Pembuatan gambar Nano Banana
- Atau buat sendiri dari perintah:
-








-
Dibuat oleh Nano Banana 2 Perintah: "Foto sampul majalah glossy, sampul biru minimalis memiliki kata-kata Nano Banana yang besar dan tebal. Teks menggunakan font serif dan mengisi tampilan. Tidak ada teks lain. Di depan teks terdapat potret seseorang yang mengenakan gaun elegan dan minimalis. Dia memegang angka 2 dengan lucu, yang merupakan titik fokus.
Letakkan nomor masalah dan tanggal "Feb 2026" di sudut bersama dengan kode batang. Majalah tersebut berada di rak di depan dinding yang diplester berwarna oranye, di dalam toko desainer." -
Dibuat oleh Nano Banana Pro Perintah: "Tampilkan adegan kartun 3D miniatur isometrik yang jelas, dilihat dari atas pada sudut 45°, tentang London, yang menampilkan landmark dan elemen arsitekturnya yang paling ikonik. Gunakan tekstur lembut dan halus dengan material PBR realistis serta pencahayaan dan bayangan yang lembut dan tampak nyata. Integrasikan kondisi cuaca saat ini langsung ke lingkungan kota untuk menciptakan suasana yang imersif. Gunakan komposisi yang bersih dan minimalis dengan latar belakang warna solid yang lembut. Di bagian tengah atas, tempatkan judul "London" dalam teks tebal besar, ikon cuaca yang terlihat jelas di bawahnya, lalu tanggal (teks kecil) dan suhu (teks sedang). Semua teks harus berada di tengah dengan jarak yang konsisten, dan dapat sedikit tumpang-tindih dengan bagian atas bangunan." -
Dibuat oleh Nano Banana 2 Perintah: "Gunakan penelusuran gambar untuk menemukan gambar akurat burung quetzal yang indah. Buat wallpaper 3:2 yang indah dari burung ini, dengan gradien alami dari atas ke bawah dan komposisi minimal." -

Dibuat oleh Nano Banana Pro Perintah: "Letakkan logo ini pada iklan kelas atas untuk parfum beraroma pisang. Logo terintegrasi sempurna ke dalam botol." -
Dibuat oleh Nano Banana Pro Perintah: "Foto suasana sehari-hari di kafe ramai yang menyajikan sarapan. Di latar depan ada seorang pria anime berambut biru, salah satu orang adalah sketsa pensil, yang lain adalah orang claymation" -
Dibuat oleh Nano Banana Pro Perintah: "Gunakan penelusuran untuk mengetahui tanggapan terhadap peluncuran Gemini 3 Flash. Gunakan informasi ini untuk menulis artikel singkat tentangnya (dengan judul). Tampilkan foto artikel seperti yang muncul di majalah glossy yang berfokus pada desain. Gambar tersebut adalah foto satu halaman yang dilipat, yang menampilkan artikel tentang Gemini 3 Flash. Satu foto utama. Judul dalam huruf serif." -
Dibuat oleh Nano Banana Pro Perintah: "Ikon yang merepresentasikan lucu. Latar belakangnya berwarna putih. Buat ikon dalam gaya 3D yang berwarna-warni dan terasa nyata. Tidak ada teks." -
Dibuat oleh Nano Banana 2 Perintah: "Buat foto yang isometrik sempurna. Ini bukan miniatur, ini adalah foto yang diambil dan kebetulan isometrik sempurna. Ini adalah foto taman modern yang indah. Terdapat kolam renang besar berbentuk 2 dan kata-kata: Nano Banana 2."
Nano Banana adalah nama untuk kemampuan pembuatan gambar native Gemini. Gemini dapat membuat dan memproses gambar melalui percakapan dengan teks, gambar, atau kombinasi keduanya. Dengan begitu, Anda dapat membuat, mengedit, dan melakukan iterasi pada visual dengan kontrol yang belum pernah ada sebelumnya.
Nano Banana mengacu pada empat model berbeda yang tersedia di Gemini API:
- Nano Banana 2 Lite (Gemini 3.1 Flash Lite Image)
(
gemini-3.1-flash-lite-image): Model gambar Gemini tercepat dan termurah kami, yang dirancang untuk kecepatan dan skala di mana kecepatan dan biaya adalah batasan operasional utama. Tidak dioptimalkan untuk beberapa input referensi atau pengeditan berurutan multi-putaran. - Nano Banana 2 (Gemini 3.1 Flash Image)
(
gemini-3.1-flash-image): Berfungsi sebagai model serbaguna, model pekerja keras generalis untuk semua tugas. Model ini menyeimbangkan kecepatan dengan pembuatan 4K canggih, pengetahuan umum, dan rendering teks yang andal. Unggul dalam pemrosesan dan konsistensi beberapa gambar referensi. - Nano Banana Pro (Gambar Gemini 3 Pro)
(
gemini-3-pro-image): Pilihan premium untuk tugas visual paling kompleks, yang menawarkan tingkat pengetahuan dunia tertinggi, pelokalan tingkat lanjut, konsistensi merek yang akurat, dan kontrol kreatif yang presisi. - Nano Banana (Gemini 2.5 Flash Image)
(
gemini-2.5-flash-image): Pelopor lama seri Nano Banana. Meskipun telah menjadi andalan yang andal, sebaiknya pelanggan beralih ke Nano Banana 2 Lite untuk merasakan peningkatan kualitas, kecepatan pembuatan yang lebih cepat, dan harga API yang lebih rendah.
Semua gambar yang dihasilkan menyertakan watermark SynthID.
Pembuatan gambar (teks ke gambar)
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme",
)
with open("generated_image.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const prompt =
"Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme";
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: prompt,
});
const generatedImage = interaction.output_image;
if (generatedImage) {
const buffer = Buffer.from(generatedImage.data, "base64");
fs.writeFileSync("gemini-native-image.png", buffer);
console.log("Image saved as gemini-native-image.png");
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{"type": "text", "text": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme"}
]
}'
Anda dapat mengambil data gambar yang dibuat menggunakan properti interaction.output_image, yang menampilkan blok gambar terakhir yang dibuat. Untuk mengetahui detail properti praktis, lihat Ringkasan interaksi.
Pengeditan gambar (text-and-image-to-image)
Pengingat: Pastikan Anda memiliki hak yang diperlukan atas gambar apa pun yang Anda upload. Jangan membuat konten yang melanggar hak orang lain, termasuk video atau gambar yang menipu, melecehkan, atau membahayakan. Penggunaan layanan AI generatif ini oleh Anda tunduk pada Kebijakan Penggunaan Terlarang kami.
Berikan gambar dan gunakan perintah teks untuk menambahkan, menghapus, atau mengubah elemen, mengubah gaya, atau menyesuaikan gradasi warna.
Contoh berikut menunjukkan cara mengupload gambar yang dienkode base64.
Untuk beberapa gambar, payload yang lebih besar, dan jenis MIME yang didukung, lihat halaman Pemahaman gambar.
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open("/path/to/cat_image.png", "rb") as f:
image_bytes = f.read()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "text",
"text": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
}
],
)
with open("generated_image.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "path/to/cat_image.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const prompt = [
{ type: "text", text: "Create a picture of my cat eating a nano-banana in a" +
"fancy restaurant under the Gemini constellation" },
{
type: "image",
mime_type: "image/png",
data: base64Image
},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: prompt,
});
const generatedImage = interaction.output_image;
if (generatedImage) {
const buffer = Buffer.from(generatedImage.data, "base64");
fs.writeFileSync("gemini-native-image.png", buffer);
console.log("Image saved as gemini-native-image.png");
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"text\", \"text\": \"Create a picture of my cat eating a nano-banana in a fancy restaurant under the Gemini constellation\"},
{
\"type\": \"image\",
\"mime_type\": \"image/jpeg\",
\"data\": \"<BASE64_IMAGE_DATA>\"
}
]
}"
Pengeditan gambar multi-turn
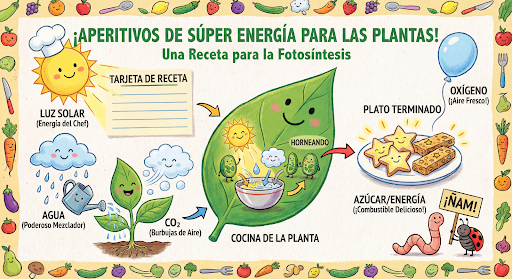
Terus buat dan edit gambar melalui percakapan. Percakapan multi-giliran adalah cara yang direkomendasikan untuk melakukan iterasi pada gambar. Contoh berikut menunjukkan perintah untuk membuat infografis tentang fotosintesis.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plant's favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids' cookbook, suitable for a 4th grader.",
tools=[{"type": "google_search"}],
)
with open("photosynthesis.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
const ai = new GoogleGenAI({});
async function main() {
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plant's favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids' cookbook, suitable for a 4th grader.",
tools: [{"type": "google_search"}],
});
const generatedImage = interaction.output_image;
if (generatedImage) {
const buffer = Buffer.from(generatedImage.data, "base64");
fs.writeFileSync("photosynthesis.png", buffer);
console.log("Image saved as photosynthesis.png");
}
}
await main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{"type": "text", "text": "Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plants favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids cookbook, suitable for a 4th grader."}
],
"tools": [{"type": "google_search"}]
}'

Kemudian, Anda dapat menggunakan previous_interaction_id untuk mengubah bahasa pada grafik menjadi Spanyol.
Python
interaction_2 = client.interactions.create(
model="gemini-3.1-flash-image",
input="Update this infographic to be in Spanish. Do not change any other elements of the image.",
previous_interaction_id=interaction.id,
response_format={
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9",
"image_size": "2K"
},
)
generated_image = interaction_2.output_image
if generated_image:
with open("photosynthesis_spanish.png", "wb") as f:
f.write(base64.b64decode(generated_image.data))
JavaScript
const interaction2 = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Update this infographic to be in Spanish. Do not change any other elements of the image.",
previous_interaction_id: interaction.id,
response_format: {
type: "image",
mime_type: "image/png",
aspect_ratio: "16:9",
image_size: "2K"
},
});
const generatedImage = interaction2.output_image;
if (generatedImage) {
const buffer = Buffer.from(generatedImage.data, "base64");
fs.writeFileSync("photosynthesis_spanish.png", buffer);
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Update this infographic to be in Spanish. Do not change any other elements of the image.",
"previous_interaction_id": "<PREVIOUS_INTERACTION_ID>",
"response_format": {
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9",
"image_size": "2K"
}
}'
Baru dengan model Gambar Gemini 3
Gemini 3 menawarkan model pengeditan dan pembuatan gambar tercanggih. Gemini 3.1 Flash Image dioptimalkan untuk kecepatan dan kasus penggunaan bervolume tinggi, sedangkan Gemini 3 Pro Image dioptimalkan untuk produksi aset profesional. Dirancang untuk menangani alur kerja yang paling menantang melalui penalaran tingkat lanjut, model ini unggul dalam tugas pembuatan dan modifikasi yang kompleks dan melibatkan banyak giliran.
- Output resolusi tinggi: Kemampuan pembuatan bawaan untuk visual 1K, 2K, dan 4K.
- Gambar Flash Gemini 3.1 menambahkan resolusi 512 piksel (0,5K) yang lebih kecil.
- Gemini 3.1 Flash Lite Image hanya mendukung resolusi 1K.
- Rendering teks lanjutan: Mampu membuat teks yang mudah dibaca dan bergaya untuk infografis, menu, diagram, dan aset pemasaran.
- Grounding dengan Google Penelusuran: Model dapat menggunakan Google Penelusuran sebagai alat untuk memverifikasi fakta dan membuat gambar berdasarkan data real-time (misalnya, peta cuaca saat ini, diagram saham, peristiwa terkini).
- Tidak didukung oleh model Gemini 3.1 Flash Lite Image.
- Gemini 3.1 Flash Image menambahkan integrasi Google Penelusuran Gambar dengan Web Search untuk melakukan perujukan.
- Mode penalaran: Model menggunakan proses "penalaran" untuk menalar perintah yang kompleks. Fitur ini menghasilkan "gambar pemikiran" sementara (dapat dilihat di backend, tetapi tidak dikenai biaya) untuk menyempurnakan komposisi sebelum menghasilkan output akhir berkualitas tinggi.
- Hingga 14 gambar referensi: Anda kini dapat menggabungkan hingga 14 gambar referensi untuk menghasilkan gambar akhir.
- Rasio aspek baru: Gemini 3.1 Flash Lite Image menambahkan
1:1,3:2,2:3,3:4,4:3,4:5,5:4,9:16,16:9,21:9rasio aspek.
Menggunakan hingga 14 gambar referensi
Model gambar Gemini 3 memungkinkan Anda menggabungkan hingga 14 gambar referensi. 14 gambar ini dapat mencakup hal berikut:
| Gambar Gemini 3.1 Flash Lite | Gambar Gemini 3.1 Flash | Gemini 3 Pro Image |
|---|---|---|
| Hingga 14 gambar objek dengan fidelitas tinggi untuk disertakan dalam gambar akhir | Hingga 10 gambar objek dengan fidelitas tinggi untuk disertakan dalam gambar akhir | Hingga 6 gambar objek dengan fidelitas tinggi untuk disertakan dalam gambar akhir |
| T/A | Hingga 4 gambar karakter untuk mempertahankan konsistensi karakter | Hingga 5 gambar karakter untuk mempertahankan konsistensi karakter |
| T/A | T/A | Hingga 3 gambar yang akan digunakan sebagai referensi gaya |
Python
from google import genai
from google.genai import types
from PIL import Image
import base64
prompt = "An office group photo of these people, they are making funny faces."
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "text",
"text": prompt,
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
],
response_format={
"type": "image",
"aspect_ratio": "5:4",
"image_size": "2K"
},
)
with open("office.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const input = [
{
type: "text",
text: "An office group photo of these people, they are making funny faces.",
},
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile1 },
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile2 },
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile3 },
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile4 },
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile5 },
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
response_format: {
type: "image",
aspect_ratio: "5:4",
image_size: "2K",
},
});
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('office.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"text\", \"text\": \"An office group photo of these people, they are making funny faces.\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_1>\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_2>\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_3>\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_4>\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_5>\"}
],
\"response_format\": {
\"type\": \"image\",
\"aspect_ratio\": \"5:4\",
\"image_size\": \"2K\"
}
}"

Grounding dengan Google Penelusuran
Gunakan alat Google Penelusuran untuk membuat gambar berdasarkan informasi real-time, seperti prakiraan cuaca, diagram saham, atau peristiwa terkini.
Perhatikan bahwa saat menggunakan Grounding with Google Search dengan pembuatan gambar, hasil penelusuran berbasis gambar tidak diteruskan ke model generatif dan dikecualikan dari respons (lihat Grounding dengan Google Penelusuran Gambar)
Python
from google import genai
from google.genai import types
import base64
prompt = "Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day"
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=prompt,
tools=[{"type": "google_search"}],
response_format={
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9"
},
)
with open("weather.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day",
tools: [{"type": "google_search"}],
response_format: {
type: "image",
mime_type: "image/png",
aspect_ratio: "16:9",
image_size: "2K"
},
});
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('weather.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{"type": "text", "text": "Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day"}
],
"tools": [{"type": "google_search"}],
"response_format": {
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9"
}
}'

Respons mencakup langkah-langkah google_search_call dan google_search_result,
beserta anotasi url_citation inline pada langkah teks:
google_search_result: Berisisearch_suggestions, cuplikan HTML untuk merender saran penelusuran di UI Anda.- Anotasi
url_citation: Kutipan inline pada langkah teks yang menautkan bagian respons ke sumber webnya.
Grounding dengan Google Penelusuran untuk Gambar (3.1 Flash)
Grounding dengan Penelusuran Gambar Google memungkinkan model menggunakan gambar web yang diambil melalui Penelusuran Gambar Google sebagai konteks visual untuk pembuatan gambar. Penelusuran Gambar adalah jenis penelusuran baru dalam alat Grounding with Google Search yang sudah ada, yang berfungsi bersama Penelusuran Web standar.
Untuk mengaktifkan Penelusuran Gambar, konfigurasi alat google_search dalam permintaan API Anda dan tentukan image_search dalam array search_types. Penelusuran Gambar dapat digunakan secara terpisah atau bersama dengan Penelusuran Web.
Python
from google import genai
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A detailed painting of a Timareta butterfly resting on a flower",
tools=[{
"type": "google_search",
"search_types": ["web_search", "image_search"]
}]
)
JavaScript
import { GoogleGenAI } from "@google/genai";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A detailed painting of a Timareta butterfly resting on a flower",
tools: [{
"type": "google_search",
"search_types": ["web_search", "image_search"]
}]
});
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A detailed painting of a Timareta butterfly resting on a flower",
"tools": [{"type": "google_search", "search_types": ["web_search", "image_search"]}]
}'
Persyaratan tampilan
Saat menggunakan Penelusuran Gambar dalam Grounding dengan Google Penelusuran, Anda harus menampilkan
search_suggestions dari langkah google_search_result. Persyaratan penggunaan
lengkap dijelaskan dalam
Persyaratan Layanan.
Respons
Untuk respons yang memiliki rujukan menggunakan penelusuran gambar, API menampilkan kutipan inline dan metadata atribusi sebagai bagian dari langkah-langkah respons:
Anotasi
url_citation: Kutipan inline pada blok konten teks dalammodel_output, yang menautkan konten yang dihasilkan ke sumbernya.google_search_result: Berisisearch_suggestions, cuplikan HTML untuk merender saran penelusuran di UI Anda.
Pembuatan gambar dari video (3.1 Flash)
Pembuatan video ke gambar memungkinkan Anda membuat gambar baru menggunakan konteks video sebagai referensi multimodal. Hal ini berguna untuk membuat thumbnail video berkualitas tinggi, poster sinematik, infografis ringkasan, atau karya seni baru yang terinspirasi dari adegan video.
Selama pembuatan, model menganalisis frame video dalam konteks untuk mengekstrak tema visual dan peristiwa utama, lalu menggunakannya bersama dengan perintah teks Anda untuk menyintesis gambar output.
Anda dapat meneruskan URL YouTube publik secara langsung dalam permintaan API atau mengupload file video lokal menggunakan Files API.
Python
from google import genai
from google.genai import types
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "video",
"uri": "https://www.youtube.com/watch?v=UTdfxFyOQTI",
"mime_type": "video/mp4"
},
{"type": "text", "text": "Generate a poster image that captures the key themes of this video."}
],
response_format={"type": "image", "aspect_ratio": "16:9"}
)
# Save the generated image part
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("video_poster.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
print("Image saved as video_poster.png")
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: [
{
type: "video",
uri: "https://www.youtube.com/watch?v=UTdfxFyOQTI",
mime_type: "video/mp4"
},
{ type: "text", text: "Generate a poster image that captures the key themes of this video." }
],
response_format: {
type: "image",
aspect_ratio: "16:9"
}
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("video_poster.png", buffer);
console.log("Image saved as video_poster.png");
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{
"type": "video",
"uri": "https://www.youtube.com/watch?v=UTdfxFyOQTI",
"mime_type": "video/mp4"
},
{
"type": "text",
"text": "Generate a poster image that captures the key themes of this video."
}
],
"response_format": {
"type": "image",
"aspect_ratio": "16:9"
}
}'

Membuat gambar dengan resolusi hingga 4K
Model gambar Gemini 3 menghasilkan 1.000 gambar secara default, tetapi juga dapat menghasilkan gambar 2K, 4K, dan 512 px (05.K) (khusus Gemini 3.1 Flash Image). Untuk membuat aset dengan resolusi lebih tinggi, tentukan image_size di response_format.
Anda harus menggunakan huruf besar 'K' (misalnya, 512 piksel (05.K), 1K, 2K, 4K). Parameter huruf kecil (misalnya, 1k) akan ditolak.
Python
from google import genai
from google.genai import types
import base64
prompt = "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English."
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=prompt,
response_format={
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "1:1",
"image_size": "1K"
},
)
print(interaction.output_text)
with open("butterfly.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English.",
response_format: {
type: "image",
mime_type: "image/png",
aspect_ratio: "1:1",
image_size: "1K",
},
});
console.log(interaction.output_text);
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('butterfly.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English.",
"response_format": {
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "1:1",
"image_size": "1K"
}
}'
Berikut adalah contoh gambar yang dihasilkan dari perintah ini:

Proses Berpikir
Model gambar Gemini 3 adalah model pemikiran yang menggunakan proses penalaran ("Penalaran") untuk perintah yang kompleks. Fitur ini diaktifkan secara default dan tidak dapat dinonaktifkan di API. Untuk mempelajari lebih lanjut proses berpikirnya, lihat panduan Proses Berpikir Gemini.
Model ini menghasilkan hingga dua gambar sementara untuk menguji komposisi dan logika. Gambar terakhir dalam Thinking juga merupakan gambar akhir yang dirender.
Anda dapat memeriksa pemikiran yang menghasilkan gambar akhir.
Python
for step in interaction.steps:
if step.type == "thought":
for content_block in step.summary:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
image = Image.open(io.BytesIO(base64.b64decode(content_block.data)))
image.show()
JavaScript
for (const step of interaction.steps) {
if (step.type === "thought") {
for (const contentBlock of step.summary) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, 'base64');
fs.writeFileSync('thought_image.png', buffer);
}
}
}
}
Teks dan gambar yang diselingi
Meskipun model pembuatan gambar standar hanya menghasilkan gambar, beberapa model Gemini 3 yang canggih (seperti gemini-3-pro-image) dapat menghasilkan konten yang disisipkan—seperti cerita atau panduan instruksional yang berisi blok teks dan ilustrasi dalam respons yang sama.
Karena outputnya rumit dan saling terkait, properti praktis seperti
.output_image atau .output_text tidak akan merekam seluruh urutan. Untuk mengakses
dan menyimpan konten yang disisipkan, Anda harus melakukan iterasi secara manual pada steps:
Python
interaction = client.interactions.create(
model="gemini-3-pro-image",
input="Write the story of the lifecycle of a monarch butterfly, interleave illustrations",
)
image_counter = 1
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
filename = f"butterfly_lifecycle_{image_counter}.png"
with open(filename, "wb") as f:
f.write(base64.b64decode(content_block.data))
print(f"\n[Saved illustration: {filename}]\n")
image_counter += 1
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3-pro-image",
input: "Write the story of the lifecycle of a monarch butterfly, interleave illustrations",
});
let imageCounter = 1;
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
const filename = `butterfly_lifecycle_${imageCounter}.png`;
fs.writeFileSync(filename, buffer);
console.log(`\n[Saved illustration: ${filename}]\n`);
imageCounter++;
}
}
}
}
Mengontrol tingkat penalaran
Dengan Gemini 3.1 Flash Image, Anda dapat mengontrol jumlah pemikiran yang digunakan model untuk menyeimbangkan kualitas dan latensi. thinking_level default adalah minimal,
dan tingkat yang didukung adalah minimal dan high.
Python
from google import genai
from PIL import Image
import base64
import io
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A futuristic city built inside a giant glass bottle floating in space",
generation_config={"thinking_level": "high"},
)
print(interaction.output_text)
image = Image.open(io.BytesIO(base64.b64decode(interaction.output_image.data)))
image.show()
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A futuristic city built inside a giant glass bottle floating in space",
generation_config: { thinking_level: "high" },
});
console.log(interaction.output_text);
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('image.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A futuristic city built inside a giant glass bottle floating in space",
"generation_config": {
"thinking_level": "high"
}
}'
Perhatikan bahwa token pemikiran ditagih secara default untuk model pemikiran, karena proses pemikiran selalu terjadi secara default, baik Anda melihat prosesnya atau tidak.
Mode pembuatan gambar lainnya
Meskipun model pembuatan gambar Nano Banana direkomendasikan untuk sebagian besar kasus penggunaan, Anda juga dapat menjelajahi model pembuatan gambar khusus:
- Imagen: Model pembuatan gambar dari teks Google yang dioptimalkan untuk menghasilkan gambar berkualitas tinggi.
- Veo: Model pembuatan video Google.
Membuat gambar secara batch
Semua kemampuan pembuatan gambar yang dijelaskan di halaman ini juga dapat dijalankan sebagai tugas batch menggunakan Batch API, yang ideal jika Anda perlu membuat banyak gambar.Anda akan mendapatkan batas frekuensi yang lebih tinggi dengan imbalan waktu penyelesaian hingga 24 jam.
Panduan dan strategi penulisan perintah
Bagian ini memberikan contoh dan template perintah untuk alur kerja pembuatan dan pengeditan gambar umum. Setiap contoh mencakup template yang dapat digunakan kembali dan contoh perintah untuk Interactions API.
Perintah untuk membuat gambar
Contoh berikut menunjukkan cara menggunakan perintah teks untuk membuat berbagai jenis gambar.
1. Adegan fotorealistik
Deskripsikan adegan dengan detail yang kaya. Makin spesifik perintah Anda, makin besar kontrol yang Anda miliki atas hasilnya.
Template
A photorealistic [type of shot] of a [subject description] in a [setting
description]. [Description of the light]. Shot from a [camera angle]
with a [lens type].
Perintah
A photorealistic wide-angle shot of a vibrant coral reef teeming with tropical fish. Crystal-clear turquoise water with sunbeams filtering down from the surface, illuminating a sea turtle gliding gracefully over the coral. Shot from a low perspective with a wide-angle lens. Aspect ratio 16:9.
Python
from google import genai
from google.genai import types
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A photorealistic wide-angle shot of a vibrant coral reef teeming with tropical fish. Crystal-clear turquoise water with sunbeams filtering down from the surface, illuminating a sea turtle gliding gracefully over the coral. Shot from a low perspective with a wide-angle lens. Aspect ratio 16:9.",
response_format=[
{
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9",
}
],
)
print(interaction.output_text)
with open("coral_reef.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A photorealistic wide-angle shot of a vibrant coral reef teeming with tropical fish. Crystal-clear turquoise water with sunbeams filtering down from the surface, illuminating a sea turtle gliding gracefully over the coral. Shot from a low perspective with a wide-angle lens. Aspect ratio 16:9.",
response_format: [
{
type: "image",
mime_type: "image/jpeg",
aspect_ratio: "16:9",
}
],
});
console.log(interaction.output_text);
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('coral_reef.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A photorealistic wide-angle shot of a vibrant coral reef teeming with tropical fish. Crystal-clear turquoise water with sunbeams filtering down from the surface, illuminating a sea turtle gliding gracefully over the coral. Shot from a low perspective with a wide-angle lens. Aspect ratio 16:9.",
"response_format": {
"type": "image",
"mime_type": "image/png",
"aspect_ratio": "16:9"
}
}'

2. Ilustrasi & stiker bergaya
Deskripsikan gaya artistik, subjek, dan media. Tentukan detail visual (garis tebal, warna, dll.) untuk hasil yang konsisten.
Template
A [style] of a [subject, with details about accessories or actions]
doing [activity]. The design features [visual qualities, e.g., bold outlines,
cel-shading, etc.] and [color/background preference].
Perintah
A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It's munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It's munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white.",
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("red_panda_sticker.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It's munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white.",
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("red_panda_sticker.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It is munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white."
}'

3. Teks yang akurat dalam gambar
Gemini unggul dalam merender teks. Jelaskan teks, gaya font (secara deskriptif), dan desain keseluruhan. Gunakan Gemini 3 Pro Image untuk produksi aset profesional.
Template
Create a [image type] for [brand/concept] with the text "[text to render]"
in a [font style]. The design should be [style description], with a
[color scheme].
Perintah
Create a modern, minimalist logo for a coffee shop called 'The Daily Grind'. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Create a modern, minimalist logo for a coffee shop called 'The Daily Grind'. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way.",
response_format={"type": "image", "aspect_ratio": "1:1"},
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("logo_example.jpg", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Create a modern, minimalist logo for a coffee shop called 'The Daily Grind'. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way.",
response_format: { type: "image", aspect_ratio: "1:1" },
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("logo_example.jpg", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Create a modern, minimalist logo for a coffee shop called The Daily Grind. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way.",
"response_format": {
"type": "image",
"aspect_ratio": "1:1"
}
}'
4. Mockup produk & fotografi komersial
Sempurna untuk membuat gambar produk yang bersih dan profesional untuk e-commerce, iklan, atau branding.
Template
A high-resolution, studio-lit product photograph of a [product description]
on a [background surface/description]. The lighting is a [lighting setup,
e.g., three-point softbox setup] to [lighting purpose]. The camera angle is
a [angle type] to showcase [specific feature]. Ultra-realistic, with sharp
focus on [key detail]. [Aspect ratio].
Perintah
A high-resolution, studio-lit product photograph of a minimalist ceramic
coffee mug in matte black, presented on a polished concrete surface. The
lighting is a three-point softbox setup designed to create soft, diffused
highlights and eliminate harsh shadows. The camera angle is a slightly
elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with
sharp focus on the steam rising from the coffee. Square image.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A high-resolution, studio-lit product photograph of a minimalist ceramic coffee mug in matte black, presented on a polished concrete surface. The lighting is a three-point softbox setup designed to create soft, diffused highlights and eliminate harsh shadows. The camera angle is a slightly elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with sharp focus on the steam rising from the coffee. Square image.",
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("product_mockup.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A high-resolution, studio-lit product photograph of a minimalist ceramic coffee mug in matte black, presented on a polished concrete surface. The lighting is a three-point softbox setup designed to create soft, diffused highlights and eliminate harsh shadows. The camera angle is a slightly elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with sharp focus on the steam rising from the coffee. Square image.",
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("product_mockup.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A high-resolution, studio-lit product photograph of a minimalist ceramic coffee mug in matte black, presented on a polished concrete surface. The lighting is a three-point softbox setup designed to create soft, diffused highlights and eliminate harsh shadows. The camera angle is a slightly elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with sharp focus on the steam rising from the coffee. Square image."
}'

5. Desain minimalis & ruang negatif
Sangat cocok untuk membuat latar belakang situs, presentasi, atau materi pemasaran yang akan menampilkan teks di atasnya.
Template
A minimalist composition featuring a single [subject] positioned in the
[bottom-right/top-left/etc.] of the frame. The background is a vast, empty
[color] canvas, creating significant negative space. Soft, subtle lighting.
[Aspect ratio].
Perintah
A minimalist composition featuring a single, delicate red maple leaf
positioned in the bottom-right of the frame. The background is a vast, empty
off-white canvas, creating significant negative space for text. Soft,
diffused lighting from the top left. Square image.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A minimalist composition featuring a single, delicate red maple leaf positioned in the bottom-right of the frame. The background is a vast, empty off-white canvas, creating significant negative space for text. Soft, diffused lighting from the top left. Square image.",
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("minimalist_design.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A minimalist composition featuring a single, delicate red maple leaf positioned in the bottom-right of the frame. The background is a vast, empty off-white canvas, creating significant negative space for text. Soft, diffused lighting from the top left. Square image.",
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("minimalist_design.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A minimalist composition featuring a single, delicate red maple leaf positioned in the bottom-right of the frame. The background is a vast, empty off-white canvas, creating significant negative space for text. Soft, diffused lighting from the top left. Square image."
}'

6. Seni berurutan (Panel komik / Storyboard)
Membangun konsistensi karakter dan deskripsi adegan untuk membuat panel penceritaan visual. Untuk akurasi dengan teks dan kemampuan bercerita, perintah ini paling cocok digunakan dengan Gemini 3 Pro dan Gemini 3.1 Flash Image.
Template
Make a 3 panel comic in a [style]. Put the character in a [type of scene].
Perintah
Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene.
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/man_in_white_glasses.jpg', 'rb') as f:
image_bytes = f.read()
text_input = "Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene."
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{"type": "text", "text": text_input},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/jpeg"
}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("comic_panel.jpg", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/man_in_white_glasses.jpg";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const input = [
{ type: "text", text: "Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene." },
{
type: "image",
mime_type: "image/jpeg",
data: base64Image
},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("comic_panel.jpg", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{"type": "text", "text": "Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene."},
{"type": "image", "data": "<BASE64_IMAGE_DATA>", "mime_type": "image/jpeg"}
]
}'
Input |
Output |

|

|
7. Grounding dengan Google Penelusuran
Gunakan Google Penelusuran untuk membuat gambar berdasarkan informasi terbaru atau real-time. Hal ini berguna untuk berita, cuaca, dan topik mendesak lainnya.
Perintah
Make a simple but stylish graphic of last night's Arsenal game in the Champion's League
Python
from google import genai
from google.genai import types
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Make a simple but stylish graphic of last night's Arsenal game in the Champion's League",
tools=[{"type": "google_search"}],
response_format={"type": "image", "aspect_ratio": "16:9"},
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("football-score.jpg", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Make a simple but stylish graphic of last night's Arsenal game in the Champion's League",
tools: [{ type: "google_search" }],
response_format: { type: "image", aspect_ratio: "16:9", image_size: "2K" },
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("football-score.jpg", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Make a simple but stylish graphic of last nights Arsenal game in the Champions League",
"tools": [{"type": "google_search"}],
"response_format": {
"type": "image",
"aspect_ratio": "16:9"
}
}'

Perintah untuk mengedit gambar
Contoh ini menunjukkan cara memberikan gambar bersama perintah teks Anda untuk pengeditan, komposisi, dan transfer gaya.
1. Menambahkan dan menghapus elemen
Berikan gambar dan deskripsikan perubahan Anda. Model akan cocok dengan gaya, pencahayaan, dan perspektif gambar asli.
Template
Using the provided image of [subject], please [add/remove/modify] [element]
to/from the scene. Ensure the change is [description of how the change should
integrate].
Perintah
"Using the provided image of my cat, please add a small, knitted wizard hat
on its head. Make it look like it's sitting comfortably and matches the soft
lighting of the photo."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/cat_photo.png', 'rb') as f:
image_bytes = f.read()
text_input = """Using the provided image of my cat, please add a small, knitted wizard hat on its head. Make it look like it's sitting comfortably and not falling off."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{"type": "text", "text": text_input},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("cat_with_hat.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/cat_photo.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const input = [
{ type: "text", text: "Using the provided image of my cat, please add a small, knitted wizard hat on its head. Make it look like it's sitting comfortably and not falling off." },
{
type: "image",
mime_type: "image/png",
data: base64Image
},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("cat_with_hat.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"text\", \"text\": \"Using the provided image of my cat, please add a small, knitted wizard hat on its head. Make it look like it's sitting comfortably and not falling off.\"},
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA>\"}
]
}"
Input |
Output |

|

|
2. Lukisan (Masking semantik)
Tentukan "mask" secara percakapan untuk mengedit bagian tertentu dari gambar tanpa mengubah bagian lainnya.
Template
Using the provided image, change only the [specific element] to [new
element/description]. Keep everything else in the image exactly the same,
preserving the original style, lighting, and composition.
Perintah
"Using the provided image of a living room, change only the blue sofa to be
a vintage, brown leather chesterfield sofa. Keep the rest of the room,
including the pillows on the sofa and the lighting, unchanged."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/living_room.png', 'rb') as f:
image_bytes = f.read()
text_input = """Using the provided image of a living room, change only the blue sofa to be a vintage, brown leather chesterfield sofa. Keep the rest of the room, including the pillows on the sofa and the lighting, unchanged."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("living_room_edited.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/living_room.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const input = [
{
type: "image",
mime_type: "image/png",
data: base64Image
},
{ type: "text", text: "Using the provided image of a living room, change only the blue sofa to be a vintage, brown leather chesterfield sofa. Keep the rest of the room, including the pillows on the sofa and the lighting, unchanged." },
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("living_room_edited.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA>\"},
{\"type\": \"text\", \"text\": \"Using the provided image of a living room, change only the blue sofa to be a vintage, brown leather chesterfield sofa. Keep the rest of the room, including the pillows on the sofa and the lighting, unchanged.\"}
]
}"
Input |
Output |

|

|
3. Transfer gaya
Berikan gambar dan minta model untuk membuat ulang kontennya dalam gaya artistik yang berbeda.
Template
Transform the provided photograph of [subject] into the artistic style of [artist/art style]. Preserve the original composition but render it with [description of stylistic elements].
Perintah
"Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/city.png', 'rb') as f:
image_bytes = f.read()
text_input = """Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("city_style_transfer.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imageData = fs.readFileSync("/path/to/your/city.png");
const base64Image = imageData.toString("base64");
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: [
{
type: "image",
mime_type: "image/png",
data: base64Image
},
{ type: "text", text: "Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows." },
],
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("city_style_transfer.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA>\"},
{\"type\": \"text\", \"text\": \"Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows.\"}
]
}"
Input |
Output |

|

|
4. Komposisi lanjutan: Menggabungkan beberapa gambar
Berikan beberapa gambar sebagai konteks untuk membuat adegan komposit baru. Fitur ini sangat cocok untuk mockup produk atau kolase kreatif.
Template
Create a new image by combining the elements from the provided images. Take
the [element from image 1] and place it with/on the [element from image 2].
The final image should be a [description of the final scene].
Perintah
"Create a professional e-commerce fashion photo. Take the blue floral dress
from the first image and let the woman from the second image wear it.
Generate a realistic, full-body shot of the woman wearing the dress, with
the lighting and shadows adjusted to match the outdoor environment."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/dress.png', 'rb') as f:
dress_bytes = f.read()
with open('/path/to/your/model.png', 'rb') as f:
model_bytes = f.read()
text_input = """Create a professional e-commerce fashion photo. Take the blue floral dress from the first image and let the woman from the second image wear it. Generate a realistic, full-body shot of the woman wearing the dress, with the lighting and shadows adjusted to match the outdoor environment."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "image",
"data": base64.b64encode(dress_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(model_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("fashion_ecommerce_shot.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath1 = "/path/to/your/dress.png";
const imageData1 = fs.readFileSync(imagePath1);
const base64Image1 = imageData1.toString("base64");
const imagePath2 = "/path/to/your/model.png";
const imageData2 = fs.readFileSync(imagePath2);
const base64Image2 = imageData2.toString("base64");
const input = [
{
type: "image",
mime_type: "image/png",
data: base64Image1
},
{
type: "image",
mime_type: "image/png",
data: base64Image2
},
{ type: "text", text: "Create a professional e-commerce fashion photo. Take the blue floral dress from the first image and let the woman from the second image wear it. Generate a realistic, full-body shot of the woman wearing the dress, with the lighting and shadows adjusted to match the outdoor environment." },
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("fashion_ecommerce_shot.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA_1>\"},
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA_2>\"},
{\"type\": \"text\", \"text\": \"Create a professional e-commerce fashion photo. Take the blue floral dress from the first image and let the woman from the second image wear it. Generate a realistic, full-body shot of the woman wearing the dress, with the lighting and shadows adjusted to match the outdoor environment.\"}
}]
}"
Masukan 1 |
Input 2 |
Output |

|

|

|
5. Mempertahankan detail dengan fidelitas tinggi
Untuk memastikan detail penting (seperti wajah atau logo) dipertahankan selama pengeditan, deskripsikan detail tersebut secara mendalam bersama dengan permintaan pengeditan Anda.
Template
Using the provided images, place [element from image 2] onto [element from
image 1]. Ensure that the features of [element from image 1] remain
completely unchanged. The added element should [description of how the
element should integrate].
Perintah
"Take the first image of the woman with brown hair, blue eyes, and a neutral
expression. Add the logo from the second image onto her black t-shirt.
Ensure the woman's face and features remain completely unchanged. The logo
should look like it's naturally printed on the fabric, following the folds
of the shirt."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/woman.png', 'rb') as f:
woman_bytes = f.read()
with open('/path/to/your/logo.png', 'rb') as f:
logo_bytes = f.read()
text_input = """Take the first image of the woman with brown hair, blue eyes, and a neutral expression. Add the logo from the second image onto her black t-shirt. Ensure the woman's face and features remain completely unchanged. The logo should look like it's naturally printed on the fabric, following the folds of the shirt."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{"type": "image", "mime_type":"image/png", "data": base64.b64encode(woman_bytes).decode('utf-8')},
{"type": "image", "mime_type":"image/png", "data": base64.b64encode(logo_bytes).decode('utf-8')},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("woman_with_logo.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath1 = "/path/to/your/woman.png";
const imageData1 = fs.readFileSync(imagePath1);
const base64Image1 = imageData1.toString("base64");
const imagePath2 = "/path/to/your/logo.png";
const imageData2 = fs.readFileSync(imagePath2);
const base64Image2 = imageData2.toString("base64");
const input = [
{"type": "image", "mime_type":"image/png", "data": base64Image1},
{"type": "image", "mime_type":"image/png", "data": base64Image2},
{"type": "text", "text": "Take the first image of the woman with brown hair, blue eyes, and a neutral expression. Add the logo from the second image onto her black t-shirt. Ensure the woman's face and features remain completely unchanged. The logo should look like it's naturally printed on the fabric, following the folds of the shirt."},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("woman_with_logo.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA_1>\"},
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA_2>\"},
{\"type\": \"text\", \"text\": \"Take the first image of the woman with brown hair, blue eyes, and a neutral expression. Add the logo from the second image onto her black t-shirt. Ensure the woman's face and features remain completely unchanged. The logo should look like it's naturally printed on the fabric, following the folds of the shirt.\"}
]
}"
Masukan 1 |
Input 2 |
Output |

|
|
|
6. Menghidupkan sesuatu
Upload sketsa atau gambar kasar dan minta model untuk menyempurnakannya menjadi gambar akhir.
Template
Turn this rough [medium] sketch of a [subject] into a [style description]
photo. Keep the [specific features] from the sketch but add [new details/materials].
Perintah
"Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/car_sketch.png', 'rb') as f:
sketch_bytes = f.read()
text_input = """Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{"type": "image", "mime_type":"image/png", "data": base64.b64encode(sketch_bytes).decode('utf-8')},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("car_photo.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/car_sketch.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const input = [
{"type": "image", "mime_type":"image/png", "data": base64Image},
{"type": "text", "text": "Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting."},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("car_photo.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA>\"},
{\"type\": \"text\", \"text\": \"Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting.\"}
]
}"
Input |
Output |

|

|
7. Konsistensi karakter: Tampilan 360 derajat
Anda dapat membuat tampilan karakter 360 derajat dengan memberikan perintah secara berulang untuk mendapatkan sudut yang berbeda. Untuk hasil terbaik, sertakan gambar yang dibuat sebelumnya dalam perintah berikutnya untuk menjaga konsistensi. Untuk pose yang rumit, sertakan gambar referensi pose yang dipilih.
Template
A studio portrait of [person] against [background], [looking forward/in profile looking right/etc.]
Perintah
A studio portrait of this man against white, in profile looking right
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/man_in_white_glasses.jpg', 'rb') as f:
image_bytes = f.read()
text_input = """A studio portrait of this man against white, in profile looking right"""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input={
{"type": "text", "text": text_input},
{"type": "image", "mime_type":"image/png", "data": base64.b64encode(image_bytes).decode('utf-8')}
},
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("man_right_profile.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
Input |
Output 1 |
Output 2 |
|
|

|

|
Praktik Terbaik
Untuk meningkatkan hasil dari baik menjadi luar biasa, masukkan strategi profesional ini ke dalam alur kerja Anda.
- Bersifat Sangat Spesifik: Semakin detail informasi yang Anda berikan, semakin besar kontrol yang Anda miliki. Daripada "armor fantasi", jelaskan: "armor pelat elf yang indah, diukir dengan pola daun perak, dengan kerah tinggi dan pelindung bahu berbentuk seperti sayap elang".
- Berikan Konteks dan Maksud: Jelaskan tujuan gambar. Pemahaman model tentang konteks akan memengaruhi output akhir. Misalnya, "Buat logo untuk merek perawatan kulit minimalis kelas atas" akan memberikan hasil yang lebih baik daripada hanya "Buat logo".
- Lakukan Iterasi dan Tingkatkan Kualitas: Jangan mengharapkan gambar yang sempurna pada percobaan pertama. Gunakan sifat percakapan model untuk melakukan perubahan kecil. Tindak lanjuti dengan perintah seperti, "Bagus, tapi bisakah kamu membuat pencahayaannya sedikit lebih hangat?" atau "Biarkan semuanya sama, tetapi ubah ekspresi karakter menjadi lebih serius."
- Gunakan Petunjuk Langkah demi Langkah: Untuk adegan kompleks dengan banyak elemen, pecah perintah Anda menjadi beberapa langkah. "Pertama, buat latar belakang hutan berkabut yang tenang saat fajar. Kemudian, di latar depan, tambahkan altar batu kuno yang tertutup lumut. Terakhir, letakkan pedang tunggal yang bercahaya di atas altar."
- Gunakan "Perintah Negatif Semantik": Daripada mengatakan "tidak ada mobil", deskripsikan adegan yang diinginkan secara positif: "jalan yang kosong dan sepi tanpa tanda-tanda lalu lintas".
- Mengontrol Kamera: Gunakan bahasa fotografi dan sinematik untuk mengontrol komposisi. Istilah seperti
wide-angle shot,macro shot,low-angle perspective.
Batasan
- Untuk performa terbaik, gunakan bahasa berikut: EN, ar-EG, de-DE, es-MX, fr-FR, hi-IN, id-ID, it-IT, ja-JP, ko-KR, pt-BR, ru-RU, ua-UA, vi-VN, zh-CN.
- Pembuatan gambar tidak mendukung input audio. Input video hanya didukung untuk Gambar Gemini 3.1 Flash.
- Model tidak akan selalu mengikuti jumlah output gambar persis seperti yang diminta pengguna secara eksplisit.
gemini-2.5-flash-imageberfungsi paling baik dengan hingga 3 gambar sebagai input, sedangkangemini-3-pro-imagemendukung 5 gambar dengan fidelitas tinggi, dan hingga 14 gambar secara total.gemini-3.1-flash-imagemendukung kemiripan karakter hingga 4 karakter dan kualitas hingga 10 objek dalam satu alur kerja.- Saat membuat teks untuk gambar, Gemini akan berfungsi paling baik jika Anda membuat teks terlebih dahulu, lalu meminta gambar dengan teks tersebut.
gemini-3.1-flash-imageGrounding with Google Search saat ini tidak mendukung penggunaan gambar orang dari dunia nyata dari penelusuran web.- Semua gambar yang dihasilkan menyertakan watermark SynthID.
Konfigurasi opsional
Anda dapat secara opsional mengonfigurasi format output, rasio aspek, dan ukuran gambar menggunakan parameter response_format.
Format output
Model secara default akan menampilkan respons teks dan gambar. Anda dapat mengonfigurasi respons agar hanya menampilkan gambar yang dibuat (tidak menyertakan teks percakapan) dengan menentukan format gambar dalam parameter response_format.
Untuk meminta beberapa modalitas (misalnya, teks dan gambar yang dihasilkan), teruskan array entri format ke response_format.
Python
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Write a short poem about a starry night and generate an image of it.",
response_format=[
{"type": "text"},
{"type": "image"},
],
)
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Write a short poem about a starry night and generate an image of it.",
response_format: [
{ type: "text" },
{ type: "image" },
],
});
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Write a short poem about a starry night and generate an image of it.",
"response_format": [
{ "type": "text" },
{ "type": "image" }
]
}'
Rasio aspek dan ukuran gambar
Secara default, model mencocokkan ukuran gambar output dengan ukuran gambar input Anda, atau menghasilkan persegi 1:1. Anda dapat mengontrol rasio aspek dan ukuran gambar output menggunakan kolom aspect_ratio dan image_size di bagian response_format saat type disetel ke "image".
Python
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=prompt,
response_format={
"type": "image",
"aspect_ratio": "16:9",
"image_size": "2K",
},
)
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: prompt,
response_format: {
type: "image",
aspect_ratio: "16:9",
image_size: "2K",
},
});
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme",
"response_format": {
"type": "image",
"aspect_ratio": "16:9",
"image_size": "2K"
}
}'
Berbagai rasio yang tersedia dan ukuran gambar yang dihasilkan tercantum dalam tabel berikut:
3.1 Flash Image
| Rasio aspek | Resolusi 512 piksel | 0,5 ribu token | Resolusi 1K | 1.000 token | Resolusi 2K | 2 ribu token | Resolusi 4K | 4K token |
|---|---|---|---|---|---|---|---|---|
| 1:1 | 512x512 | 747 | 1024x1024 | 1120 | 2048x2048 | 1120 | 4096x4096 | 2000 |
| 1:4 | 256x1024 | 747 | 512x2048 | 1120 | 1024x4096 | 1120 | 2048x8192 | 2000 |
| 1:8 | 192x1536 | 747 | 384x3072 | 1120 | 768x6144 | 1120 | 1536x12288 | 2000 |
| 2:3 | 424x632 | 747 | 848x1264 | 1120 | 1696x2528 | 1120 | 3392x5056 | 2000 |
| 3:2 | 632x424 | 747 | 1264x848 | 1120 | 2528x1696 | 1120 | 5056x3392 | 2000 |
| 3:4 | 448x600 | 747 | 896x1200 | 1120 | 1792x2400 | 1120 | 3584x4800 | 2000 |
| 4:1 | 1024x256 | 747 | 2048x512 | 1120 | 4096x1024 | 1120 | 8192x2048 | 2000 |
| 4:3 | 600x448 | 747 | 1200x896 | 1120 | 2400x1792 | 1120 | 4800x3584 | 2000 |
| 4:5 | 464x576 | 747 | 928x1152 | 1120 | 1856x2304 | 1120 | 3712x4608 | 2000 |
| 5:4 | 576x464 | 747 | 1152x928 | 1120 | 2304x1856 | 1120 | 4608x3712 | 2000 |
| 8:1 | 1536x192 | 747 | 3072x384 | 1120 | 6144x768 | 1120 | 12288x1536 | 2000 |
| 9:16 | 384x688 | 747 | 768x1376 | 1120 | 1536x2752 | 1120 | 3072x5504 | 2000 |
| 16:9 | 688x384 | 747 | 1376x768 | 1120 | 2752x1536 | 1120 | 5504x3072 | 2000 |
| 21:9 | 792x168 | 747 | 1584x672 | 1120 | 3168x1344 | 1120 | 6336x2688 | 2000 |
3.1 Pro Image
| Rasio aspek | Resolusi 1K | 1.000 token | Resolusi 2K | 2 ribu token | Resolusi 4K | 4K token |
|---|---|---|---|---|---|---|
| 1:1 | 1024x1024 | 1120 | 2048x2048 | 1120 | 4096x4096 | 2000 |
| 2:3 | 848x1264 | 1120 | 1696x2528 | 1120 | 3392x5056 | 2000 |
| 3:2 | 1264x848 | 1120 | 2528x1696 | 1120 | 5056x3392 | 2000 |
| 3:4 | 896x1200 | 1120 | 1792x2400 | 1120 | 3584x4800 | 2000 |
| 4:3 | 1200x896 | 1120 | 2400x1792 | 1120 | 4800x3584 | 2000 |
| 4:5 | 928x1152 | 1120 | 1856x2304 | 1120 | 3712x4608 | 2000 |
| 5:4 | 1152x928 | 1120 | 2304x1856 | 1120 | 4608x3712 | 2000 |
| 9:16 | 768x1376 | 1120 | 1536x2752 | 1120 | 3072x5504 | 2000 |
| 16:9 | 1376x768 | 1120 | 2752x1536 | 1120 | 5504x3072 | 2000 |
| 21:9 | 1584x672 | 1120 | 3168x1344 | 1120 | 6336x2688 | 2000 |
Gambar Gemini 2.5 Flash
| Rasio aspek | Resolusi | Token |
|---|---|---|
| 1:1 | 1024x1024 | 1290 |
| 2:3 | 832x1248 | 1290 |
| 3:2 | 1248x832 | 1290 |
| 3:4 | 864x1184 | 1290 |
| 4:3 | 1184x864 | 1290 |
| 4:5 | 896x1152 | 1290 |
| 5:4 | 1152x896 | 1290 |
| 9:16 | 768x1344 | 1290 |
| 16:9 | 1344x768 | 1290 |
| 21:9 | 1536x672 | 1290 |
Pemilihan model
Pilih model yang paling sesuai untuk kasus penggunaan spesifik Anda.
Gemini 3.1 Flash Image (Nano Banana 2) harus menjadi model pembuatan gambar pilihan Anda, karena model ini memiliki performa dan kecerdasan terbaik secara keseluruhan dengan keseimbangan biaya dan latensi yang optimal. Lihat halaman harga dan kemampuan model untuk mengetahui detail selengkapnya.
Gemini 3.1 Flash Lite Image (Nano Banana Lite) adalah model paling efisien dalam keluarga pembuatan gambar, yang menawarkan latensi ultra-rendah serta pembuatan dan pengeditan gambar yang hemat biaya. Lihat halaman harga dan kemampuan model untuk mengetahui detail selengkapnya.
Gambar Gemini 3 Pro (Nano Banana Pro) dirancang untuk produksi aset profesional dan perintah yang kompleks. Model ini memiliki pengaitan dunia nyata menggunakan Google Penelusuran, proses "Berpikir" default yang memperbaiki komposisi sebelum pembuatan, dan dapat menghasilkan gambar dengan resolusi hingga 4K. Lihat halaman harga dan kemampuan model untuk mengetahui detail selengkapnya.
Gemini 2.5 Flash Image (Nano Banana) dirancang untuk kecepatan dan efisiensi. Model ini dioptimalkan untuk tugas bervolume tinggi dan latensi rendah serta membuat gambar dengan resolusi 1024 piksel. Lihat halaman harga dan kemampuan model untuk mengetahui detail selengkapnya.
Kapan menggunakan Imagen
Selain menggunakan kemampuan pembuatan gambar bawaan Gemini, Anda juga dapat mengakses Imagen, model pembuatan gambar khusus kami, melalui Gemini API. Rencanakan migrasi sebelum tanggal penutupan.
Langkah berikutnya
- Lihat panduan Veo untuk mempelajari cara membuat video dengan Gemini API.
- Untuk mempelajari model Gemini lebih lanjut, lihat Model Gemini.