إنشاء الصور باستخدام Nano Banana
- أو يمكنك إنشاء سلسلة إجراءات خاصة بك من الطلبات:
-








-
تم إنشاؤها باستخدام Nano Banana 2 الطلب: "صورة لغلاف مجلّة لامع، الغلاف الأزرق البسيط يتضمّن الكلمات الكبيرة البارزة Nano Banana. يظهر النص بخط serif ويملأ طريقة العرض. لا أريد عرض أي نص آخر. أمام النص، تظهر صورة مقرّبة لشخص يرتدي فستانًا أنيقًا وبسيطًا. تمسك الفتاة بالرقم 2 بشكل مرح، وهو نقطة التركيز في الصورة.
ضَع رقم الإصدار وتاريخ "شباط (فبراير) 2026" في الزاوية مع رمز شريطي. المجلة موضوعة على رفّ أمام جدار برتقالي مكسو بالجص، داخل متجر للمصمّمين". -
تم إنشاؤها باستخدام Nano Banana Pro الطلب: "أريد مشهدًا كرتونيًا ثلاثي الأبعاد مصغّرًا ودقيقًا من منظور متساوي القياس (أيزومتري) وزاوية رؤية علوية 45 درجة، يمثّل مدينة لندن ويضمّ أبرز معالمها وعناصرها المعمارية. استخدِم ملمسًا ناعمًا ودقيقًا مع مواد PBR واقعية وإضاءة وظلال لطيفة ونابضة بالحياة. يمكنك دمج أحوال الطقس الحالية مباشرةً في بيئة المدينة لإنشاء أجواء غامرة. استخدِم تركيبة بسيطة ونظيفة مع خلفية ناعمة بلون موحّد. في أعلى منتصف الشاشة، ضَع العنوان "لندن" بخط كبير وغامق، ثم أيقونة بارزة للطقس أسفله، ثم التاريخ (بخط صغير) ودرجة الحرارة (بخط متوسط). يجب توسيط جميع النصوص مع ترك مسافة متسقة، ويجوز أن تتداخل بشكل طفيف مع أعلى المباني". -
تم إنشاؤها باستخدام Nano Banana 2 الطلب: "استخدِم "بحث الصور" للعثور على صور دقيقة لطائر الكيتزال الرائع. أنشئ خلفية جميلة بنسبة عرض إلى ارتفاع 3:2 لهذه الطائر، مع تدرّج طبيعي من الأعلى إلى الأسفل وتصميم بسيط." -

تم إنشاؤها باستخدام Nano Banana Pro الطلب: "أريد وضع هذا الشعار على إعلان فاخر لعطر برائحة الموز. تم دمج الشعار بشكل مثالي في الزجاجة". -
تم إنشاؤها باستخدام Nano Banana Pro الطلب: "صورة لمشهد يومي في مقهى مزدحم يقدّم وجبة الفطور في مقدّمة الصورة، يظهر رجل من عالم الأنمي بشعر أزرق، وأحد الأشخاص هو رسم بقلم الرصاص، والآخر هو شخص من عالم الصلصال" -
تم إنشاؤها باستخدام Nano Banana Pro الطلب: "استخدِم "بحث Google" للعثور على آراء المستخدمين بشأن إطلاق Gemini 3 Flash. استخدِم هذه المعلومات لكتابة مقالة قصيرة حول هذا الموضوع (مع عناوين). أريد صورة للمقالة كما ظهرت في مجلة لامعة تركز على التصميم. إنّها صورة لصفحة واحدة مطوية، تعرض المقالة حول Gemini 3 Flash. صورة رئيسية واحدة عنوان بخط ذي نهايات معقوفة". -
تم إنشاؤها باستخدام Nano Banana Pro الطلب: "أريد رمزًا يمثّل كلبًا لطيفًا. يجب أن تكون الخلفية بيضاء. أنشئ الرموز بأسلوب ثلاثي الأبعاد ملوّن وملموس. لا يوجد نص". -
تم إنشاؤها باستخدام Nano Banana 2 الطلب: "أريد صورة متساوية القياس تمامًا. إنّها ليست صورة مصغّرة، بل صورة تم التقاطها وكانت متساوية القياس تمامًا. إنّها صورة لحديقة عصرية جميلة. يظهر مسبح كبير على شكل الرقم 2 والعبارة Nano Banana 2".
Nano Banana هو اسم إمكانات إنشاء الصور الأصلية في Gemini. يمكن لـ Gemini إنشاء الصور ومعالجتها بشكل حواري باستخدام النصوص أو الصور أو كليهما. يتيح لك ذلك إنشاء المرئيات وتعديلها وتكرارها مع مستوى تحكّم غير مسبوق.
تشير Nano Banana إلى أربعة نماذج مختلفة متوفّرة في Gemini API:
- Nano Banana 2 Lite (Gemini 3.1 Flash Lite Image)
(
gemini-3.1-flash-lite-image): هو أسرع نموذج وأقل تكلفة لمعالجة الصور من Gemini، وقد تم تصميمه لتحقيق السرعة والتوسّع حيث تشكّل السرعة والتكلفة القيود التشغيلية الأساسية. غير محسَّن لإدخالات مرجعية متعددة أو تعديل تسلسلي متعدد الجولات. - Nano Banana 2 (Gemini 3.1 Flash Image)
(
gemini-3.1-flash-image): هو النموذج الأكثر تنوعًا، وهو نموذج عام يُستخدم في جميع المهام. وهو يوازن بين السرعة والجودة العالية للصور بدقة 4K والمعرفة الأوسع بالعالم الواقعي والعرض الموثوق للنصوص. التفوّق في معالجة صور مرجعية متعددة والحفاظ على الاتساق - Nano Banana Pro (Gemini 3 Pro Image)
(
gemini-3-pro-image): هو الخيار الأفضل للمهام المرئية الأكثر تعقيدًا، إذ يوفّر أعلى مستوى من المعرفة بالعالم، وميزات متقدّمة لتحديد الموقع الجغرافي، وتناسقًا دقيقًا للعلامة التجارية، وتحكّمًا إبداعيًا دقيقًا. - Nano Banana (Gemini 2.5 Flash Image)
(
gemini-2.5-flash-image): هو الإصدار الأول من سلسلة Nano Banana. على الرغم من أنّ هذا الطراز كان خيارًا موثوقًا، ننصح العملاء بشدة بالانتقال إلى Nano Banana 2 Lite للاستفادة من الجودة المحسّنة وسرعات الإنشاء الأسرع وأسعار واجهة برمجة التطبيقات الأقل.
تتضمّن جميع الصور التي يتم إنشاؤها علامة مائية من SynthID.
إنشاء الصور (تحويل النص إلى صورة)
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme",
)
with open("generated_image.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const prompt =
"Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme";
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: prompt,
});
const generatedImage = interaction.output_image;
if (generatedImage) {
const buffer = Buffer.from(generatedImage.data, "base64");
fs.writeFileSync("gemini-native-image.png", buffer);
console.log("Image saved as gemini-native-image.png");
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{"type": "text", "text": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme"}
]
}'
يمكنك استرداد بيانات الصورة التي تم إنشاؤها باستخدام السمة interaction.output_image، التي تعرض آخر كتلة صور تم إنشاؤها. للحصول على تفاصيل حول سمات الراحة، يُرجى الاطّلاع على نظرة عامة على التفاعلات.
تعديل الصور (تحويل النص والصورة إلى صورة)
تذكير: يُرجى التأكّد من امتلاكك الحقوق اللازمة لأي صور قبل تحميلها. لا يجوز إنشاء محتوى ينتهك حقوق الآخرين، بما في ذلك الفيديوهات أو الصور التي تتسبب في الخداع أو المضايقة أو الأذى. يخضع استخدامك لخدمة الذكاء الاصطناعي التوليدي هذه لسياسة الاستخدام المحظور.
قدِّم صورة واستخدِم طلبات نصية لإضافة عناصر أو إزالتها أو تعديلها، أو تغيير النمط، أو ضبط تصحيح الألوان.
يوضّح المثال التالي كيفية تحميل صور مرمّزة base64.
للحصول على معلومات حول الصور المتعددة والحِزم الأكبر وأنواع MIME المتوافقة، يُرجى الاطّلاع على صفحة فهم الصور.
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open("/path/to/cat_image.png", "rb") as f:
image_bytes = f.read()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "text",
"text": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
}
],
)
with open("generated_image.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "path/to/cat_image.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const prompt = [
{ type: "text", text: "Create a picture of my cat eating a nano-banana in a" +
"fancy restaurant under the Gemini constellation" },
{
type: "image",
mime_type: "image/png",
data: base64Image
},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: prompt,
});
const generatedImage = interaction.output_image;
if (generatedImage) {
const buffer = Buffer.from(generatedImage.data, "base64");
fs.writeFileSync("gemini-native-image.png", buffer);
console.log("Image saved as gemini-native-image.png");
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"text\", \"text\": \"Create a picture of my cat eating a nano-banana in a fancy restaurant under the Gemini constellation\"},
{
\"type\": \"image\",
\"mime_type\": \"image/jpeg\",
\"data\": \"<BASE64_IMAGE_DATA>\"
}
]
}"
تعديل الصور في محادثة مترابطة
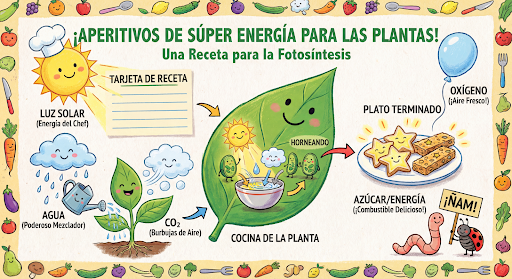
مواصلة إنشاء الصور وتعديلها بشكل حواري المحادثة المتعدّدة الجولات هي الطريقة المقترَحة لتكرار الصور. يعرض المثال التالي طلبًا لإنشاء مخطّط بياني حول عملية البناء الضوئي.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plant's favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids' cookbook, suitable for a 4th grader.",
tools=[{"type": "google_search"}],
)
with open("photosynthesis.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
const ai = new GoogleGenAI({});
async function main() {
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plant's favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids' cookbook, suitable for a 4th grader.",
tools: [{"type": "google_search"}],
});
const generatedImage = interaction.output_image;
if (generatedImage) {
const buffer = Buffer.from(generatedImage.data, "base64");
fs.writeFileSync("photosynthesis.png", buffer);
console.log("Image saved as photosynthesis.png");
}
}
await main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{"type": "text", "text": "Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plants favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids cookbook, suitable for a 4th grader."}
],
"tools": [{"type": "google_search"}]
}'

يمكنك بعد ذلك استخدام previous_interaction_id لتغيير اللغة في الرسم إلى الإسبانية.
Python
interaction_2 = client.interactions.create(
model="gemini-3.1-flash-image",
input="Update this infographic to be in Spanish. Do not change any other elements of the image.",
previous_interaction_id=interaction.id,
response_format={
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9",
"image_size": "2K"
},
)
generated_image = interaction_2.output_image
if generated_image:
with open("photosynthesis_spanish.png", "wb") as f:
f.write(base64.b64decode(generated_image.data))
JavaScript
const interaction2 = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Update this infographic to be in Spanish. Do not change any other elements of the image.",
previous_interaction_id: interaction.id,
response_format: {
type: "image",
mime_type: "image/png",
aspect_ratio: "16:9",
image_size: "2K"
},
});
const generatedImage = interaction2.output_image;
if (generatedImage) {
const buffer = Buffer.from(generatedImage.data, "base64");
fs.writeFileSync("photosynthesis_spanish.png", buffer);
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Update this infographic to be in Spanish. Do not change any other elements of the image.",
"previous_interaction_id": "<PREVIOUS_INTERACTION_ID>",
"response_format": {
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9",
"image_size": "2K"
}
}'
ميزات جديدة في نماذج الصور Gemini 3
يوفّر Gemini 3 أحدث النماذج لإنشاء الصور وتعديلها. تم تحسين أداء Gemini 3.1 Flash Image ليكون سريعًا ومناسبًا لحالات الاستخدام التي تتطلّب كميات كبيرة من البيانات، بينما تم تحسين أداء Gemini 3 Pro Image لإنتاج أصول احترافية. تم تصميم هذه النماذج للتعامل مع أكثر مهام سير العمل صعوبةً من خلال الاستدلال المتقدّم، وهي تتفوّق في المهام المعقّدة والمحادثة المترابطة التي تتضمّن إنشاء المحتوى وتعديله.
- إخراج بدقة عالية: إمكانات إنشاء مضمّنة لمرئيات بدقة 1K و2K و4K
- يضيف Gemini 3.1 Flash Image درجة الدقة الأصغر 512 بكسل (0.5K).
- لا يتيح Gemini 3.1 Flash Lite Image سوى دقة 1K.
- تكنولوجيا متقدمة لعرض النصوص: يمكنها إنشاء نصوص واضحة ومصمّمة بشكل أنيق للرسومات البيانية والقوائم والمخططات ومواد التسويق.
- تحديد المصدر من خلال "بحث Search": يمكن للنموذج استخدام "بحث Google" كأداة للتحقّق من الحقائق وإنشاء صور استنادًا إلى بيانات في الوقت الفعلي (مثل خرائط الطقس الحالية، والرسومات البيانية للأسهم، والأحداث الأخيرة).
- غير متوافق مع نموذج الصور Gemini 3.1 Flash Lite
- تضيف صورة Gemini 3.1 Flash إمكانية دمج ميزة "الاستناد إلى مصادر" من "بحث صور Google" مع "بحث الويب".
- وضع التفكير: يستخدم النموذج عملية "تفكير" للاستدلال على الطلبات المعقّدة. تنشئ هذه الأداة "صورًا مؤقتة" (تظهر في الخلفية ولكن لا يتم تحصيل رسوم مقابلها) لتحسين التركيب قبل إنتاج الناتج النهائي عالي الجودة.
- ما يصل إلى 14 صورة مرجعية: يمكنك الآن دمج ما يصل إلى 14 صورة مرجعية لإنتاج الصورة النهائية.
- نسب عرض إلى ارتفاع جديدة: يضيف Gemini 3.1 Flash Lite Image
1:1و3:2و2:3و3:4و4:3و4:5و5:4و9:16و16:9و21:9نسب عرض إلى ارتفاع.
استخدام ما يصل إلى 14 صورة مرجعية
تتيح لك نماذج الصور في Gemini 3 دمج ما يصل إلى 14 صورة مرجعية. يمكن أن تتضمّن هذه الصور الـ 14 ما يلي:
| صورة Gemini 3.1 Flash Lite | صورة Gemini 3.1 Flash | صورة Gemini 3 Pro |
|---|---|---|
| ما يصل إلى 14 صورة لأشياء عالية الدقة لتضمينها في الصورة النهائية | ما يصل إلى 10 صور لكائنات عالية الدقة لتضمينها في الصورة النهائية | ما يصل إلى 6 صور لكائنات عالية الدقة لتضمينها في الصورة النهائية |
| لا ينطبق | ما يصل إلى 4 صور لشخصيات للحفاظ على اتساق الشخصيات | ما يصل إلى 5 صور لشخصيات للحفاظ على اتساق مظهرها |
| لا ينطبق | لا ينطبق | ما يصل إلى 3 صور لاستخدامها كصور مرجعية للنمط |
Python
from google import genai
from google.genai import types
from PIL import Image
import base64
prompt = "An office group photo of these people, they are making funny faces."
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "text",
"text": prompt,
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
],
response_format={
"type": "image",
"aspect_ratio": "5:4",
"image_size": "2K"
},
)
with open("office.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const input = [
{
type: "text",
text: "An office group photo of these people, they are making funny faces.",
},
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile1 },
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile2 },
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile3 },
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile4 },
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile5 },
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
response_format: {
type: "image",
aspect_ratio: "5:4",
image_size: "2K",
},
});
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('office.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"text\", \"text\": \"An office group photo of these people, they are making funny faces.\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_1>\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_2>\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_3>\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_4>\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_5>\"}
],
\"response_format\": {
\"type\": \"image\",
\"aspect_ratio\": \"5:4\",
\"image_size\": \"2K\"
}
}"

تحديد المصدر من خلال "بحث Search"
استخدِم أداة "بحث Google" لإنشاء صور استنادًا إلى معلومات في الوقت الفعلي، مثل توقعات الطقس أو الرسومات البيانية للأسهم أو الأحداث الأخيرة.
يُرجى العِلم أنّه عند استخدام ميزة "الاستناد إلى مصادر خارجية" مع ميزة "إنشاء الصور" في "بحث Google"، لا يتم تمرير نتائج البحث المستندة إلى الصور إلى نموذج الإنشاء، ويتم استبعادها من الردّ (راجِع الاستناد إلى مصادر خارجية مع ميزة "بحث الصور من Google").
Python
from google import genai
from google.genai import types
import base64
prompt = "Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day"
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=prompt,
tools=[{"type": "google_search"}],
response_format={
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9"
},
)
with open("weather.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day",
tools: [{"type": "google_search"}],
response_format: {
type: "image",
mime_type: "image/png",
aspect_ratio: "16:9",
image_size: "2K"
},
});
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('weather.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{"type": "text", "text": "Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day"}
],
"tools": [{"type": "google_search"}],
"response_format": {
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9"
}
}'

تتضمّن الاستجابة الخطوتَين google_search_call وgoogle_search_result، بالإضافة إلى التعليقات التوضيحية url_citation المضمَّنة في خطوة النص:
google_search_result: يحتوي علىsearch_suggestions، وهو مقتطف HTML لعرض اقتراحات البحث في واجهة المستخدم.url_citationتعليقات توضيحية: إشارات مضمّنة في خطوة النص تربط أجزاء من الرد بمصادرها على الويب.
تحديد المصدر باستخدام "بحث Google" للصور (3.1 Flash)
تتيح ميزة "الاستناد إلى بيانات خارجية" من خلال "صور بحث Google" للنماذج استخدام صور الويب التي يتم استرجاعها عبر "صور بحث Google" كسياق مرئي لإنشاء الصور. "البحث بالصور" هو نوع بحث جديد ضمن أداة "تحديد المصدر من خلال "بحث Search"" الحالية، ويعمل إلى جانب بحث الويب العادي.
لتفعيل ميزة "البحث بالصور"، اضبط أداة google_search في طلب بيانات من واجهة برمجة التطبيقات وحدِّد image_search ضمن مصفوفة search_types. يمكن استخدام "بحث الصور" بشكل مستقل أو مع "بحث الويب".
Python
from google import genai
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A detailed painting of a Timareta butterfly resting on a flower",
tools=[{
"type": "google_search",
"search_types": ["web_search", "image_search"]
}]
)
JavaScript
import { GoogleGenAI } from "@google/genai";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A detailed painting of a Timareta butterfly resting on a flower",
tools: [{
"type": "google_search",
"search_types": ["web_search", "image_search"]
}]
});
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A detailed painting of a Timareta butterfly resting on a flower",
"tools": [{"type": "google_search", "search_types": ["web_search", "image_search"]}]
}'
متطلبات العرض
عند استخدام "البحث بالصور" ضمن "الاستناد إلى معلومات من بحث Google"، يجب عرض search_suggestions من الخطوة google_search_result. يمكنك الاطّلاع على متطلبات الاستخدام الكاملة في بنود الخدمة.
الردّ
بالنسبة إلى الردود المستندة إلى مصادر باستخدام "البحث بالصور"، تعرض واجهة برمجة التطبيقات اقتباسات مضمّنة وبيانات وصفية خاصة بالمصدر كجزء من خطوات الرد:
url_citationالتعليقات التوضيحية: اقتباسات مضمّنة في فقرة المحتوى النصي ضمنmodel_output، تربط المحتوى الذي تم إنشاؤه بمصدره.google_search_result: يحتوي علىsearch_suggestions، وهو مقتطف HTML لعرض اقتراحات البحث في واجهة المستخدم.
إنشاء صور من فيديوهات (3.1 Flash)
تتيح لك ميزة "إنشاء صور من فيديوهات" إنشاء صور جديدة باستخدام سياق الفيديو كمرجع متعدد الوسائط. وهي مفيدة لإنشاء صور مصغّرة عالية الجودة للفيديوهات، أو ملصقات سينمائية، أو رسومات بيانية تلخيصية، أو أعمال فنية جديدة مستوحاة من مشهد فيديو.
أثناء عملية الإنشاء، يحلّل النموذج إطارات الفيديو في سياقها لاستخراج المواضيع المرئية والأحداث الرئيسية، ثم يستخدمها مع الطلب النصي لإنشاء الصورة الناتجة.
يمكنك إدخال عناوين URL علنية على YouTube مباشرةً في طلب واجهة برمجة التطبيقات أو تحميل ملفات فيديو محلية باستخدام Files API.
Python
from google import genai
from google.genai import types
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "video",
"uri": "https://www.youtube.com/watch?v=UTdfxFyOQTI",
"mime_type": "video/mp4"
},
{"type": "text", "text": "Generate a poster image that captures the key themes of this video."}
],
response_format={"type": "image", "aspect_ratio": "16:9"}
)
# Save the generated image part
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("video_poster.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
print("Image saved as video_poster.png")
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: [
{
type: "video",
uri: "https://www.youtube.com/watch?v=UTdfxFyOQTI",
mime_type: "video/mp4"
},
{ type: "text", text: "Generate a poster image that captures the key themes of this video." }
],
response_format: {
type: "image",
aspect_ratio: "16:9"
}
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("video_poster.png", buffer);
console.log("Image saved as video_poster.png");
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{
"type": "video",
"uri": "https://www.youtube.com/watch?v=UTdfxFyOQTI",
"mime_type": "video/mp4"
},
{
"type": "text",
"text": "Generate a poster image that captures the key themes of this video."
}
],
"response_format": {
"type": "image",
"aspect_ratio": "16:9"
}
}'

إنشاء صور بدقة تصل إلى 4K
تنشئ نماذج الصور في Gemini 3 صورًا بدقة 1000 بكسل تلقائيًا، ولكن يمكنها أيضًا إنشاء صور بدقة 2000 بكسل و4000 بكسل و512 بكسل (05.K) (في Gemini 3.1 Flash Image فقط). لإنشاء مواد عرض بدقة أعلى، حدِّد image_size في response_format.
يجب استخدام الحرف "K" الكبير (مثلاً 512 بكسل (05.K)، و1K، و2K، و4K). سيتم رفض المَعلمات التي تتضمّن أحرفًا صغيرة (مثل 1k).
Python
from google import genai
from google.genai import types
import base64
prompt = "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English."
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=prompt,
response_format={
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "1:1",
"image_size": "1K"
},
)
print(interaction.output_text)
with open("butterfly.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English.",
response_format: {
type: "image",
mime_type: "image/png",
aspect_ratio: "1:1",
image_size: "1K",
},
});
console.log(interaction.output_text);
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('butterfly.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English.",
"response_format": {
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "1:1",
"image_size": "1K"
}
}'
في ما يلي مثال على صورة تم إنشاؤها من خلال هذا الطلب:

عملية التفكير
نماذج الصور في Gemini 3 هي نماذج مُفكِّرة تستخدم عملية استدلال ("التفكير") للتعامل مع الطلبات المعقّدة. تكون هذه الميزة مفعّلة تلقائيًا ولا يمكن إيقافها في واجهة برمجة التطبيقات. لمزيد من المعلومات حول عملية التفكير، يُرجى الاطّلاع على دليل تفكير Gemini.
ينشئ النموذج ما يصل إلى صورتَين مؤقتتَين لاختبار التركيب والمنطق. الصورة الأخيرة ضمن "جارٍ التفكير" هي أيضًا الصورة النهائية المعروضة.
يمكنك الاطّلاع على الأفكار التي أدّت إلى إنتاج الصورة النهائية.
Python
for step in interaction.steps:
if step.type == "thought":
for content_block in step.summary:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
image = Image.open(io.BytesIO(base64.b64decode(content_block.data)))
image.show()
JavaScript
for (const step of interaction.steps) {
if (step.type === "thought") {
for (const contentBlock of step.summary) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, 'base64');
fs.writeFileSync('thought_image.png', buffer);
}
}
}
}
النصوص والصور المتداخلة
في حين أنّ نماذج إنشاء الصور العادية تعرض صورًا فقط، يمكن لبعض نماذج Gemini 3 المتقدّمة (مثل gemini-3-pro-image) إنشاء محتوى متداخل، مثل القصص أو الأدلة الإرشادية التي تحتوي على كل من فقرات نصية ورسوم توضيحية ضمن الرد نفسه.
بما أنّ الناتج معقّد ومتداخل، لن تتمكّن خصائص الراحة، مثل
.output_image أو .output_text، من تسجيل التسلسل الكامل. للوصول إلى المحتوى المتداخل وحفظه، يجب تكرار steps يدويًا:
Python
interaction = client.interactions.create(
model="gemini-3-pro-image",
input="Write the story of the lifecycle of a monarch butterfly, interleave illustrations",
)
image_counter = 1
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
filename = f"butterfly_lifecycle_{image_counter}.png"
with open(filename, "wb") as f:
f.write(base64.b64decode(content_block.data))
print(f"\n[Saved illustration: {filename}]\n")
image_counter += 1
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3-pro-image",
input: "Write the story of the lifecycle of a monarch butterfly, interleave illustrations",
});
let imageCounter = 1;
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
const filename = `butterfly_lifecycle_${imageCounter}.png`;
fs.writeFileSync(filename, buffer);
console.log(`\n[Saved illustration: ${filename}]\n`);
imageCounter++;
}
}
}
}
التحكّم في مستويات التفكير
باستخدام Gemini 3.1 Flash Image، يمكنك التحكّم في مقدار التفكير الذي يستخدمه النموذج لتحقيق التوازن بين الجودة وسرعة الاستجابة. القيمة التلقائية thinking_level هي minimal،
والمستويات المتاحة هي minimal وhigh.
Python
from google import genai
from PIL import Image
import base64
import io
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A futuristic city built inside a giant glass bottle floating in space",
generation_config={"thinking_level": "high"},
)
print(interaction.output_text)
image = Image.open(io.BytesIO(base64.b64decode(interaction.output_image.data)))
image.show()
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A futuristic city built inside a giant glass bottle floating in space",
generation_config: { thinking_level: "high" },
});
console.log(interaction.output_text);
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('image.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A futuristic city built inside a giant glass bottle floating in space",
"generation_config": {
"thinking_level": "high"
}
}'
يُرجى العِلم أنّه يتم تلقائيًا تحصيل رسوم الرموز المميزة الخاصة بالتفكير من نماذج التفكير، لأنّ عملية التفكير تحدث تلقائيًا دائمًا سواء عرضت العملية أم لا.
أوضاع أخرى لإنشاء الصور
على الرغم من أنّ نماذج إنشاء الصور في Nano Banana يُنصح بها لمعظم حالات الاستخدام، يمكنك أيضًا استكشاف نماذج مخصّصة لإنشاء الصور:
- Imagen: نماذج من Google لتحويل النص إلى صورة، وهي محسّنة لإنشاء صور عالية الجودة.
- Veo: نموذج إنشاء الفيديوهات من Google
إنشاء صور بشكل مجمّع
يمكن أيضًا تنفيذ جميع إمكانات إنشاء الصور الموضّحة في هذه الصفحة كمهام مجمّعة باستخدام Batch API، وهو أمر مثالي إذا كنت بحاجة إلى إنشاء العديد من الصور.ستحصل على حدود معدّل أعلى مقابل مدة تنفيذ تصل إلى 24 ساعة.
دليل واستراتيجيات كتابة الطلبات
يقدّم هذا القسم أمثلة على الطلبات ونماذج لعمليات إنشاء الصور وتعديلها الشائعة. يتضمّن كل مثال نموذجًا يمكن إعادة استخدامه وطلبًا نموذجيًا لواجهة برمجة التطبيقات Interactions API.
طلبات إنشاء الصور
توضّح الأمثلة التالية كيفية استخدام طلبات نصية لإنشاء أنواع مختلفة من الصور.
1. مشاهد واقعية
صِف مشهدًا بتفاصيل غنية. كلّما كانت التفاصيل أكثر، زادت إمكانية التحكّم في النتائج.
نموذج
A photorealistic [type of shot] of a [subject description] in a [setting
description]. [Description of the light]. Shot from a [camera angle]
with a [lens type].
الطلب
A photorealistic wide-angle shot of a vibrant coral reef teeming with tropical fish. Crystal-clear turquoise water with sunbeams filtering down from the surface, illuminating a sea turtle gliding gracefully over the coral. Shot from a low perspective with a wide-angle lens. Aspect ratio 16:9.
Python
from google import genai
from google.genai import types
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A photorealistic wide-angle shot of a vibrant coral reef teeming with tropical fish. Crystal-clear turquoise water with sunbeams filtering down from the surface, illuminating a sea turtle gliding gracefully over the coral. Shot from a low perspective with a wide-angle lens. Aspect ratio 16:9.",
response_format=[
{
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9",
}
],
)
print(interaction.output_text)
with open("coral_reef.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A photorealistic wide-angle shot of a vibrant coral reef teeming with tropical fish. Crystal-clear turquoise water with sunbeams filtering down from the surface, illuminating a sea turtle gliding gracefully over the coral. Shot from a low perspective with a wide-angle lens. Aspect ratio 16:9.",
response_format: [
{
type: "image",
mime_type: "image/jpeg",
aspect_ratio: "16:9",
}
],
});
console.log(interaction.output_text);
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('coral_reef.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A photorealistic wide-angle shot of a vibrant coral reef teeming with tropical fish. Crystal-clear turquoise water with sunbeams filtering down from the surface, illuminating a sea turtle gliding gracefully over the coral. Shot from a low perspective with a wide-angle lens. Aspect ratio 16:9.",
"response_format": {
"type": "image",
"mime_type": "image/png",
"aspect_ratio": "16:9"
}
}'
2. رسومات توضيحية وملصقات ذات طابع مميز
قدِّم وصفًا للأسلوب الفني والموضوع والوسيط. يجب أن تكون محددًا بشأن تفاصيل الصورة (الخطوط الغليظة والألوان وما إلى ذلك) للحصول على نتائج متسقة.
نموذج
A [style] of a [subject, with details about accessories or actions]
doing [activity]. The design features [visual qualities, e.g., bold outlines,
cel-shading, etc.] and [color/background preference].
الطلب
A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It's munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It's munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white.",
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("red_panda_sticker.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It's munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white.",
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("red_panda_sticker.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It is munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white."
}'

3- نص دقيق في الصور
يتفوّق Gemini في عرض النصوص. يجب أن يكون النص واضحًا، وأن يكون نمط الخط (وصفيًا)، وأن يكون التصميم العام واضحًا. استخدام Gemini 3 Pro Image لإنتاج أصول احترافية
نموذج
Create a [image type] for [brand/concept] with the text "[text to render]"
in a [font style]. The design should be [style description], with a
[color scheme].
الطلب
Create a modern, minimalist logo for a coffee shop called 'The Daily Grind'. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Create a modern, minimalist logo for a coffee shop called 'The Daily Grind'. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way.",
response_format={"type": "image", "aspect_ratio": "1:1"},
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("logo_example.jpg", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Create a modern, minimalist logo for a coffee shop called 'The Daily Grind'. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way.",
response_format: { type: "image", aspect_ratio: "1:1" },
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("logo_example.jpg", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Create a modern, minimalist logo for a coffee shop called The Daily Grind. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way.",
"response_format": {
"type": "image",
"aspect_ratio": "1:1"
}
}'
4. نماذج المنتجات والتصوير الفوتوغرافي التجاري
وهي مثالية لالتقاط صور منتجات احترافية وواضحة للتجارة الإلكترونية أو الإعلانات أو العلامات التجارية.
نموذج
A high-resolution, studio-lit product photograph of a [product description]
on a [background surface/description]. The lighting is a [lighting setup,
e.g., three-point softbox setup] to [lighting purpose]. The camera angle is
a [angle type] to showcase [specific feature]. Ultra-realistic, with sharp
focus on [key detail]. [Aspect ratio].
الطلب
A high-resolution, studio-lit product photograph of a minimalist ceramic
coffee mug in matte black, presented on a polished concrete surface. The
lighting is a three-point softbox setup designed to create soft, diffused
highlights and eliminate harsh shadows. The camera angle is a slightly
elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with
sharp focus on the steam rising from the coffee. Square image.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A high-resolution, studio-lit product photograph of a minimalist ceramic coffee mug in matte black, presented on a polished concrete surface. The lighting is a three-point softbox setup designed to create soft, diffused highlights and eliminate harsh shadows. The camera angle is a slightly elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with sharp focus on the steam rising from the coffee. Square image.",
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("product_mockup.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A high-resolution, studio-lit product photograph of a minimalist ceramic coffee mug in matte black, presented on a polished concrete surface. The lighting is a three-point softbox setup designed to create soft, diffused highlights and eliminate harsh shadows. The camera angle is a slightly elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with sharp focus on the steam rising from the coffee. Square image.",
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("product_mockup.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A high-resolution, studio-lit product photograph of a minimalist ceramic coffee mug in matte black, presented on a polished concrete surface. The lighting is a three-point softbox setup designed to create soft, diffused highlights and eliminate harsh shadows. The camera angle is a slightly elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with sharp focus on the steam rising from the coffee. Square image."
}'

5- التصميم البسيط والمساحة السالبة
وهي ممتازة لإنشاء خلفيات للمواقع الإلكترونية أو العروض التقديمية أو المواد التسويقية التي سيتم عرض النص فوقها.
نموذج
A minimalist composition featuring a single [subject] positioned in the
[bottom-right/top-left/etc.] of the frame. The background is a vast, empty
[color] canvas, creating significant negative space. Soft, subtle lighting.
[Aspect ratio].
الطلب
A minimalist composition featuring a single, delicate red maple leaf
positioned in the bottom-right of the frame. The background is a vast, empty
off-white canvas, creating significant negative space for text. Soft,
diffused lighting from the top left. Square image.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A minimalist composition featuring a single, delicate red maple leaf positioned in the bottom-right of the frame. The background is a vast, empty off-white canvas, creating significant negative space for text. Soft, diffused lighting from the top left. Square image.",
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("minimalist_design.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A minimalist composition featuring a single, delicate red maple leaf positioned in the bottom-right of the frame. The background is a vast, empty off-white canvas, creating significant negative space for text. Soft, diffused lighting from the top left. Square image.",
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("minimalist_design.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A minimalist composition featuring a single, delicate red maple leaf positioned in the bottom-right of the frame. The background is a vast, empty off-white canvas, creating significant negative space for text. Soft, diffused lighting from the top left. Square image."
}'

6. الفن التسلسلي (لوحة الكتب المصوّرة / لوحة ترتيب الصور)
تستند هذه الميزة إلى اتساق الشخصية ووصف المشهد لإنشاء لوحات لسرد القصص بشكل مرئي. للحصول على دقة عالية في النصوص وقدرة أفضل على سرد القصص، تعمل هذه الطلبات بشكل أفضل مع Gemini 3 Pro وGemini 3.1 Flash Image.
نموذج
Make a 3 panel comic in a [style]. Put the character in a [type of scene].
الطلب
Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene.
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/man_in_white_glasses.jpg', 'rb') as f:
image_bytes = f.read()
text_input = "Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene."
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{"type": "text", "text": text_input},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/jpeg"
}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("comic_panel.jpg", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/man_in_white_glasses.jpg";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const input = [
{ type: "text", text: "Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene." },
{
type: "image",
mime_type: "image/jpeg",
data: base64Image
},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("comic_panel.jpg", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{"type": "text", "text": "Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene."},
{"type": "image", "data": "<BASE64_IMAGE_DATA>", "mime_type": "image/jpeg"}
]
}'
الإدخال |
الناتج |

|

|
7. تحديد المصدر من خلال "بحث Search"
استخدام "بحث Google" لإنشاء صور استنادًا إلى معلومات حديثة أو في الوقت الفعلي ويفيد ذلك في ما يتعلق بالأخبار والطقس والمواضيع الأخرى التي تتطلب معلومات حديثة.
الطلب
Make a simple but stylish graphic of last night's Arsenal game in the Champion's League
Python
from google import genai
from google.genai import types
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Make a simple but stylish graphic of last night's Arsenal game in the Champion's League",
tools=[{"type": "google_search"}],
response_format={"type": "image", "aspect_ratio": "16:9"},
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("football-score.jpg", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Make a simple but stylish graphic of last night's Arsenal game in the Champion's League",
tools: [{ type: "google_search" }],
response_format: { type: "image", aspect_ratio: "16:9", image_size: "2K" },
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("football-score.jpg", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Make a simple but stylish graphic of last nights Arsenal game in the Champions League",
"tools": [{"type": "google_search"}],
"response_format": {
"type": "image",
"aspect_ratio": "16:9"
}
}'

طلبات تعديل الصور
توضّح هذه الأمثلة كيفية تقديم صور إلى جانب طلباتك النصية لإجراء التعديل والتركيب ونقل الأنماط.
1. إضافة العناصر وإزالتها
قدِّم صورة واشرح التغيير المطلوب. سيتطابق النموذج مع نمط الصورة الأصلية وإضاءتها ومنظورها.
نموذج
Using the provided image of [subject], please [add/remove/modify] [element]
to/from the scene. Ensure the change is [description of how the change should
integrate].
الطلب
"Using the provided image of my cat, please add a small, knitted wizard hat
on its head. Make it look like it's sitting comfortably and matches the soft
lighting of the photo."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/cat_photo.png', 'rb') as f:
image_bytes = f.read()
text_input = """Using the provided image of my cat, please add a small, knitted wizard hat on its head. Make it look like it's sitting comfortably and not falling off."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{"type": "text", "text": text_input},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("cat_with_hat.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/cat_photo.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const input = [
{ type: "text", text: "Using the provided image of my cat, please add a small, knitted wizard hat on its head. Make it look like it's sitting comfortably and not falling off." },
{
type: "image",
mime_type: "image/png",
data: base64Image
},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("cat_with_hat.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"text\", \"text\": \"Using the provided image of my cat, please add a small, knitted wizard hat on its head. Make it look like it's sitting comfortably and not falling off.\"},
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA>\"}
]
}"
الإدخال |
الناتج |

|

|
2. الطلاء (الإخفاء الدلالي)
تحديد "قناع" بشكل حواري لتعديل جزء معيّن من الصورة بدون التأثير في بقية الصورة
نموذج
Using the provided image, change only the [specific element] to [new
element/description]. Keep everything else in the image exactly the same,
preserving the original style, lighting, and composition.
الطلب
"Using the provided image of a living room, change only the blue sofa to be
a vintage, brown leather chesterfield sofa. Keep the rest of the room,
including the pillows on the sofa and the lighting, unchanged."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/living_room.png', 'rb') as f:
image_bytes = f.read()
text_input = """Using the provided image of a living room, change only the blue sofa to be a vintage, brown leather chesterfield sofa. Keep the rest of the room, including the pillows on the sofa and the lighting, unchanged."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("living_room_edited.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/living_room.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const input = [
{
type: "image",
mime_type: "image/png",
data: base64Image
},
{ type: "text", text: "Using the provided image of a living room, change only the blue sofa to be a vintage, brown leather chesterfield sofa. Keep the rest of the room, including the pillows on the sofa and the lighting, unchanged." },
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("living_room_edited.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA>\"},
{\"type\": \"text\", \"text\": \"Using the provided image of a living room, change only the blue sofa to be a vintage, brown leather chesterfield sofa. Keep the rest of the room, including the pillows on the sofa and the lighting, unchanged.\"}
]
}"
الإدخال |
الناتج |

|

|
3- تحويل النمط
قدِّم صورة واطلب من النموذج إعادة إنشاء محتواها بأسلوب فني مختلف.
نموذج
Transform the provided photograph of [subject] into the artistic style of [artist/art style]. Preserve the original composition but render it with [description of stylistic elements].
الطلب
"Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/city.png', 'rb') as f:
image_bytes = f.read()
text_input = """Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("city_style_transfer.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imageData = fs.readFileSync("/path/to/your/city.png");
const base64Image = imageData.toString("base64");
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: [
{
type: "image",
mime_type: "image/png",
data: base64Image
},
{ type: "text", text: "Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows." },
],
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("city_style_transfer.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA>\"},
{\"type\": \"text\", \"text\": \"Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows.\"}
]
}"
الإدخال |
الناتج |

|

|
4. التركيب المتقدّم: دمج صور متعددة
تقديم صور متعددة كسياق لإنشاء مشهد جديد ومجمّع هذه الميزة مثالية لإنشاء نماذج للمنتجات أو صور مجمّعة إبداعية.
نموذج
Create a new image by combining the elements from the provided images. Take
the [element from image 1] and place it with/on the [element from image 2].
The final image should be a [description of the final scene].
الطلب
"Create a professional e-commerce fashion photo. Take the blue floral dress
from the first image and let the woman from the second image wear it.
Generate a realistic, full-body shot of the woman wearing the dress, with
the lighting and shadows adjusted to match the outdoor environment."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/dress.png', 'rb') as f:
dress_bytes = f.read()
with open('/path/to/your/model.png', 'rb') as f:
model_bytes = f.read()
text_input = """Create a professional e-commerce fashion photo. Take the blue floral dress from the first image and let the woman from the second image wear it. Generate a realistic, full-body shot of the woman wearing the dress, with the lighting and shadows adjusted to match the outdoor environment."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "image",
"data": base64.b64encode(dress_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(model_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("fashion_ecommerce_shot.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath1 = "/path/to/your/dress.png";
const imageData1 = fs.readFileSync(imagePath1);
const base64Image1 = imageData1.toString("base64");
const imagePath2 = "/path/to/your/model.png";
const imageData2 = fs.readFileSync(imagePath2);
const base64Image2 = imageData2.toString("base64");
const input = [
{
type: "image",
mime_type: "image/png",
data: base64Image1
},
{
type: "image",
mime_type: "image/png",
data: base64Image2
},
{ type: "text", text: "Create a professional e-commerce fashion photo. Take the blue floral dress from the first image and let the woman from the second image wear it. Generate a realistic, full-body shot of the woman wearing the dress, with the lighting and shadows adjusted to match the outdoor environment." },
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("fashion_ecommerce_shot.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA_1>\"},
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA_2>\"},
{\"type\": \"text\", \"text\": \"Create a professional e-commerce fashion photo. Take the blue floral dress from the first image and let the woman from the second image wear it. Generate a realistic, full-body shot of the woman wearing the dress, with the lighting and shadows adjusted to match the outdoor environment.\"}
}]
}"
المعلومة 1 |
المعلومة 2 |
الناتج |

|

|

|
5- الحفاظ على التفاصيل العالية الدقة
لضمان الحفاظ على التفاصيل المهمة (مثل وجه أو شعار) أثناء التعديل، يجب وصفها بالتفصيل مع طلب التعديل.
نموذج
Using the provided images, place [element from image 2] onto [element from
image 1]. Ensure that the features of [element from image 1] remain
completely unchanged. The added element should [description of how the
element should integrate].
الطلب
"Take the first image of the woman with brown hair, blue eyes, and a neutral
expression. Add the logo from the second image onto her black t-shirt.
Ensure the woman's face and features remain completely unchanged. The logo
should look like it's naturally printed on the fabric, following the folds
of the shirt."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/woman.png', 'rb') as f:
woman_bytes = f.read()
with open('/path/to/your/logo.png', 'rb') as f:
logo_bytes = f.read()
text_input = """Take the first image of the woman with brown hair, blue eyes, and a neutral expression. Add the logo from the second image onto her black t-shirt. Ensure the woman's face and features remain completely unchanged. The logo should look like it's naturally printed on the fabric, following the folds of the shirt."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{"type": "image", "mime_type":"image/png", "data": base64.b64encode(woman_bytes).decode('utf-8')},
{"type": "image", "mime_type":"image/png", "data": base64.b64encode(logo_bytes).decode('utf-8')},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("woman_with_logo.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath1 = "/path/to/your/woman.png";
const imageData1 = fs.readFileSync(imagePath1);
const base64Image1 = imageData1.toString("base64");
const imagePath2 = "/path/to/your/logo.png";
const imageData2 = fs.readFileSync(imagePath2);
const base64Image2 = imageData2.toString("base64");
const input = [
{"type": "image", "mime_type":"image/png", "data": base64Image1},
{"type": "image", "mime_type":"image/png", "data": base64Image2},
{"type": "text", "text": "Take the first image of the woman with brown hair, blue eyes, and a neutral expression. Add the logo from the second image onto her black t-shirt. Ensure the woman's face and features remain completely unchanged. The logo should look like it's naturally printed on the fabric, following the folds of the shirt."},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("woman_with_logo.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA_1>\"},
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA_2>\"},
{\"type\": \"text\", \"text\": \"Take the first image of the woman with brown hair, blue eyes, and a neutral expression. Add the logo from the second image onto her black t-shirt. Ensure the woman's face and features remain completely unchanged. The logo should look like it's naturally printed on the fabric, following the folds of the shirt.\"}
]
}"
المعلومة 1 |
المعلومة 2 |
الناتج |

|
|
|
6. إحياء ذكرى شخص أو حدث
حمِّلوا رسمًا تخطيطيًا أو رسمًا عاديًا واطلبوا من النموذج تحسينه ليصبح صورة نهائية.
نموذج
Turn this rough [medium] sketch of a [subject] into a [style description]
photo. Keep the [specific features] from the sketch but add [new details/materials].
الطلب
"Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/car_sketch.png', 'rb') as f:
sketch_bytes = f.read()
text_input = """Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{"type": "image", "mime_type":"image/png", "data": base64.b64encode(sketch_bytes).decode('utf-8')},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("car_photo.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/car_sketch.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const input = [
{"type": "image", "mime_type":"image/png", "data": base64Image},
{"type": "text", "text": "Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting."},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("car_photo.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA>\"},
{\"type\": \"text\", \"text\": \"Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting.\"}
]
}"
الإدخال |
الناتج |

|

|
7. الحفاظ على ملامح الشخصية: عرض بزاوية 360 درجة
يمكنك إنشاء طرق عرض بزاوية 360 درجة لشخصية ما من خلال تقديم طلبات متكرّرة للحصول على زوايا مختلفة. للحصول على أفضل النتائج، أدرِج الصور التي تم إنشاؤها سابقًا في الطلبات اللاحقة للحفاظ على التناسق. بالنسبة إلى الوضعيات المعقّدة، أدرِج صورة مرجعية للوضعية المحدّدة.
نموذج
A studio portrait of [person] against [background], [looking forward/in profile looking right/etc.]
الطلب
A studio portrait of this man against white, in profile looking right
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/man_in_white_glasses.jpg', 'rb') as f:
image_bytes = f.read()
text_input = """A studio portrait of this man against white, in profile looking right"""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input={
{"type": "text", "text": text_input},
{"type": "image", "mime_type":"image/png", "data": base64.b64encode(image_bytes).decode('utf-8')}
},
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("man_right_profile.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
الإدخال |
النتيجة 1 |
النتيجة 2 |
|
|

|

|
أفضل الممارسات
لتحسين نتائجك من جيدة إلى ممتازة، يمكنك دمج الاستراتيجيات الاحترافية التالية في سير عملك.
- كن دقيقًا جدًا: كلّما قدّمت تفاصيل أكثر، زادت إمكانية التحكّم. بدلاً من كتابة "درع خيالي"، يمكنك وصفه على النحو التالي: "درع ألواح مزخرف خاص بالجِن، منقوش بنقوش أوراق فضية، مع ياقة عالية وواقيات كتف على شكل أجنحة صقر".
- توفير السياق والنية: اشرح الغرض من الصورة. سيؤثر فهم النموذج للسياق في الناتج النهائي. على سبيل المثال، سيؤدي طلب "إنشاء شعار لعلامة تجارية راقية وبسيطة للعناية بالبشرة" إلى نتائج أفضل من مجرد طلب "إنشاء شعار".
- التكرار والتحسين: لا تتوقّع الحصول على صورة مثالية من المحاولة الأولى. استخدِم الطبيعة الحوارية للنموذج لإجراء تغييرات بسيطة. يمكنك متابعة المحادثة بطلبات مثل "هذا رائع، ولكن هل يمكنك جعل الإضاءة أكثر دفئًا؟" أو "أريد إبقاء كل شيء كما هو، ولكن أريد تغيير تعابير وجه الشخصية لتكون أكثر جدية".
- استخدام تعليمات مفصّلة: بالنسبة إلى المشاهد المعقّدة التي تتضمّن عناصر كثيرة، قسِّم طلبك إلى خطوات. "أريد أولاً إنشاء خلفية لغابة هادئة يلفّها الضباب عند الفجر. بعد ذلك، أضِف في المقدّمة مذبحًا حجريًا قديمًا مغطى بالطحالب. أخيرًا، ضَع سيفًا واحدًا متوهجًا فوق المذبح".
- استخدام "مطالبات سلبية دلالية": بدلاً من قول "لا أريد سيارات"، يمكنك وصف المشهد المطلوب بشكل إيجابي: "شارع خالٍ ومهجور لا تظهر فيه أي علامات على حركة المرور".
- التحكّم في الكاميرا: استخدِم لغة التصوير الفوتوغرافي والسينمائي للتحكّم في التركيبة. عبارات مثل
wide-angle shotوmacro shotوlow-angle perspective
القيود
- للحصول على أفضل أداء، استخدِم اللغات التالية: الإنجليزية، والعربية (مصر)، والألمانية (ألمانيا)، والإسبانية (المكسيك)، والفرنسية (فرنسا)، والهندية (الهند)، والإندونيسية (إندونيسيا)، والإيطالية (إيطاليا)، واليابانية (اليابان)، والكورية (كوريا الجنوبية)، والبرتغالية (البرازيل)، والروسية (روسيا)، والأوكرانية (أوكرانيا)، والفيتنامية (فيتنام)، والصينية (الصين).
- لا تتيح ميزة إنشاء الصور إدخال طلبات صوتية. لا يمكن استخدام فيديوهات كمدخلات إلا مع Gemini 3.1 Flash Image.
- لن يلتزم النموذج دائمًا بالعدد الدقيق للصور التي يطلبها المستخدم بشكل صريح.
- يعمل
gemini-2.5-flash-imageعلى أفضل وجه مع ما يصل إلى 3 صور كمدخلات، بينما يتيحgemini-3-pro-imageاستخدام 5 صور بدقة عالية، وما يصل إلى 14 صورة إجمالاً. تتيحgemini-3.1-flash-imageتشابه الأحرف بما يصل إلى 4 أحرف ودقة تصل إلى 10 عناصر في سير عمل واحد. - عند إنشاء نص لصورة، يعمل Gemini بشكل أفضل إذا أنشأت النص أولاً ثم طلبت صورة تتضمّن النص.
gemini-3.1-flash-imageلا تتيح ميزة "تحديد المصدر من خلال بحث Google" حاليًا استخدام صور واقعية لأشخاص من بحث الويب.- تتضمّن جميع الصور التي يتم إنشاؤها علامة مائية من SynthID.
الإعدادات الاختيارية
يمكنك اختياريًا ضبط تنسيق الإخراج ونسبة العرض إلى الارتفاع وحجم الصورة باستخدام المَعلمة response_format.
تنسيق الإخراج
يعرض النموذج بشكل تلقائي ردودًا نصية وردودًا على شكل صور. يمكنك ضبط الردّ لعرض الصور التي تم إنشاؤها فقط (مع حذف النص الحواري) من خلال تحديد تنسيق صورة في المَعلمة response_format.
لطلب وسائط متعددة (على سبيل المثال، النص والصورة التي تم إنشاؤها)، مرِّر مصفوفة من إدخالات التنسيق إلى response_format بدلاً من ذلك.
Python
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Write a short poem about a starry night and generate an image of it.",
response_format=[
{"type": "text"},
{"type": "image"},
],
)
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Write a short poem about a starry night and generate an image of it.",
response_format: [
{ type: "text" },
{ type: "image" },
],
});
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Write a short poem about a starry night and generate an image of it.",
"response_format": [
{ "type": "text" },
{ "type": "image" }
]
}'
نِسَب العرض إلى الارتفاع وحجم الصورة
يتطابق حجم الصورة الناتجة تلقائيًا مع حجم الصورة التي أدخلتها، أو يتم إنشاء مربّعات بنسبة 1:1. يمكنك التحكّم في نسبة العرض إلى الارتفاع وحجم الصورة الناتجة باستخدام الحقلَين aspect_ratio وimage_size ضمن response_format عندما يكون type مضبوطًا على "image".
Python
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=prompt,
response_format={
"type": "image",
"aspect_ratio": "16:9",
"image_size": "2K",
},
)
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: prompt,
response_format: {
type: "image",
aspect_ratio: "16:9",
image_size: "2K",
},
});
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme",
"response_format": {
"type": "image",
"aspect_ratio": "16:9",
"image_size": "2K"
}
}'
في ما يلي الجداول التي تعرض النسب المختلفة المتاحة وحجم الصورة التي يتم إنشاؤها:
3.1 Flash Image
| نسبة العرض إلى الارتفاع | درجة الدقة 512 بكسل | 0.5 ألف رمز مميّز | درجة الدقة 1K | 1,000 رمز مميّز | درجة الدقة 2K | 2,000 رمز مميّز | درجة الدقة 4K | 4 آلاف رمز مميّز |
|---|---|---|---|---|---|---|---|---|
| 1:1 | 512×512 | 747 | 1024x1024 | 1120 | 2048x2048 | 1120 | 4096x4096 | 2000 |
| 1:4 | 256x1024 | 747 | 512x2048 | 1120 | 1024x4096 | 1120 | 2048x8192 | 2000 |
| 1:8 | 192x1536 | 747 | 384x3072 | 1120 | 768x6144 | 1120 | 1536x12288 | 2000 |
| 2:3 | 424x632 | 747 | 848x1264 | 1120 | 1696x2528 | 1120 | 3392 × 5056 | 2000 |
| 3:2 | 632x424 | 747 | 1264x848 | 1120 | 2528x1696 | 1120 | 5056x3392 | 2000 |
| 3:4 | 448x600 | 747 | 896x1200 | 1120 | 1792x2400 | 1120 | 3584x4800 | 2000 |
| 4:1 | 1024x256 | 747 | 2048x512 | 1120 | 4096x1024 | 1120 | 8192x2048 | 2000 |
| 4:3 | 600x448 | 747 | 1200x896 | 1120 | 2400 × 1792 | 1120 | 4800x3584 | 2000 |
| 4:5 | 464x576 | 747 | 928×1152 | 1120 | 1856x2304 | 1120 | 3712x4608 | 2000 |
| 5:4 | 576x464 | 747 | 1152x928 | 1120 | 2304x1856 | 1120 | 4608x3712 | 2000 |
| 8:1 | 1536x192 | 747 | 3072x384 | 1120 | 6144x768 | 1120 | 12288x1536 | 2000 |
| 9:16 | 384x688 | 747 | 768x1376 | 1120 | 1536 × 2752 | 1120 | 3072x5504 | 2000 |
| 16:9 | 688x384 | 747 | 1376x768 | 1120 | 2752x1536 | 1120 | 5504x3072 | 2000 |
| 21:9 | 792×168 | 747 | 1584x672 | 1120 | 3168x1344 | 1120 | 6336x2688 | 2000 |
3.1 Pro Image
| نسبة العرض إلى الارتفاع | درجة الدقة 1K | 1,000 رمز مميّز | درجة الدقة 2K | 2,000 رمز مميّز | درجة الدقة 4K | 4 آلاف رمز مميّز |
|---|---|---|---|---|---|---|
| 1:1 | 1024x1024 | 1120 | 2048x2048 | 1120 | 4096x4096 | 2000 |
| 2:3 | 848x1264 | 1120 | 1696x2528 | 1120 | 3392 × 5056 | 2000 |
| 3:2 | 1264x848 | 1120 | 2528x1696 | 1120 | 5056x3392 | 2000 |
| 3:4 | 896x1200 | 1120 | 1792x2400 | 1120 | 3584x4800 | 2000 |
| 4:3 | 1200x896 | 1120 | 2400 × 1792 | 1120 | 4800x3584 | 2000 |
| 4:5 | 928×1152 | 1120 | 1856x2304 | 1120 | 3712x4608 | 2000 |
| 5:4 | 1152x928 | 1120 | 2304x1856 | 1120 | 4608x3712 | 2000 |
| 9:16 | 768x1376 | 1120 | 1536 × 2752 | 1120 | 3072x5504 | 2000 |
| 16:9 | 1376x768 | 1120 | 2752x1536 | 1120 | 5504x3072 | 2000 |
| 21:9 | 1584x672 | 1120 | 3168x1344 | 1120 | 6336x2688 | 2000 |
صورة Gemini 2.5 Flash
| نسبة العرض إلى الارتفاع | الدقة | الرموز المميزة |
|---|---|---|
| 1:1 | 1024x1024 | 1290 |
| 2:3 | 832x1248 | 1290 |
| 3:2 | 1248x832 | 1290 |
| 3:4 | 864 × 1184 | 1290 |
| 4:3 | 1184x864 | 1290 |
| 4:5 | 896×1152 | 1290 |
| 5:4 | 1152x896 | 1290 |
| 9:16 | 768x1344 | 1290 |
| 16:9 | 1344x768 | 1290 |
| 21:9 | 1536x672 | 1290 |
اختيار النموذج
اختَر النموذج الأنسب لحالة الاستخدام المحدّدة.
ننصحك باستخدام Gemini 3.1 Flash Image (Nano Banana 2) كنموذج أساسي لإنشاء الصور، فهو يقدّم أفضل أداء شامل ويحقق التوازن بين الذكاء والتكلفة ووقت الاستجابة. لمزيد من التفاصيل، يُرجى الاطّلاع على صفحة الأسعار والإمكانات الخاصة بالنموذج.
Gemini 3.1 Flash Lite Image (Nano Banana 2 Lite) هو النموذج الأكثر فعالية ضمن مجموعة نماذج إنشاء الصور، إذ يوفّر إنشاء الصور وتعديلها بتأخير منخفض جدًا وبتكلفة فعالة. لمزيد من التفاصيل، يُرجى الاطّلاع على صفحة الأسعار والإمكانات الخاصة بالنموذج.
تم تصميم Gemini 3 Pro Image (Nano Banana Pro) لإنتاج مواد عرض احترافية وتنفيذ التعليمات المعقّدة. يتميّز هذا النموذج بإمكانية الاستناد إلى معلومات واقعية باستخدام "بحث Google"، وبإجراء عملية "التفكير" تلقائيًا لتحسين التركيب قبل الإنشاء، ويمكنه إنشاء صور بدقة تصل إلى 4K. لمزيد من التفاصيل، يُرجى الاطّلاع على صفحة الأسعار والإمكانات الخاصة بالنموذج.
تم تصميم Gemini 2.5 Flash Image (المعروف أيضًا باسم Nano Banana) لتحقيق السرعة والكفاءة. تم تحسين هذا النموذج لتنفيذ المهام التي تتطلّب عددًا كبيرًا من الطلبات ووقت استجابة منخفضًا، وهو ينشئ صورًا بدقة 1024 بكسل. يمكنك الاطّلاع على صفحة الأسعار والإمكانات الخاصة بالنموذج للحصول على مزيد من التفاصيل.
حالات استخدام Imagen
بالإضافة إلى استخدام إمكانات إنشاء الصور المضمّنة في Gemini، يمكنك أيضًا الاستفادة من Imagen، نموذجنا المتخصّص في إنشاء الصور، من خلال Gemini API. ننصحك بالتخطيط لنقل البيانات قبل تاريخ الإيقاف النهائي.
الخطوات التالية
- راجِع دليل Veo للتعرّف على كيفية إنشاء فيديوهات باستخدام Gemini API.
- لمزيد من المعلومات حول نماذج Gemini، يُرجى الاطّلاع على نماذج Gemini.