModel": "models/gemini-embedding-2"
}' > store_res.json
FILE_SEARCH_STORE_NAME=$(jq -r ".name" store_res.json)
# 3. Import the file into the File Search store
curl -X POST "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/$FILE_SEARCH_STORE_NAME:importFile?key=$GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{"fileName": "'"$FILE_NAME"'"}'
# 4. Query using the File Search store
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.5-flash",
"input": "Can you tell me about [insert question]",
"tools": [{
"type": "file_search",
"file_search_store_names": ["'"$FILE_SEARCH_STORE_NAME"'"]
}]
}'
Lihat referensi API untuk importFile untuk mengetahui informasi selengkapnya.
Konfigurasi pemotongan
Saat Anda mengimpor file ke penyimpanan Penelusuran File, file tersebut akan otomatis dipecah menjadi beberapa bagian, disematkan, diindeks, dan diupload ke penyimpanan Penelusuran File Anda. Jika Anda
membutuhkan kontrol yang lebih besar atas strategi chunking, Anda dapat menentukan setelan
chunking_config
untuk menetapkan jumlah maksimum token per chunk dan jumlah maksimum token yang tumpang-tindih.
Python
from google import genai
from google.genai import types
import time
client = genai.Client()
operation = client.file_search_stores.upload_to_file_search_store(
file_search_store_name=file_search_store.name,
file='sample.txt',
config={
'chunking_config': {
'white_space_config': {
'max_tokens_per_chunk': 200,
'max_overlap_tokens': 20
}
}
}
)
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
print("Custom chunking complete.")
JavaScript
import { GoogleGenAI } from '@google/genai';
const ai = new GoogleGenAI({});
let operation = await ai.fileSearchStores.uploadToFileSearchStore({
file: 'file.txt',
fileSearchStoreName: fileSearchStore.name,
config: {
displayName: 'file-name',
chunkingConfig: {
whiteSpaceConfig: {
maxTokensPerChunk: 200,
maxOverlapTokens: 20
}
}
}
});
while (!operation.done) {
await new Promise(resolve => setTimeout(resolve, 5000));
operation = await ai.operations.get({ operation });
}
console.log("Custom chunking complete.");
REST
NUM_BYTES=$(wc -c < "sample.txt")
curl "https://generativelanguage.googleapis.com/upload/v1beta/fileSearchStores/$FILE_SEARCH_STORE_NAME:uploadToFileSearchStore?key=$GEMINI_API_KEY" \
-D upload-header.tmp \
-H "X-Goog-Upload-Protocol: resumable" \
-H "X-Goog-Upload-Command: start" \
-H "X-Goog-Upload-Header-Content-Length: $NUM_BYTES" \
-H "X-Goog-Upload-Header-Content-Type: text/plain" \
-H "Content-Type: application/json" \
-d '{
"displayName": "sample.txt",
"chunkingConfig": {
"whiteSpaceConfig": {
"maxTokensPerChunk": 200,
"maxOverlapTokens": 20
}
}
}' 2> /dev/null
upload_url=$(grep -i "x-goog-upload-url: " upload-header.tmp | cut -d" " -f2 | tr -d "\r")
rm upload-header.tmp
curl "${upload_url}" \
-H "Content-Length: $NUM_BYTES" \
-H "X-Goog-Upload-Offset: 0" \
-H "X-Goog-Upload-Command: upload, finalize" \
--data-binary "@sample.txt" 2> /dev/null > upload_response.json
cat upload_response.json
Untuk menggunakan penyimpanan Penelusuran File, teruskan sebagai alat ke metode interactions.create, seperti yang ditunjukkan dalam contoh Upload dan Impor.
Cara kerjanya
Penelusuran File menggunakan teknik yang disebut penelusuran semantik untuk menemukan informasi yang relevan dengan perintah pengguna. Tidak seperti penelusuran berbasis kata kunci standar, penelusuran semantik memahami makna dan konteks kueri Anda.
Saat Anda mengimpor file, file tersebut akan dikonversi menjadi representasi numerik yang disebut embedding, yang menangkap makna semantik konten yang diupload. Embedding ini disimpan dalam database Penelusuran File khusus. Saat Anda membuat kueri, kueri tersebut juga dikonversi menjadi embedding. Kemudian, sistem melakukan Penelusuran File untuk menemukan potongan dokumen yang paling mirip dan relevan dari penyimpanan Penelusuran File.
Tidak ada Time To Live (TTL) untuk penyematan; penyematan akan tetap ada hingga dihapus secara manual, atau saat model tidak digunakan lagi. Namun, file akan dihapus setelah 48 jam.
Berikut perincian proses penggunaan File Search
uploadToFileSearchStore API:
Membuat penyimpanan Penelusuran File: Penyimpanan Penelusuran File berisi data yang diproses dari file Anda. Ini adalah penampung persisten untuk sematan yang akan dioperasikan oleh penelusuran semantik.
Mengupload file dan mengimpor ke penyimpanan Penelusuran File: Mengupload file dan mengimpor hasil ke penyimpanan Penelusuran File secara bersamaan. Tindakan ini akan membuat objek
Filesementara, yang merupakan referensi ke dokumen mentah Anda. Data tersebut kemudian dibagi-bagi, dikonversi menjadi embedding Penelusuran File, dan diindeks. Objek akan dihapus setelah 48 jam, sedangkan data yang diimpor ke penyimpanan Penelusuran File akan disimpan tanpa batas waktu hingga Anda memilih untuk menghapusnya.FileKueri dengan Penelusuran File: Terakhir, Anda menggunakan alat
FileSearchdalam panggilangenerateContent. Dalam konfigurasi alat, Anda menentukanFileSearchRetrievalResource, yang mengarah keFileSearchStoreyang ingin Anda telusuri. Hal ini memberi tahu model untuk melakukan penelusuran semantik di penyimpanan Penelusuran File tertentu tersebut guna menemukan informasi yang relevan untuk mendasari responsnya.
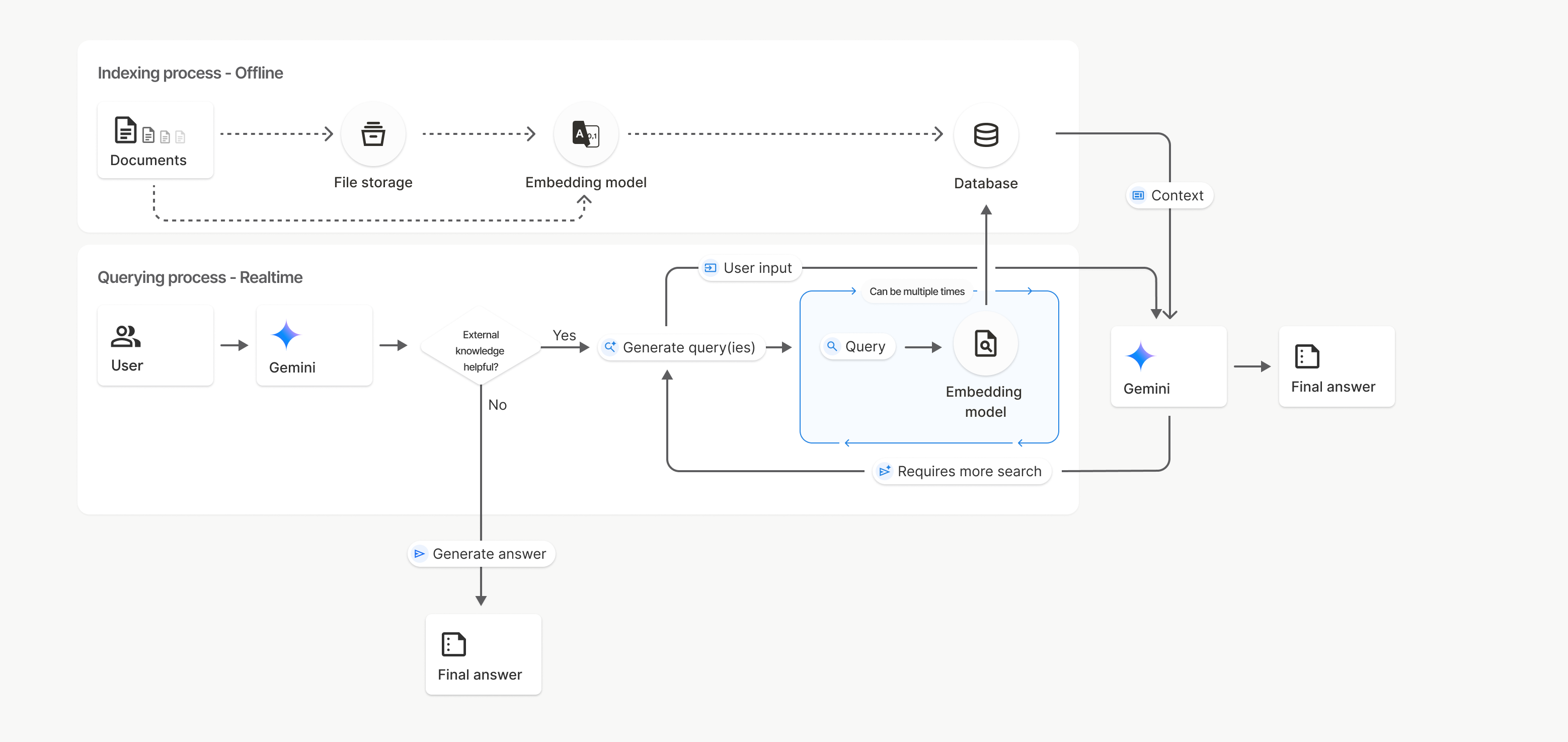
Dalam diagram ini, garis putus-putus dari Documents ke Embedding model
(menggunakan gemini-embedding-001)
mewakili uploadToFileSearchStore API (melewati File storage).
Jika tidak, menggunakan Files API untuk membuat
dan mengimpor file secara terpisah akan memindahkan proses pengindeksan dari Dokumen ke
Penyimpanan file, lalu ke Model sematan.
Menyimpan Penelusuran File
Penyimpanan Penelusuran File adalah container untuk embedding dokumen Anda. Meskipun file mentah yang diupload melalui File API akan dihapus setelah 48 jam, data yang diimpor ke penyimpanan Penelusuran File akan disimpan tanpa batas waktu hingga Anda menghapusnya secara manual. Anda dapat membuat beberapa penyimpanan Penelusuran File untuk mengatur dokumen Anda. API
FileSearchStore memungkinkan Anda membuat, mencantumkan, mendapatkan, dan menghapus untuk mengelola toko penelusuran file. Nama toko Penelusuran File memiliki cakupan global.
Berikut beberapa contoh cara mengelola toko Penelusuran File Anda:
Python
file_search_store = client.file_search_stores.create(
config={
'display_name': 'myfilesearchstore123',
'embedding_model': 'models/gemini-embedding-2'
}
)
for store in client.file_search_stores.list():
print(store)
my_file_search_store = client.file_search_stores.get(name=file_search_store.name)
client.file_search_stores.delete(name=file_search_store.name, config={'force': True})
JavaScript
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: 'myfilesearchstore123',
embeddingModel: 'models/gemini-embedding-2'
}
});
const fileSearchStores = await ai.fileSearchStores.list();
for await (const store of fileSearchStores) {
console.log(store);
}
const myFileSearchStore = await ai.fileSearchStores.get({
name: fileSearchStore.name
});
await ai.fileSearchStores.delete({
name: fileSearchStore.name,
config: { force: true }
});
REST
curl -X POST "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=${GEMINI_API_KEY}" \
-H "Content-Type: application/json" \
-d '{ "displayName": "My Store", "embedding_model": "models/gemini-embedding-2" }'
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=${GEMINI_API_KEY}"
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/myfilesearchstore123?key=${GEMINI_API_KEY}"
curl -X DELETE "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/myfilesearchstore123?key=${GEMINI_API_KEY}"
Dokumen Penelusuran File
Anda dapat mengelola setiap dokumen di penyimpanan file dengan API
File Search Documents untuk list setiap dokumen
di penyimpanan penelusuran file, get informasi tentang dokumen, dan delete
dokumen berdasarkan nama.
Python
for document_in_store in client.file_search_stores.documents.list(parent='fileSearchStores/myfilesearchstore123'):
print(document_in_store)
file_search_document = client.file_search_stores.documents.get(name='fileSearchStores/myfilesearchstore123/documents/sampletxt123')
print(file_search_document)
client.file_search_stores.documents.delete(name='fileSearchStores/myfilesearchstore123/documents/sampletxt123', config={'force': True})
JavaScript
const documents = await ai.fileSearchStores.documents.list({
parent: 'fileSearchStores/myfilesearchstore123'
});
for await (const doc of documents) {
console.log(doc);
}
const fileSearchDocument = await ai.fileSearchStores.documents.get({
name: 'fileSearchStores/myfilesearchstore123/documents/sampletxt123'
});
await ai.fileSearchStores.documents.delete({
name: 'fileSearchStores/myfilesearchstore123/documents/sampletxt123',
config: { force: true }
});
REST
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/myfilesearchstore123/documents?key=${GEMINI_API_KEY}"
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/myfilesearchstore123/documents/sampletxt123?key=${GEMINI_API_KEY}"
curl -X DELETE "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/myfilesearchstore123/documents/sampletxt123?key=${GEMINI_API_KEY}&force=true"
Metadata file
Anda dapat menambahkan metadata kustom ke file untuk membantu memfilter atau memberikan konteks tambahan. Metadata adalah sekumpulan key-value pair.
Python
op = client.file_search_stores.import_file(
file_search_store_name=file_search_store.name,
file_name=sample_file.name,
config={
'custom_metadata': [
{"key": "author", "string_value": "Robert Graves"},
{"key": "year", "numeric_value": 1934}
]
}
)
JavaScript
let operation = await ai.fileSearchStores.importFile({
fileSearchStoreName: fileSearchStore.name,
fileName: sampleFile.name,
config: {
customMetadata: [
{ key: "author", stringValue: "Robert Graves" },
{ key: "year", numericValue: 1934 }
]
}
});
Hal ini berguna jika Anda memiliki beberapa dokumen di penyimpanan Penelusuran File dan ingin menelusuri hanya sebagian dokumen tersebut.
Python
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Tell me about the book 'I, Claudius'",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name],
"metadata_filter": 'author="Robert Graves"',
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Tell me about the book 'I, Claudius'",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name],
metadata_filter: 'author="Robert Graves"',
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text') {
console.log(contentBlock.text);
}
}
}
}
REST
curl "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"model": "gemini-3.5-flash",
"input": [{"type": "text", "text": "Tell me about the book I, Claudius"}],
"tools": [{
"type": "file_search",
"file_search_store_names": ["'$STORE_NAME'"],
"metadata_filter": "author = \"Robert Graves\""
}]
}' 2> /dev/null > response.json
cat response.json
Panduan tentang penerapan sintaksis filter daftar untuk metadata_filter dapat ditemukan
di google.aip.dev/160
Penelusuran File Multimodal
Penelusuran File Multimodal memungkinkan Anda menyematkan dan menelusuri gambar secara native, sehingga memungkinkan aplikasi RAG multimodal yang kaya.
Mengonfigurasi model embedding
Saat membuat FileSearchStore, Anda harus mengganti model embedding default khusus teks untuk menggunakan model multimodal. Gunakan models/gemini-embedding-2 untuk
memproses teks dan gambar.
Python
store = client.file_search_stores.create(
config={
"display_name": "Multimodal Catalog",
"embedding_model": "models/gemini-embedding-2",
}
)
JavaScript
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: "Multimodal Catalog",
embeddingModel: "models/gemini-embedding-2",
},
});
REST
curl -X POST "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=$GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"display_name": "Multimodal Catalog",
"embedding_model": "models/gemini-embedding-2"
}'
Upload gambar
Setelah membuat penyimpanan dengan model penyematan multimodal, Anda dapat mengupload file gambar secara langsung menggunakan API upload yang sama seperti yang dijelaskan dalam Mengupload langsung ke penyimpanan Penelusuran File atau Mengimpor file.
Persyaratan file gambar:
- File gambar harus memiliki resolusi maksimal 4K x 4K piksel.
- Format yang didukung adalah PNG, JPEG.
Kutipan
Saat Anda menggunakan Penelusuran File, respons model dapat menyertakan kutipan yang menentukan bagian dokumen yang Anda upload yang digunakan untuk membuat jawaban. Hal ini membantu dalam pengecekan fakta dan verifikasi.
Anda dapat mengakses informasi kutipan melalui atribut annotations di dalam blok content respons langkah model_output.
Python
for step in interaction.steps:
if step.type == 'model_output':
for content in step.content:
if content.type == 'text' and content.annotations:
print(content.annotations)
JavaScript
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text' && contentBlock.annotations) {
console.log(JSON.stringify(contentBlock.annotations, null, 2));
}
}
}
}
REST
{
"steps": [
{
"type": "model_output",
"content": [
{
"type": "text",
"text": "...",
"annotations": [
{
"type": "file_citation",
"file_name": "sample.txt",
"source": "..."
}
]
}
]
}
]
}
Untuk mengetahui informasi mendetail tentang struktur kutipan, lihat referensi API untuk Interaksi.
Nomor halaman
Saat Anda menggunakan Penelusuran File dengan dokumen yang memiliki halaman (seperti PDF), respons model dapat menyertakan nomor halaman tempat informasi ditemukan.
Anda dapat mengakses informasi ini melalui atribut page_number dari anotasi
file_citation.
Python
for step in interaction.steps:
if step.type == "model_output":
for content in step.content:
if content.type == "text" and content.annotations:
for annotation in content.annotations:
if annotation.type == "file_citation" and annotation.page_number:
print(f"Cited Page: {annotation.page_number}")
JavaScript
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const block of step.content) {
if (block.type === 'text' && block.annotations) {
for (const annotation of block.annotations) {
if (annotation.type === 'file_citation' && annotation.pageNumber) {
console.log(`Cited Page: ${annotation.pageNumber}`);
}
}
}
}
}
}
REST
{
"steps": [
{
"type": "model_output",
"content": [
{
"type": "text",
"text": "...",
"annotations": [
{
"type": "file_citation",
"file_name": "document.pdf",
"page_number": 1,
"source": "..."
}
]
}
]
}
]
}
Kutipan media
Saat model mereferensikan potongan gambar selama pembuatan, API akan menampilkan anotasi jenis file_citation dalam anotasi yang menyertakan media_id. Anda dapat menggunakan ID ini untuk mendownload potongan gambar persis yang dirujuk model. media_id ini bersifat persisten di beberapa panggilan penelusuran, sehingga Anda dapat mengambil gambar yang sama atau menyimpannya dalam cache menggunakan ID dengan andal.
Cuplikan berikut adalah contoh langkah respons REST:
{
"type": "model_output",
"content": [
{
"type": "text",
"text": "...",
"annotations": [
{
"type": "file_citation",
"file_name": "product_image",
"media_id": "fileSearchStores/my-store-123/media/BlobId-456"
}
]
}
]
}
Cuplikan kode berikut menunjukkan cara mengambil media_id dan mendownload media:
Python
for step in interaction.steps:
if step.type == "model_output":
for content in step.content:
if content.type == "text" and content.annotations:
for annotation in content.annotations:
if annotation.type == "file_citation" and annotation.media_id:
print(f"Cited Media ID: {annotation.media_id}")
blob_content = client.file_search_stores.download_media(
media_id=annotation.media_id
)
JavaScript
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const block of step.content) {
if (block.type === 'text' && block.annotations) {
for (const annotation of block.annotations) {
if (annotation.type === 'file_citation' && annotation.mediaId) {
console.log(`Cited Media ID: ${annotation.mediaId}`);
const blobContent = await ai.fileSearchStores.downloadMedia(annotation.mediaId);
}
}
}
}
}
}
REST
curl -X GET "https://generativelanguage.googleapis.com/v1/fileSearchStores/my-store-123/media/BlobId-456" \
-H "x-goog-api-key: $GEMINI_API_KEY"
Metadata kustom
Jika telah menambahkan metadata kustom ke file, Anda dapat mengaksesnya di
anotasi respons model. Hal ini berguna untuk meneruskan konteks tambahan (seperti URL, nomor halaman, atau penulis) dari dokumen sumber ke logika aplikasi Anda. Setiap anotasi kutipan berjenis file_citation
berisi metadata kustom ini.
Python
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Tell me about [insert question]",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.annotations:
for annotation in content_block.annotations:
print(annotation)
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Tell me about [insert question]",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name]
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.annotations) {
contentBlock.annotations.forEach((annotation) => {
console.log(annotation);
});
}
}
}
}
REST
{
"steps": [
{
"type": "model_output",
"content": [
{
"type": "text",
"text": "...",
"annotations": [
{
"file_name": "...",
"source": "...",
"custom_metadata": [
{
"key": "author",
"string_value": "Robert Graves"
},
{
"key": "year",
"numeric_value": 1934
}
]
}
]
}
]
}
]
}
Output terstruktur
Mulai dari model Gemini 3, Anda dapat menggabungkan alat penelusuran file dengan output terstruktur.
Python
from pydantic import BaseModel, Field
class Money(BaseModel):
amount: str = Field(description="The numerical part of the amount.")
currency: str = Field(description="The currency of amount.")
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="What is the minimum hourly wage in Tokyo right now?",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}],
response_format={
"type": "text",
"mime_type": "application/json",
"schema": Money.model_json_schema()
},
)
result = Money.model_validate_json(interaction.output_text)
print(result)
JavaScript
import { z } from "zod";
const moneyJsonSchema = {
type: "object",
properties: {
amount: { type: "string", description: "The numerical part of the amount." },
currency: { type: "string", description: "The currency of amount." }
},
required: ["amount", "currency"]
};
const moneySchema = z.fromJSONSchema(moneyJsonSchema);
async function run() {
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "What is the minimum hourly wage in Tokyo right now?",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name],
}],
response_format: {
type: 'text',
mime_type: 'application/json',
schema: moneyJsonSchema
},
});
const result = moneySchema.parse(JSON.parse(interaction.output_text));
console.log(result);
}
run();
REST
curl "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"model": "gemini-3.5-flash",
"input": "What is the minimum hourly wage in Tokyo right now?",
"tools": [{
"type": "file_search",
"file_search_store_names": ["$FILE_SEARCH_STORE_NAME"]
}],
"response_format": {
"type": "text",
"mime_type": "application/json",
"schema": {
"type": "object",
"properties": {
"amount": {"type": "string", "description": "The numerical part of the amount."},
"currency": {"type": "string", "description": "The currency of amount."}
},
"required": ["amount", "currency"]
}
}
}'
Model yang didukung
Model berikut mendukung Penelusuran File:
| Model | Penelusuran File |
|---|---|
| Gemini 3.5 Flash | ✔️ |
| Pratinjau Gemini 3.1 Pro | ✔️ |
| Gemini 3.1 Flash-Lite | ✔️ |
| Pratinjau Gemini 3 Flash | ✔️ |
Jenis file yang didukung
Penelusuran File mendukung berbagai format file, yang tercantum di bagian berikut.
Jenis file aplikasi
application/dartapplication/ecmascriptapplication/jsonapplication/ms-javaapplication/mswordapplication/pdfapplication/sqlapplication/typescriptapplication/vnd.curlapplication/vnd.dartapplication/vnd.ibm.secure-containerapplication/vnd.jupyterapplication/vnd.ms-excelapplication/vnd.oasis.opendocument.textapplication/vnd.openxmlformats-officedocument.presentationml.presentationapplication/vnd.openxmlformats-officedocument.spreadsheetml.sheetapplication/vnd.openxmlformats-officedocument.wordprocessingml.documentapplication/vnd.openxmlformats-officedocument.wordprocessingml.templateapplication/x-cshapplication/x-hwpapplication/x-hwp-v5application/x-latexapplication/x-phpapplication/x-powershellapplication/x-shapplication/x-shellscriptapplication/x-texapplication/x-zshapplication/xmlapplication/zip
Jenis file teks
text/1d-interleaved-parityfectext/REDtext/SGMLtext/cache-manifesttext/calendartext/cqltext/cql-extensiontext/cql-identifiertext/csstext/csvtext/csv-schematext/dnstext/encaprtptext/enrichedtext/exampletext/fhirpathtext/flexfectext/fwdredtext/gff3text/grammar-ref-listtext/hl7v2text/htmltext/javascripttext/jcr-cndtext/jsxtext/markdowntext/mizartext/n3text/parameterstext/parityfectext/phptext/plaintext/provenance-notationtext/prs.fallenstein.rsttext/prs.lines.tagtext/prs.prop.logictext/raptorfectext/rfc822-headerstext/rtftext/rtp-enc-aescm128text/rtploopbacktext/rtxtext/sgmltext/shaclctext/shextext/spdxtext/stringstext/t140text/tab-separated-valuestext/texmacstext/trofftext/tsvtext/tsxtext/turtletext/ulpfectext/uri-listtext/vcardtext/vnd.DMClientScripttext/vnd.IPTC.NITFtext/vnd.IPTC.NewsMLtext/vnd.atext/vnd.abctext/vnd.ascii-arttext/vnd.curltext/vnd.debian.copyrighttext/vnd.dvb.subtitletext/vnd.esmertec.theme-descriptortext/vnd.exchangeabletext/vnd.familysearch.gedcomtext/vnd.ficlab.flttext/vnd.flytext/vnd.fmi.flexstortext/vnd.gmltext/vnd.graphviztext/vnd.hanstext/vnd.hgltext/vnd.in3d.3dmltext/vnd.in3d.spottext/vnd.latex-ztext/vnd.motorola.reflextext/vnd.ms-mediapackagetext/vnd.net2phone.commcenter.commandtext/vnd.radisys.msml-basic-layouttext/vnd.senx.warpscripttext/vnd.sositext/vnd.sun.j2me.app-descriptortext/vnd.trolltech.linguisttext/vnd.wap.sitext/vnd.wap.sltext/vnd.wap.wmltext/vnd.wap.wmlscripttext/vtttext/wgsltext/x-asmtext/x-bibtextext/x-bootext/x-ctext/x-c++hdrtext/x-c++srctext/x-cassandratext/x-chdrtext/x-coffeescripttext/x-componenttext/x-cshtext/x-csharptext/x-csrctext/x-cudatext/x-dtext/x-difftext/x-dsrctext/x-emacs-lisptext/x-erlangtext/x-gff3text/x-gotext/x-haskelltext/x-javatext/x-java-propertiestext/x-java-sourcetext/x-kotlintext/x-lilypondtext/x-lisptext/x-literate-haskelltext/x-luatext/x-moctext/x-objcsrctext/x-pascaltext/x-pcs-gcdtext/x-perltext/x-perl-scripttext/x-pythontext/x-python-scripttext/x-r-markdowntext/x-rsrctext/x-rsttext/x-ruby-scripttext/x-rusttext/x-sasstext/x-scalatext/x-schemetext/x-script.pythontext/x-scsstext/x-setexttext/x-sfvtext/x-shtext/x-siestatext/x-sostext/x-sqltext/x-swifttext/x-tcltext/x-textext/x-vbasictext/x-vcalendartext/xmltext/xml-dtdtext/xml-external-parsed-entitytext/yaml
Batasan
- Live API: Penelusuran File tidak didukung di Live API.
- Ketidakcocokan alat: Alat perujukan bawaan tidak dapat digabungkan satu sama lain; misalnya, Penelusuran File tidak dapat digunakan secara bersamaan dengan Perujukan dengan Google Penelusuran atau Konteks URL dalam permintaan yang sama.
Batas kapasitas
File Search API memiliki batas berikut untuk menerapkan stabilitas layanan:
- Ukuran file maksimum / batas per dokumen: 100 MB
- Total ukuran penyimpanan Penelusuran File project (berdasarkan tingkat pengguna):
- Gratis: 1 GB
- Tingkat 1: 10 GB
- Tingkat 2: 100 GB
- Tingkat 3: 1 TB
- Rekomendasi: Batasi ukuran setiap penyimpanan Penelusuran File hingga di bawah 20 GB untuk memastikan latensi pengambilan yang optimal.
Harga
- Anda akan ditagih untuk penyematan pada waktu pengindeksan berdasarkan harga penyematan yang ada.
- Penyimpanan tidak dikenai biaya.
- Penyematan waktu kueri tidak dikenai biaya.
- Token dokumen yang diambil akan ditagih sebagai token konteks reguler.
Langkah berikutnya
- Baca referensi API untuk Penyimpanan Penelusuran File dan Dokumen Penelusuran File.