L'API Gemini permet la génération augmentée par récupération (RAG) grâce à l'outil de recherche de fichiers. La recherche de fichiers importe, segmente et indexe vos données pour permettre une récupération rapide des informations pertinentes en fonction d'un prompt fourni. Ces informations récupérées sont ensuite utilisées comme contexte pour le modèle, ce qui lui permet de fournir des réponses plus précises et pertinentes. La recherche de fichiers peut également fournir des fonctionnalités multimodales avec des embeddings de texte compatibles avec gemini-embedding-001 et des embeddings d'image/multimodaux compatibles avec gemini-embedding-2.
Le stockage de fichiers et la génération d'embeddings au moment de la requête sont sans frais. Vous ne payez que la création d'embeddings lorsque vous indexez vos fichiers pour la première fois, ainsi que le coût normal des jetons d'entrée / sortie du modèle Gemini. Ce nouveau modèle de facturation permet de créer et de faire évoluer l'outil de recherche de fichiers plus facilement et de manière plus économique. Pour en savoir plus, consultez la section Tarifs.
Importer directement dans le dépôt de la recherche de fichiers
Cet exemple montre comment importer directement un fichier dans le magasin de recherche de fichiers :
Python
from google import genai
from google.genai import types
import time
client = genai.Client()
file_search_store = client.file_search_stores.create(
config={
'display_name': 'your-fileSearchStore-name',
'embedding_model': 'models/gemini-embedding-2'
}
)
operation = client.file_search_stores.upload_to_file_search_store(
file='sample.txt',
file_search_store_name=file_search_store.name,
config={
'display_name' : 'display-file-name',
}
)
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Can you tell me about [insert question]",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
if content_block.annotations:
print("\nSources:")
for annotation in content_block.annotations:
if annotation.type == "file_citation":
print(f" - {annotation.file_name}: {annotation.source}")
JavaScript
import { GoogleGenAI } from '@google/genai';
const ai = new GoogleGenAI({});
async function run() {
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: 'your-fileSearchStore-name',
embeddingModel: 'models/gemini-embedding-2'
}
});
let operation = await ai.fileSearchStores.uploadToFileSearchStore({
file: 'file.txt',
fileSearchStoreName: fileSearchStore.name,
config: {
displayName: 'file-name',
}
});
while (!operation.done) {
await new Promise(resolve => setTimeout(resolve, 5000));
operation = await ai.operations.get({ operation });
}
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Can you tell me about [insert question]",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name]
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text') {
console.log(contentBlock.text);
if (contentBlock.annotations) {
console.log("\nSources:");
for (const annotation of contentBlock.annotations) {
if (annotation.type === 'file_citation') {
console.log(` - ${annotation.file_name}: ${annotation.source}`);
}
}
}
}
}
}
}
}
run();
REST
# 1. Create a File Search store
curl -X POST "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=$GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"displayName": "your-file-search-store-name",
"embeddingModel": "models/gemini-embedding-2"
}' > store_res.json
FILE_SEARCH_STORE_NAME=$(jq -r ".name" store_res.json)
# 2. Upload directly to File Search store using resumable upload
NUM_BYTES=$(wc -c < "sample.txt")
curl "https://generativelanguage.googleapis.com/upload/v1beta/fileSearchStores/$FILE_SEARCH_STORE_NAME:uploadToFileSearchStore?key=$GEMINI_API_KEY" \
-D upload-header.tmp \
-H "X-Goog-Upload-Protocol: resumable" \
-H "X-Goog-Upload-Command: start" \
-H "X-Goog-Upload-Header-Content-Length: $NUM_BYTES" \
-H "X-Goog-Upload-Header-Content-Type: text/plain" \
-H "Content-Type: application/json" \
-d '{"displayName": "sample.txt"}' 2> /dev/null
upload_url=$(grep -i "x-goog-upload-url: " upload-header.tmp | cut -d" " -f2 | tr -d "\r")
rm upload-header.tmp
curl "${upload_url}" \
-H "Content-Length: $NUM_BYTES" \
-H "X-Goog-Upload-Offset: 0" \
-H "X-Goog-Upload-Command: upload, finalize" \
--data-binary "@sample.txt" 2> /dev/null > upload_response.json
cat upload_response.json
# 3. Query using the File Search store
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.5-flash",
"input": "Can you tell me about [insert question]",
"tools": [{
"type": "file_search",
"file_search_store_names": ["'"$FILE_SEARCH_STORE_NAME"'"]
}]
}'
Pour en savoir plus, consultez la documentation de référence de l'API pour uploadToFileSearchStore.
Importation de fichiers
Vous pouvez également importer un fichier existant dans votre magasin de recherche de fichiers :
Python
from google import genai
from google.genai import types
import time
client = genai.Client()
sample_file = client.files.upload(file='sample.txt', config={'display_name': 'display_file_name'})
file_search_store = client.file_search_stores.create(
config={
'display_name': 'your-fileSearchStore-name',
'embedding_model': 'models/gemini-embedding-2'
}
)
operation = client.file_search_stores.import_file(
file_search_store_name=file_search_store.name,
file_name=sample_file.name
)
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Can you tell me about [insert question]",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
JavaScript
import { GoogleGenAI } from '@google/genai';
const ai = new GoogleGenAI({});
async function run() {
const sampleFile = await ai.files.upload({
file: 'sample.txt',
config: { displayName: 'file-name' }
});
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: 'your-fileSearchStore-name',
embeddingModel: 'models/gemini-embedding-2'
}
});
let operation = await ai.fileSearchStores.importFile({
fileSearchStoreName: fileSearchStore.name,
fileName: sampleFile.name
});
while (!operation.done) {
await new Promise(resolve => setTimeout(resolve, 5000));
operation = await ai.operations.get({ operation: operation });
}
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Can you tell me about [insert question]",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name]
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text') {
console.log(contentBlock.text);
}
}
}
}
}
run();
REST
# 1. Upload file using the Files API
NUM_BYTES=$(wc -c < "sample.txt")
curl "https://generativelanguage.googleapis.com/upload/v1beta/files?key=$GEMINI_API_KEY" \
-D upload-header.tmp \
-H "X-Goog-Upload-Protocol: resumable" \
-H "X-Goog-Upload-Command: start" \
-H "X-Goog-Upload-Header-Content-Length: $NUM_BYTES" \
-H "X-Goog-Upload-Header-Content-Type: text/plain" \
-H "Content-Type: application/json" \
-d '{"file": {"displayName": "sample.txt"}}' 2> /dev/null
upload_url=$(grep -i "x-goog-upload-url: " upload-header.tmp | cut -d" " -f2 | tr -d "\r")
rm upload-header.tmp
curl "${upload_url}" \
-H "Content-Length: $NUM_BYTES" \
-H "X-Goog-Upload-Offset: 0" \
-H "X-Goog-Upload-Command: upload, finalize" \
--data-binary "@sample.txt" 2> /dev/null > file_info.json
FILE_NAME=$(jq -r ".file.name" file_info.json)
# 2. Create a File Search store
curl -X POST "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=$GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"displayName": "your-file-search-store-name",
"embeddingModel": "models/gemini-embedding-2"
}' > store_res.json
FILE_SEARCH_STORE_NAME=$(jq -r ".name" store_res.json)
# 3. Import the file into the File Search store
curl -X POST "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/$FILE_SEARCH_STORE_NAME:importFile?key=$GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{"fileName": "'"$FILE_NAME"'"}'
# 4. Query using the File Search store
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.5-flash",
"input": "Can you tell me about [insert question]",
"tools": [{
"type": "file_search",
"file_search_store_names": ["'"$FILE_SEARCH_STORE_NAME"'"]
}]
}'
Pour en savoir plus, consultez la documentation de référence de l'API pour importFile.
Configuration de la segmentation
Lorsque vous importez un fichier dans un magasin File Search, il est automatiquement divisé en blocs, intégré, indexé et importé dans votre magasin File Search. Si vous avez besoin de plus de contrôle sur la stratégie de segmentation, vous pouvez spécifier un paramètre chunking_config pour définir un nombre maximal de jetons par segment et un nombre maximal de jetons qui se chevauchent.
Python
from google import genai
from google.genai import types
import time
client = genai.Client()
operation = client.file_search_stores.upload_to_file_search_store(
file_search_store_name=file_search_store.name,
file='sample.txt',
config={
'chunking_config': {
'white_space_config': {
'max_tokens_per_chunk': 200,
'max_overlap_tokens': 20
}
}
}
)
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
print("Custom chunking complete.")
JavaScript
import { GoogleGenAI } from '@google/genai';
const ai = new GoogleGenAI({});
let operation = await ai.fileSearchStores.uploadToFileSearchStore({
file: 'file.txt',
fileSearchStoreName: fileSearchStore.name,
config: {
displayName: 'file-name',
chunkingConfig: {
whiteSpaceConfig: {
maxTokensPerChunk: 200,
maxOverlapTokens: 20
}
}
}
});
while (!operation.done) {
await new Promise(resolve => setTimeout(resolve, 5000));
operation = await ai.operations.get({ operation });
}
console.log("Custom chunking complete.");
REST
NUM_BYTES=$(wc -c < "sample.txt")
curl "https://generativelanguage.googleapis.com/upload/v1beta/fileSearchStores/$FILE_SEARCH_STORE_NAME:uploadToFileSearchStore?key=$GEMINI_API_KEY" \
-D upload-header.tmp \
-H "X-Goog-Upload-Protocol: resumable" \
-H "X-Goog-Upload-Command: start" \
-H "X-Goog-Upload-Header-Content-Length: $NUM_BYTES" \
-H "X-Goog-Upload-Header-Content-Type: text/plain" \
-H "Content-Type: application/json" \
-d '{
"displayName": "sample.txt",
"chunkingConfig": {
"whiteSpaceConfig": {
"maxTokensPerChunk": 200,
"maxOverlapTokens": 20
}
}
}' 2> /dev/null
upload_url=$(grep -i "x-goog-upload-url: " upload-header.tmp | cut -d" " -f2 | tr -d "\r")
rm upload-header.tmp
curl "${upload_url}" \
-H "Content-Length: $NUM_BYTES" \
-H "X-Goog-Upload-Offset: 0" \
-H "X-Goog-Upload-Command: upload, finalize" \
--data-binary "@sample.txt" 2> /dev/null > upload_response.json
cat upload_response.json
Pour utiliser votre magasin File Search, transmettez-le en tant qu'outil à la méthode interactions.create, comme indiqué dans les exemples Upload et Import.
Fonctionnement
La recherche de fichiers utilise une technique appelée recherche sémantique pour trouver des informations pertinentes par rapport à la requête utilisateur. Contrairement à la recherche standard basée sur les mots clés, la recherche sémantique comprend la signification et le contexte de votre requête.
Lorsque vous importez un fichier, il est converti en représentations numériques appelées embeddings, qui capturent la signification sémantique du contenu importé. Ces embeddings sont stockés dans une base de données de recherche de fichiers spécialisée. Lorsque vous effectuez une requête, elle est également convertie en embedding. Le système effectue ensuite une recherche de fichiers pour trouver les blocs de documents les plus similaires et pertinents dans le magasin de recherche de fichiers.
Il n'y a pas de valeur TTL (Time To Live) pour les embeddings. Ils persistent jusqu'à ce qu'ils soient supprimés manuellement ou lorsque le modèle est obsolète. Toutefois, les fichiers sont supprimés au bout de 48 heures.
Voici le détail du processus d'utilisation de l'API File Search uploadToFileSearchStore :
Créez un magasin File Search : un magasin File Search contient les données traitées de vos fichiers. Il s'agit du conteneur persistant pour les embeddings sur lesquels la recherche sémantique fonctionnera.
Importer un fichier dans un magasin de recherche de fichiers : importez simultanément un fichier et les résultats dans votre magasin de recherche de fichiers. Cela crée un objet
Filetemporaire, qui est une référence à votre document brut. Ces données sont ensuite segmentées, converties en embeddings File Search et indexées. L'objetFileest supprimé au bout de 48 heures, tandis que les données importées dans le magasin de recherche de fichiers sont stockées indéfiniment jusqu'à ce que vous choisissiez de les supprimer.Interroger avec la recherche de fichiers : enfin, vous utilisez l'outil
FileSearchdans un appelgenerateContent. Dans la configuration de l'outil, vous spécifiez unFileSearchRetrievalResourcequi pointe vers leFileSearchStoreque vous souhaitez rechercher. Cela indique au modèle d'effectuer une recherche sémantique dans ce File Search Store spécifique pour trouver des informations pertinentes afin d'ancrer sa réponse.
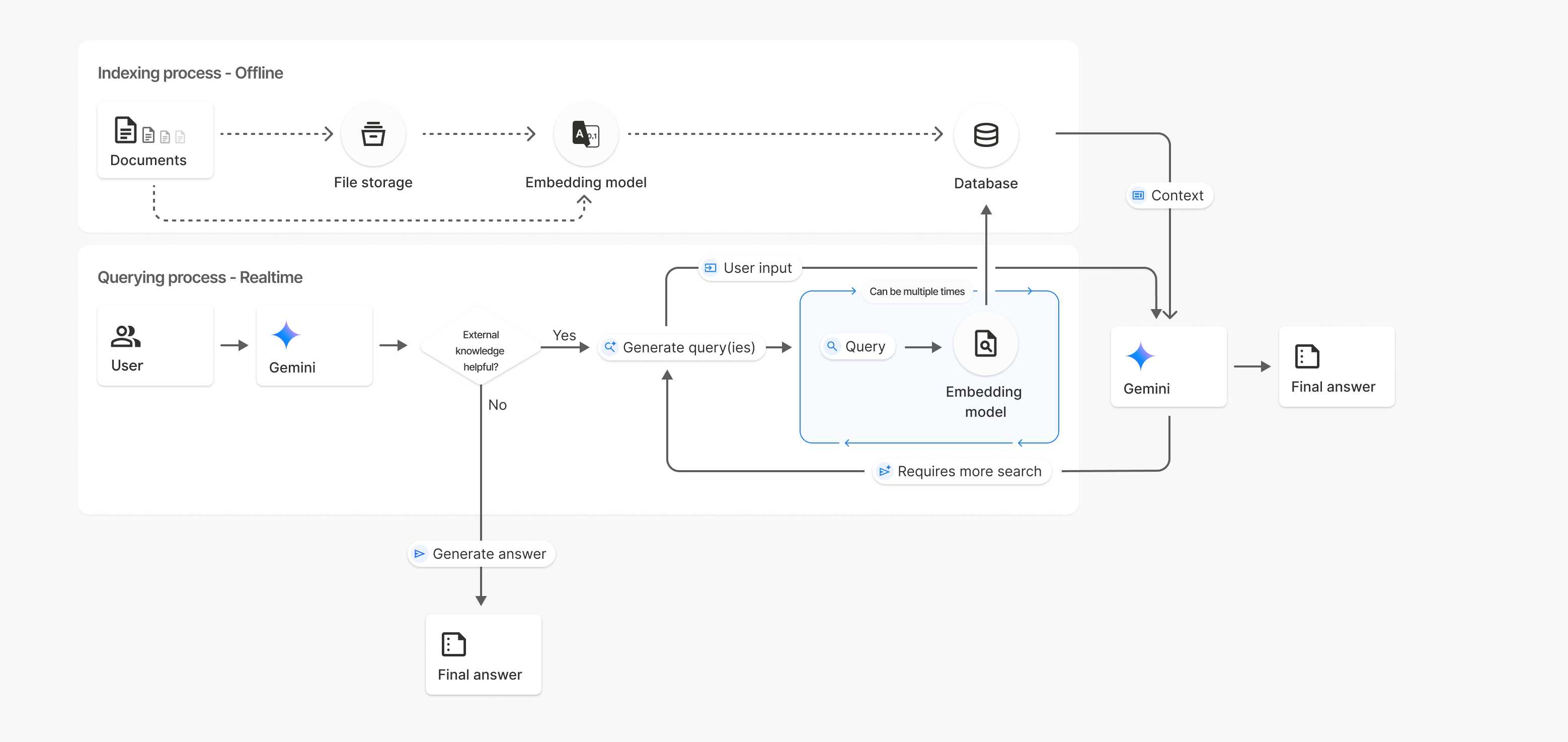
Dans ce diagramme, la ligne en pointillés allant de Documents à Modèle d'embedding (à l'aide de gemini-embedding-001) représente l'API uploadToFileSearchStore (en contournant Stockage de fichiers).
Sinon, l'utilisation de l'API Files pour créer et importer des fichiers séparément déplace le processus d'indexation de Documents vers Stockage de fichiers, puis vers Modèle d'embedding.
Magasins de recherche de fichiers
Un magasin File Search est un conteneur pour vos embeddings de documents. Les fichiers bruts importés via l'API File sont supprimés au bout de 48 heures, mais les données importées dans un magasin File Search sont stockées indéfiniment jusqu'à ce que vous les supprimiez manuellement. Vous pouvez créer plusieurs magasins de recherche de fichiers pour organiser vos documents. L'API FileSearchStore vous permet de créer, de lister, d'obtenir et de supprimer des magasins de recherche de fichiers pour les gérer. Les noms de magasins de la recherche de fichiers ont une portée globale.
Voici quelques exemples de gestion de vos magasins de recherche de fichiers :
Python
file_search_store = client.file_search_stores.create(
config={
'display_name': 'myfilesearchstore123',
'embedding_model': 'models/gemini-embedding-2'
}
)
for store in client.file_search_stores.list():
print(store)
my_file_search_store = client.file_search_stores.get(name=file_search_store.name)
client.file_search_stores.delete(name=file_search_store.name, config={'force': True})
JavaScript
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: 'myfilesearchstore123',
embeddingModel: 'models/gemini-embedding-2'
}
});
const fileSearchStores = await ai.fileSearchStores.list();
for await (const store of fileSearchStores) {
console.log(store);
}
const myFileSearchStore = await ai.fileSearchStores.get({
name: fileSearchStore.name
});
await ai.fileSearchStores.delete({
name: fileSearchStore.name,
config: { force: true }
});
REST
curl -X POST "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=${GEMINI_API_KEY}" \
-H "Content-Type: application/json" \
-d '{ "displayName": "My Store", "embedding_model": "models/gemini-embedding-2" }'
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=${GEMINI_API_KEY}"
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/myfilesearchstore123?key=${GEMINI_API_KEY}"
curl -X DELETE "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/myfilesearchstore123?key=${GEMINI_API_KEY}"
Documents de recherche de fichiers
Vous pouvez gérer des documents individuels dans vos magasins de fichiers avec l'API File Search Documents pour list chaque document dans un magasin de recherche de fichiers, get des informations sur un document et delete un document par nom.
Python
for document_in_store in client.file_search_stores.documents.list(parent='fileSearchStores/myfilesearchstore123'):
print(document_in_store)
file_search_document = client.file_search_stores.documents.get(name='fileSearchStores/myfilesearchstore123/documents/sampletxt123')
print(file_search_document)
client.file_search_stores.documents.delete(name='fileSearchStores/myfilesearchstore123/documents/sampletxt123', config={'force': True})
JavaScript
const documents = await ai.fileSearchStores.documents.list({
parent: 'fileSearchStores/myfilesearchstore123'
});
for await (const doc of documents) {
console.log(doc);
}
const fileSearchDocument = await ai.fileSearchStores.documents.get({
name: 'fileSearchStores/myfilesearchstore123/documents/sampletxt123'
});
await ai.fileSearchStores.documents.delete({
name: 'fileSearchStores/myfilesearchstore123/documents/sampletxt123',
config: { force: true }
});
REST
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/myfilesearchstore123/documents?key=${GEMINI_API_KEY}"
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/myfilesearchstore123/documents/sampletxt123?key=${GEMINI_API_KEY}"
curl -X DELETE "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/myfilesearchstore123/documents/sampletxt123?key=${GEMINI_API_KEY}&force=true"
Métadonnées des fichiers
Vous pouvez ajouter des métadonnées personnalisées à vos fichiers pour les filtrer ou fournir un contexte supplémentaire. Les métadonnées sont un ensemble de paires clé/valeur.
Python
op = client.file_search_stores.import_file(
file_search_store_name=file_search_store.name,
file_name=sample_file.name,
config={
'custom_metadata': [
{"key": "author", "string_value": "Robert Graves"},
{"key": "year", "numeric_value": 1934}
]
}
)
JavaScript
let operation = await ai.fileSearchStores.importFile({
fileSearchStoreName: fileSearchStore.name,
fileName: sampleFile.name,
config: {
customMetadata: [
{ key: "author", stringValue: "Robert Graves" },
{ key: "year", numericValue: 1934 }
]
}
});
Cela est utile lorsque vous avez plusieurs documents dans un magasin de recherche de fichiers et que vous souhaitez n'en rechercher qu'un sous-ensemble.
Python
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Tell me about the book 'I, Claudius'",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name],
"metadata_filter": 'author="Robert Graves"',
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Tell me about the book 'I, Claudius'",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name],
metadata_filter: 'author="Robert Graves"',
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text') {
console.log(contentBlock.text);
}
}
}
}
REST
curl "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"model": "gemini-3.5-flash",
"input": [{"type": "text", "text": "Tell me about the book I, Claudius"}],
"tools": [{
"type": "file_search",
"file_search_store_names": ["'$STORE_NAME'"],
"metadata_filter": "author = \"Robert Graves\""
}]
}' 2> /dev/null > response.json
cat response.json
Pour savoir comment implémenter la syntaxe des filtres de liste pour metadata_filter, consultez google.aip.dev/160.
Recherche multimodale de fichiers
La recherche de fichiers multimodale vous permet d'intégrer et de rechercher des images de manière native, ce qui permet de créer des applications RAG multimodales riches.
Configurer le modèle d'embedding
Lorsque vous créez un FileSearchStore, vous devez remplacer le modèle d'embedding par défaut réservé au texte pour utiliser un modèle multimodal. Utilisez models/gemini-embedding-2 pour traiter le texte et les images.
Python
store = client.file_search_stores.create(
config={
"display_name": "Multimodal Catalog",
"embedding_model": "models/gemini-embedding-2",
}
)
JavaScript
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: "Multimodal Catalog",
embeddingModel: "models/gemini-embedding-2",
},
});
REST
curl -X POST "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=$GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"display_name": "Multimodal Catalog",
"embedding_model": "models/gemini-embedding-2"
}'
Importer des images
Une fois que vous avez créé le magasin avec un modèle d'embedding multimodal, vous pouvez importer des fichiers image directement à l'aide des mêmes API d'importation décrites dans Importer directement dans un magasin de recherche de fichiers ou Importer des fichiers.
Exigences concernant les fichiers image :
- La résolution des fichiers image ne doit pas dépasser 4 000 x 4 000 pixels.
- Les formats acceptés sont PNG et JPEG.
Citations
Lorsque vous utilisez la recherche de fichiers, la réponse du modèle peut inclure des citations qui précisent les parties de vos documents importés qui ont été utilisées pour générer la réponse. Cela permet de vérifier les faits.
Vous pouvez accéder aux informations de citation via l'attribut annotations à l'intérieur des blocs content de l'étape model_output de la réponse.
Python
for step in interaction.steps:
if step.type == 'model_output':
for content in step.content:
if content.type == 'text' and content.annotations:
print(content.annotations)
JavaScript
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text' && contentBlock.annotations) {
console.log(JSON.stringify(contentBlock.annotations, null, 2));
}
}
}
}
REST
{
"steps": [
{
"type": "model_output",
"content": [
{
"type": "text",
"text": "...",
"annotations": [
{
"type": "file_citation",
"file_name": "sample.txt",
"source": "..."
}
]
}
]
}
]
}
Pour obtenir des informations détaillées sur la structure des citations, consultez la documentation de référence de l'API Interactions.
Numéros de page
Lorsque vous utilisez la recherche de fichiers avec des documents comportant des pages (comme les PDF), la réponse du modèle peut inclure le numéro de la page où les informations ont été trouvées.
Vous pouvez accéder à ces informations via l'attribut page_number d'une annotation file_citation.
Python
for step in interaction.steps:
if step.type == "model_output":
for content in step.content:
if content.type == "text" and content.annotations:
for annotation in content.annotations:
if annotation.type == "file_citation" and annotation.page_number:
print(f"Cited Page: {annotation.page_number}")
JavaScript
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const block of step.content) {
if (block.type === 'text' && block.annotations) {
for (const annotation of block.annotations) {
if (annotation.type === 'file_citation' && annotation.pageNumber) {
console.log(`Cited Page: ${annotation.pageNumber}`);
}
}
}
}
}
}
REST
{
"steps": [
{
"type": "model_output",
"content": [
{
"type": "text",
"text": "...",
"annotations": [
{
"type": "file_citation",
"file_name": "document.pdf",
"page_number": 1,
"source": "..."
}
]
}
]
}
]
}
Citations de médias
Lorsque le modèle fait référence à un bloc d'image lors de la génération, l'API renvoie une annotation de type file_citation dans les annotations qui incluent un media_id. Vous pouvez utiliser cet ID pour télécharger le bloc d'image exact auquel le modèle fait référence. Ce media_id est persistant pour plusieurs appels de recherche, ce qui vous permet de récupérer de manière fiable la même image ou de la mettre en cache à l'aide de l'ID.
L'extrait suivant est un exemple d'étape de réponse REST :
{
"type": "model_output",
"content": [
{
"type": "text",
"text": "...",
"annotations": [
{
"type": "file_citation",
"file_name": "product_image",
"media_id": "fileSearchStores/my-store-123/media/BlobId-456"
}
]
}
]
}
Les extraits de code suivants montrent comment récupérer le media_id et télécharger le contenu multimédia :
Python
for step in interaction.steps:
if step.type == "model_output":
for content in step.content:
if content.type == "text" and content.annotations:
for annotation in content.annotations:
if annotation.type == "file_citation" and annotation.media_id:
print(f"Cited Media ID: {annotation.media_id}")
blob_content = client.file_search_stores.download_media(
media_id=annotation.media_id
)
JavaScript
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const block of step.content) {
if (block.type === 'text' && block.annotations) {
for (const annotation of block.annotations) {
if (annotation.type === 'file_citation' && annotation.mediaId) {
console.log(`Cited Media ID: ${annotation.mediaId}`);
const blobContent = await ai.fileSearchStores.downloadMedia(annotation.mediaId);
}
}
}
}
}
}
REST
curl -X GET "https://generativelanguage.googleapis.com/v1/fileSearchStores/my-store-123/media/BlobId-456" \
-H "x-goog-api-key: $GEMINI_API_KEY"
Métadonnées personnalisées
Si vous avez ajouté des métadonnées personnalisées à vos fichiers, vous pouvez y accéder dans les annotations de la réponse du modèle. Cela est utile pour transmettre du contexte supplémentaire (comme des URL, des numéros de page ou des auteurs) de vos documents sources à la logique de votre application. Chaque annotation de citation de type file_citation contient ces métadonnées personnalisées.
Python
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Tell me about [insert question]",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.annotations:
for annotation in content_block.annotations:
print(annotation)
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Tell me about [insert question]",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name]
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.annotations) {
contentBlock.annotations.forEach((annotation) => {
console.log(annotation);
});
}
}
}
}
REST
{
"steps": [
{
"type": "model_output",
"content": [
{
"type": "text",
"text": "...",
"annotations": [
{
"file_name": "...",
"source": "...",
"custom_metadata": [
{
"key": "author",
"string_value": "Robert Graves"
},
{
"key": "year",
"numeric_value": 1934
}
]
}
]
}
]
}
]
}
Sortie structurée
À partir des modèles Gemini 3, vous pouvez combiner l'outil de recherche de fichiers avec des sorties structurées.
Python
from pydantic import BaseModel, Field
class Money(BaseModel):
amount: str = Field(description="The numerical part of the amount.")
currency: str = Field(description="The currency of amount.")
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="What is the minimum hourly wage in Tokyo right now?",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}],
response_format={
"type": "text",
"mime_type": "application/json",
"schema": Money.model_json_schema()
},
)
result = Money.model_validate_json(interaction.output_text)
print(result)
JavaScript
import { z } from "zod";
const moneyJsonSchema = {
type: "object",
properties: {
amount: { type: "string", description: "The numerical part of the amount." },
currency: { type: "string", description: "The currency of amount." }
},
required: ["amount", "currency"]
};
const moneySchema = z.fromJSONSchema(moneyJsonSchema);
async function run() {
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "What is the minimum hourly wage in Tokyo right now?",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name],
}],
response_format: {
type: 'text',
mime_type: 'application/json',
schema: moneyJsonSchema
},
});
const result = moneySchema.parse(JSON.parse(interaction.output_text));
console.log(result);
}
run();
REST
curl "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"model": "gemini-3.5-flash",
"input": "What is the minimum hourly wage in Tokyo right now?",
"tools": [{
"type": "file_search",
"file_search_store_names": ["$FILE_SEARCH_STORE_NAME"]
}],
"response_format": {
"type": "text",
"mime_type": "application/json",
"schema": {
"type": "object",
"properties": {
"amount": {"type": "string", "description": "The numerical part of the amount."},
"currency": {"type": "string", "description": "The currency of amount."}
},
"required": ["amount", "currency"]
}
}
}'
Modèles compatibles
Les modèles suivants sont compatibles avec la recherche de fichiers :
| Modèle | Recherche de fichiers |
|---|---|
| Gemini 3.5 Flash | ✔️ |
| Preview Gemini 3.1 Pro | ✔️ |
| Gemini 3.1 Flash-Lite | ✔️ |
| Preview Gemini 3 Flash | ✔️ |
Types de fichiers compatibles
La recherche de fichiers est compatible avec un large éventail de formats de fichiers, listés dans les sections suivantes.
Types de fichiers d'application
application/dartapplication/ecmascriptapplication/jsonapplication/ms-javaapplication/mswordapplication/pdfapplication/sqlapplication/typescriptapplication/vnd.curlapplication/vnd.dartapplication/vnd.ibm.secure-containerapplication/vnd.jupyterapplication/vnd.ms-excelapplication/vnd.oasis.opendocument.textapplication/vnd.openxmlformats-officedocument.presentationml.presentationapplication/vnd.openxmlformats-officedocument.spreadsheetml.sheetapplication/vnd.openxmlformats-officedocument.wordprocessingml.documentapplication/vnd.openxmlformats-officedocument.wordprocessingml.templateapplication/x-cshapplication/x-hwpapplication/x-hwp-v5application/x-latexapplication/x-phpapplication/x-powershellapplication/x-shapplication/x-shellscriptapplication/x-texapplication/x-zshapplication/xmlapplication/zip
Types de fichiers texte
text/1d-interleaved-parityfectext/REDtext/SGMLtext/cache-manifesttext/calendartext/cqltext/cql-extensiontext/cql-identifiertext/csstext/csvtext/csv-schematext/dnstext/encaprtptext/enrichedtext/exampletext/fhirpathtext/flexfectext/fwdredtext/gff3text/grammar-ref-listtext/hl7v2text/htmltext/javascripttext/jcr-cndtext/jsxtext/markdowntext/mizartext/n3text/parameterstext/parityfectext/phptext/plaintext/provenance-notationtext/prs.fallenstein.rsttext/prs.lines.tagtext/prs.prop.logictext/raptorfectext/rfc822-headerstext/rtftext/rtp-enc-aescm128text/rtploopbacktext/rtxtext/sgmltext/shaclctext/shextext/spdxtext/stringstext/t140text/tab-separated-valuestext/texmacstext/trofftext/tsvtext/tsxtext/turtletext/ulpfectext/uri-listtext/vcardtext/vnd.DMClientScripttext/vnd.IPTC.NITFtext/vnd.IPTC.NewsMLtext/vnd.atext/vnd.abctext/vnd.ascii-arttext/vnd.curltext/vnd.debian.copyrighttext/vnd.dvb.subtitletext/vnd.esmertec.theme-descriptortext/vnd.exchangeabletext/vnd.familysearch.gedcomtext/vnd.ficlab.flttext/vnd.flytext/vnd.fmi.flexstortext/vnd.gmltext/vnd.graphviztext/vnd.hanstext/vnd.hgltext/vnd.in3d.3dmltext/vnd.in3d.spottext/vnd.latex-ztext/vnd.motorola.reflextext/vnd.ms-mediapackagetext/vnd.net2phone.commcenter.commandtext/vnd.radisys.msml-basic-layouttext/vnd.senx.warpscripttext/vnd.sositext/vnd.sun.j2me.app-descriptortext/vnd.trolltech.linguisttext/vnd.wap.sitext/vnd.wap.sltext/vnd.wap.wmltext/vnd.wap.wmlscripttext/vtttext/wgsltext/x-asmtext/x-bibtextext/x-bootext/x-ctext/x-c++hdrtext/x-c++srctext/x-cassandratext/x-chdrtext/x-coffeescripttext/x-componenttext/x-cshtext/x-csharptext/x-csrctext/x-cudatext/x-dtext/x-difftext/x-dsrctext/x-emacs-lisptext/x-erlangtext/x-gff3text/x-gotext/x-haskelltext/x-javatext/x-java-propertiestext/x-java-sourcetext/x-kotlintext/x-lilypondtext/x-lisptext/x-literate-haskelltext/x-luatext/x-moctext/x-objcsrctext/x-pascaltext/x-pcs-gcdtext/x-perltext/x-perl-scripttext/x-pythontext/x-python-scripttext/x-r-markdowntext/x-rsrctext/x-rsttext/x-ruby-scripttext/x-rusttext/x-sasstext/x-scalatext/x-schemetext/x-script.pythontext/x-scsstext/x-setexttext/x-sfvtext/x-shtext/x-siestatext/x-sostext/x-sqltext/x-swifttext/x-tcltext/x-textext/x-vbasictext/x-vcalendartext/xmltext/xml-dtdtext/xml-external-parsed-entitytext/yaml
Limites
- API Live : la recherche de fichiers n'est pas compatible avec l'API Live.
- Incompatibilité des outils : les outils d'ancrage intégrés ne peuvent pas être combinés entre eux. Par exemple, la recherche de fichiers ne peut pas être utilisée simultanément avec l'ancrage avec la recherche Google ou le contexte d'URL dans la même requête.
Limites de débit
Pour assurer la stabilité du service, l'API File Search est soumise aux limites suivantes :
- Taille maximale des fichiers / limite par document : 100 Mo
- Taille totale des magasins de recherche de fichiers de projet (selon le niveau d'utilisateur) :
- Sans frais : 1 Go
- Niveau 1 : 10 Go
- Niveau 2 : 100 Go
- Niveau 3 : 1 To
- Recommandation : Limitez la taille de chaque magasin File Search à moins de 20 Go pour garantir des latences de récupération optimales.
Tarifs
- Les embeddings vous sont facturés au moment de l'indexation, en fonction des tarifs existants pour les embeddings.
- Le stockage est sans frais.
- Les embeddings au moment de la requête sont sans frais.
- Les jetons de documents récupérés sont facturés en tant que jetons de contexte standards.
Étape suivante
- Consultez la documentation de référence sur l'API pour les magasins de recherche de fichiers et les documents de recherche de fichiers.