Gemini API では、ファイル検索ツールを使用して検索拡張生成(RAG)を利用できます。ファイル検索では、データがインポート、チャンク化、インデックス登録され、指定されたプロンプトに基づいて関連情報をすばやく取得できます。取得した情報はモデルのコンテキストとして使用され、より正確で関連性の高い回答を提供できるようになります。ファイル検索では、gemini-embedding-001 でサポートされているテキスト エンベディングと、gemini-embedding-2 でサポートされている画像/マルチモーダル エンベディングを使用して、マルチモーダル機能を提供することもできます。
クエリ時のファイル ストレージとエンベディング生成は無料です。エンベディングの作成に対してのみ料金が発生します。これは、最初にファイルをインデックス登録するときと、通常の Gemini モデルの入力 / 出力トークンの費用です。この新しい課金パラダイムにより、ファイル検索ツールをより簡単に、費用対効果の高い方法で構築してスケーリングできます。詳細については、料金セクションをご覧ください。
ファイル検索ストアに直接アップロードする
この例は、ファイル検索ストアにファイルを直接アップロードする方法を示しています。
Python
from google import genai
from google.genai import types
import time
client = genai.Client()
file_search_store = client.file_search_stores.create(
config={
'display_name': 'your-fileSearchStore-name',
'embedding_model': 'models/gemini-embedding-2'
}
)
operation = client.file_search_stores.upload_to_file_search_store(
file='sample.txt',
file_search_store_name=file_search_store.name,
config={
'display_name' : 'display-file-name',
}
)
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Can you tell me about [insert question]",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
if content_block.annotations:
print("\nSources:")
for annotation in content_block.annotations:
if annotation.type == "file_citation":
print(f" - {annotation.file_name}: {annotation.source}")
JavaScript
const { GoogleGenAI } = require('@google/genai');
const ai = new GoogleGenAI({});
async function run() {
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: 'your-fileSearchStore-name',
embeddingModel: 'models/gemini-embedding-2'
}
});
let operation = await ai.fileSearchStores.uploadToFileSearchStore({
file: 'file.txt',
fileSearchStoreName: fileSearchStore.name,
config: {
displayName: 'file-name',
}
});
while (!operation.done) {
await new Promise(resolve => setTimeout(resolve, 5000));
operation = await ai.operations.get({ operation });
}
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Can you tell me about [insert question]",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name]
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text') {
console.log(contentBlock.text);
if (contentBlock.annotations) {
console.log("\nSources:");
for (const annotation of contentBlock.annotations) {
if (annotation.type === 'file_citation') {
console.log(` - ${annotation.file_name}: ${annotation.source}`);
}
}
}
}
}
}
}
}
run();
詳しくは、uploadToFileSearchStore の API リファレンスをご覧ください。
ファイルのインポート
または、既存のファイルをアップロードして、ファイル検索ストアにインポートすることもできます。
Python
from google import genai
from google.genai import types
import time
client = genai.Client()
sample_file = client.files.upload(file='sample.txt', config={'display_name': 'display_file_name'})
file_search_store = client.file_search_stores.create(
config={
'display_name': 'your-fileSearchStore-name',
'embedding_model': 'models/gemini-embedding-2'
}
)
operation = client.file_search_stores.import_file(
file_search_store_name=file_search_store.name,
file_name=sample_file.name
)
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Can you tell me about [insert question]",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
JavaScript
const { GoogleGenAI } = require('@google/genai');
const ai = new GoogleGenAI({});
async function run() {
const sampleFile = await ai.files.upload({
file: 'sample.txt',
config: { displayName: 'file-name' }
});
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: 'your-fileSearchStore-name',
embeddingModel: 'models/gemini-embedding-2'
}
});
let operation = await ai.fileSearchStores.importFile({
fileSearchStoreName: fileSearchStore.name,
fileName: sampleFile.name
});
while (!operation.done) {
await new Promise(resolve => setTimeout(resolve, 5000));
operation = await ai.operations.get({ operation: operation });
}
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Can you tell me about [insert question]",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name]
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text') {
console.log(contentBlock.text);
}
}
}
}
}
run();
詳しくは、importFile の API リファレンスをご覧ください。
チャンク構成
ファイルをファイル検索ストアにインポートすると、ファイルは自動的にチャンクに分割され、埋め込み、インデックス登録され、ファイル検索ストアにアップロードされます。チャンク分割戦略をより細かく制御する必要がある場合は、chunking_config 設定を指定して、チャンクあたりの最大トークン数と重複するトークンの最大数を設定できます。
Python
from google import genai
from google.genai import types
import time
client = genai.Client()
operation = client.file_search_stores.upload_to_file_search_store(
file_search_store_name=file_search_store.name,
file='sample.txt',
config={
'chunking_config': {
'white_space_config': {
'max_tokens_per_chunk': 200,
'max_overlap_tokens': 20
}
}
}
)
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
print("Custom chunking complete.")
JavaScript
const { GoogleGenAI } = require('@google/genai');
const ai = new GoogleGenAI({});
let operation = await ai.fileSearchStores.uploadToFileSearchStore({
file: 'file.txt',
fileSearchStoreName: fileSearchStore.name,
config: {
displayName: 'file-name',
chunkingConfig: {
whiteSpaceConfig: {
maxTokensPerChunk: 200,
maxOverlapTokens: 20
}
}
}
});
while (!operation.done) {
await new Promise(resolve => setTimeout(resolve, 5000));
operation = await ai.operations.get({ operation });
}
console.log("Custom chunking complete.");
ファイル検索ストアを使用するには、アップロードとインポートの例に示すように、ツールとして interactions.create メソッドに渡します。
仕組み
ファイル検索では、セマンティック検索と呼ばれる手法を使用して、ユーザーのプロンプトに関連する情報を見つけます。標準的なキーワード ベースの検索とは異なり、セマンティック検索はクエリの意味とコンテキストを理解します。
ファイルをインポートすると、アップロードされたコンテンツのセマンティックな意味を捉えたエンベディングと呼ばれる数値表現に変換されます。これらのエンベディングは、専用のファイル検索データベースに保存されます。クエリを行うと、クエリもエンベディングに変換されます。次に、システムはファイル検索を実行して、ファイル検索ストアから最も類似した関連性の高いドキュメント チャンクを見つけます。
エンベディングには有効期間(TTL)はありません。手動で削除されるか、モデルが非推奨になるまで保持されます。ただし、ファイルは 48 時間後に削除されます。
ファイル検索 uploadToFileSearchStore API を使用する手順は次のとおりです。
ファイル検索ストアを作成する: ファイル検索ストアには、ファイルから処理されたデータが含まれます。これは、セマンティック検索が動作するエンベディングの永続コンテナです。
ファイルをアップロードしてファイル検索ストアにインポートする: ファイルをアップロードすると同時に、結果をファイル検索ストアにインポートします。これにより、未加工ドキュメントへの参照である一時的な
Fileオブジェクトが作成されます。このデータはチャンク化され、ファイル検索エンベディングに変換されて、インデックスが作成されます。Fileオブジェクトは 48 時間後に削除されますが、ファイル検索ストアにインポートされたデータは、削除するまで無期限に保存されます。ファイル検索でクエリを実行する: 最後に、
generateContent呼び出しでFileSearchツールを使用します。ツール構成で、検索するFileSearchStoreを指すFileSearchRetrievalResourceを指定します。これにより、モデルは特定のファイル検索ストアに対してセマンティック検索を実行し、回答のグラウンディングに関連する情報を検索します。
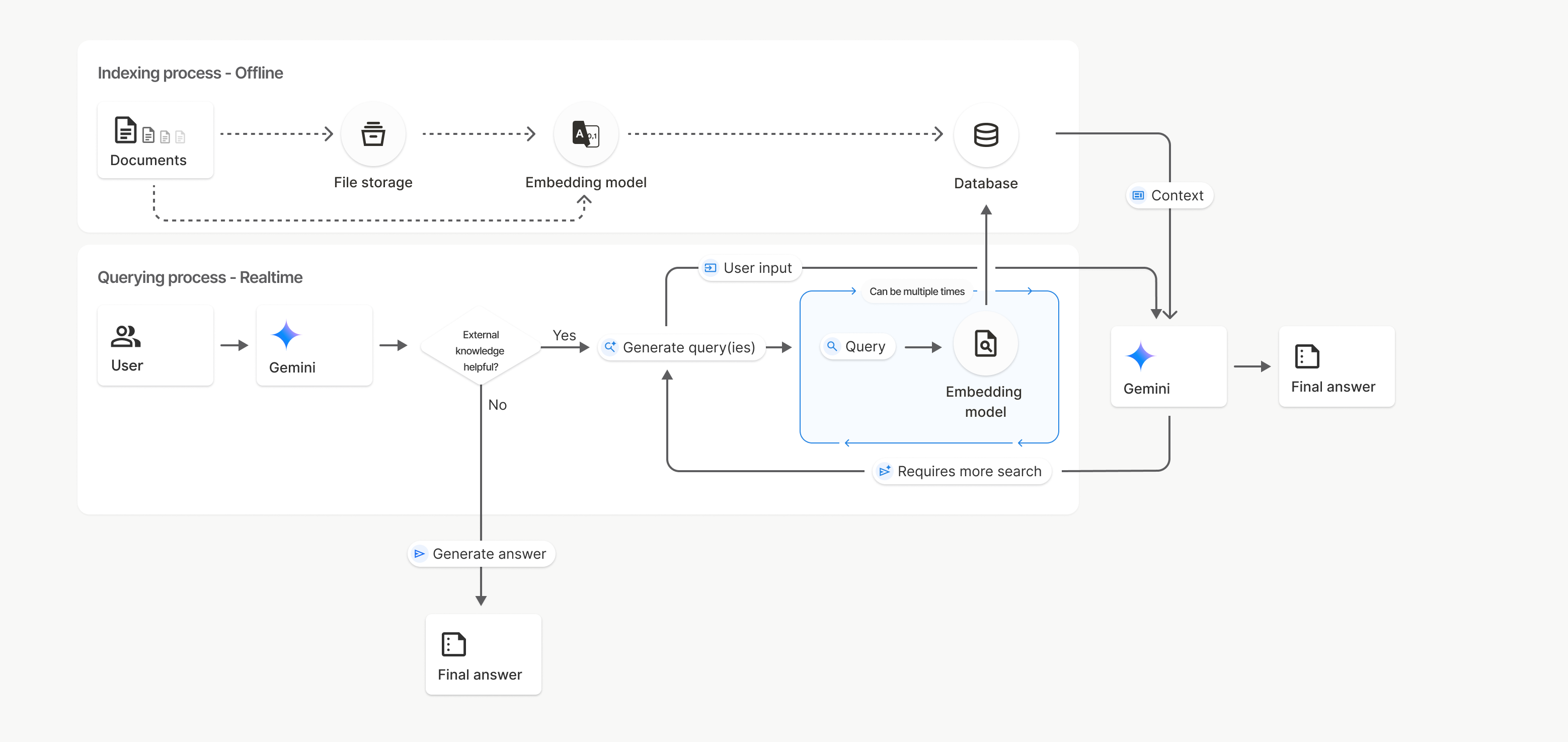
この図では、ドキュメントからエンベディング モデル(gemini-embedding-001 を使用)への点線は、uploadToFileSearchStore API(ファイル ストレージをバイパス)を表しています。それ以外の場合、Files API を使用してファイルを個別に作成してからインポートすると、インデックス登録プロセスが ドキュメントから ファイル ストレージ、エンベディング モデルに移動します。
ファイル検索ストア
ファイル検索ストアは、ドキュメント エンベディングのコンテナです。File API を介してアップロードされた未加工ファイルは 48 時間後に削除されますが、ファイル検索ストアにインポートされたデータは、手動で削除するまで無期限に保存されます。複数のファイル検索ストアを作成して、ドキュメントを整理できます。FileSearchStore API を使用すると、ファイル検索ストアの作成、一覧表示、取得、削除を行って管理できます。ファイル検索のストア名はグローバル スコープです。
ファイル検索ストアの管理方法の例を次に示します。
Python
file_search_store = client.file_search_stores.create(
config={
'display_name': 'my-file_search-store-123',
'embedding_model': 'models/gemini-embedding-2'
}
)
for file_search_store in client.file_search_stores.list():
print(file_search_store)
my_file_search_store = client.file_search_stores.get(name='fileSearchStores/my-file_search-store-123')
client.file_search_stores.delete(name='fileSearchStores/my-file_search-store-123', config={'force': True})
JavaScript
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: 'my-file_search-store-123',
embeddingModel: 'models/gemini-embedding-2'
}
});
const fileSearchStores = await ai.fileSearchStores.list();
for await (const store of fileSearchStores) {
console.log(store);
}
const myFileSearchStore = await ai.fileSearchStores.get({
name: 'fileSearchStores/my-file_search-store-123'
});
await ai.fileSearchStores.delete({
name: 'fileSearchStores/my-file_search-store-123',
config: { force: true }
});
REST
curl -X POST "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=${GEMINI_API_KEY}" \
-H "Content-Type: application/json" \
-d '{ "displayName": "My Store", "embedding_model": "models/gemini-embedding-2" }'
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=${GEMINI_API_KEY}" \
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123?key=${GEMINI_API_KEY}"
curl -X DELETE "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123?key=${GEMINI_API_KEY}"
ファイル検索のドキュメント
ファイル検索ドキュメント API を使用して、ファイル ストア内の個々のドキュメントを管理できます。この API を使用すると、ファイル検索ストア内の各ドキュメントの list、ドキュメントに関する情報の get、名前によるドキュメントの delete を行うことができます。
Python
for document_in_store in client.file_search_stores.documents.list(parent='fileSearchStores/my-file_search-store-123'):
print(document_in_store)
file_search_document = client.file_search_stores.documents.get(name='fileSearchStores/my-file_search-store-123/documents/my_doc')
print(file_search_document)
client.file_search_stores.documents.delete(name='fileSearchStores/my-file_search-store-123/documents/my_doc', config={'force': True})
JavaScript
const documents = await ai.fileSearchStores.documents.list({
parent: 'fileSearchStores/my-file_search-store-123'
});
for await (const doc of documents) {
console.log(doc);
}
const fileSearchDocument = await ai.fileSearchStores.documents.get({
name: 'fileSearchStores/my-file_search-store-123/documents/my_doc'
});
await ai.fileSearchStores.documents.delete({
name: 'fileSearchStores/my-file_search-store-123/documents/my_doc'
});
REST
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123/documents?key=${GEMINI_API_KEY}"
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123/documents/my_doc?key=${GEMINI_API_KEY}"
curl -X DELETE "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123/documents/my_doc?key=${GEMINI_API_KEY}&force=true"
ファイルのメタデータ
ファイルにカスタム メタデータを追加すると、ファイルをフィルタしたり、追加のコンテキストを提供したりするのに役立ちます。メタデータは Key-Value ペアのセットです。
Python
op = client.file_search_stores.import_file(
file_search_store_name=file_search_store.name,
file_name=sample_file.name,
config={
'custom_metadata': [
{"key": "author", "string_value": "Robert Graves"},
{"key": "year", "numeric_value": 1934}
]
}
)
JavaScript
let operation = await ai.fileSearchStores.importFile({
fileSearchStoreName: fileSearchStore.name,
fileName: sampleFile.name,
config: {
customMetadata: [
{ key: "author", stringValue: "Robert Graves" },
{ key: "year", numericValue: 1934 }
]
}
});
これは、ファイル検索ストアに複数のドキュメントがあり、そのサブセットのみを検索する場合に便利です。
Python
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Tell me about the book 'I, Claudius'",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name],
"metadata_filter": 'author="Robert Graves"',
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Tell me about the book 'I, Claudius'",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name],
metadata_filter: 'author="Robert Graves"',
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text') {
console.log(contentBlock.text);
}
}
}
}
REST
curl "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"model": "gemini-3.5-flash",
"input": [{"type": "text", "text": "Tell me about the book I, Claudius"}],
"tools": [{
"type": "file_search",
"file_search_store_names": ["'$STORE_NAME'"],
"metadata_filter": "author = \"Robert Graves\""
}]
}' 2> /dev/null > response.json
cat response.json
metadata_filter のリストフィルタ構文の実装に関するガイダンスについては、google.aip.dev/160 をご覧ください。
マルチモーダル ファイル検索
マルチモーダル ファイル検索を使用すると、画像をネイティブに埋め込んで検索できるため、リッチなマルチモーダル RAG アプリケーションを構築できます。
エンベディング モデルを構成する
FileSearchStore を作成する場合は、デフォルトのテキストのみのエンベディング モデルをオーバーライドして、マルチモーダル モデルを使用する必要があります。models/gemini-embedding-2 を使用して、テキストと画像の両方を処理します。
Python
store = client.file_search_stores.create(
config={
"display_name": "Multimodal Catalog",
"embedding_model": "models/gemini-embedding-2",
}
)
JavaScript
const fileSearchStore = await ai.fileSearchStores.create({
config: {
displayName: "Multimodal Catalog",
embeddingModel: "models/gemini-embedding-2",
},
});
REST
curl -X POST "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=$GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"display_name": "Multimodal Catalog",
"embedding_model": "models/gemini-embedding-2"
}'
画像のアップロード
マルチモーダル エンベディング モデルを使用してストアを作成したら、ファイル検索ストアに直接アップロードするまたはファイルのインポートで説明されている同じアップロード API を使用して、画像ファイルを直接アップロードできます。
画像ファイルの要件:
- 画像ファイルの解像度は 4K x 4K ピクセル以下にする必要があります。
- サポートされている形式は PNG、JPEG です。
引用
ファイル検索を使用すると、モデルの回答に、アップロードしたドキュメントのどの部分が回答の生成に使用されたかを指定する引用が含まれることがあります。これにより、ファクト チェックと検証が容易になります。
引用情報には、レスポンスの model_output ステップの content ブロック内の annotations 属性を介してアクセスできます。
Python
for step in interaction.steps:
if step.type == 'model_output':
for content in step.content:
if content.type == 'text' and content.annotations:
print(content.annotations)
JavaScript
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.type === 'text' && contentBlock.annotations) {
console.log(JSON.stringify(contentBlock.annotations, null, 2));
}
}
}
}
引用の構造の詳細については、インタラクションの API リファレンスをご覧ください。
ページ番号
ページがあるドキュメント(PDF など)でファイル検索を使用すると、モデルのレスポンスに情報が見つかったページ番号が含まれることがあります。この情報には、file_citation アノテーションの page_number 属性からアクセスできます。
Python
for step in interaction.steps:
if step.type == "model_output":
for content in step.content:
if content.type == "text" and content.annotations:
for annotation in content.annotations:
if annotation.type == "file_citation" and annotation.page_number:
print(f"Cited Page: {annotation.page_number}")
JavaScript
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const block of step.content) {
if (block.type === 'text' && block.annotations) {
for (const annotation of block.annotations) {
if (annotation.type === 'file_citation' && annotation.pageNumber) {
console.log(`Cited Page: ${annotation.pageNumber}`);
}
}
}
}
}
}
メディアでの引用
モデルが生成中に画像チャンクを参照すると、API は media_id を含むアノテーションで file_citation 型のアノテーションを返します。この ID を使用して、モデルが参照した正確な画像チャンクをダウンロードできます。この media_id は複数の検索呼び出しにわたって永続化されるため、ID を使用して同じ画像を確実に取得したり、キャッシュに保存したりできます。
次のスニペットは、REST レスポンス ステップの例です。
{
"type": "model_output",
"content": [
{
"type": "text",
"text": "...",
"annotations": [
{
"type": "file_citation",
"file_name": "product_image",
"media_id": "fileSearchStores/my-store-123/media/BlobId-456"
}
]
}
]
}
次のコード スニペットは、media_id を取得してメディアをダウンロードする方法を示しています。
Python
for step in interaction.steps:
if step.type == "model_output":
for content in step.content:
if content.type == "text" and content.annotations:
for annotation in content.annotations:
if annotation.type == "file_citation" and annotation.media_id:
print(f"Cited Media ID: {annotation.media_id}")
blob_content = client.file_search_stores.download_media(
media_id=annotation.media_id
)
JavaScript
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const block of step.content) {
if (block.type === 'text' && block.annotations) {
for (const annotation of block.annotations) {
if (annotation.type === 'file_citation' && annotation.mediaId) {
console.log(`Cited Media ID: ${annotation.mediaId}`);
const blobContent = await ai.fileSearchStores.downloadMedia(annotation.mediaId);
}
}
}
}
}
}
REST
curl -X GET "https://generativelanguage.googleapis.com/v1/fileSearchStores/my-store-123/media/BlobId-456" \
-H "x-goog-api-key: $GEMINI_API_KEY"
カスタム メタデータ
ファイルにカスタム メタデータを追加した場合は、モデルのレスポンスのアノテーションでアクセスできます。これは、ソースドキュメントからアプリケーション ロジックに追加のコンテキスト(URL、ページ番号、著者など)を渡す場合に便利です。file_citation タイプの各引用アノテーションには、このカスタム メタデータが含まれます。
Python
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Tell me about [insert question]",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}]
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.annotations:
for annotation in content_block.annotations:
print(annotation)
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Tell me about [insert question]",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name]
}]
});
for (const step of interaction.steps) {
if (step.type === 'model_output') {
for (const contentBlock of step.content) {
if (contentBlock.annotations) {
contentBlock.annotations.forEach((annotation) => {
console.log(annotation);
});
}
}
}
}
REST
{
"steps": [
{
"type": "model_output",
"content": [
{
"type": "text",
"text": "...",
"annotations": [
{
"file_name": "...",
"source": "...",
"custom_metadata": [
{
"key": "author",
"string_value": "Robert Graves"
},
{
"key": "year",
"numeric_value": 1934
}
]
}
]
}
]
}
]
}
構造化出力
Gemini 3 モデル以降では、ファイル検索ツールと構造化された出力を組み合わせることができます。
Python
from pydantic import BaseModel, Field
class Money(BaseModel):
amount: str = Field(description="The numerical part of the amount.")
currency: str = Field(description="The currency of amount.")
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="What is the minimum hourly wage in Tokyo right now?",
tools=[{
"type": "file_search",
"file_search_store_names": [file_search_store.name]
}],
response_format={
"type": "text",
"mime_type": "application/json",
"schema": Money.model_json_schema()
},
)
result = Money.model_validate_json(interaction.output_text)
print(result)
JavaScript
import { z } from "zod";
const moneyJsonSchema = {
type: "object",
properties: {
amount: { type: "string", description: "The numerical part of the amount." },
currency: { type: "string", description: "The currency of amount." }
},
required: ["amount", "currency"]
};
const moneySchema = z.fromJSONSchema(moneyJsonSchema);
async function run() {
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "What is the minimum hourly wage in Tokyo right now?",
tools: [{
type: "file_search",
file_search_store_names: [fileSearchStore.name],
}],
response_format: {
type: 'text',
mime_type: 'application/json',
schema: moneyJsonSchema
},
});
const result = moneySchema.parse(JSON.parse(interaction.output_text));
console.log(result);
}
run();
REST
curl "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"model": "gemini-3.5-flash",
"input": "What is the minimum hourly wage in Tokyo right now?",
"tools": [{
"type": "file_search",
"file_search_store_names": ["$FILE_SEARCH_STORE_NAME"]
}],
"response_format": {
"type": "text",
"mime_type": "application/json",
"schema": {
"type": "object",
"properties": {
"amount": {"type": "string", "description": "The numerical part of the amount."},
"currency": {"type": "string", "description": "The currency of amount."}
},
"required": ["amount", "currency"]
}
}
}'
サポートされているモデル
次のモデルはファイル検索をサポートしています。
| モデル | ファイル検索 |
|---|---|
| Gemini 3.5 Flash | ✔️ |
| Gemini 3.1 Pro プレビュー版 | ✔️ |
| Gemini 3.1 Flash-Lite | ✔️ |
| Gemini 3 Flash プレビュー | ✔️ |
| Gemini 2.5 Pro | ✔️ |
| Gemini 2.5 Flash-Lite | ✔️ |
サポートされているツールの組み合わせ
Gemini 3 モデルは、組み込みツール(ファイル検索など)とカスタムツール(関数呼び出し)の組み合わせをサポートしています。詳しくは、ツールの組み合わせのページをご覧ください。
サポートされているファイル形式
ファイル検索は、次のセクションに記載されている幅広いファイル形式をサポートしています。
アプリケーション ファイルの種類
application/dartapplication/ecmascriptapplication/jsonapplication/ms-javaapplication/mswordapplication/pdfapplication/sqlapplication/typescriptapplication/vnd.curlapplication/vnd.dartapplication/vnd.ibm.secure-containerapplication/vnd.jupyterapplication/vnd.ms-excelapplication/vnd.oasis.opendocument.textapplication/vnd.openxmlformats-officedocument.presentationml.presentationapplication/vnd.openxmlformats-officedocument.spreadsheetml.sheetapplication/vnd.openxmlformats-officedocument.wordprocessingml.documentapplication/vnd.openxmlformats-officedocument.wordprocessingml.templateapplication/x-cshapplication/x-hwpapplication/x-hwp-v5application/x-latexapplication/x-phpapplication/x-powershellapplication/x-shapplication/x-shellscriptapplication/x-texapplication/x-zshapplication/xmlapplication/zip
テキスト ファイル形式
text/1d-interleaved-parityfectext/REDtext/SGMLtext/cache-manifesttext/calendartext/cqltext/cql-extensiontext/cql-identifiertext/csstext/csvtext/csv-schematext/dnstext/encaprtptext/enrichedtext/exampletext/fhirpathtext/flexfectext/fwdredtext/gff3text/grammar-ref-listtext/hl7v2text/htmltext/javascripttext/jcr-cndtext/jsxtext/markdowntext/mizartext/n3text/parameterstext/parityfectext/phptext/plaintext/provenance-notationtext/prs.fallenstein.rsttext/prs.lines.tagtext/prs.prop.logictext/raptorfectext/rfc822-headerstext/rtftext/rtp-enc-aescm128text/rtploopbacktext/rtxtext/sgmltext/shaclctext/shextext/spdxtext/stringstext/t140text/tab-separated-valuestext/texmacstext/trofftext/tsvtext/tsxtext/turtletext/ulpfectext/uri-listtext/vcardtext/vnd.DMClientScripttext/vnd.IPTC.NITFtext/vnd.IPTC.NewsMLtext/vnd.atext/vnd.abctext/vnd.ascii-arttext/vnd.curltext/vnd.debian.copyrighttext/vnd.dvb.subtitletext/vnd.esmertec.theme-descriptortext/vnd.exchangeabletext/vnd.familysearch.gedcomtext/vnd.ficlab.flttext/vnd.flytext/vnd.fmi.flexstortext/vnd.gmltext/vnd.graphviztext/vnd.hanstext/vnd.hgltext/vnd.in3d.3dmltext/vnd.in3d.spottext/vnd.latex-ztext/vnd.motorola.reflextext/vnd.ms-mediapackagetext/vnd.net2phone.commcenter.commandtext/vnd.radisys.msml-basic-layouttext/vnd.senx.warpscripttext/vnd.sositext/vnd.sun.j2me.app-descriptortext/vnd.trolltech.linguisttext/vnd.wap.sitext/vnd.wap.sltext/vnd.wap.wmltext/vnd.wap.wmlscripttext/vtttext/wgsltext/x-asmtext/x-bibtextext/x-bootext/x-ctext/x-c++hdrtext/x-c++srctext/x-cassandratext/x-chdrtext/x-coffeescripttext/x-componenttext/x-cshtext/x-csharptext/x-csrctext/x-cudatext/x-dtext/x-difftext/x-dsrctext/x-emacs-lisptext/x-erlangtext/x-gff3text/x-gotext/x-haskelltext/x-javatext/x-java-propertiestext/x-java-sourcetext/x-kotlintext/x-lilypondtext/x-lisptext/x-literate-haskelltext/x-luatext/x-moctext/x-objcsrctext/x-pascaltext/x-pcs-gcdtext/x-perltext/x-perl-scripttext/x-pythontext/x-python-scripttext/x-r-markdowntext/x-rsrctext/x-rsttext/x-ruby-scripttext/x-rusttext/x-sasstext/x-scalatext/x-schemetext/x-script.pythontext/x-scsstext/x-setexttext/x-sfvtext/x-shtext/x-siestatext/x-sostext/x-sqltext/x-swifttext/x-tcltext/x-textext/x-vbasictext/x-vcalendartext/xmltext/xml-dtdtext/xml-external-parsed-entitytext/yaml
制限事項
- Live API: Live API ではファイル検索はサポートされていません。
- ツールの互換性: 現時点では、ファイル検索を Google 検索によるグラウンディングや URL コンテキストなどの他のツールと組み合わせることはできません。
レート上限
File Search API には、サービスの安定性を維持するため、次の制限が適用されます。
- 最大ファイルサイズ / ドキュメントあたりの上限: 100 MB
- プロジェクト ファイル検索ストアの合計サイズ(ユーザーの階層に基づく):
- 無料: 1 GB
- Tier 1: 10 GB
- Tier 2: 100 GB
- Tier 3: 1 TB
- 推奨事項: 最適な取得レイテンシを確保するため、各ファイル検索ストアのサイズを 20 GB 未満に制限します。
料金
- エンベディングの料金は、既存のエンベディングの料金に基づいて、インデックス登録時に請求されます。
- ストレージは無料です。
- クエリタイム エンベディングは無料です。
- 取得したドキュメント トークンは、通常のコンテキスト トークンとして課金されます。