Bildgenerierung mit Nano Banana
- Oder Sie erstellen Ihre eigene mit Prompts:
-








-
Generiert von Nano Banana 2 Eingabeaufforderung: „Ein Foto eines glänzenden Magazintitels. Das minimalistische blaue Cover hat die großen fett gedruckten Wörter ‚Nano Banana‘.“ Der Text ist in einer Serifenschriftart und füllt die Ansicht aus. Kein anderer Text. Vor dem Text ist ein Porträt einer Person in einem eleganten und minimalistischen Kleid zu sehen. Sie hält spielerisch die Zahl 2, die den Schwerpunkt bildet.
Platziere die Ausgabenummer und das Datum „Februar 2026“ zusammen mit einem Barcode in der Ecke. Die Zeitschrift liegt in einem Designergeschäft auf einem Regal vor einer orangefarbenen Wand.“ -
Generiert von Nano Banana Pro Prompt: „Erstelle eine klare, isometrische 3D-Miniatur-Cartoonszene aus der 45°-Draufsicht von London mit den berühmtesten Wahrzeichen und architektonischen Elementen. Verwende weiche, raffinierte Texturen mit realistischen PBR-Materialien und sanfter, lebensechter Beleuchtung und Schatten. Integrieren Sie die aktuellen Wetterbedingungen direkt in die Stadtumgebung, um eine immersive, atmosphärische Stimmung zu erzeugen. Verwende eine schlichte, minimalistische Komposition mit einem weichen, einfarbigen Hintergrund. Platziere oben in der Mitte den Titel „London“ in großer Schrift im Fettdruck, darunter ein auffälliges Wettersymbol, dann das Datum (kleine Schrift) und die Temperatur (mittlere Schrift). Der gesamte Text muss zentriert sein und einen einheitlichen Abstand haben. Er darf sich leicht mit den Dächern der Gebäude überschneiden.“ -
Generiert von Nano Banana 2 Prompt: „Verwende die Bildersuche, um genaue Bilder eines Quetzals zu finden. Erstelle ein schönes Hintergrundbild im Format 3:2 von diesem Vogel mit einem natürlichen Farbverlauf von oben nach unten und einer minimalistischen Komposition.“ -

Generiert von Nano Banana Pro Prompt: „Platziere dieses Logo in einer hochwertigen Anzeige für ein Parfüm mit Bananenduft. Das Logo ist perfekt in die Flasche integriert.“ -
Generiert von Nano Banana Pro Eingabeaufforderung: „Ein Foto einer Alltagsszene in einem belebten Café, in dem Frühstück serviert wird. Im Vordergrund ist ein Anime-Mann mit blauen Haaren zu sehen. Eine der Personen ist eine Bleistiftskizze, eine andere ist eine Claymation-Person.“ -
Generiert von Nano Banana Pro Prompt: „Finde mit der Suche heraus, wie die Einführung von Gemini 3 Flash aufgenommen wurde. Schreibe anhand dieser Informationen einen kurzen Artikel (mit Überschriften). Gib ein Foto des Artikels zurück, wie er in einem designorientierten Hochglanzmagazin erscheinen würde. Es ist ein Foto einer einzelnen umgeklappten Seite, auf der der Artikel über Gemini 3 Flash zu sehen ist. Ein Hero-Foto. Anzeigentitel in Serifenschrift.“ -
Generiert von Nano Banana Pro Prompt: „Ein Symbol, das einen niedlichen Hund darstellt. Der Hintergrund ist weiß. Gestalte die Symbole in einem farbenfrohen und taktilen 3D-Stil. Kein Text.“ -
Generiert von Nano Banana 2 Prompt: „Erstelle ein perfekt isometrisches Foto. Es handelt sich nicht um ein Miniaturbild, sondern um ein aufgenommenes Foto, das zufällig perfekt isometrisch ist. Es ist ein Foto eines wunderschönen modernen Gartens. Es ist ein großer Pool in Form einer 2 zu sehen und die Worte „Nano Banana 2“.
Nano Banana ist der Name für die nativen Bildgenerierungsfunktionen von Gemini. Gemini kann Bilder dialogorientiert mit Text, Bildern oder einer Kombination aus beidem generieren und verarbeiten. So können Sie visuelle Elemente mit beispielloser Kontrolle erstellen, bearbeiten und iterieren.
Nano Banana bezieht sich auf vier verschiedene Modelle, die in der Gemini API verfügbar sind:
- Nano Banana 2 Lite (Gemini 3.1 Flash Lite Image) (
gemini-3.1-flash-lite-image): Unser schnellstes und kostengünstigstes Gemini-Bildmodell, das auf Geschwindigkeit und Skalierbarkeit ausgelegt ist, wenn Geschwindigkeit und Kosten die primären betrieblichen Einschränkungen sind. Nicht für mehrere Referenzeingaben oder sequenzielle Bearbeitung in mehreren Schritten optimiert. - Nano Banana 2 (Gemini 3.1 Flash Image)
(
gemini-3.1-flash-image): Das vielseitigste Modell, das sich für alle Aufgaben eignet. Das Modell bietet eine gute Balance zwischen Geschwindigkeit und modernster 4K-Generierung, weltweitem Wissen und zuverlässigem Textrendering. Hervorragende Verarbeitung mehrerer Referenzbilder und hohe Konsistenz. - Nano Banana Pro (Gemini 3 Pro Image)
(
gemini-3-pro-image): Die Premium-Option für die komplexesten visuellen Aufgaben. Sie bietet das höchste Maß an Weltwissen, erweiterte Lokalisierung, genaue Markenkonsistenz und präzise kreative Kontrolle. - Nano Banana (Gemini 2.5 Flash Image) (
gemini-2.5-flash-image): Das ursprüngliche Modell der Nano Banana-Reihe. Das Modell war zwar immer zuverlässig, wir empfehlen Kunden jedoch dringend, auf Nano Banana 2 Lite umzusteigen, um von der verbesserten Qualität, der schnelleren Generierung und den niedrigeren API-Preisen zu profitieren.
Alle generierten Bilder enthalten ein SynthID-Wasserzeichen.
Bildgenerierung (Text-zu-Bild)
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme",
)
with open("generated_image.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const prompt =
"Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme";
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: prompt,
});
const generatedImage = interaction.output_image;
if (generatedImage) {
const buffer = Buffer.from(generatedImage.data, "base64");
fs.writeFileSync("gemini-native-image.png", buffer);
console.log("Image saved as gemini-native-image.png");
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{"type": "text", "text": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme"}
]
}'
Sie können generierte Bilddaten mit der Eigenschaft interaction.output_image abrufen, die den zuletzt generierten Bildblock zurückgibt. Weitere Informationen zu Convenience-Attributen finden Sie in der Übersicht zu Interaktionen.
Bildbearbeitung (Text-und-Bild-zu-Bild)
Zur Erinnerung: Sie müssen die erforderlichen Rechte an allen Bildern haben, die Sie hochladen. Erstelle keine Inhalte, durch die die Rechte anderer verletzt werden, einschließlich Videos oder Bildern, durch die andere getäuscht, belästigt oder geschädigt werden. Ihre Nutzung dieses auf generativer KI basierenden Dienstes unterliegt unserer Richtlinie zur unzulässigen Nutzung.
Sie können ein Bild bereitstellen und Text-Prompts verwenden, um Elemente hinzuzufügen, zu entfernen oder zu ändern, den Stil zu ändern oder die Farbkorrektur anzupassen.
Das folgende Beispiel zeigt das Hochladen von base64-codierten Bildern.
Informationen zu mehreren Bildern, größeren Nutzlasten und unterstützten MIME-Typen finden Sie auf der Seite Bildanalyse.
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open("/path/to/cat_image.png", "rb") as f:
image_bytes = f.read()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "text",
"text": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
}
],
)
with open("generated_image.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "path/to/cat_image.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const prompt = [
{ type: "text", text: "Create a picture of my cat eating a nano-banana in a" +
"fancy restaurant under the Gemini constellation" },
{
type: "image",
mime_type: "image/png",
data: base64Image
},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: prompt,
});
const generatedImage = interaction.output_image;
if (generatedImage) {
const buffer = Buffer.from(generatedImage.data, "base64");
fs.writeFileSync("gemini-native-image.png", buffer);
console.log("Image saved as gemini-native-image.png");
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"text\", \"text\": \"Create a picture of my cat eating a nano-banana in a fancy restaurant under the Gemini constellation\"},
{
\"type\": \"image\",
\"mime_type\": \"image/jpeg\",
\"data\": \"<BASE64_IMAGE_DATA>\"
}
]
}"
Multi-Turn-Bildbearbeitung
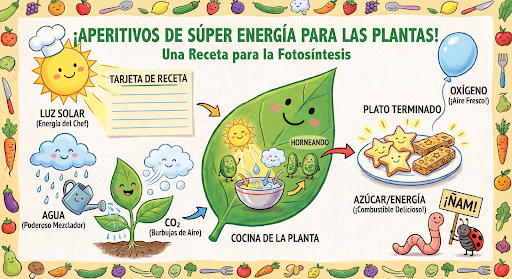
Bilder weiterhin dialogorientiert generieren und bearbeiten Multi-Turn-Unterhaltungen sind die empfohlene Methode, um Bilder zu optimieren. Im folgenden Beispiel wird ein Prompt zum Generieren einer Infografik zur Fotosynthese verwendet.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plant's favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids' cookbook, suitable for a 4th grader.",
tools=[{"type": "google_search"}],
)
with open("photosynthesis.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
const ai = new GoogleGenAI({});
async function main() {
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plant's favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids' cookbook, suitable for a 4th grader.",
tools: [{"type": "google_search"}],
});
const generatedImage = interaction.output_image;
if (generatedImage) {
const buffer = Buffer.from(generatedImage.data, "base64");
fs.writeFileSync("photosynthesis.png", buffer);
console.log("Image saved as photosynthesis.png");
}
}
await main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{"type": "text", "text": "Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plants favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids cookbook, suitable for a 4th grader."}
],
"tools": [{"type": "google_search"}]
}'

Anschließend können Sie previous_interaction_id verwenden, um die Sprache der Grafik in Spanisch zu ändern.
Python
interaction_2 = client.interactions.create(
model="gemini-3.1-flash-image",
input="Update this infographic to be in Spanish. Do not change any other elements of the image.",
previous_interaction_id=interaction.id,
response_format={
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9",
"image_size": "2K"
},
)
generated_image = interaction_2.output_image
if generated_image:
with open("photosynthesis_spanish.png", "wb") as f:
f.write(base64.b64decode(generated_image.data))
JavaScript
const interaction2 = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Update this infographic to be in Spanish. Do not change any other elements of the image.",
previous_interaction_id: interaction.id,
response_format: {
type: "image",
mime_type: "image/png",
aspect_ratio: "16:9",
image_size: "2K"
},
});
const generatedImage = interaction2.output_image;
if (generatedImage) {
const buffer = Buffer.from(generatedImage.data, "base64");
fs.writeFileSync("photosynthesis_spanish.png", buffer);
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Update this infographic to be in Spanish. Do not change any other elements of the image.",
"previous_interaction_id": "<PREVIOUS_INTERACTION_ID>",
"response_format": {
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9",
"image_size": "2K"
}
}'
Neu mit Gemini 3-Bildmodellen
Gemini 3 bietet hochmoderne Modelle für die Bildgenerierung und ‑bearbeitung. Gemini 3.1 Flash Image ist für Geschwindigkeit und Anwendungsfälle mit hohem Volumen optimiert, während Gemini 3 Pro Image für die professionelle Asset-Produktion optimiert ist. Sie wurden für die anspruchsvollsten Workflows entwickelt und können durch fortschrittliche Schlussfolgerungen komplexe Aufgaben mit mehreren Schritten bewältigen.
- Ausgabe in hoher Auflösung: Integrierte Funktionen zum Generieren von Bildern in 1K, 2K und 4K.
- Mit Gemini 3.1 Flash Image wird die kleinere Auflösung von 512 Pixeln (0,5K) hinzugefügt.
- Gemini 3.1 Flash Lite Image unterstützt nur 1K-Auflösung.
- Erweitertes Text-Rendering: Kann gut lesbaren, stilisierten Text für Infografiken, Menüs, Diagramme und Marketing-Assets generieren.
- Fundierung mit der Google Suche: Das Modell kann die Google Suche als Tool verwenden, um Fakten zu überprüfen und Bilder auf Grundlage von Echtzeitdaten zu generieren (z.B. aktuelle Wetterkarten, Aktiencharts, aktuelle Ereignisse).
- Wird vom Gemini 3.1 Flash Lite Image-Modell nicht unterstützt.
- Mit Gemini 3.1 Flash Image wird die Fundierung mit der Google Bildersuche zusätzlich zur Websuche eingeführt.
- Thinking-Modus: Das Modell verwendet einen „Denkprozess“, um komplexe Prompts zu analysieren. Es werden vorläufige „Gedankenbilder“ generiert (im Backend sichtbar, aber nicht kostenpflichtig), um die Komposition zu optimieren, bevor die endgültige hochwertige Ausgabe erstellt wird.
- Bis zu 14 Referenzbilder: Sie können jetzt bis zu 14 Referenzbilder kombinieren, um das endgültige Bild zu erstellen.
- Neue Seitenverhältnisse: Gemini 3.1 Flash Lite Image unterstützt die Seitenverhältnisse
1:1,3:2,2:3,3:4,4:3,4:5,5:4,9:16,16:9und21:9.
Bis zu 14 Referenzbilder verwenden
Mit Gemini 3-Bildmodellen können Sie bis zu 14 Referenzbilder kombinieren. Diese 14 Bilder können Folgendes enthalten:
| Gemini 3.1 Flash Lite Image | Gemini 3.1 Flash Image | Gemini 3 Pro Image |
|---|---|---|
| Bis zu 14 Bilder von Objekten mit hoher Wiedergabetreue, die in das endgültige Bild aufgenommen werden sollen | Bis zu 10 Bilder von Objekten mit hoher Wiedergabetreue, die in das endgültige Bild aufgenommen werden sollen | Bis zu sechs Bilder von Objekten mit hoher Detailtreue, die in das endgültige Bild aufgenommen werden sollen |
| – | Bis zu 4 Bilder von Figuren, um die Konsistenz der Figuren beizubehalten | Bis zu 5 Bilder von Figuren, um die Konsistenz der Figuren zu wahren |
| – | – | Bis zu 3 Bilder, die als Stilreferenzen verwendet werden sollen |
Python
from google import genai
from google.genai import types
from PIL import Image
import base64
prompt = "An office group photo of these people, they are making funny faces."
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "text",
"text": prompt,
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
],
response_format={
"type": "image",
"aspect_ratio": "5:4",
"image_size": "2K"
},
)
with open("office.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const input = [
{
type: "text",
text: "An office group photo of these people, they are making funny faces.",
},
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile1 },
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile2 },
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile3 },
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile4 },
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile5 },
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
response_format: {
type: "image",
aspect_ratio: "5:4",
image_size: "2K",
},
});
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('office.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"text\", \"text\": \"An office group photo of these people, they are making funny faces.\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_1>\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_2>\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_3>\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_4>\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_5>\"}
],
\"response_format\": {
\"type\": \"image\",
\"aspect_ratio\": \"5:4\",
\"image_size\": \"2K\"
}
}"

Fundierung mit der Google Suche
Mit dem Google Suche-Tool können Sie Bilder auf Grundlage von Echtzeitinformationen wie Wettervorhersagen, Aktiencharts oder aktuellen Ereignissen generieren.
Wenn Sie die Fundierung mit der Google Suche für die Bildgenerierung verwenden, werden bildbasierte Suchergebnisse nicht an das Generierungsmodell übergeben und sind von der Antwort ausgeschlossen (siehe Fundierung mit der Google Bildersuche).
Python
from google import genai
from google.genai import types
import base64
prompt = "Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day"
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=prompt,
tools=[{"type": "google_search"}],
response_format={
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9"
},
)
with open("weather.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day",
tools: [{"type": "google_search"}],
response_format: {
type: "image",
mime_type: "image/png",
aspect_ratio: "16:9",
image_size: "2K"
},
});
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('weather.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{"type": "text", "text": "Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day"}
],
"tools": [{"type": "google_search"}],
"response_format": {
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9"
}
}'

Die Antwort enthält die Schritte google_search_call und google_search_result sowie Inline-url_citation-Anmerkungen zum Textschritt:
google_search_result: Enthältsearch_suggestions, ein HTML-Snippet zum Rendern von Suchvorschlägen in Ihrer Benutzeroberfläche.url_citation-Anmerkungen: Inline-Zitate im Text, die Teile der Antwort mit ihren Webquellen verknüpfen.
Fundierung mit der Google Bildersuche (3.1 Flash)
Durch die Fundierung mit der Google Bildersuche können Modelle Webbilder, die über die Google Bildersuche abgerufen werden, als visuellen Kontext für die Bildgenerierung verwenden. Die Bildersuche ist ein neuer Suchtyp im vorhandenen Tool „Fundierung mit der Google Suche“, der neben der standardmäßigen Websuche funktioniert.
Wenn Sie die Bildersuche aktivieren möchten, konfigurieren Sie das google_search-Tool in Ihrer API-Anfrage und geben Sie image_search im search_types-Array an. Die Bildersuche kann unabhängig oder zusammen mit der Websuche verwendet werden.
Python
from google import genai
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A detailed painting of a Timareta butterfly resting on a flower",
tools=[{
"type": "google_search",
"search_types": ["web_search", "image_search"]
}]
)
JavaScript
import { GoogleGenAI } from "@google/genai";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A detailed painting of a Timareta butterfly resting on a flower",
tools: [{
"type": "google_search",
"search_types": ["web_search", "image_search"]
}]
});
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A detailed painting of a Timareta butterfly resting on a flower",
"tools": [{"type": "google_search", "search_types": ["web_search", "image_search"]}]
}'
Displayanforderungen
Wenn Sie die Bildersuche im Rahmen der Fundierung mit der Google Suche verwenden, müssen Sie die search_suggestions aus dem google_search_result-Schritt anzeigen. Die vollständigen Nutzungsanforderungen sind in den Nutzungsbedingungen beschrieben.
Antwort
Bei fundierten Antworten, für die die Bildersuche verwendet wird, gibt die API Inline-Zitationen und Attributionsmetadaten als Teil der Antwortschritte zurück:
url_citation-Anmerkungen: Inline-Zitationen im Textinhaltsblock innerhalb vonmodel_output, die den generierten Inhalt mit seiner Quelle verknüpfen.google_search_result: Enthältsearch_suggestions, ein HTML-Snippet zum Rendern von Suchvorschlägen in Ihrer Benutzeroberfläche.
Videobildgenerierung (3.1 Flash)
Mit der Funktion „Video zu Bild“ können Sie neue Bilder auf Grundlage des Kontexts eines Videos als multimodale Referenz generieren. Das ist nützlich, um hochwertige Video-Thumbnails, Kinoposter, zusammenfassende Infografiken oder neue Grafiken zu erstellen, die von einer Videoszene inspiriert sind.
Während der Generierung analysiert das Modell die Videoframes im Kontext, um visuelle Themen und Schlüsselereignisse zu extrahieren. Diese werden dann zusammen mit Ihrem Text-Prompt verwendet, um das Ausgabebild zu synthetisieren.
Sie können öffentliche YouTube-URLs direkt in Ihre API-Anfrage einfügen oder lokale Videodateien über die Files API hochladen.
Python
from google import genai
from google.genai import types
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "video",
"uri": "https://www.youtube.com/watch?v=UTdfxFyOQTI",
"mime_type": "video/mp4"
},
{"type": "text", "text": "Generate a poster image that captures the key themes of this video."}
],
response_format={"type": "image", "aspect_ratio": "16:9"}
)
# Save the generated image part
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("video_poster.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
print("Image saved as video_poster.png")
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: [
{
type: "video",
uri: "https://www.youtube.com/watch?v=UTdfxFyOQTI",
mime_type: "video/mp4"
},
{ type: "text", text: "Generate a poster image that captures the key themes of this video." }
],
response_format: {
type: "image",
aspect_ratio: "16:9"
}
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("video_poster.png", buffer);
console.log("Image saved as video_poster.png");
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{
"type": "video",
"uri": "https://www.youtube.com/watch?v=UTdfxFyOQTI",
"mime_type": "video/mp4"
},
{
"type": "text",
"text": "Generate a poster image that captures the key themes of this video."
}
],
"response_format": {
"type": "image",
"aspect_ratio": "16:9"
}
}'

Bilder mit einer Auflösung von bis zu 4K generieren
Gemini 3-Bildmodelle generieren standardmäßig Bilder mit 1.000 Pixeln, können aber auch Bilder mit 2.000 Pixeln, 4.000 Pixeln und 512 Pixeln (0,5 K) (nur Gemini 3.1 Flash Image) ausgeben. Wenn Sie Assets mit höherer Auflösung generieren möchten, geben Sie die image_size im response_format an.
Sie müssen ein großes „K“ verwenden, z.B. 512px (05.K), 1K, 2K, 4K. Parameter in Kleinbuchstaben (z.B. 1k) werden abgelehnt.
Python
from google import genai
from google.genai import types
import base64
prompt = "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English."
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=prompt,
response_format={
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "1:1",
"image_size": "1K"
},
)
print(interaction.output_text)
with open("butterfly.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English.",
response_format: {
type: "image",
mime_type: "image/png",
aspect_ratio: "1:1",
image_size: "1K",
},
});
console.log(interaction.output_text);
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('butterfly.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English.",
"response_format": {
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "1:1",
"image_size": "1K"
}
}'
Das folgende Bild wurde mit diesem Prompt generiert:

Denkprozess
Die Bildmodelle von Gemini 3 sind Thinking Models, die für komplexe Prompts einen Denkprozess („Thinking“) verwenden. Dieses Feature ist standardmäßig aktiviert und kann in der API nicht deaktiviert werden. Weitere Informationen zum Denkprozess finden Sie im Leitfaden Gemini Thinking.
Das Modell generiert bis zu zwei Zwischenbilder, um Komposition und Logik zu testen. Das letzte Bild unter „Thinking“ ist auch das endgültige gerenderte Bild.
Sie können sich die Überlegungen ansehen, die zur Erstellung des endgültigen Bildes geführt haben.
Python
for step in interaction.steps:
if step.type == "thought":
for content_block in step.summary:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
image = Image.open(io.BytesIO(base64.b64decode(content_block.data)))
image.show()
JavaScript
for (const step of interaction.steps) {
if (step.type === "thought") {
for (const contentBlock of step.summary) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, 'base64');
fs.writeFileSync('thought_image.png', buffer);
}
}
}
}
Verschachtelte Texte und Bilder
Während Standardmodelle zur Bildgenerierung nur Bilder ausgeben, können einige fortschrittliche Gemini 3-Modelle (z. B. gemini-3-pro-image) verschachtelte Inhalte generieren, z. B. Geschichten oder Anleitungen, die sowohl Textblöcke als auch Illustrationen in derselben Antwort enthalten.
Da die Ausgabe komplex und verschachtelt ist, wird die vollständige Sequenz nicht durch Convenience-Properties wie .output_image oder .output_text erfasst. Um auf verschachtelte Inhalte zuzugreifen und sie zu speichern, müssen Sie manuell über steps iterieren:
Python
interaction = client.interactions.create(
model="gemini-3-pro-image",
input="Write the story of the lifecycle of a monarch butterfly, interleave illustrations",
)
image_counter = 1
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
filename = f"butterfly_lifecycle_{image_counter}.png"
with open(filename, "wb") as f:
f.write(base64.b64decode(content_block.data))
print(f"\n[Saved illustration: {filename}]\n")
image_counter += 1
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3-pro-image",
input: "Write the story of the lifecycle of a monarch butterfly, interleave illustrations",
});
let imageCounter = 1;
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
const filename = `butterfly_lifecycle_${imageCounter}.png`;
fs.writeFileSync(filename, buffer);
console.log(`\n[Saved illustration: ${filename}]\n`);
imageCounter++;
}
}
}
}
Denkaufwand steuern
Mit Gemini 3.1 Flash Image können Sie steuern, wie viel das Modell nachdenkt, um ein Gleichgewicht zwischen Qualität und Latenz zu schaffen. Der Standardwert für thinking_level ist minimal und die unterstützten Ebenen sind minimal und high.
Python
from google import genai
from PIL import Image
import base64
import io
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A futuristic city built inside a giant glass bottle floating in space",
generation_config={"thinking_level": "high"},
)
print(interaction.output_text)
image = Image.open(io.BytesIO(base64.b64decode(interaction.output_image.data)))
image.show()
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A futuristic city built inside a giant glass bottle floating in space",
generation_config: { thinking_level: "high" },
});
console.log(interaction.output_text);
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('image.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A futuristic city built inside a giant glass bottle floating in space",
"generation_config": {
"thinking_level": "high"
}
}'
Hinweis: Denk-Tokens werden standardmäßig für Denkmodelle abgerechnet, da der Denkprozess immer standardmäßig erfolgt, unabhängig davon, ob Sie ihn ansehen oder nicht.
Andere Modi zur Bildgenerierung
Obwohl die Nano Banana-Modelle zur Bildgenerierung für die meisten Anwendungsfälle empfohlen werden, können Sie auch spezielle Modelle zur Bildgenerierung verwenden:
- Imagen: Die Text-zu-Bild-Modelle von Google sind für die Generierung hochwertiger Bilder optimiert.
- Veo: Das Videogenerierungsmodell von Google.
Bilder im Batch generieren
Alle auf dieser Seite beschriebenen Funktionen zur Bildgenerierung können auch als Batch-Jobs über die Batch API ausgeführt werden. Das ist ideal, wenn Sie viele Bilder generieren müssen. Sie erhalten höhere Ratenlimits im Austausch für eine Bearbeitungszeit von bis zu 24 Stunden.
Anleitung und Strategien für Prompts
In diesem Abschnitt finden Sie Beispiele für Prompts und Vorlagen für gängige Workflows zur Bildgenerierung und ‑bearbeitung. Jedes Beispiel enthält eine wiederverwendbare Vorlage und einen Beispielprompt für die Interactions API.
Prompts zum Generieren von Bildern
In den folgenden Beispielen wird gezeigt, wie Sie mit Text-Prompts verschiedene Arten von Bildern generieren können.
1. Fotorealistische Szenen
Beschreiben Sie eine Szene detailliert. Je genauer Sie sind, desto mehr Kontrolle haben Sie über die Ergebnisse.
Vorlage
A photorealistic [type of shot] of a [subject description] in a [setting
description]. [Description of the light]. Shot from a [camera angle]
with a [lens type].
Prompt
A photorealistic wide-angle shot of a vibrant coral reef teeming with tropical fish. Crystal-clear turquoise water with sunbeams filtering down from the surface, illuminating a sea turtle gliding gracefully over the coral. Shot from a low perspective with a wide-angle lens. Aspect ratio 16:9.
Python
from google import genai
from google.genai import types
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A photorealistic wide-angle shot of a vibrant coral reef teeming with tropical fish. Crystal-clear turquoise water with sunbeams filtering down from the surface, illuminating a sea turtle gliding gracefully over the coral. Shot from a low perspective with a wide-angle lens. Aspect ratio 16:9.",
response_format=[
{
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9",
}
],
)
print(interaction.output_text)
with open("coral_reef.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A photorealistic wide-angle shot of a vibrant coral reef teeming with tropical fish. Crystal-clear turquoise water with sunbeams filtering down from the surface, illuminating a sea turtle gliding gracefully over the coral. Shot from a low perspective with a wide-angle lens. Aspect ratio 16:9.",
response_format: [
{
type: "image",
mime_type: "image/jpeg",
aspect_ratio: "16:9",
}
],
});
console.log(interaction.output_text);
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('coral_reef.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A photorealistic wide-angle shot of a vibrant coral reef teeming with tropical fish. Crystal-clear turquoise water with sunbeams filtering down from the surface, illuminating a sea turtle gliding gracefully over the coral. Shot from a low perspective with a wide-angle lens. Aspect ratio 16:9.",
"response_format": {
"type": "image",
"mime_type": "image/png",
"aspect_ratio": "16:9"
}
}'

2. Stilisierte Illustrationen und Sticker
Beschreiben Sie den künstlerischen Stil, das Motiv und das Medium. Geben Sie die visuellen Details (fette Linien, Farben usw.) genau an, um einheitliche Ergebnisse zu erhalten.
Vorlage
A [style] of a [subject, with details about accessories or actions]
doing [activity]. The design features [visual qualities, e.g., bold outlines,
cel-shading, etc.] and [color/background preference].
Prompt
A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It's munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It's munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white.",
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("red_panda_sticker.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It's munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white.",
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("red_panda_sticker.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It is munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white."
}'

3. Genaue Darstellung von Text in Bildern
Gemini zeichnet sich durch die Darstellung von Text aus. Beschreiben Sie den Text, die Schriftart und das Gesamtdesign so genau wie möglich. Gemini 3 Pro Image für die professionelle Asset-Produktion verwenden.
Vorlage
Create a [image type] for [brand/concept] with the text "[text to render]"
in a [font style]. The design should be [style description], with a
[color scheme].
Prompt
Create a modern, minimalist logo for a coffee shop called 'The Daily Grind'. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Create a modern, minimalist logo for a coffee shop called 'The Daily Grind'. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way.",
response_format={"type": "image", "aspect_ratio": "1:1"},
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("logo_example.jpg", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Create a modern, minimalist logo for a coffee shop called 'The Daily Grind'. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way.",
response_format: { type: "image", aspect_ratio: "1:1" },
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("logo_example.jpg", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Create a modern, minimalist logo for a coffee shop called The Daily Grind. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way.",
"response_format": {
"type": "image",
"aspect_ratio": "1:1"
}
}'
4. Produkt-Mockups und kommerzielle Fotografie
Ideal für die Erstellung von sauberen, professionellen Produktbildern für E-Commerce, Werbung oder Branding.
Vorlage
A high-resolution, studio-lit product photograph of a [product description]
on a [background surface/description]. The lighting is a [lighting setup,
e.g., three-point softbox setup] to [lighting purpose]. The camera angle is
a [angle type] to showcase [specific feature]. Ultra-realistic, with sharp
focus on [key detail]. [Aspect ratio].
Prompt
A high-resolution, studio-lit product photograph of a minimalist ceramic
coffee mug in matte black, presented on a polished concrete surface. The
lighting is a three-point softbox setup designed to create soft, diffused
highlights and eliminate harsh shadows. The camera angle is a slightly
elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with
sharp focus on the steam rising from the coffee. Square image.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A high-resolution, studio-lit product photograph of a minimalist ceramic coffee mug in matte black, presented on a polished concrete surface. The lighting is a three-point softbox setup designed to create soft, diffused highlights and eliminate harsh shadows. The camera angle is a slightly elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with sharp focus on the steam rising from the coffee. Square image.",
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("product_mockup.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A high-resolution, studio-lit product photograph of a minimalist ceramic coffee mug in matte black, presented on a polished concrete surface. The lighting is a three-point softbox setup designed to create soft, diffused highlights and eliminate harsh shadows. The camera angle is a slightly elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with sharp focus on the steam rising from the coffee. Square image.",
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("product_mockup.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A high-resolution, studio-lit product photograph of a minimalist ceramic coffee mug in matte black, presented on a polished concrete surface. The lighting is a three-point softbox setup designed to create soft, diffused highlights and eliminate harsh shadows. The camera angle is a slightly elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with sharp focus on the steam rising from the coffee. Square image."
}'

5. Minimalistisches Design mit Negativraum
Hervorragend geeignet für Hintergründe für Websites, Präsentationen oder Marketingmaterialien, auf denen Text eingeblendet werden soll.
Vorlage
A minimalist composition featuring a single [subject] positioned in the
[bottom-right/top-left/etc.] of the frame. The background is a vast, empty
[color] canvas, creating significant negative space. Soft, subtle lighting.
[Aspect ratio].
Prompt
A minimalist composition featuring a single, delicate red maple leaf
positioned in the bottom-right of the frame. The background is a vast, empty
off-white canvas, creating significant negative space for text. Soft,
diffused lighting from the top left. Square image.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A minimalist composition featuring a single, delicate red maple leaf positioned in the bottom-right of the frame. The background is a vast, empty off-white canvas, creating significant negative space for text. Soft, diffused lighting from the top left. Square image.",
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("minimalist_design.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A minimalist composition featuring a single, delicate red maple leaf positioned in the bottom-right of the frame. The background is a vast, empty off-white canvas, creating significant negative space for text. Soft, diffused lighting from the top left. Square image.",
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("minimalist_design.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A minimalist composition featuring a single, delicate red maple leaf positioned in the bottom-right of the frame. The background is a vast, empty off-white canvas, creating significant negative space for text. Soft, diffused lighting from the top left. Square image."
}'

6. Sequenzielle Kunst (Comic-Panel / Storyboard)
Baut auf der Konsistenz der Charaktere und der Szenenbeschreibung auf, um Panels für das visuelle Storytelling zu erstellen. Für Genauigkeit bei Text und Storytelling eignen sich diese Prompts am besten für Gemini 3 Pro und Gemini 3.1 Flash Image.
Vorlage
Make a 3 panel comic in a [style]. Put the character in a [type of scene].
Prompt
Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene.
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/man_in_white_glasses.jpg', 'rb') as f:
image_bytes = f.read()
text_input = "Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene."
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{"type": "text", "text": text_input},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/jpeg"
}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("comic_panel.jpg", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/man_in_white_glasses.jpg";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const input = [
{ type: "text", text: "Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene." },
{
type: "image",
mime_type: "image/jpeg",
data: base64Image
},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("comic_panel.jpg", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{"type": "text", "text": "Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene."},
{"type": "image", "data": "<BASE64_IMAGE_DATA>", "mime_type": "image/jpeg"}
]
}'
Eingabe |
Ausgabe |

|

|
7. Fundierung mit der Google Suche
Mit der Google Suche Bilder auf Grundlage aktueller oder Echtzeitinformationen generieren Das ist nützlich für Nachrichten, Wetterberichte und andere zeitkritische Themen.
Prompt
Make a simple but stylish graphic of last night's Arsenal game in the Champion's League
Python
from google import genai
from google.genai import types
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Make a simple but stylish graphic of last night's Arsenal game in the Champion's League",
tools=[{"type": "google_search"}],
response_format={"type": "image", "aspect_ratio": "16:9"},
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("football-score.jpg", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Make a simple but stylish graphic of last night's Arsenal game in the Champion's League",
tools: [{ type: "google_search" }],
response_format: { type: "image", aspect_ratio: "16:9", image_size: "2K" },
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("football-score.jpg", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Make a simple but stylish graphic of last nights Arsenal game in the Champions League",
"tools": [{"type": "google_search"}],
"response_format": {
"type": "image",
"aspect_ratio": "16:9"
}
}'

Prompts zum Bearbeiten von Bildern
In diesen Beispielen wird gezeigt, wie Sie Bilder zusammen mit Ihren Text-Prompts für die Bearbeitung, Komposition und Stilübertragung bereitstellen.
1. Elemente hinzufügen und entfernen
Stellen Sie ein Bild bereit und beschreiben Sie die Änderung. Das Modell entspricht dem Stil, der Beleuchtung und der Perspektive des Originalbilds.
Vorlage
Using the provided image of [subject], please [add/remove/modify] [element]
to/from the scene. Ensure the change is [description of how the change should
integrate].
Prompt
"Using the provided image of my cat, please add a small, knitted wizard hat
on its head. Make it look like it's sitting comfortably and matches the soft
lighting of the photo."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/cat_photo.png', 'rb') as f:
image_bytes = f.read()
text_input = """Using the provided image of my cat, please add a small, knitted wizard hat on its head. Make it look like it's sitting comfortably and not falling off."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{"type": "text", "text": text_input},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("cat_with_hat.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/cat_photo.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const input = [
{ type: "text", text: "Using the provided image of my cat, please add a small, knitted wizard hat on its head. Make it look like it's sitting comfortably and not falling off." },
{
type: "image",
mime_type: "image/png",
data: base64Image
},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("cat_with_hat.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"text\", \"text\": \"Using the provided image of my cat, please add a small, knitted wizard hat on its head. Make it look like it's sitting comfortably and not falling off.\"},
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA>\"}
]
}"
Eingabe |
Ausgabe |

|

|
2. Übermalen (semantische Maskierung)
Sie können eine „Maske“ im Dialog definieren, um einen bestimmten Teil eines Bildes zu bearbeiten, während der Rest unverändert bleibt.
Vorlage
Using the provided image, change only the [specific element] to [new
element/description]. Keep everything else in the image exactly the same,
preserving the original style, lighting, and composition.
Prompt
"Using the provided image of a living room, change only the blue sofa to be
a vintage, brown leather chesterfield sofa. Keep the rest of the room,
including the pillows on the sofa and the lighting, unchanged."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/living_room.png', 'rb') as f:
image_bytes = f.read()
text_input = """Using the provided image of a living room, change only the blue sofa to be a vintage, brown leather chesterfield sofa. Keep the rest of the room, including the pillows on the sofa and the lighting, unchanged."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("living_room_edited.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/living_room.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const input = [
{
type: "image",
mime_type: "image/png",
data: base64Image
},
{ type: "text", text: "Using the provided image of a living room, change only the blue sofa to be a vintage, brown leather chesterfield sofa. Keep the rest of the room, including the pillows on the sofa and the lighting, unchanged." },
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("living_room_edited.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA>\"},
{\"type\": \"text\", \"text\": \"Using the provided image of a living room, change only the blue sofa to be a vintage, brown leather chesterfield sofa. Keep the rest of the room, including the pillows on the sofa and the lighting, unchanged.\"}
]
}"
Eingabe |
Ausgabe |

|

|
3. Stilübertragung
Stellen Sie ein Bild zur Verfügung und bitten Sie das Modell, den Inhalt in einem anderen künstlerischen Stil neu zu erstellen.
Vorlage
Transform the provided photograph of [subject] into the artistic style of [artist/art style]. Preserve the original composition but render it with [description of stylistic elements].
Prompt
"Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/city.png', 'rb') as f:
image_bytes = f.read()
text_input = """Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("city_style_transfer.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imageData = fs.readFileSync("/path/to/your/city.png");
const base64Image = imageData.toString("base64");
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: [
{
type: "image",
mime_type: "image/png",
data: base64Image
},
{ type: "text", text: "Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows." },
],
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("city_style_transfer.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA>\"},
{\"type\": \"text\", \"text\": \"Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows.\"}
]
}"
Eingabe |
Ausgabe |

|

|
4. Erweiterte Komposition: Mehrere Bilder kombinieren
Stellen Sie mehrere Bilder als Kontext bereit, um eine neue, zusammengesetzte Szene zu erstellen. Das ist ideal für Produkt-Mockups oder kreative Collagen.
Vorlage
Create a new image by combining the elements from the provided images. Take
the [element from image 1] and place it with/on the [element from image 2].
The final image should be a [description of the final scene].
Prompt
"Create a professional e-commerce fashion photo. Take the blue floral dress
from the first image and let the woman from the second image wear it.
Generate a realistic, full-body shot of the woman wearing the dress, with
the lighting and shadows adjusted to match the outdoor environment."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/dress.png', 'rb') as f:
dress_bytes = f.read()
with open('/path/to/your/model.png', 'rb') as f:
model_bytes = f.read()
text_input = """Create a professional e-commerce fashion photo. Take the blue floral dress from the first image and let the woman from the second image wear it. Generate a realistic, full-body shot of the woman wearing the dress, with the lighting and shadows adjusted to match the outdoor environment."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "image",
"data": base64.b64encode(dress_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(model_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("fashion_ecommerce_shot.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath1 = "/path/to/your/dress.png";
const imageData1 = fs.readFileSync(imagePath1);
const base64Image1 = imageData1.toString("base64");
const imagePath2 = "/path/to/your/model.png";
const imageData2 = fs.readFileSync(imagePath2);
const base64Image2 = imageData2.toString("base64");
const input = [
{
type: "image",
mime_type: "image/png",
data: base64Image1
},
{
type: "image",
mime_type: "image/png",
data: base64Image2
},
{ type: "text", text: "Create a professional e-commerce fashion photo. Take the blue floral dress from the first image and let the woman from the second image wear it. Generate a realistic, full-body shot of the woman wearing the dress, with the lighting and shadows adjusted to match the outdoor environment." },
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("fashion_ecommerce_shot.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA_1>\"},
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA_2>\"},
{\"type\": \"text\", \"text\": \"Create a professional e-commerce fashion photo. Take the blue floral dress from the first image and let the woman from the second image wear it. Generate a realistic, full-body shot of the woman wearing the dress, with the lighting and shadows adjusted to match the outdoor environment.\"}
}]
}"
Eingabe 1 |
Eingabe 2 |
Ausgabe |

|

|

|
5. High-Fidelity-Detailerhaltung
Damit wichtige Details wie ein Gesicht oder ein Logo bei der Bearbeitung erhalten bleiben, beschreiben Sie sie zusammen mit Ihrem Bearbeitungswunsch sehr detailliert.
Vorlage
Using the provided images, place [element from image 2] onto [element from
image 1]. Ensure that the features of [element from image 1] remain
completely unchanged. The added element should [description of how the
element should integrate].
Prompt
"Take the first image of the woman with brown hair, blue eyes, and a neutral
expression. Add the logo from the second image onto her black t-shirt.
Ensure the woman's face and features remain completely unchanged. The logo
should look like it's naturally printed on the fabric, following the folds
of the shirt."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/woman.png', 'rb') as f:
woman_bytes = f.read()
with open('/path/to/your/logo.png', 'rb') as f:
logo_bytes = f.read()
text_input = """Take the first image of the woman with brown hair, blue eyes, and a neutral expression. Add the logo from the second image onto her black t-shirt. Ensure the woman's face and features remain completely unchanged. The logo should look like it's naturally printed on the fabric, following the folds of the shirt."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{"type": "image", "mime_type":"image/png", "data": base64.b64encode(woman_bytes).decode('utf-8')},
{"type": "image", "mime_type":"image/png", "data": base64.b64encode(logo_bytes).decode('utf-8')},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("woman_with_logo.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath1 = "/path/to/your/woman.png";
const imageData1 = fs.readFileSync(imagePath1);
const base64Image1 = imageData1.toString("base64");
const imagePath2 = "/path/to/your/logo.png";
const imageData2 = fs.readFileSync(imagePath2);
const base64Image2 = imageData2.toString("base64");
const input = [
{"type": "image", "mime_type":"image/png", "data": base64Image1},
{"type": "image", "mime_type":"image/png", "data": base64Image2},
{"type": "text", "text": "Take the first image of the woman with brown hair, blue eyes, and a neutral expression. Add the logo from the second image onto her black t-shirt. Ensure the woman's face and features remain completely unchanged. The logo should look like it's naturally printed on the fabric, following the folds of the shirt."},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("woman_with_logo.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA_1>\"},
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA_2>\"},
{\"type\": \"text\", \"text\": \"Take the first image of the woman with brown hair, blue eyes, and a neutral expression. Add the logo from the second image onto her black t-shirt. Ensure the woman's face and features remain completely unchanged. The logo should look like it's naturally printed on the fabric, following the folds of the shirt.\"}
]
}"
Eingabe 1 |
Eingabe 2 |
Ausgabe |

|
|
|
6. Etwas zum Leben erwecken
Laden Sie eine grobe Skizze oder Zeichnung hoch und bitten Sie das Modell, sie in ein fertiges Bild umzuwandeln.
Vorlage
Turn this rough [medium] sketch of a [subject] into a [style description]
photo. Keep the [specific features] from the sketch but add [new details/materials].
Prompt
"Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/car_sketch.png', 'rb') as f:
sketch_bytes = f.read()
text_input = """Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{"type": "image", "mime_type":"image/png", "data": base64.b64encode(sketch_bytes).decode('utf-8')},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("car_photo.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/car_sketch.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const input = [
{"type": "image", "mime_type":"image/png", "data": base64Image},
{"type": "text", "text": "Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting."},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("car_photo.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA>\"},
{\"type\": \"text\", \"text\": \"Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting.\"}
]
}"
Eingabe |
Ausgabe |

|

|
7. Charaktere mit Wiedererkennungswert: 360°-Ansicht
Sie können 360-Grad-Ansichten einer Figur generieren, indem Sie iterativ Prompts für verschiedene Winkel eingeben. Die besten Ergebnisse erzielen Sie, wenn Sie zuvor generierte Bilder in nachfolgende Prompts einfügen, um die Konsistenz zu wahren. Fügen Sie für komplexe Posen ein Referenzbild der ausgewählten Pose hinzu.
Vorlage
A studio portrait of [person] against [background], [looking forward/in profile looking right/etc.]
Prompt
A studio portrait of this man against white, in profile looking right
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/man_in_white_glasses.jpg', 'rb') as f:
image_bytes = f.read()
text_input = """A studio portrait of this man against white, in profile looking right"""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input={
{"type": "text", "text": text_input},
{"type": "image", "mime_type":"image/png", "data": base64.b64encode(image_bytes).decode('utf-8')}
},
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("man_right_profile.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
Eingabe |
Ausgabe 1 |
Ausgabe 2 |
|
|

|

|
Best Practices
Mit diesen professionellen Strategien können Sie Ihre Ergebnisse noch weiter verbessern.
- Seien Sie sehr spezifisch:Je mehr Details Sie angeben, desto mehr Kontrolle haben Sie. Beschreiben Sie die Rüstung, anstatt nur „Fantasy-Rüstung“ zu schreiben: „aufwendige elfenhafte Plattenrüstung, geätzt mit silbernen Blattmustern, mit hohem Kragen und Schulterstücken in Form von Falkenflügeln“.
- Kontext und Zweck angeben:Erläutern Sie den Zweck des Bildes. Das Kontextverständnis des Modells beeinflusst die endgültige Ausgabe. Ein Prompt wie „Erstelle ein Logo für eine hochwertige, minimalistische Hautpflegemarke“ liefert bessere Ergebnisse als „Erstelle ein Logo“.
- Wiederholen und verfeinern:Erwarten Sie nicht, dass Sie beim ersten Versuch ein perfektes Bild erhalten. Nutzen Sie die Konversationsfunktion des Modells, um kleine Änderungen vorzunehmen. Verwende Folge-Prompts wie „Das ist toll, aber kannst du die Beleuchtung etwas wärmer gestalten?“ oder „Lass alles so, aber ändere den Gesichtsausdruck der Figur zu einem ernsteren.“
- Schritt-für-Schritt-Anleitung verwenden:Bei komplexen Szenen mit vielen Elementen sollten Sie Ihren Prompt in Schritte unterteilen. „Erstelle zuerst einen Hintergrund mit einem ruhigen, nebligen Wald bei Sonnenaufgang. Fügen Sie dann im Vordergrund einen moosbewachsenen alten Steinaltar hinzu. Lege schließlich ein einzelnes, glühendes Schwert auf den Altar.“
- Semantische negative Prompts verwenden: Anstatt „keine Autos“ zu sagen, beschreiben Sie die gewünschte Szene positiv: „eine leere, verlassene Straße ohne Anzeichen von Verkehr“.
- Kamera steuern:Verwenden Sie fotografische und filmische Sprache, um die Komposition zu steuern. Begriffe wie
wide-angle shot,macro shot,low-angle perspective.
Beschränkungen
- Die beste Leistung erzielen Sie, wenn Sie die folgenden Sprachen verwenden: EN, ar-EG, de-DE, es-MX, fr-FR, hi-IN, id-ID, it-IT, ja-JP, ko-KR, pt-BR, ru-RU, ua-UA, vi-VN, zh-CN.
- Bei der Bildgenerierung werden keine Audioeingaben unterstützt. Videoeingaben werden nur für Gemini 3.1 Flash Image unterstützt.
- Das Modell gibt nicht immer genau die Anzahl von Bildern aus, die der Nutzer explizit anfordert.
gemini-2.5-flash-imagefunktioniert am besten mit bis zu 3 Eingabebildern, währendgemini-3-pro-imagebis zu 5 Bilder mit hoher Qualität und insgesamt bis zu 14 Bilder unterstützt.gemini-3.1-flash-imageunterstützt die Ähnlichkeit von bis zu vier Zeichen und die Wiedergabetreue von bis zu zehn Objekten in einem einzelnen Workflow.- Wenn Sie Text für ein Bild generieren, funktioniert Gemini am besten, wenn Sie zuerst den Text generieren und dann ein Bild mit dem Text anfordern.
gemini-3.1-flash-imageDie Fundierung mit der Google Suche unterstützt derzeit nicht die Verwendung von realen Bildern von Personen aus der Websuche.- Alle generierten Bilder enthalten ein SynthID-Wasserzeichen.
Optionale Konfigurationen
Optional können Sie das Ausgabeformat, das Seitenverhältnis und die Bildgröße mit dem Parameter response_format konfigurieren.
Ausgabeformat
Standardmäßig gibt das Modell sowohl Text- als auch Bildantworten zurück. Sie können die Antwort so konfigurieren, dass nur die generierten Bilder zurückgegeben werden (ohne den Konversationstext), indem Sie im Parameter response_format ein Bildformat angeben.
Wenn Sie mehrere Modalitäten anfordern möchten (z. B. sowohl Text als auch das generierte Bild), übergeben Sie stattdessen ein Array von Formateinträgen an response_format.
Python
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Write a short poem about a starry night and generate an image of it.",
response_format=[
{"type": "text"},
{"type": "image"},
],
)
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Write a short poem about a starry night and generate an image of it.",
response_format: [
{ type: "text" },
{ type: "image" },
],
});
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Write a short poem about a starry night and generate an image of it.",
"response_format": [
{ "type": "text" },
{ "type": "image" }
]
}'
Seitenverhältnisse und Bildgröße
Standardmäßig passt das Modell die Bildgröße des Ausgabebilds an die des Eingabebilds an. Andernfalls werden 1:1-Quadrate generiert. Sie können das Seitenverhältnis und die Größe des Ausgabebildes mit den Feldern aspect_ratio und image_size unter response_format steuern, wenn type auf "image" festgelegt ist.
Python
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=prompt,
response_format={
"type": "image",
"aspect_ratio": "16:9",
"image_size": "2K",
},
)
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: prompt,
response_format: {
type: "image",
aspect_ratio: "16:9",
image_size: "2K",
},
});
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme",
"response_format": {
"type": "image",
"aspect_ratio": "16:9",
"image_size": "2K"
}
}'
Die verfügbaren Seitenverhältnisse und die Größe des generierten Bildes sind in den folgenden Tabellen aufgeführt:
3.1 Flash Image
| Seitenverhältnis | Auflösung: 512 Pixel | 500 Tokens | 1K-Auflösung | 1.000 Tokens | 2K-Auflösung | 2.000 Tokens | 4K-Auflösung | 4.000 Tokens |
|---|---|---|---|---|---|---|---|---|
| 1:1 | 512 x 512 | 747 | 1024x1024 | 1.120 | 2.048 x 2.048 | 1.120 | 4096 x 4096 | 2000 |
| 1:4 | 256 × 1.024 | 747 | 512 × 2.048 | 1.120 | 1024 × 4096 | 1.120 | 2.048 × 8.192 | 2000 |
| 1:8 | 192 × 1536 | 747 | 384 × 3072 | 1.120 | 768 × 6144 | 1.120 | 1536 × 12288 | 2000 |
| 2:3 | 424 × 632 | 747 | 848 × 1264 | 1.120 | 1696 × 2528 | 1.120 | 3392 × 5056 | 2000 |
| 3:2 | 632 × 424 | 747 | 1264 × 848 | 1.120 | 2528 × 1696 | 1.120 | 5056 × 3392 | 2000 |
| 3:4 | 448 × 600 | 747 | 896 × 1200 | 1.120 | 1792 × 2400 | 1.120 | 3584 × 4800 | 2000 |
| 4:1 | 1024 × 256 | 747 | 2.048 × 512 | 1.120 | 4096 x 1024 | 1.120 | 8.192 × 2.048 | 2000 |
| 4:3 | 600 × 448 | 747 | 1200 × 896 | 1.120 | 2400 × 1792 | 1.120 | 4800 × 3584 | 2000 |
| 4:5 | 464 × 576 | 747 | 928 × 1.152 | 1.120 | 1856 × 2304 | 1.120 | 3712 × 4608 | 2000 |
| 5:4 | 576 × 464 | 747 | 1152 × 928 | 1.120 | 2304 × 1856 | 1.120 | 4608 × 3712 | 2000 |
| 8:1 | 1536 × 192 | 747 | 3072 × 384 | 1.120 | 6144 × 768 | 1.120 | 12288 x 1536 | 2000 |
| 9:16 | 384 × 688 | 747 | 768 × 1376 | 1.120 | 1536 × 2752 | 1.120 | 3072 × 5504 | 2000 |
| 16:9 | 688 × 384 | 747 | 1376 × 768 | 1.120 | 2752 × 1536 | 1.120 | 5504 × 3072 | 2000 |
| 21:9 | 792 × 168 | 747 | 1584 × 672 | 1.120 | 3168 × 1344 | 1.120 | 6336 × 2688 | 2000 |
3.1 Pro Image
| Seitenverhältnis | 1K-Auflösung | 1.000 Tokens | 2K-Auflösung | 2.000 Tokens | 4K-Auflösung | 4.000 Tokens |
|---|---|---|---|---|---|---|
| 1:1 | 1024x1024 | 1.120 | 2.048 x 2.048 | 1.120 | 4096 x 4096 | 2000 |
| 2:3 | 848 × 1264 | 1.120 | 1696 × 2528 | 1.120 | 3392 × 5056 | 2000 |
| 3:2 | 1264 × 848 | 1.120 | 2528 × 1696 | 1.120 | 5056 × 3392 | 2000 |
| 3:4 | 896 × 1200 | 1.120 | 1792 × 2400 | 1.120 | 3584 × 4800 | 2000 |
| 4:3 | 1200 × 896 | 1.120 | 2400 × 1792 | 1.120 | 4800 × 3584 | 2000 |
| 4:5 | 928 × 1.152 | 1.120 | 1856 × 2304 | 1.120 | 3712 × 4608 | 2000 |
| 5:4 | 1152 × 928 | 1.120 | 2304 × 1856 | 1.120 | 4608 × 3712 | 2000 |
| 9:16 | 768 × 1376 | 1.120 | 1536 × 2752 | 1.120 | 3072 × 5504 | 2000 |
| 16:9 | 1376 × 768 | 1.120 | 2752 × 1536 | 1.120 | 5504 × 3072 | 2000 |
| 21:9 | 1584 × 672 | 1.120 | 3168 × 1344 | 1.120 | 6336 × 2688 | 2000 |
Gemini 2.5 Flash Image
| Seitenverhältnis | Auflösung | Tokens |
|---|---|---|
| 1:1 | 1024x1024 | 1290 |
| 2:3 | 832 × 1248 | 1290 |
| 3:2 | 1248 × 832 | 1290 |
| 3:4 | 864 × 1184 | 1290 |
| 4:3 | 1184 × 864 | 1290 |
| 4:5 | 896 × 1152 | 1290 |
| 5:4 | 1152 × 896 | 1290 |
| 9:16 | 768 × 1344 | 1290 |
| 16:9 | 1344 × 768 | 1290 |
| 21:9 | 1536 × 672 | 1290 |
Modellauswahl
Wählen Sie das Modell aus, das am besten für Ihren speziellen Anwendungsfall geeignet ist.
Gemini 3.1 Flash Image (Nano Banana 2) ist das beste Modell für die Bildgenerierung, da es die beste Allround-Leistung und Intelligenz in Bezug auf Kosten und Latenz bietet. Weitere Informationen finden Sie auf der Seite Preise und Funktionen.
Gemini 3.1 Flash Lite Image (Nano Banana Lite) ist das effizienteste Modell der Bildgenerierungsfamilie und bietet eine extrem niedrige Latenz sowie eine kostengünstige Bildgenerierung und ‑bearbeitung. Weitere Informationen finden Sie auf der Seite Preise und Funktionen.
Gemini 3 Pro Image (Nano Banana Pro) wurde für die professionelle Asset-Produktion und komplexe Anweisungen entwickelt. Dieses Modell bietet eine Fundierung in der realen Welt durch die Google Suche, einen standardmäßigen „Denkprozess“, der die Komposition vor der Generierung verfeinert, und kann Bilder mit einer Auflösung von bis zu 4K generieren. Weitere Informationen finden Sie auf der Seite Preise und Funktionen.
Gemini 2.5 Flash Image (Nano Banana) wurde für Geschwindigkeit und Effizienz entwickelt. Dieses Modell ist für Aufgaben mit hohem Volumen und geringer Latenz optimiert und generiert Bilder mit einer Auflösung von 1.024 Pixeln. Weitere Informationen finden Sie auf der Seite Preise und Funktionen.
Wann sollte Imagen verwendet werden?
Zusätzlich zu den integrierten Funktionen von Gemini zur Bildgenerierung können Sie über die Gemini API auch auf Imagen zugreifen, unser spezialisiertes Modell zur Bildgenerierung. Planen Sie die Migration vor dem Abschaltungsdatum.
Nächste Schritte
- Veo-Anleitung, um zu erfahren, wie Sie Videos mit der Gemini API generieren.
- Weitere Informationen zu Gemini-Modellen finden Sie unter Gemini-Modelle.