-








-
Generated by Nano Banana Pro Prompt: "Present a clear, 45° top-down isometric miniature 3D cartoon scene of London, featuring its most iconic landmarks and architectural elements. Use soft, refined textures with realistic PBR materials and gentle, lifelike lighting and shadows. Integrate the current weather conditions directly into the city environment to create an immersive atmospheric mood. Use a clean, minimalistic composition with a soft, solid-colored background. At the top-center, place the title "London" in large bold text, a prominent weather icon beneath it, then the date (small text) and temperature (medium text). All text must be centered with consistent spacing, and may subtly overlap the tops of the buildings."Learn more about search grounding and try it in AI Studio -

Generated by Nano Banana Pro Prompt: "Put this logo on a high-end ad for a banana scented perfume. The logo is perfectly integrated into the bottle."Try Nano Banana's high fidelity detail preservation in AI Studio -

Generated by Nano Banana Pro Prompt: "Faithfully restore this image with high fidelity to modern photograph quality, in full color, upscale to 4K"Generate images in up to 4K resolution. Try Nano Banana AI Studio -
Generated by Nano Banana Pro Prompt: "A photo of a glossy magazine cover, the cover has the large bold words "Nano Banana Pro". The text is in a serif font and fills the view. No other text. In front of the text there is a portrait of a person in a beautiful outfit. Put the issue number and today's date in the corner along with a barcode and a price. The magazine is on a shelf against a brick wall, within a designer store. A mannequin is wearing the same outfit."Create professional product shots in AI Studio -
Generated by Nano Banana Pro Prompt: "Use search to find how the Gemini 3 Flash launch has been received. Use this information to write a short article about it (with headings). Return a photo of the article as it appeared in a design focused glossy magazine. It is a photo of a single folded over page, showing the article about Gemini 3 Flash. One hero photo. Headline in serif." -
Generated by Nano Banana Pro Prompt: "A photo of an everyday scene at a busy cafe serving breakfast. In the foreground is an anime man with blue hair, one of the people is a pencil sketch, another is a claymation person"Experiment with different artistic styles with Nano Banana in AI Studio -
Generated by Nano Banana Pro Prompt: "An icon representing a cute dog. The background is white. Make the icons in a colorful and tactile 3D style. No text."Create icons, stickers, and assets with Nano Banana in AI Studio -
Generated by Nano Banana Pro Prompt: "Make a photo that is perfectly isometric. It is not a miniature, it is a captured photo that just happened to be perfectly isometric. It is a photo of a beautiful modern office interior."
Nano Banana is the name for Gemini's native image generation capabilities. Gemini can generate and process images conversationally with text, images, or a combination of both. This lets you create, edit, and iterate on visuals with unprecedented control.
Nano Banana refers to two distinct models available in the Gemini API:
- Nano Banana: The Gemini 2.5 Flash Image
model (
gemini-2.5-flash-image). This model is designed for speed and efficiency, optimized for high-volume, low-latency tasks. - Nano Banana Pro: The Gemini 3 Pro Image Preview
model (
gemini-3-pro-image-preview). This model is designed for professional asset production, utilizing advanced reasoning ("Thinking") to follow complex instructions and render high-fidelity text.
All generated images include a SynthID watermark.
Image generation (text-to-image)
Python
from google import genai
from google.genai import types
from PIL import Image
client = genai.Client()
prompt = ("Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme")
response = client.models.generate_content(
model="gemini-2.5-flash-image",
contents=[prompt],
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save("generated_image.png")
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const prompt =
"Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme";
const response = await ai.models.generateContent({
model: "gemini-2.5-flash-image",
contents: prompt,
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("gemini-native-image.png", buffer);
console.log("Image saved as gemini-native-image.png");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-2.5-flash-image",
genai.Text("Create a picture of a nano banana dish in a " +
" fancy restaurant with a Gemini theme"),
)
for _, part := range result.Candidates[0].Content.Parts {
if part.Text != "" {
fmt.Println(part.Text)
} else if part.InlineData != nil {
imageBytes := part.InlineData.Data
outputFilename := "gemini_generated_image.png"
_ = os.WriteFile(outputFilename, imageBytes, 0644)
}
}
}
Java
import com.google.genai.Client;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.Part;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class TextToImage {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-2.5-flash-image",
"Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme",
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("_01_generated_image.png"), blob.data().get());
}
}
}
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{
"parts": [
{"text": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme"}
]
}]
}'
Image editing (text-and-image-to-image)
Reminder: Make sure you have the necessary rights to any images you upload. Don't generate content that infringe on others' rights, including videos or images that deceive, harass, or harm. Your use of this generative AI service is subject to our Prohibited Use Policy.
Provide an image and use text prompts to add, remove, or modify elements, change the style, or adjust the color grading.
The following example demonstrates uploading base64 encoded images.
For multiple images, larger payloads, and supported MIME types, check the Image
understanding page.
Python
from google import genai
from google.genai import types
from PIL import Image
client = genai.Client()
prompt = (
"Create a picture of my cat eating a nano-banana in a "
"fancy restaurant under the Gemini constellation",
)
image = Image.open("/path/to/cat_image.png")
response = client.models.generate_content(
model="gemini-2.5-flash-image",
contents=[prompt, image],
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save("generated_image.png")
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "path/to/cat_image.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const prompt = [
{ text: "Create a picture of my cat eating a nano-banana in a" +
"fancy restaurant under the Gemini constellation" },
{
inlineData: {
mimeType: "image/png",
data: base64Image,
},
},
];
const response = await ai.models.generateContent({
model: "gemini-2.5-flash-image",
contents: prompt,
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("gemini-native-image.png", buffer);
console.log("Image saved as gemini-native-image.png");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
imagePath := "/path/to/cat_image.png"
imgData, _ := os.ReadFile(imagePath)
parts := []*genai.Part{
genai.NewPartFromText("Create a picture of my cat eating a nano-banana in a fancy restaurant under the Gemini constellation"),
&genai.Part{
InlineData: &genai.Blob{
MIMEType: "image/png",
Data: imgData,
},
},
}
contents := []*genai.Content{
genai.NewContentFromParts(parts, genai.RoleUser),
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-2.5-flash-image",
contents,
)
for _, part := range result.Candidates[0].Content.Parts {
if part.Text != "" {
fmt.Println(part.Text)
} else if part.InlineData != nil {
imageBytes := part.InlineData.Data
outputFilename := "gemini_generated_image.png"
_ = os.WriteFile(outputFilename, imageBytes, 0644)
}
}
}
Java
import com.google.genai.Client;
import com.google.genai.types.Content;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.Part;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
public class TextAndImageToImage {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-2.5-flash-image",
Content.fromParts(
Part.fromText("""
Create a picture of my cat eating a nano-banana in
a fancy restaurant under the Gemini constellation
"""),
Part.fromBytes(
Files.readAllBytes(
Path.of("src/main/resources/cat.jpg")),
"image/jpeg")),
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("gemini_generated_image.png"), blob.data().get());
}
}
}
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"contents\": [{
\"parts\":[
{\"text\": \"'Create a picture of my cat eating a nano-banana in a fancy restaurant under the Gemini constellation\"},
{
\"inline_data\": {
\"mime_type\":\"image/jpeg\",
\"data\": \"<BASE64_IMAGE_DATA>\"
}
}
]
}]
}"
Multi-turn image editing
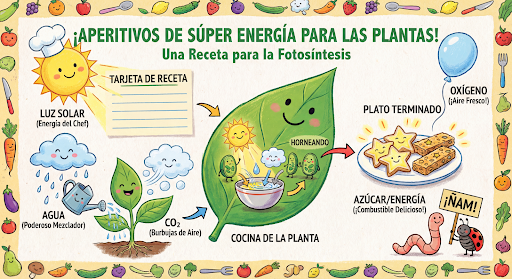
Keep generating and editing images conversationally. Chat or multi-turn conversation is the recommended way to iterate on images. The following example shows a prompt to generate an infographic about photosynthesis.
Python
from google import genai
from google.genai import types
client = genai.Client()
chat = client.chats.create(
model="gemini-3-pro-image-preview",
config=types.GenerateContentConfig(
response_modalities=['TEXT', 'IMAGE'],
tools=[{"google_search": {}}]
)
)
message = "Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plant's favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids' cookbook, suitable for a 4th grader."
response = chat.send_message(message)
for part in response.parts:
if part.text is not None:
print(part.text)
elif image:= part.as_image():
image.save("photosynthesis.png")
Javascript
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({});
async function main() {
const chat = ai.chats.create({
model: "gemini-3-pro-image-preview",
config: {
responseModalities: ['TEXT', 'IMAGE'],
tools: [{googleSearch: {}}],
},
});
await main();
const message = "Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plant's favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids' cookbook, suitable for a 4th grader."
let response = await chat.sendMessage({message});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("photosynthesis.png", buffer);
console.log("Image saved as photosynthesis.png");
}
}
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
defer client.Close()
model := client.GenerativeModel("gemini-3-pro-image-preview")
model.GenerationConfig = &pb.GenerationConfig{
ResponseModalities: []pb.ResponseModality{genai.Text, genai.Image},
}
chat := model.StartChat()
message := "Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plant's favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids' cookbook, suitable for a 4th grader."
resp, err := chat.SendMessage(ctx, genai.Text(message))
if err != nil {
log.Fatal(err)
}
for _, part := range resp.Candidates[0].Content.Parts {
if txt, ok := part.(genai.Text); ok {
fmt.Printf("%s", string(txt))
} else if img, ok := part.(genai.ImageData); ok {
err := os.WriteFile("photosynthesis.png", img.Data, 0644)
if err != nil {
log.Fatal(err)
}
}
}
}
Java
import com.google.genai.Chat;
import com.google.genai.Client;
import com.google.genai.types.Content;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.GoogleSearch;
import com.google.genai.types.ImageConfig;
import com.google.genai.types.Part;
import com.google.genai.types.RetrievalConfig;
import com.google.genai.types.Tool;
import com.google.genai.types.ToolConfig;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
public class MultiturnImageEditing {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.tools(Tool.builder()
.googleSearch(GoogleSearch.builder().build())
.build())
.build();
Chat chat = client.chats.create("gemini-3-pro-image-preview", config);
GenerateContentResponse response = chat.sendMessage("""
Create a vibrant infographic that explains photosynthesis
as if it were a recipe for a plant's favorite food.
Show the "ingredients" (sunlight, water, CO2)
and the "finished dish" (sugar/energy).
The style should be like a page from a colorful
kids' cookbook, suitable for a 4th grader.
""");
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("photosynthesis.png"), blob.data().get());
}
}
}
// ...
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-image-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{
"role": "user",
"parts": [
{"text": "Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plants favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids cookbook, suitable for a 4th grader."}
]
}],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"]
}
}'

You can then use the same chat to change the language on the graphic to Spanish.
Python
message = "Update this infographic to be in Spanish. Do not change any other elements of the image."
aspect_ratio = "16:9" # "1:1","2:3","3:2","3:4","4:3","4:5","5:4","9:16","16:9","21:9"
resolution = "2K" # "1K", "2K", "4K"
response = chat.send_message(message,
config=types.GenerateContentConfig(
image_config=types.ImageConfig(
aspect_ratio=aspect_ratio,
image_size=resolution
),
))
for part in response.parts:
if part.text is not None:
print(part.text)
elif image:= part.as_image():
image.save("photosynthesis_spanish.png")
Javascript
const message = 'Update this infographic to be in Spanish. Do not change any other elements of the image.';
const aspectRatio = '16:9';
const resolution = '2K';
let response = await chat.sendMessage({
message,
config: {
responseModalities: ['TEXT', 'IMAGE'],
imageConfig: {
aspectRatio: aspectRatio,
imageSize: resolution,
},
tools: [{googleSearch: {}}],
},
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("photosynthesis2.png", buffer);
console.log("Image saved as photosynthesis2.png");
}
}
Go
message = "Update this infographic to be in Spanish. Do not change any other elements of the image."
aspect_ratio = "16:9" // "1:1","2:3","3:2","3:4","4:3","4:5","5:4","9:16","16:9","21:9"
resolution = "2K" // "1K", "2K", "4K"
model.GenerationConfig.ImageConfig = &pb.ImageConfig{
AspectRatio: aspect_ratio,
ImageSize: resolution,
}
resp, err = chat.SendMessage(ctx, genai.Text(message))
if err != nil {
log.Fatal(err)
}
for _, part := range resp.Candidates[0].Content.Parts {
if txt, ok := part.(genai.Text); ok {
fmt.Printf("%s", string(txt))
} else if img, ok := part.(genai.ImageData); ok {
err := os.WriteFile("photosynthesis_spanish.png", img.Data, 0644)
if err != nil {
log.Fatal(err)
}
}
}
Java
String aspectRatio = "16:9"; // "1:1","2:3","3:2","3:4","4:3","4:5","5:4","9:16","16:9","21:9"
String resolution = "2K"; // "1K", "2K", "4K"
config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.imageConfig(ImageConfig.builder()
.aspectRatio(aspectRatio)
.imageSize(resolution)
.build())
.build();
response = chat.sendMessage(
"Update this infographic to be in Spanish. " +
"Do not change any other elements of the image.",
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("photosynthesis_spanish.png"), blob.data().get());
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-image-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"contents": [
{
"role": "user",
"parts": [{"text": "Create a vibrant infographic that explains photosynthesis..."}]
},
{
"role": "model",
"parts": [{"inline_data": {"mime_type": "image/png", "data": "<PREVIOUS_IMAGE_DATA>"}}]
},
{
"role": "user",
"parts": [{"text": "Update this infographic to be in Spanish. Do not change any other elements of the image."}]
}
],
"tools": [{"google_search": {}}],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"],
"imageConfig": {
"aspectRatio": "16:9",
"imageSize": "2K"
}
}
}'
New with Gemini 3 Pro Image
Gemini 3 Pro Image (gemini-3-pro-image-preview) is a state-of-the-art image
generation and editing model optimized for professional asset production.
Designed to tackle the most challenging workflows through advanced reasoning, it
excels at complex, multi-turn creation and modification tasks.
- High-resolution output: Built-in generation capabilities for 1K, 2K, and 4K visuals.
- Advanced text rendering: Capable of generating legible, stylized text for infographics, menus, diagrams, and marketing assets.
- Grounding with Google Search: The model can use Google Search as a tool to verify facts and generate imagery based on real-time data (e.g., current weather maps, stock charts, recent events).
- Thinking mode: The model utilizes a "thinking" process to reason through complex prompts. It generates interim "thought images" (visible in the backend but not charged) to refine the composition before producing the final high-quality output.
- Up to 14 reference images: You can now mix up to 14 reference images to produce the final image.
Use up to 14 reference images
Gemini 3 Pro Preview lets you to mix up to 14 reference images. These 14 images can include the following:
- Up to 6 images of objects with high-fidelity to include in the final image
Up to 5 images of humans to maintain character consistency
Python
from google import genai
from google.genai import types
from PIL import Image
prompt = "An office group photo of these people, they are making funny faces."
aspect_ratio = "5:4" # "1:1","2:3","3:2","3:4","4:3","4:5","5:4","9:16","16:9","21:9"
resolution = "2K" # "1K", "2K", "4K"
client = genai.Client()
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=[
prompt,
Image.open('person1.png'),
Image.open('person2.png'),
Image.open('person3.png'),
Image.open('person4.png'),
Image.open('person5.png'),
],
config=types.GenerateContentConfig(
response_modalities=['TEXT', 'IMAGE'],
image_config=types.ImageConfig(
aspect_ratio=aspect_ratio,
image_size=resolution
),
)
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif image:= part.as_image():
image.save("office.png")
Javascript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const prompt =
'An office group photo of these people, they are making funny faces.';
const aspectRatio = '5:4';
const resolution = '2K';
const contents = [
{ text: prompt },
{
inlineData: {
mimeType: "image/jpeg",
data: base64ImageFile1,
},
},
{
inlineData: {
mimeType: "image/jpeg",
data: base64ImageFile2,
},
},
{
inlineData: {
mimeType: "image/jpeg",
data: base64ImageFile3,
},
},
{
inlineData: {
mimeType: "image/jpeg",
data: base64ImageFile4,
},
},
{
inlineData: {
mimeType: "image/jpeg",
data: base64ImageFile5,
},
}
];
const response = await ai.models.generateContent({
model: 'gemini-3-pro-image-preview',
contents: contents,
config: {
responseModalities: ['TEXT', 'IMAGE'],
imageConfig: {
aspectRatio: aspectRatio,
imageSize: resolution,
},
},
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("image.png", buffer);
console.log("Image saved as image.png");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
defer client.Close()
model := client.GenerativeModel("gemini-3-pro-image-preview")
model.GenerationConfig = &pb.GenerationConfig{
ResponseModalities: []pb.ResponseModality{genai.Text, genai.Image},
ImageConfig: &pb.ImageConfig{
AspectRatio: "5:4",
ImageSize: "2K",
},
}
img1, err := os.ReadFile("person1.png")
if err != nil { log.Fatal(err) }
img2, err := os.ReadFile("person2.png")
if err != nil { log.Fatal(err) }
img3, err := os.ReadFile("person3.png")
if err != nil { log.Fatal(err) }
img4, err := os.ReadFile("person4.png")
if err != nil { log.Fatal(err) }
img5, err := os.ReadFile("person5.png")
if err != nil { log.Fatal(err) }
parts := []genai.Part{
genai.Text("An office group photo of these people, they are making funny faces."),
genai.ImageData{MIMEType: "image/png", Data: img1},
genai.ImageData{MIMEType: "image/png", Data: img2},
genai.ImageData{MIMEType: "image/png", Data: img3},
genai.ImageData{MIMEType: "image/png", Data: img4},
genai.ImageData{MIMEType: "image/png", Data: img5},
}
resp, err := model.GenerateContent(ctx, parts...)
if err != nil {
log.Fatal(err)
}
for _, part := range resp.Candidates[0].Content.Parts {
if txt, ok := part.(genai.Text); ok {
fmt.Printf("%s", string(txt))
} else if img, ok := part.(genai.ImageData); ok {
err := os.WriteFile("office.png", img.Data, 0644)
if err != nil {
log.Fatal(err)
}
}
}
}
Java
import com.google.genai.Client;
import com.google.genai.types.Content;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.ImageConfig;
import com.google.genai.types.Part;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
public class GroupPhoto {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.imageConfig(ImageConfig.builder()
.aspectRatio("5:4")
.imageSize("2K")
.build())
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-3-pro-image-preview",
Content.fromParts(
Part.fromText("An office group photo of these people, they are making funny faces."),
Part.fromBytes(Files.readAllBytes(Path.of("person1.png")), "image/png"),
Part.fromBytes(Files.readAllBytes(Path.of("person2.png")), "image/png"),
Part.fromBytes(Files.readAllBytes(Path.of("person3.png")), "image/png"),
Part.fromBytes(Files.readAllBytes(Path.of("person4.png")), "image/png"),
Part.fromBytes(Files.readAllBytes(Path.of("person5.png")), "image/png")
), config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("office.png"), blob.data().get());
}
}
}
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-image-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"contents\": [{
\"parts\":[
{\"text\": \"An office group photo of these people, they are making funny faces.\"},
{\"inline_data\": {\"mime_type\":\"image/png\", \"data\": \"<BASE64_DATA_IMG_1>\"}},
{\"inline_data\": {\"mime_type\":\"image/png\", \"data\": \"<BASE64_DATA_IMG_2>\"}},
{\"inline_data\": {\"mime_type\":\"image/png\", \"data\": \"<BASE64_DATA_IMG_3>\"}},
{\"inline_data\": {\"mime_type\":\"image/png\", \"data\": \"<BASE64_DATA_IMG_4>\"}},
{\"inline_data\": {\"mime_type\":\"image/png\", \"data\": \"<BASE64_DATA_IMG_5>\"}}
]
}],
\"generationConfig\": {
\"responseModalities\": [\"TEXT\", \"IMAGE\"],
\"imageConfig\": {
\"aspectRatio\": \"5:4\",
\"imageSize\": \"2K\"
}
}
}"

Grounding with Google Search
Use the Google Search tool to generate images based on real-time information, such as weather forecasts, stock charts, or recent events.
Note that when using Grounding with Google Search with image generation, image-based search results are not passed to the generation model and are excluded from the response.
Python
from google import genai
prompt = "Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day"
aspect_ratio = "16:9" # "1:1","2:3","3:2","3:4","4:3","4:5","5:4","9:16","16:9","21:9"
client = genai.Client()
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=prompt,
config=types.GenerateContentConfig(
response_modalities=['Text', 'Image'],
image_config=types.ImageConfig(
aspect_ratio=aspect_ratio,
),
tools=[{"google_search": {}}]
)
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif image:= part.as_image():
image.save("weather.png")
Javascript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const prompt = 'Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day';
const aspectRatio = '16:9';
const resolution = '2K';
const response = await ai.models.generateContent({
model: 'gemini-3-pro-image-preview',
contents: prompt,
config: {
responseModalities: ['TEXT', 'IMAGE'],
imageConfig: {
aspectRatio: aspectRatio,
imageSize: resolution,
},
tools: [{ googleSearch: {} }]
},
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("image.png", buffer);
console.log("Image saved as image.png");
}
}
}
main();
Java
import com.google.genai.Client;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.GoogleSearch;
import com.google.genai.types.ImageConfig;
import com.google.genai.types.Part;
import com.google.genai.types.Tool;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class SearchGrounding {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.imageConfig(ImageConfig.builder()
.aspectRatio("16:9")
.build())
.tools(Tool.builder()
.googleSearch(GoogleSearch.builder().build())
.build())
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-3-pro-image-preview", """
Visualize the current weather forecast for the next 5 days
in San Francisco as a clean, modern weather chart.
Add a visual on what I should wear each day
""",
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("weather.png"), blob.data().get());
}
}
}
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-image-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{"parts": [{"text": "Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day"}]}],
"tools": [{"google_search": {}}],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"],
"imageConfig": {"aspectRatio": "16:9"}
}
}'

The response includes groundingMetadata which contains the following required
fields:
searchEntryPoint: Contains the HTML and CSS to render the required search suggestions.groundingChunks: Returns the top 3 web sources used to ground the generated image
Generate images up to 4K resolution
Gemini 3 Pro Image generates 1K images by default but can also output 2K and 4K
images. To generate higher resolution assets, specify the image_size in the
generation_config.
You must use an uppercase 'K' (e.g., 1K, 2K, 4K). Lowercase parameters (e.g., 1k) will be rejected.
Python
from google import genai
from google.genai import types
prompt = "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English."
aspect_ratio = "1:1" # "1:1","2:3","3:2","3:4","4:3","4:5","5:4","9:16","16:9","21:9"
resolution = "1K" # "1K", "2K", "4K"
client = genai.Client()
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=prompt,
config=types.GenerateContentConfig(
response_modalities=['TEXT', 'IMAGE'],
image_config=types.ImageConfig(
aspect_ratio=aspect_ratio,
image_size=resolution
),
)
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif image:= part.as_image():
image.save("butterfly.png")
Javascript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const prompt =
'Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English.';
const aspectRatio = '1:1';
const resolution = '1K';
const response = await ai.models.generateContent({
model: 'gemini-3-pro-image-preview',
contents: prompt,
config: {
responseModalities: ['TEXT', 'IMAGE'],
imageConfig: {
aspectRatio: aspectRatio,
imageSize: resolution,
},
},
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("image.png", buffer);
console.log("Image saved as image.png");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
defer client.Close()
model := client.GenerativeModel("gemini-3-pro-image-preview")
model.GenerationConfig = &pb.GenerationConfig{
ResponseModalities: []pb.ResponseModality{genai.Text, genai.Image},
ImageConfig: &pb.ImageConfig{
AspectRatio: "1:1",
ImageSize: "1K",
},
}
prompt := "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English."
resp, err := model.GenerateContent(ctx, genai.Text(prompt))
if err != nil {
log.Fatal(err)
}
for _, part := range resp.Candidates[0].Content.Parts {
if txt, ok := part.(genai.Text); ok {
fmt.Printf("%s", string(txt))
} else if img, ok := part.(genai.ImageData); ok {
err := os.WriteFile("butterfly.png", img.Data, 0644)
if err != nil {
log.Fatal(err)
}
}
}
}
Java
import com.google.genai.Client;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.GoogleSearch;
import com.google.genai.types.ImageConfig;
import com.google.genai.types.Part;
import com.google.genai.types.Tool;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class HiRes {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.imageConfig(ImageConfig.builder()
.aspectRatio("16:9")
.imageSize("4K")
.build())
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-3-pro-image-preview", """
Da Vinci style anatomical sketch of a dissected Monarch butterfly.
Detailed drawings of the head, wings, and legs on textured
parchment with notes in English.
""",
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("butterfly.png"), blob.data().get());
}
}
}
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-image-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{"parts": [{"text": "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English."}]}],
"tools": [{"google_search": {}}],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"],
"imageConfig": {"aspectRatio": "1:1", "imageSize": "1K"}
}
}'
The following is an example image generated from this prompt:

Thinking Process
The Gemini 3 Pro Image Preview model is a thinking model and uses a reasoning process ("Thinking") for complex prompts. This feature is enabled by default and cannot be disabled in the API. To learn more about the thinking process, see the Gemini Thinking guide.
The model generates up to two interim images to test composition and logic. The last image within Thinking is also the final rendered image.
You can check the thoughts that lead to the final image being produced.
Python
for part in response.parts:
if part.thought:
if part.text:
print(part.text)
elif image:= part.as_image():
image.show()
Javascript
for (const part of response.candidates[0].content.parts) {
if (part.thought) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, 'base64');
fs.writeFileSync('image.png', buffer);
console.log('Image saved as image.png');
}
}
}
Thought Signatures
Thought signatures are encrypted representations of the
model's internal thought process and are used to preserve reasoning context
across multi-turn interactions. All responses include a thought_signature
field. As a general rule, if you receive a thought signature in a model
response, you should pass it back exactly as received when sending the
conversation history in the next turn. Failure to circulate thought signatures
may cause the response to fail. Check the thought signature
documentation for more explanations of signatures overall.
Here is how thought signatures work:
- All
inline_dataparts with imagemimetypewhich are part of the response should have signature. - If there are some text parts at the beginning (before any image) right after the thoughts, the first text part should also have a signature.
- If
inline_dataparts with imagemimetypeare part of thoughts, they won't have signatures.
The following code shows an example of where thought signatures are included:
[
{
"inline_data": {
"data": "<base64_image_data_0>",
"mime_type": "image/png"
},
"thought": true // Thoughts don't have signatures
},
{
"inline_data": {
"data": "<base64_image_data_1>",
"mime_type": "image/png"
},
"thought": true // Thoughts don't have signatures
},
{
"inline_data": {
"data": "<base64_image_data_2>",
"mime_type": "image/png"
},
"thought": true // Thoughts don't have signatures
},
{
"text": "Here is a step-by-step guide to baking macarons, presented in three separate images.\n\n### Step 1: Piping the Batter\n\nThe first step after making your macaron batter is to pipe it onto a baking sheet. This requires a steady hand to create uniform circles.\n\n",
"thought_signature": "<Signature_A>" // The first non-thought part always has a signature
},
{
"inline_data": {
"data": "<base64_image_data_3>",
"mime_type": "image/png"
},
"thought_signature": "<Signature_B>" // All image parts have a signatures
},
{
"text": "\n\n### Step 2: Baking and Developing Feet\n\nOnce piped, the macarons are baked in the oven. A key sign of a successful bake is the development of \"feet\"—the ruffled edge at the base of each macaron shell.\n\n"
// Follow-up text parts don't have signatures
},
{
"inline_data": {
"data": "<base64_image_data_4>",
"mime_type": "image/png"
},
"thought_signature": "<Signature_C>" // All image parts have a signatures
},
{
"text": "\n\n### Step 3: Assembling the Macaron\n\nThe final step is to pair the cooled macaron shells by size and sandwich them together with your desired filling, creating the classic macaron dessert.\n\n"
},
{
"inline_data": {
"data": "<base64_image_data_5>",
"mime_type": "image/png"
},
"thought_signature": "<Signature_D>" // All image parts have a signatures
}
]
Other image generation modes
Gemini supports other image interaction modes based on prompt structure and context, including:
- Text to image(s) and text (interleaved): Outputs images with related text.
- Example prompt: "Generate an illustrated recipe for a paella."
- Image(s) and text to image(s) and text (interleaved): Uses input images and text to create new related images and text.
- Example prompt: (With an image of a furnished room) "What other color sofas would work in my space? can you update the image?"
Generate images in batch
If you need to generate a lot of images, you can use the Batch API. You get higher rate limits in exchange for a turnaround of up to 24 hours.
Check the Batch API image generation documentation and the cookbook for Batch API image examples and code.
Prompting guide and strategies
Mastering image generation starts with one fundamental principle:
Describe the scene, don't just list keywords. The model's core strength is its deep language understanding. A narrative, descriptive paragraph will almost always produce a better, more coherent image than a list of disconnected words.
Prompts for generating images
The following strategies will help you create effective prompts to generate exactly the images you're looking for.
1. Photorealistic scenes
For realistic images, use photography terms. Mention camera angles, lens types, lighting, and fine details to guide the model toward a photorealistic result.
Template
A photorealistic [shot type] of [subject], [action or expression], set in
[environment]. The scene is illuminated by [lighting description], creating
a [mood] atmosphere. Captured with a [camera/lens details], emphasizing
[key textures and details]. The image should be in a [aspect ratio] format.
Prompt
A photorealistic close-up portrait of an elderly Japanese ceramicist with
deep, sun-etched wrinkles and a warm, knowing smile. He is carefully
inspecting a freshly glazed tea bowl. The setting is his rustic,
sun-drenched workshop. The scene is illuminated by soft, golden hour light
streaming through a window, highlighting the fine texture of the clay.
Captured with an 85mm portrait lens, resulting in a soft, blurred background
(bokeh). The overall mood is serene and masterful. Vertical portrait
orientation.
Python
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-2.5-flash-image",
contents="A photorealistic close-up portrait of an elderly Japanese ceramicist with deep, sun-etched wrinkles and a warm, knowing smile. He is carefully inspecting a freshly glazed tea bowl. The setting is his rustic, sun-drenched workshop with pottery wheels and shelves of clay pots in the background. The scene is illuminated by soft, golden hour light streaming through a window, highlighting the fine texture of the clay and the fabric of his apron. Captured with an 85mm portrait lens, resulting in a soft, blurred background (bokeh). The overall mood is serene and masterful.",
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save("photorealistic_example.png")
Java
import com.google.genai.Client;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.Part;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class PhotorealisticScene {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-2.5-flash-image",
"""
A photorealistic close-up portrait of an elderly Japanese ceramicist
with deep, sun-etched wrinkles and a warm, knowing smile. He is
carefully inspecting a freshly glazed tea bowl. The setting is his
rustic, sun-drenched workshop with pottery wheels and shelves of
clay pots in the background. The scene is illuminated by soft,
golden hour light streaming through a window, highlighting the
fine texture of the clay and the fabric of his apron. Captured
with an 85mm portrait lens, resulting in a soft, blurred
background (bokeh). The overall mood is serene and masterful.
""",
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("photorealistic_example.png"), blob.data().get());
}
}
}
}
}
}
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const prompt =
"A photorealistic close-up portrait of an elderly Japanese ceramicist with deep, sun-etched wrinkles and a warm, knowing smile. He is carefully inspecting a freshly glazed tea bowl. The setting is his rustic, sun-drenched workshop with pottery wheels and shelves of clay pots in the background. The scene is illuminated by soft, golden hour light streaming through a window, highlighting the fine texture of the clay and the fabric of his apron. Captured with an 85mm portrait lens, resulting in a soft, blurred background (bokeh). The overall mood is serene and masterful.";
const response = await ai.models.generateContent({
model: "gemini-2.5-flash-image",
contents: prompt,
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("photorealistic_example.png", buffer);
console.log("Image saved as photorealistic_example.png");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-2.5-flash-image",
genai.Text("A photorealistic close-up portrait of an elderly Japanese ceramicist with deep, sun-etched wrinkles and a warm, knowing smile. He is carefully inspecting a freshly glazed tea bowl. The setting is his rustic, sun-drenched workshop with pottery wheels and shelves of clay pots in the background. The scene is illuminated by soft, golden hour light streaming through a window, highlighting the fine texture of the clay and the fabric of his apron. Captured with an 85mm portrait lens, resulting in a soft, blurred background (bokeh). The overall mood is serene and masterful."),
)
for _, part := range result.Candidates[0].Content.Parts {
if part.Text != "" {
fmt.Println(part.Text)
} else if part.InlineData != nil {
imageBytes := part.InlineData.Data
outputFilename := "photorealistic_example.png"
_ = os.WriteFile(outputFilename, imageBytes, 0644)
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{
"parts": [
{"text": "A photorealistic close-up portrait of an elderly Japanese ceramicist with deep, sun-etched wrinkles and a warm, knowing smile. He is carefully inspecting a freshly glazed tea bowl. The setting is his rustic, sun-drenched workshop with pottery wheels and shelves of clay pots in the background. The scene is illuminated by soft, golden hour light streaming through a window, highlighting the fine texture of the clay and the fabric of his apron. Captured with an 85mm portrait lens, resulting in a soft, blurred background (bokeh). The overall mood is serene and masterful."}
]
}]
}'

2. Stylized illustrations & stickers
To create stickers, icons, or assets, be explicit about the style and request a transparent background.
Template
A [style] sticker of a [subject], featuring [key characteristics] and a
[color palette]. The design should have [line style] and [shading style].
The background must be transparent.
Prompt
A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It's
munching on a green bamboo leaf. The design features bold, clean outlines,
simple cel-shading, and a vibrant color palette. The background must be white.
Python
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-2.5-flash-image",
contents="A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It's munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white.",
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save("red_panda_sticker.png")
Java
import com.google.genai.Client;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.Part;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class StylizedIllustration {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-2.5-flash-image",
"""
A kawaii-style sticker of a happy red panda wearing a tiny bamboo
hat. It's munching on a green bamboo leaf. The design features
bold, clean outlines, simple cel-shading, and a vibrant color
palette. The background must be white.
""",
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("red_panda_sticker.png"), blob.data().get());
}
}
}
}
}
}
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const prompt =
"A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It's munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white.";
const response = await ai.models.generateContent({
model: "gemini-2.5-flash-image",
contents: prompt,
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("red_panda_sticker.png", buffer);
console.log("Image saved as red_panda_sticker.png");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-2.5-flash-image",
genai.Text("A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It's munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white."),
)
for _, part := range result.Candidates[0].Content.Parts {
if part.Text != "" {
fmt.Println(part.Text)
} else if part.InlineData != nil {
imageBytes := part.InlineData.Data
outputFilename := "red_panda_sticker.png"
_ = os.WriteFile(outputFilename, imageBytes, 0644)
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{
"parts": [
{"text": "A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It is munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white."}
]
}]
}'

3. Accurate text in images
Gemini excels at rendering text. Be clear about the text, the font style (descriptively), and the overall design. Use Gemini 3 Pro Image Preview for professional asset production.
Template
Create a [image type] for [brand/concept] with the text "[text to render]"
in a [font style]. The design should be [style description], with a
[color scheme].
Prompt
Create a modern, minimalist logo for a coffee shop called 'The Daily Grind'. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way.
Python
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="Create a modern, minimalist logo for a coffee shop called 'The Daily Grind'. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way.",
config=types.GenerateContentConfig(
image_config=types.ImageConfig(
aspect_ratio="1:1",
)
)
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save("logo_example.jpg")
Java
import com.google.genai.Client;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.Part;
import com.google.genai.types.ImageConfig;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class AccurateTextInImages {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.imageConfig(ImageConfig.builder()
.aspectRatio("1:1")
.build())
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-3-pro-image-preview",
"""
Create a modern, minimalist logo for a coffee shop called 'The Daily Grind'. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way.
""",
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("logo_example.jpg"), blob.data().get());
}
}
}
}
}
}
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const prompt =
"Create a modern, minimalist logo for a coffee shop called 'The Daily Grind'. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way.";
const response = await ai.models.generateContent({
model: "gemini-3-pro-image-preview",
contents: prompt,
config: {
imageConfig: {
aspectRatio: "1:1",
},
},
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("logo_example.jpg", buffer);
console.log("Image saved as logo_example.jpg");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-3-pro-image-preview",
genai.Text("Create a modern, minimalist logo for a coffee shop called 'The Daily Grind'. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way."),
&genai.GenerateContentConfig{
ImageConfig: &genai.ImageConfig{
AspectRatio: "1:1",
},
},
)
for _, part := range result.Candidates[0].Content.Parts {
if part.Text != "" {
fmt.Println(part.Text)
} else if part.InlineData != nil {
imageBytes := part.InlineData.Data
outputFilename := "logo_example.jpg"
_ = os.WriteFile(outputFilename, imageBytes, 0644)
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-image-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{
"parts": [
{"text": "Create a modern, minimalist logo for a coffee shop called The Daily Grind. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way."}
]
}],
"generationConfig": {
"imageConfig": {
"aspectRatio": "1:1"
}
}
}'
4. Product mockups & commercial photography
Perfect for creating clean, professional product shots for ecommerce, advertising, or branding.
Template
A high-resolution, studio-lit product photograph of a [product description]
on a [background surface/description]. The lighting is a [lighting setup,
e.g., three-point softbox setup] to [lighting purpose]. The camera angle is
a [angle type] to showcase [specific feature]. Ultra-realistic, with sharp
focus on [key detail]. [Aspect ratio].
Prompt
A high-resolution, studio-lit product photograph of a minimalist ceramic
coffee mug in matte black, presented on a polished concrete surface. The
lighting is a three-point softbox setup designed to create soft, diffused
highlights and eliminate harsh shadows. The camera angle is a slightly
elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with
sharp focus on the steam rising from the coffee. Square image.
Python
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-2.5-flash-image",
contents="A high-resolution, studio-lit product photograph of a minimalist ceramic coffee mug in matte black, presented on a polished concrete surface. The lighting is a three-point softbox setup designed to create soft, diffused highlights and eliminate harsh shadows. The camera angle is a slightly elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with sharp focus on the steam rising from the coffee. Square image.",
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save("product_mockup.png")
Java
import com.google.genai.Client;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.Part;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class ProductMockup {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-2.5-flash-image",
"""
A high-resolution, studio-lit product photograph of a minimalist
ceramic coffee mug in matte black, presented on a polished
concrete surface. The lighting is a three-point softbox setup
designed to create soft, diffused highlights and eliminate harsh
shadows. The camera angle is a slightly elevated 45-degree shot
to showcase its clean lines. Ultra-realistic, with sharp focus
on the steam rising from the coffee. Square image.
""",
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("product_mockup.png"), blob.data().get());
}
}
}
}
}
}
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const prompt =
"A high-resolution, studio-lit product photograph of a minimalist ceramic coffee mug in matte black, presented on a polished concrete surface. The lighting is a three-point softbox setup designed to create soft, diffused highlights and eliminate harsh shadows. The camera angle is a slightly elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with sharp focus on the steam rising from the coffee. Square image.";
const response = await ai.models.generateContent({
model: "gemini-2.5-flash-image",
contents: prompt,
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("product_mockup.png", buffer);
console.log("Image saved as product_mockup.png");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-2.5-flash-image",
genai.Text("A high-resolution, studio-lit product photograph of a minimalist ceramic coffee mug in matte black, presented on a polished concrete surface. The lighting is a three-point softbox setup designed to create soft, diffused highlights and eliminate harsh shadows. The camera angle is a slightly elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with sharp focus on the steam rising from the coffee. Square image."),
)
for _, part := range result.Candidates[0].Content.Parts {
if part.Text != "" {
fmt.Println(part.Text)
} else if part.InlineData != nil {
imageBytes := part.InlineData.Data
outputFilename := "product_mockup.png"
_ = os.WriteFile(outputFilename, imageBytes, 0644)
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{
"parts": [
{"text": "A high-resolution, studio-lit product photograph of a minimalist ceramic coffee mug in matte black, presented on a polished concrete surface. The lighting is a three-point softbox setup designed to create soft, diffused highlights and eliminate harsh shadows. The camera angle is a slightly elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with sharp focus on the steam rising from the coffee. Square image."}
]
}]
}'

5. Minimalist & negative space design
Excellent for creating backgrounds for websites, presentations, or marketing materials where text will be overlaid.
Template
A minimalist composition featuring a single [subject] positioned in the
[bottom-right/top-left/etc.] of the frame. The background is a vast, empty
[color] canvas, creating significant negative space. Soft, subtle lighting.
[Aspect ratio].
Prompt
A minimalist composition featuring a single, delicate red maple leaf
positioned in the bottom-right of the frame. The background is a vast, empty
off-white canvas, creating significant negative space for text. Soft,
diffused lighting from the top left. Square image.
Python
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-2.5-flash-image",
contents="A minimalist composition featuring a single, delicate red maple leaf positioned in the bottom-right of the frame. The background is a vast, empty off-white canvas, creating significant negative space for text. Soft, diffused lighting from the top left. Square image.",
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save("minimalist_design.png")
Java
import com.google.genai.Client;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.Part;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class MinimalistDesign {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-2.5-flash-image",
"""
A minimalist composition featuring a single, delicate red maple
leaf positioned in the bottom-right of the frame. The background
is a vast, empty off-white canvas, creating significant negative
space for text. Soft, diffused lighting from the top left.
Square image.
""",
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("minimalist_design.png"), blob.data().get());
}
}
}
}
}
}
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const prompt =
"A minimalist composition featuring a single, delicate red maple leaf positioned in the bottom-right of the frame. The background is a vast, empty off-white canvas, creating significant negative space for text. Soft, diffused lighting from the top left. Square image.";
const response = await ai.models.generateContent({
model: "gemini-2.5-flash-image",
contents: prompt,
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("minimalist_design.png", buffer);
console.log("Image saved as minimalist_design.png");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-2.5-flash-image",
genai.Text("A minimalist composition featuring a single, delicate red maple leaf positioned in the bottom-right of the frame. The background is a vast, empty off-white canvas, creating significant negative space for text. Soft, diffused lighting from the top left. Square image."),
)
for _, part := range result.Candidates[0].Content.Parts {
if part.Text != "" {
fmt.Println(part.Text)
} else if part.InlineData != nil {
imageBytes := part.InlineData.Data
outputFilename := "minimalist_design.png"
_ = os.WriteFile(outputFilename, imageBytes, 0644)
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{
"parts": [
{"text": "A minimalist composition featuring a single, delicate red maple leaf positioned in the bottom-right of the frame. The background is a vast, empty off-white canvas, creating significant negative space for text. Soft, diffused lighting from the top left. Square image."}
]
}]
}'

6. Sequential art (Comic panel / Storyboard)
Builds on character consistency and scene description to create panels for visual storytelling. For accuracy with text and storytelling ability, these prompts work best with Gemini 3 Pro Image Preview.
Template
Make a 3 panel comic in a [style]. Put the character in a [type of scene].
Prompt
Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene.
Python
from google import genai
from google.genai import types
from PIL import Image
client = genai.Client()
image_input = Image.open('/path/to/your/man_in_white_glasses.jpg')
text_input = "Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene."
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=[text_input, image_input],
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save("comic_panel.jpg")
Java
import com.google.genai.Client;
import com.google.genai.types.Content;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.Part;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
public class ComicPanel {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-3-pro-image-preview",
Content.fromParts(
Part.fromText("""
Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene.
"""),
Part.fromBytes(
Files.readAllBytes(
Path.of("/path/to/your/man_in_white_glasses.jpg")),
"image/jpeg")),
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("comic_panel.jpg"), blob.data().get());
}
}
}
}
}
}
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/man_in_white_glasses.jpg";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const prompt = [
{text: "Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene."},
{
inlineData: {
mimeType: "image/jpeg",
data: base64Image,
},
},
];
const response = await ai.models.generateContent({
model: "gemini-3-pro-image-preview",
contents: prompt,
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("comic_panel.jpg", buffer);
console.log("Image saved as comic_panel.jpg");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
imagePath := "/path/to/your/man_in_white_glasses.jpg"
imgData, _ := os.ReadFile(imagePath)
parts := []*genai.Part{
genai.NewPartFromText("Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene."),
&genai.Part{
InlineData: &genai.Blob{
MIMEType: "image/jpeg",
Data: imgData,
},
},
}
contents := []*genai.Content{
genai.NewContentFromParts(parts, genai.RoleUser),
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-3-pro-image-preview",
contents,
)
for _, part := range result.Candidates[0].Content.Parts {
if part.Text != "" {
fmt.Println(part.Text)
} else if part.InlineData != nil {
imageBytes := part.InlineData.Data
outputFilename := "comic_panel.jpg"
_ = os.WriteFile(outputFilename, imageBytes, 0644)
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-image-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{
"parts": [
{"text": "Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene."},
{"inline_data": {"mime_type": "image/jpeg", "data": "<BASE64_IMAGE_DATA>"}}
]
}]
}'
Input |
Output |

|

|
7. Grounding with Google Search
Use Google Search to generate images based on recent or real-time information. This is useful for news, weather, and other time-sensitive topics.
Prompt
Make a simple but stylish graphic of last night's Arsenal game in the Champion's League
Python
from google import genai
from google.genai import types
prompt = "Make a simple but stylish graphic of last night's Arsenal game in the Champion's League"
aspect_ratio = "16:9" # "1:1","2:3","3:2","3:4","4:3","4:5","5:4","9:16","16:9","21:9"
client = genai.Client()
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=prompt,
config=types.GenerateContentConfig(
response_modalities=['Text', 'Image'],
image_config=types.ImageConfig(
aspect_ratio=aspect_ratio,
),
tools=[{"google_search": {}}]
)
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif image:= part.as_image():
image.save("football-score.jpg")
Java
import com.google.genai.Client;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.GoogleSearch;
import com.google.genai.types.ImageConfig;
import com.google.genai.types.Part;
import com.google.genai.types.Tool;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class SearchGrounding {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.imageConfig(ImageConfig.builder()
.aspectRatio("16:9")
.build())
.tools(Tool.builder()
.googleSearch(GoogleSearch.builder().build())
.build())
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-3-pro-image-preview", """
Make a simple but stylish graphic of last night's Arsenal game in the Champion's League
""",
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("football-score.jpg"), blob.data().get());
}
}
}
}
}
}
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const prompt = "Make a simple but stylish graphic of last night's Arsenal game in the Champion's League";
const aspectRatio = '16:9';
const resolution = '2K';
const response = await ai.models.generateContent({
model: 'gemini-3-pro-image-preview',
contents: prompt,
config: {
responseModalities: ['TEXT', 'IMAGE'],
imageConfig: {
aspectRatio: aspectRatio,
imageSize: resolution,
},
tools: [{"google_search": {}}],
},
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("football-score.jpg", buffer);
console.log("Image saved as football-score.jpg");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
pb "google.golang.org/genai/schema"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
defer client.Close()
model := client.GenerativeModel("gemini-3-pro-image-preview")
model.Tools = []*pb.Tool{
pb.NewGoogleSearchTool(),
}
model.GenerationConfig = &pb.GenerationConfig{
ResponseModalities: []pb.ResponseModality{genai.Text, genai.Image},
ImageConfig: &pb.ImageConfig{
AspectRatio: "16:9",
},
}
prompt := "Make a simple but stylish graphic of last night's Arsenal game in the Champion's League"
resp, err := model.GenerateContent(ctx, genai.Text(prompt))
if err != nil {
log.Fatal(err)
}
for _, part := range resp.Candidates[0].Content.Parts {
if txt, ok := part.(genai.Text); ok {
fmt.Printf("%s", string(txt))
} else if img, ok := part.(genai.ImageData); ok {
err := os.WriteFile("football-score.jpg", img.Data, 0644)
if err != nil {
log.Fatal(err)
}
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-image-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{"parts": [{"text": "Make a simple but stylish graphic of last nights Arsenal game in the Champions League"}]}],
"tools": [{"google_search": {}}],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"],
"imageConfig": {"aspectRatio": "16:9"}
}
}'

Prompts for editing images
These examples show how to provide images alongside your text prompts for editing, composition, and style transfer.
1. Adding and removing elements
Provide an image and describe your change. The model will match the original image's style, lighting, and perspective.
Template
Using the provided image of [subject], please [add/remove/modify] [element]
to/from the scene. Ensure the change is [description of how the change should
integrate].
Prompt
"Using the provided image of my cat, please add a small, knitted wizard hat
on its head. Make it look like it's sitting comfortably and matches the soft
lighting of the photo."
Python
from google import genai
from google.genai import types
from PIL import Image
client = genai.Client()
# Base image prompt: "A photorealistic picture of a fluffy ginger cat sitting on a wooden floor, looking directly at the camera. Soft, natural light from a window."
image_input = Image.open('/path/to/your/cat_photo.png')
text_input = """Using the provided image of my cat, please add a small, knitted wizard hat on its head. Make it look like it's sitting comfortably and not falling off."""
# Generate an image from a text prompt
response = client.models.generate_content(
model="gemini-2.5-flash-image",
contents=[text_input, image_input],
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save("cat_with_hat.png")
Java
import com.google.genai.Client;
import com.google.genai.types.Content;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.Part;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
public class AddRemoveElements {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-2.5-flash-image",
Content.fromParts(
Part.fromText("""
Using the provided image of my cat, please add a small,
knitted wizard hat on its head. Make it look like it's
sitting comfortably and not falling off.
"""),
Part.fromBytes(
Files.readAllBytes(
Path.of("/path/to/your/cat_photo.png")),
"image/png")),
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("cat_with_hat.png"), blob.data().get());
}
}
}
}
}
}
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/cat_photo.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const prompt = [
{ text: "Using the provided image of my cat, please add a small, knitted wizard hat on its head. Make it look like it's sitting comfortably and not falling off." },
{
inlineData: {
mimeType: "image/png",
data: base64Image,
},
},
];
const response = await ai.models.generateContent({
model: "gemini-2.5-flash-image",
contents: prompt,
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("cat_with_hat.png", buffer);
console.log("Image saved as cat_with_hat.png");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
imagePath := "/path/to/your/cat_photo.png"
imgData, _ := os.ReadFile(imagePath)
parts := []*genai.Part{
genai.NewPartFromText("Using the provided image of my cat, please add a small, knitted wizard hat on its head. Make it look like it's sitting comfortably and not falling off."),
&genai.Part{
InlineData: &genai.Blob{
MIMEType: "image/png",
Data: imgData,
},
},
}
contents := []*genai.Content{
genai.NewContentFromParts(parts, genai.RoleUser),
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-2.5-flash-image",
contents,
)
for _, part := range result.Candidates[0].Content.Parts {
if part.Text != "" {
fmt.Println(part.Text)
} else if part.InlineData != nil {
imageBytes := part.InlineData.Data
outputFilename := "cat_with_hat.png"
_ = os.WriteFile(outputFilename, imageBytes, 0644)
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"contents\": [{
\"parts\":[
{\"text\": \"Using the provided image of my cat, please add a small, knitted wizard hat on its head. Make it look like it's sitting comfortably and not falling off.\"},
{
\"inline_data\": {
\"mime_type\":\"image/png\",
\"data\": \"<BASE64_IMAGE_DATA>\"
}
}
]
}]
}"
Input |
Output |

|

|
2. Inpainting (Semantic masking)
Conversationally define a "mask" to edit a specific part of an image while leaving the rest untouched.
Template
Using the provided image, change only the [specific element] to [new
element/description]. Keep everything else in the image exactly the same,
preserving the original style, lighting, and composition.
Prompt
"Using the provided image of a living room, change only the blue sofa to be
a vintage, brown leather chesterfield sofa. Keep the rest of the room,
including the pillows on the sofa and the lighting, unchanged."
Python
from google import genai
from google.genai import types
from PIL import Image
client = genai.Client()
# Base image prompt: "A wide shot of a modern, well-lit living room with a prominent blue sofa in the center. A coffee table is in front of it and a large window is in the background."
living_room_image = Image.open('/path/to/your/living_room.png')
text_input = """Using the provided image of a living room, change only the blue sofa to be a vintage, brown leather chesterfield sofa. Keep the rest of the room, including the pillows on the sofa and the lighting, unchanged."""
# Generate an image from a text prompt
response = client.models.generate_content(
model="gemini-2.5-flash-image",
contents=[living_room_image, text_input],
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save("living_room_edited.png")
Java
import com.google.genai.Client;
import com.google.genai.types.Content;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.Part;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
public class Inpainting {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-2.5-flash-image",
Content.fromParts(
Part.fromBytes(
Files.readAllBytes(
Path.of("/path/to/your/living_room.png")),
"image/png"),
Part.fromText("""
Using the provided image of a living room, change
only the blue sofa to be a vintage, brown leather
chesterfield sofa. Keep the rest of the room,
including the pillows on the sofa and the lighting,
unchanged.
""")),
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("living_room_edited.png"), blob.data().get());
}
}
}
}
}
}
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/living_room.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const prompt = [
{
inlineData: {
mimeType: "image/png",
data: base64Image,
},
},
{ text: "Using the provided image of a living room, change only the blue sofa to be a vintage, brown leather chesterfield sofa. Keep the rest of the room, including the pillows on the sofa and the lighting, unchanged." },
];
const response = await ai.models.generateContent({
model: "gemini-2.5-flash-image",
contents: prompt,
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("living_room_edited.png", buffer);
console.log("Image saved as living_room_edited.png");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
imagePath := "/path/to/your/living_room.png"
imgData, _ := os.ReadFile(imagePath)
parts := []*genai.Part{
&genai.Part{
InlineData: &genai.Blob{
MIMEType: "image/png",
Data: imgData,
},
},
genai.NewPartFromText("Using the provided image of a living room, change only the blue sofa to be a vintage, brown leather chesterfield sofa. Keep the rest of the room, including the pillows on the sofa and the lighting, unchanged."),
}
contents := []*genai.Content{
genai.NewContentFromParts(parts, genai.RoleUser),
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-2.5-flash-image",
contents,
)
for _, part := range result.Candidates[0].Content.Parts {
if part.Text != "" {
fmt.Println(part.Text)
} else if part.InlineData != nil {
imageBytes := part.InlineData.Data
outputFilename := "living_room_edited.png"
_ = os.WriteFile(outputFilename, imageBytes, 0644)
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"contents\": [{
\"parts\":[
{
\"inline_data\": {
\"mime_type\":\"image/png\",
\"data\": \"<BASE64_IMAGE_DATA>\"
}
},
{\"text\": \"Using the provided image of a living room, change only the blue sofa to be a vintage, brown leather chesterfield sofa. Keep the rest of the room, including the pillows on the sofa and the lighting, unchanged.\"}
]
}]
}"
Input |
Output |

|

|
3. Style transfer
Provide an image and ask the model to recreate its content in a different artistic style.
Template
Transform the provided photograph of [subject] into the artistic style of [artist/art style]. Preserve the original composition but render it with [description of stylistic elements].
Prompt
"Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows."
Python
from google import genai
from google.genai import types
from PIL import Image
client = genai.Client()
# Base image prompt: "A photorealistic, high-resolution photograph of a busy city street in New York at night, with bright neon signs, yellow taxis, and tall skyscrapers."
city_image = Image.open('/path/to/your/city.png')
text_input = """Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows."""
# Generate an image from a text prompt
response = client.models.generate_content(
model="gemini-2.5-flash-image",
contents=[city_image, text_input],
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save("city_style_transfer.png")
Java
import com.google.genai.Client;
import com.google.genai.types.Content;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.Part;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
public class StyleTransfer {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-2.5-flash-image",
Content.fromParts(
Part.fromBytes(
Files.readAllBytes(
Path.of("/path/to/your/city.png")),
"image/png"),
Part.fromText("""
Transform the provided photograph of a modern city
street at night into the artistic style of
Vincent van Gogh's 'Starry Night'. Preserve the
original composition of buildings and cars, but
render all elements with swirling, impasto
brushstrokes and a dramatic palette of deep blues
and bright yellows.
""")),
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("city_style_transfer.png"), blob.data().get());
}
}
}
}
}
}
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/city.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const prompt = [
{
inlineData: {
mimeType: "image/png",
data: base64Image,
},
},
{ text: "Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows." },
];
const response = await ai.models.generateContent({
model: "gemini-2.5-flash-image",
contents: prompt,
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("city_style_transfer.png", buffer);
console.log("Image saved as city_style_transfer.png");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
imagePath := "/path/to/your/city.png"
imgData, _ := os.ReadFile(imagePath)
parts := []*genai.Part{
&genai.Part{
InlineData: &genai.Blob{
MIMEType: "image/png",
Data: imgData,
},
},
genai.NewPartFromText("Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows."),
}
contents := []*genai.Content{
genai.NewContentFromParts(parts, genai.RoleUser),
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-2.5-flash-image",
contents,
)
for _, part := range result.Candidates[0].Content.Parts {
if part.Text != "" {
fmt.Println(part.Text)
} else if part.InlineData != nil {
imageBytes := part.InlineData.Data
outputFilename := "city_style_transfer.png"
_ = os.WriteFile(outputFilename, imageBytes, 0644)
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"contents\": [{
\"parts\":[
{
\"inline_data\": {
\"mime_type\":\"image/png\",
\"data\": \"<BASE64_IMAGE_DATA>\"
}
},
{\"text\": \"Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows.\"}
]
}]
}"
Input |
Output |

|

|
4. Advanced composition: Combining multiple images
Provide multiple images as context to create a new, composite scene. This is perfect for product mockups or creative collages.
Template
Create a new image by combining the elements from the provided images. Take
the [element from image 1] and place it with/on the [element from image 2].
The final image should be a [description of the final scene].
Prompt
"Create a professional e-commerce fashion photo. Take the blue floral dress
from the first image and let the woman from the second image wear it.
Generate a realistic, full-body shot of the woman wearing the dress, with
the lighting and shadows adjusted to match the outdoor environment."
Python
from google import genai
from google.genai import types
from PIL import Image
client = genai.Client()
# Base image prompts:
# 1. Dress: "A professionally shot photo of a blue floral summer dress on a plain white background, ghost mannequin style."
# 2. Model: "Full-body shot of a woman with her hair in a bun, smiling, standing against a neutral grey studio background."
dress_image = Image.open('/path/to/your/dress.png')
model_image = Image.open('/path/to/your/model.png')
text_input = """Create a professional e-commerce fashion photo. Take the blue floral dress from the first image and let the woman from the second image wear it. Generate a realistic, full-body shot of the woman wearing the dress, with the lighting and shadows adjusted to match the outdoor environment."""
# Generate an image from a text prompt
response = client.models.generate_content(
model="gemini-2.5-flash-image",
contents=[dress_image, model_image, text_input],
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save("fashion_ecommerce_shot.png")
Java
import com.google.genai.Client;
import com.google.genai.types.Content;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.Part;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
public class AdvancedComposition {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-2.5-flash-image",
Content.fromParts(
Part.fromBytes(
Files.readAllBytes(
Path.of("/path/to/your/dress.png")),
"image/png"),
Part.fromBytes(
Files.readAllBytes(
Path.of("/path/to/your/model.png")),
"image/png"),
Part.fromText("""
Create a professional e-commerce fashion photo.
Take the blue floral dress from the first image and
let the woman from the second image wear it. Generate
a realistic, full-body shot of the woman wearing the
dress, with the lighting and shadows adjusted to
match the outdoor environment.
""")),
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("fashion_ecommerce_shot.png"), blob.data().get());
}
}
}
}
}
}
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath1 = "/path/to/your/dress.png";
const imageData1 = fs.readFileSync(imagePath1);
const base64Image1 = imageData1.toString("base64");
const imagePath2 = "/path/to/your/model.png";
const imageData2 = fs.readFileSync(imagePath2);
const base64Image2 = imageData2.toString("base64");
const prompt = [
{
inlineData: {
mimeType: "image/png",
data: base64Image1,
},
},
{
inlineData: {
mimeType: "image/png",
data: base64Image2,
},
},
{ text: "Create a professional e-commerce fashion photo. Take the blue floral dress from the first image and let the woman from the second image wear it. Generate a realistic, full-body shot of the woman wearing the dress, with the lighting and shadows adjusted to match the outdoor environment." },
];
const response = await ai.models.generateContent({
model: "gemini-2.5-flash-image",
contents: prompt,
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("fashion_ecommerce_shot.png", buffer);
console.log("Image saved as fashion_ecommerce_shot.png");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
imgData1, _ := os.ReadFile("/path/to/your/dress.png")
imgData2, _ := os.ReadFile("/path/to/your/model.png")
parts := []*genai.Part{
&genai.Part{
InlineData: &genai.Blob{
MIMEType: "image/png",
Data: imgData1,
},
},
&genai.Part{
InlineData: &genai.Blob{
MIMEType: "image/png",
Data: imgData2,
},
},
genai.NewPartFromText("Create a professional e-commerce fashion photo. Take the blue floral dress from the first image and let the woman from the second image wear it. Generate a realistic, full-body shot of the woman wearing the dress, with the lighting and shadows adjusted to match the outdoor environment."),
}
contents := []*genai.Content{
genai.NewContentFromParts(parts, genai.RoleUser),
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-2.5-flash-image",
contents,
)
for _, part := range result.Candidates[0].Content.Parts {
if part.Text != "" {
fmt.Println(part.Text)
} else if part.InlineData != nil {
imageBytes := part.InlineData.Data
outputFilename := "fashion_ecommerce_shot.png"
_ = os.WriteFile(outputFilename, imageBytes, 0644)
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"contents\": [{
\"parts\":[
{
\"inline_data\": {
\"mime_type\":\"image/png\",
\"data\": \"<BASE64_IMAGE_DATA_1>\"
}
},
{
\"inline_data\": {
\"mime_type\":\"image/png\",
\"data\": \"<BASE64_IMAGE_DATA_2>\"
}
},
{\"text\": \"Create a professional e-commerce fashion photo. Take the blue floral dress from the first image and let the woman from the second image wear it. Generate a realistic, full-body shot of the woman wearing the dress, with the lighting and shadows adjusted to match the outdoor environment.\"}
]
}]
}"
Input 1 |
Input 2 |
Output |

|

|

|
5. High-fidelity detail preservation
To ensure critical details (like a face or logo) are preserved during an edit, describe them in great detail along with your edit request.
Template
Using the provided images, place [element from image 2] onto [element from
image 1]. Ensure that the features of [element from image 1] remain
completely unchanged. The added element should [description of how the
element should integrate].
Prompt
"Take the first image of the woman with brown hair, blue eyes, and a neutral
expression. Add the logo from the second image onto her black t-shirt.
Ensure the woman's face and features remain completely unchanged. The logo
should look like it's naturally printed on the fabric, following the folds
of the shirt."
Python
from google import genai
from google.genai import types
from PIL import Image
client = genai.Client()
# Base image prompts:
# 1. Woman: "A professional headshot of a woman with brown hair and blue eyes, wearing a plain black t-shirt, against a neutral studio background."
# 2. Logo: "A simple, modern logo with the letters 'G' and 'A' in a white circle."
woman_image = Image.open('/path/to/your/woman.png')
logo_image = Image.open('/path/to/your/logo.png')
text_input = """Take the first image of the woman with brown hair, blue eyes, and a neutral expression. Add the logo from the second image onto her black t-shirt. Ensure the woman's face and features remain completely unchanged. The logo should look like it's naturally printed on the fabric, following the folds of the shirt."""
# Generate an image from a text prompt
response = client.models.generate_content(
model="gemini-2.5-flash-image",
contents=[woman_image, logo_image, text_input],
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save("woman_with_logo.png")
Java
import com.google.genai.Client;
import com.google.genai.types.Content;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.Part;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
public class HighFidelity {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-2.5-flash-image",
Content.fromParts(
Part.fromBytes(
Files.readAllBytes(
Path.of("/path/to/your/woman.png")),
"image/png"),
Part.fromBytes(
Files.readAllBytes(
Path.of("/path/to/your/logo.png")),
"image/png"),
Part.fromText("""
Take the first image of the woman with brown hair,
blue eyes, and a neutral expression. Add the logo
from the second image onto her black t-shirt.
Ensure the woman's face and features remain
completely unchanged. The logo should look like
it's naturally printed on the fabric, following
the folds of the shirt.
""")),
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("woman_with_logo.png"), blob.data().get());
}
}
}
}
}
}
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath1 = "/path/to/your/woman.png";
const imageData1 = fs.readFileSync(imagePath1);
const base64Image1 = imageData1.toString("base64");
const imagePath2 = "/path/to/your/logo.png";
const imageData2 = fs.readFileSync(imagePath2);
const base64Image2 = imageData2.toString("base64");
const prompt = [
{
inlineData: {
mimeType: "image/png",
data: base64Image1,
},
},
{
inlineData: {
mimeType: "image/png",
data: base64Image2,
},
},
{ text: "Take the first image of the woman with brown hair, blue eyes, and a neutral expression. Add the logo from the second image onto her black t-shirt. Ensure the woman's face and features remain completely unchanged. The logo should look like it's naturally printed on the fabric, following the folds of the shirt." },
];
const response = await ai.models.generateContent({
model: "gemini-2.5-flash-image",
contents: prompt,
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("woman_with_logo.png", buffer);
console.log("Image saved as woman_with_logo.png");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
imgData1, _ := os.ReadFile("/path/to/your/woman.png")
imgData2, _ := os.ReadFile("/path/to/your/logo.png")
parts := []*genai.Part{
&genai.Part{
InlineData: &genai.Blob{
MIMEType: "image/png",
Data: imgData1,
},
},
&genai.Part{
InlineData: &genai.Blob{
MIMEType: "image/png",
Data: imgData2,
},
},
genai.NewPartFromText("Take the first image of the woman with brown hair, blue eyes, and a neutral expression. Add the logo from the second image onto her black t-shirt. Ensure the woman's face and features remain completely unchanged. The logo should look like it's naturally printed on the fabric, following the folds of the shirt."),
}
contents := []*genai.Content{
genai.NewContentFromParts(parts, genai.RoleUser),
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-2.5-flash-image",
contents,
)
for _, part := range result.Candidates[0].Content.Parts {
if part.Text != "" {
fmt.Println(part.Text)
} else if part.InlineData != nil {
imageBytes := part.InlineData.Data
outputFilename := "woman_with_logo.png"
_ = os.WriteFile(outputFilename, imageBytes, 0644)
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"contents\": [{
\"parts\":[
{
\"inline_data\": {
\"mime_type\":\"image/png\",
\"data\": \"<BASE64_IMAGE_DATA_1>\"
}
},
{
\"inline_data\": {
\"mime_type\":\"image/png\",
\"data\": \"<BASE64_IMAGE_DATA_2>\"
}
},
{\"text\": \"Take the first image of the woman with brown hair, blue eyes, and a neutral expression. Add the logo from the second image onto her black t-shirt. Ensure the woman's face and features remain completely unchanged. The logo should look like it's naturally printed on the fabric, following the folds of the shirt.\"}
]
}]
}"
Input 1 |
Input 2 |
Output |

|
|
|
6. Bring something to life
Upload a rough sketch or drawing and ask the model to refine it into a finished image.
Template
Turn this rough [medium] sketch of a [subject] into a [style description]
photo. Keep the [specific features] from the sketch but add [new details/materials].
Prompt
"Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting."
Python
from google import genai
from PIL import Image
client = genai.Client()
# Base image prompt: "A rough pencil sketch of a flat sports car on white paper."
sketch_image = Image.open('/path/to/your/car_sketch.png')
text_input = """Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting."""
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=[sketch_image, text_input],
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save("car_photo.png")
Java
import com.google.genai.Client;
import com.google.genai.types.Content;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.Part;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
public class BringToLife {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-3-pro-image-preview",
Content.fromParts(
Part.fromBytes(
Files.readAllBytes(
Path.of("/path/to/your/car_sketch.png")),
"image/png"),
Part.fromText("""
Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting.
""")),
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("car_photo.png"), blob.data().get());
}
}
}
}
}
}
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/car_sketch.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const prompt = [
{
inlineData: {
mimeType: "image/png",
data: base64Image,
},
},
{ text: "Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting." },
];
const response = await ai.models.generateContent({
model: "gemini-3-pro-image-preview",
contents: prompt,
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("car_photo.png", buffer);
console.log("Image saved as car_photo.png");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
imgData, _ := os.ReadFile("/path/to/your/car_sketch.png")
parts := []*genai.Part{
&genai.Part{
InlineData: &genai.Blob{
MIMEType: "image/png",
Data: imgData,
},
},
genai.NewPartFromText("Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting."),
}
contents := []*genai.Content{
genai.NewContentFromParts(parts, genai.RoleUser),
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-3-pro-image-preview",
contents,
)
for _, part := range result.Candidates[0].Content.Parts {
if part.Text != "" {
fmt.Println(part.Text)
} else if part.InlineData != nil {
imageBytes := part.InlineData.Data
outputFilename := "car_photo.png"
_ = os.WriteFile(outputFilename, imageBytes, 0644)
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-image-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"contents\": [{
\"parts\":[
{
\"inline_data\": {
\"mime_type\":\"image/png\",
\"data\": \"<BASE64_IMAGE_DATA>\"
}
},
{\"text\": \"Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting.\"}
]
}]
}"
Input |
Output |

|

|
7. Character consistency: 360 view
You can generate 360-degree views of a character by iteratively prompting for different angles. For best results, include previously generated images in subsequent prompts to maintain consistency. For complex poses, include a reference image of the desired pose.
Template
A studio portrait of [person] against [background], [looking forward/in profile looking right/etc.]
Prompt
A studio portrait of this man against white, in profile looking right
Python
from google import genai
from google.genai import types
from PIL import Image
client = genai.Client()
image_input = Image.open('/path/to/your/man_in_white_glasses.jpg')
text_input = """A studio portrait of this man against white, in profile looking right"""
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=[text_input, image_input],
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save("man_right_profile.png")
Java
import com.google.genai.Client;
import com.google.genai.types.Content;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.Part;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
public class CharacterConsistency {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-3-pro-image-preview",
Content.fromParts(
Part.fromText("""
A studio portrait of this man against white, in profile looking right
"""),
Part.fromBytes(
Files.readAllBytes(
Path.of("/path/to/your/man_in_white_glasses.jpg")),
"image/jpeg")),
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("man_right_profile.png"), blob.data().get());
}
}
}
}
}
}
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/man_in_white_glasses.jpg";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const prompt = [
{ text: "A studio portrait of this man against white, in profile looking right" },
{
inlineData: {
mimeType: "image/jpeg",
data: base64Image,
},
},
];
const response = await ai.models.generateContent({
model: "gemini-3-pro-image-preview",
contents: prompt,
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("man_right_profile.png", buffer);
console.log("Image saved as man_right_profile.png");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
imagePath := "/path/to/your/man_in_white_glasses.jpg"
imgData, _ := os.ReadFile(imagePath)
parts := []*genai.Part{
genai.NewPartFromText("A studio portrait of this man against white, in profile looking right"),
&genai.Part{
InlineData: &genai.Blob{
MIMEType: "image/jpeg",
Data: imgData,
},
},
}
contents := []*genai.Content{
genai.NewContentFromParts(parts, genai.RoleUser),
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-3-pro-image-preview",
contents,
)
for _, part := range result.Candidates[0].Content.Parts {
if part.Text != "" {
fmt.Println(part.Text)
} else if part.InlineData != nil {
imageBytes := part.InlineData.Data
outputFilename := "man_right_profile.png"
_ = os.WriteFile(outputFilename, imageBytes, 0644)
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-image-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"contents\": [{
\"parts\":[
{\"text\": \"A studio portrait of this man against white, in profile looking right\"},
{
\"inline_data\": {
\"mime_type\":\"image/jpeg\",
\"data\": \"<BASE64_IMAGE_DATA>\"
}
}
]
}]
}"
Input |
Output 1 |
Output 2 |
|
|

|

|
Best Practices
To elevate your results from good to great, incorporate these professional strategies into your workflow.
- Be Hyper-Specific: The more detail you provide, the more control you have. Instead of "fantasy armor," describe it: "ornate elven plate armor, etched with silver leaf patterns, with a high collar and pauldrons shaped like falcon wings."
- Provide Context and Intent: Explain the purpose of the image. The model's understanding of context will influence the final output. For example, "Create a logo for a high-end, minimalist skincare brand" will yield better results than just "Create a logo."
- Iterate and Refine: Don't expect a perfect image on the first try. Use the conversational nature of the model to make small changes. Follow up with prompts like, "That's great, but can you make the lighting a bit warmer?" or "Keep everything the same, but change the character's expression to be more serious."
- Use Step-by-Step Instructions: For complex scenes with many elements, break your prompt into steps. "First, create a background of a serene, misty forest at dawn. Then, in the foreground, add a moss-covered ancient stone altar. Finally, place a single, glowing sword on top of the altar."
- Use "Semantic Negative Prompts": Instead of saying "no cars," describe the desired scene positively: "an empty, deserted street with no signs of traffic."
- Control the Camera: Use photographic and cinematic language to control
the composition. Terms like
wide-angle shot,macro shot,low-angle perspective.
Limitations
- For best performance, use the following languages: EN, ar-EG, de-DE, es-MX, fr-FR, hi-IN, id-ID, it-IT, ja-JP, ko-KR, pt-BR, ru-RU, ua-UA, vi-VN, zh-CN.
- Image generation does not support audio or video inputs.
- The model won't always follow the exact number of image outputs that the user explicitly asks for.
gemini-2.5-flash-imageworks best with up to 3 images as input, whilegemini-3-pro-image-previewsupports 5 images with high fidelity, and up to 14 images in total.- When generating text for an image, Gemini works best if you first generate the text and then ask for an image with the text.
- All generated images include a SynthID watermark.
Optional configurations
You can optionally configure the response modalities and aspect ratio of the
model's output in the config field of generate_content calls.
Output types
The model defaults to returning text and image responses
(i.e. response_modalities=['Text', 'Image']).
You can configure the response to return only images without text using
response_modalities=['Image'].
Python
response = client.models.generate_content(
model="gemini-2.5-flash-image",
contents=[prompt],
config=types.GenerateContentConfig(
response_modalities=['Image']
)
)
JavaScript
const response = await ai.models.generateContent({
model: "gemini-2.5-flash-image",
contents: prompt,
config: {
responseModalities: ['Image']
}
});
Go
result, _ := client.Models.GenerateContent(
ctx,
"gemini-2.5-flash-image",
genai.Text("Create a picture of a nano banana dish in a " +
" fancy restaurant with a Gemini theme"),
&genai.GenerateContentConfig{
ResponseModalities: "Image",
},
)
Java
response = client.models.generateContent(
"gemini-2.5-flash-image",
prompt,
GenerateContentConfig.builder()
.responseModalities("IMAGE")
.build());
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{
"parts": [
{"text": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme"}
]
}],
"generationConfig": {
"responseModalities": ["Image"]
}
}'
Aspect ratios and image size
The model defaults to matching the output image size to that of your input
image, or otherwise generates 1:1 squares.
You can control the aspect ratio of the output image using the aspect_ratio
field under image_config in the response request, shown here:
Python
# For gemini-2.5-flash-image
response = client.models.generate_content(
model="gemini-2.5-flash-image",
contents=[prompt],
config=types.GenerateContentConfig(
image_config=types.ImageConfig(
aspect_ratio="16:9",
)
)
)
# For gemini-3-pro-image-preview
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=[prompt],
config=types.GenerateContentConfig(
image_config=types.ImageConfig(
aspect_ratio="16:9",
image_size="2K",
)
)
)
JavaScript
// For gemini-2.5-flash-image
const response = await ai.models.generateContent({
model: "gemini-2.5-flash-image",
contents: prompt,
config: {
imageConfig: {
aspectRatio: "16:9",
},
}
});
// For gemini-3-pro-image-preview
const response_gemini3 = await ai.models.generateContent({
model: "gemini-3-pro-image-preview",
contents: prompt,
config: {
imageConfig: {
aspectRatio: "16:9",
imageSize: "2K",
},
}
});
Go
// For gemini-2.5-flash-image
result, _ := client.Models.GenerateContent(
ctx,
"gemini-2.5-flash-image",
genai.Text("Create a picture of a nano banana dish in a " +
" fancy restaurant with a Gemini theme"),
&genai.GenerateContentConfig{
ImageConfig: &genai.ImageConfig{
AspectRatio: "16:9",
},
}
)
// For gemini-3-pro-image-preview
result_gemini3, _ := client.Models.GenerateContent(
ctx,
"gemini-3-pro-image-preview",
genai.Text("Create a picture of a nano banana dish in a " +
" fancy restaurant with a Gemini theme"),
&genai.GenerateContentConfig{
ImageConfig: &genai.ImageConfig{
AspectRatio: "16:9",
ImageSize: "2K",
},
}
)
Java
// For gemini-2.5-flash-image
response = client.models.generateContent(
"gemini-2.5-flash-image",
prompt,
GenerateContentConfig.builder()
.imageConfig(ImageConfig.builder()
.aspectRatio("16:9")
.build())
.build());
// For gemini-3-pro-image-preview
response_gemini3 = client.models.generateContent(
"gemini-3-pro-image-preview",
prompt,
GenerateContentConfig.builder()
.imageConfig(ImageConfig.builder()
.aspectRatio("16:9")
.imageSize("2K")
.build())
.build());
REST
# For gemini-2.5-flash-image
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"contents": [{
"parts": [
{"text": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme"}
]
}],
"generationConfig": {
"imageConfig": {
"aspectRatio": "16:9"
}
}
}'
# For gemini-3-pro-image-preview
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-image-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"contents": [{
"parts": [
{"text": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme"}
]
}],
"generationConfig": {
"imageConfig": {
"aspectRatio": "16:9",
"imageSize": "2K"
}
}
}'
The different ratios available and the size of the image generated are listed in the following tables:
Gemini 2.5 Flash Image
| Aspect ratio | Resolution | Tokens |
|---|---|---|
| 1:1 | 1024x1024 | 1290 |
| 2:3 | 832x1248 | 1290 |
| 3:2 | 1248x832 | 1290 |
| 3:4 | 864x1184 | 1290 |
| 4:3 | 1184x864 | 1290 |
| 4:5 | 896x1152 | 1290 |
| 5:4 | 1152x896 | 1290 |
| 9:16 | 768x1344 | 1290 |
| 16:9 | 1344x768 | 1290 |
| 21:9 | 1536x672 | 1290 |
Gemini 3 Pro Image Preview
| Aspect ratio | 1K resolution | 1K tokens | 2K resolution | 2K tokens | 4K resolution | 4K tokens |
|---|---|---|---|---|---|---|
| 1:1 | 1024x1024 | 1120 | 2048x2048 | 1120 | 4096x4096 | 2000 |
| 2:3 | 848x1264 | 1120 | 1696x2528 | 1120 | 3392x5056 | 2000 |
| 3:2 | 1264x848 | 1120 | 2528x1696 | 1120 | 5056x3392 | 2000 |
| 3:4 | 896x1200 | 1120 | 1792x2400 | 1120 | 3584x4800 | 2000 |
| 4:3 | 1200x896 | 1120 | 2400x1792 | 1120 | 4800x3584 | 2000 |
| 4:5 | 928x1152 | 1120 | 1856x2304 | 1120 | 3712x4608 | 2000 |
| 5:4 | 1152x928 | 1120 | 2304x1856 | 1120 | 4608x3712 | 2000 |
| 9:16 | 768x1376 | 1120 | 1536x2752 | 1120 | 3072x5504 | 2000 |
| 16:9 | 1376x768 | 1120 | 2752x1536 | 1120 | 5504x3072 | 2000 |
| 21:9 | 1584x672 | 1120 | 3168x1344 | 1120 | 6336x2688 | 2000 |
Model selection
Choose the model best suited for your specific use case.
Gemini 3 Pro Image Preview (Nano Banana Pro Preview) is designed for professional asset production and complex instructions. This model features real-world grounding using Google Search, a default "Thinking" process that refines composition prior to generation, and can generate images of up to 4K resolutions. Check the model pricing and capabilities page for more details.
Gemini 2.5 Flash Image (Nano Banana) is designed for speed and efficiency. This model is optimized for high-volume, low-latency tasks and generates images at 1024px resolution. Check the model pricing and capabilities page for more details.
When to use Imagen
In addition to using Gemini's built-in image generation capabilities, you can also access Imagen, our specialized image generation model, through the Gemini API.
Imagen 4 should be your go-to model when starting to generate images with Imagen. Choose Imagen 4 Ultra for advanced use-cases or when you need the best image quality (note that can only generate one image at a time).
What's next
- Find more examples and code samples in the cookbook guide.
- Check out the Veo guide to learn how to generate videos with the Gemini API.
- To learn more about Gemini models, see Gemini models.