Tạo hình ảnh bằng Nano Banana
- Dùng thử ứng dụng Nano Banana 2
- Hoặc tạo hình ảnh của riêng bạn từ câu lệnh:
-








-
Do Nano Banana 2 tạo Câu lệnh: "Ảnh chụp một trang bìa tạp chí bóng bẩy, trang bìa màu xanh dương tối giản có dòng chữ Nano Banana lớn in đậm. Văn bản có phông chữ có chân và lấp đầy khung hiển thị. Không có văn bản nào khác. Phía trước văn bản là ảnh chân dung một người mặc chiếc váy thanh lịch và tối giản. Cô bé đang cầm số 2 một cách tinh nghịch, đây là tâm điểm của bức ảnh.
Đặt số phát hành và ngày "tháng 2 năm 2026" ở góc cùng với mã vạch. Tạp chí này nằm trên một chiếc kệ dựa vào bức tường trát vữa màu cam, bên trong một cửa hàng của nhà thiết kế.Tạo ảnh chụp sản phẩm chuyên nghiệp trong AI Studio -
Do Nano Banana Pro tạo Câu lệnh: "Tạo một cảnh hoạt hình 3D thu nhỏ, rõ nét, đẳng cự, góc nhìn 45° từ trên xuống về London, có các địa danh và yếu tố kiến trúc tiêu biểu nhất. Sử dụng các hoạ tiết tinh tế, mềm mại với chất liệu PBR chân thực, ánh sáng và bóng đổ nhẹ nhàng, sống động. Tích hợp điều kiện thời tiết hiện tại trực tiếp vào môi trường thành phố để tạo ra một bầu không khí sống động. Sử dụng bố cục tối giản, gọn gàng với nền có màu đồng nhất và dịu nhẹ. Ở trên cùng và ở giữa, hãy đặt tiêu đề "London" bằng văn bản in đậm cỡ lớn, một biểu tượng thời tiết nổi bật bên dưới, sau đó là ngày (chữ nhỏ) và nhiệt độ (chữ cỡ trung). Tất cả văn bản phải được căn giữa với khoảng cách nhất quán và có thể hơi chồng lên phần trên của các toà nhà."Tìm hiểu thêm về tính năng căn cứ vào thông tin tìm kiếm và dùng thử tính năng này trong AI Studio -
Do Nano Banana 2 tạo Câu lệnh: "Sử dụng tính năng tìm kiếm hình ảnh để tìm hình ảnh chính xác về chim đuôi chuông rực rỡ. Tạo một hình nền 3:2 đẹp mắt về loài chim này, có hiệu ứng chuyển màu tự nhiên từ trên xuống dưới và bố cục tối giản.Sử dụng tính năng Tìm kiếm hình ảnh trên Google cùng với Nano Banana 2. Dùng thử trong AI Studio -

Do Nano Banana Pro tạo Câu lệnh: "Đặt biểu trưng này lên một quảng cáo cao cấp cho nước hoa có mùi chuối. Biểu trưng này được tích hợp hoàn hảo vào chai."Dùng thử tính năng giữ lại chi tiết có độ trung thực cao của Nano Banana trong AI Studio -
Do Nano Banana Pro tạo Câu lệnh: "Một bức ảnh chụp cảnh sinh hoạt thường ngày tại một quán cà phê đông đúc phục vụ bữa sáng. Ở tiền cảnh là một người đàn ông trong phim hoạt hình có mái tóc màu xanh dương, một trong số những người này là bản phác thảo bằng bút chì, người còn lại là nhân vật hoạt hình bằng đất sétThử nghiệm nhiều phong cách nghệ thuật bằng Nano Banana trong AI Studio -
Do Nano Banana Pro tạo Câu lệnh: "Tìm thông tin về phản ứng của mọi người đối với việc ra mắt Gemini 3 Flash. Hãy dùng thông tin này để viết một bài viết ngắn về chủ đề đó (có tiêu đề). Trả về ảnh của bài viết như ảnh xuất hiện trong một tạp chí bóng bẩy tập trung vào thiết kế. Đây là ảnh chụp một trang giấy được gấp lại, cho thấy bài viết về Gemini 3 Flash. Một ảnh chính. Dòng tiêu đề có chân." -
Do Nano Banana Pro tạo Câu lệnh: "Một biểu tượng đại diện cho một chú chó dễ thương. Nền có màu trắng. Tạo các biểu tượng theo phong cách 3D nhiều màu sắc và có kết cấu. Không có văn bản."Tạo biểu tượng, hình dán và thành phần bằng Nano Banana trong AI Studio -
Do Nano Banana 2 tạo Câu lệnh: "Tạo một bức ảnh có góc nhìn hoàn toàn đẳng cự. Đây không phải là một mô hình thu nhỏ mà là một bức ảnh chụp được và tình cờ có góc nhìn hoàn toàn đẳng cự. Đây là bức ảnh về một khu vườn hiện đại tuyệt đẹp. Có một bể bơi lớn có hình số 2 và dòng chữ: Nano Banana 2."Thử tạo hình ảnh siêu thực trong AI Studio
Nano Banana là tên gọi của các tính năng tạo hình ảnh gốc của Gemini. Gemini có thể tạo và xử lý hình ảnh theo cách đàm thoại bằng văn bản, hình ảnh hoặc kết hợp cả hai. Điều này giúp bạn tạo, chỉnh sửa và lặp lại các hình ảnh với khả năng kiểm soát chưa từng có.
Nano Banana đề cập đến 3 mô hình riêng biệt có trong Gemini API:
- Nano Banana 2: Mô hình Gemini 3.1 Flash Image Preview (
gemini-3.1-flash-image-preview). Mô hình này đóng vai trò là phiên bản hiệu suất cao của Gemini 3 Pro Image, được tối ưu hoá cho tốc độ và các trường hợp sử dụng của nhà phát triển với khối lượng lớn. - Nano Banana Pro: Mô hình Gemini 3 Pro Image Preview (
gemini-3-pro-image-preview). Mô hình này được thiết kế để tạo tài sản chuyên nghiệp, sử dụng khả năng suy luận nâng cao ("Tư duy") để làm theo các chỉ dẫn phức tạp và hiển thị văn bản có độ trung thực cao. - Nano Banana: Mô hình Gemini 2.5 Flash Image (
gemini-2.5-flash-image). Mô hình này được thiết kế để có tốc độ và hiệu suất cao, đồng thời được tối ưu hoá cho các tác vụ có khối lượng lớn và độ trễ thấp.
Tất cả hình ảnh được tạo đều có hình mờ SynthID.
Tạo hình ảnh (chuyển văn bản thành hình ảnh)
Python
from google import genai
from google.genai import types
from PIL import Image
client = genai.Client()
prompt = ("Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme")
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[prompt],
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save("generated_image.png")
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const prompt =
"Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme";
const response = await ai.models.generateContent({
model: "gemini-3.1-flash-image-preview",
contents: prompt,
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("gemini-native-image.png", buffer);
console.log("Image saved as gemini-native-image.png");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-3.1-flash-image-preview",
genai.Text("Create a picture of a nano banana dish in a " +
" fancy restaurant with a Gemini theme"),
)
for _, part := range result.Candidates[0].Content.Parts {
if part.Text != "" {
fmt.Println(part.Text)
} else if part.InlineData != nil {
imageBytes := part.InlineData.Data
outputFilename := "gemini_generated_image.png"
_ = os.WriteFile(outputFilename, imageBytes, 0644)
}
}
}
Java
import com.google.genai.Client;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.Part;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class TextToImage {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-3.1-flash-image-preview",
"Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme",
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("_01_generated_image.png"), blob.data().get());
}
}
}
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{
"parts": [
{"text": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme"}
]
}]
}'
Chỉnh sửa hình ảnh (chuyển văn bản và hình ảnh thành hình ảnh)
Lời nhắc: Hãy đảm bảo rằng bạn có các quyền cần thiết đối với mọi hình ảnh mà bạn tải lên. Bạn không được tạo nội dung vi phạm quyền của người khác, kể cả video hoặc hình ảnh lừa gạt, quấy rối hoặc gây hại. Khi sử dụng dịch vụ AI tạo sinh này, bạn phải tuân theo Chính sách về các hành vi bị cấm khi sử dụng của chúng tôi.
Cung cấp hình ảnh và sử dụng câu lệnh dạng văn bản để thêm, xoá hoặc sửa đổi các phần tử, thay đổi kiểu hoặc điều chỉnh phân loại màu.
Ví dụ sau đây minh hoạ việc tải hình ảnh được mã hoá base64 lên.
Đối với nhiều hình ảnh, tải trọng lớn hơn và các loại MIME được hỗ trợ, hãy xem trang Hiểu hình ảnh.
Python
from google import genai
from google.genai import types
from PIL import Image
client = genai.Client()
prompt = (
"Create a picture of my cat eating a nano-banana in a "
"fancy restaurant under the Gemini constellation",
)
image = Image.open("/path/to/cat_image.png")
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[prompt, image],
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save("generated_image.png")
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "path/to/cat_image.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const prompt = [
{ text: "Create a picture of my cat eating a nano-banana in a" +
"fancy restaurant under the Gemini constellation" },
{
inlineData: {
mimeType: "image/png",
data: base64Image,
},
},
];
const response = await ai.models.generateContent({
model: "gemini-3.1-flash-image-preview",
contents: prompt,
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("gemini-native-image.png", buffer);
console.log("Image saved as gemini-native-image.png");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
imagePath := "/path/to/cat_image.png"
imgData, _ := os.ReadFile(imagePath)
parts := []*genai.Part{
genai.NewPartFromText("Create a picture of my cat eating a nano-banana in a fancy restaurant under the Gemini constellation"),
&genai.Part{
InlineData: &genai.Blob{
MIMEType: "image/png",
Data: imgData,
},
},
}
contents := []*genai.Content{
genai.NewContentFromParts(parts, genai.RoleUser),
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-3.1-flash-image-preview",
contents,
)
for _, part := range result.Candidates[0].Content.Parts {
if part.Text != "" {
fmt.Println(part.Text)
} else if part.InlineData != nil {
imageBytes := part.InlineData.Data
outputFilename := "gemini_generated_image.png"
_ = os.WriteFile(outputFilename, imageBytes, 0644)
}
}
}
Java
import com.google.genai.Client;
import com.google.genai.types.Content;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.Part;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
public class TextAndImageToImage {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-3.1-flash-image-preview",
Content.fromParts(
Part.fromText("""
Create a picture of my cat eating a nano-banana in
a fancy restaurant under the Gemini constellation
"""),
Part.fromBytes(
Files.readAllBytes(
Path.of("src/main/resources/cat.jpg")),
"image/jpeg")),
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("gemini_generated_image.png"), blob.data().get());
}
}
}
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"contents\": [{
\"parts\":[
{\"text\": \"'Create a picture of my cat eating a nano-banana in a fancy restaurant under the Gemini constellation\"},
{
\"inline_data\": {
\"mime_type\":\"image/jpeg\",
\"data\": \"<BASE64_IMAGE_DATA>\"
}
}
]
}]
}"
Chỉnh sửa hình ảnh nhiều lượt
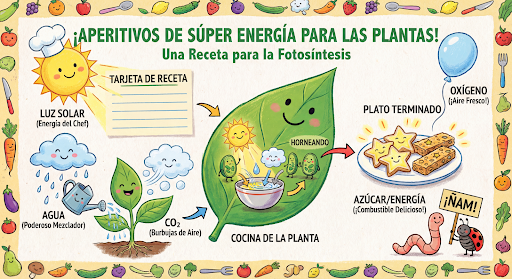
Tiếp tục tạo và chỉnh sửa hình ảnh theo cách trò chuyện. Trò chuyện hoặc trò chuyện nhiều lượt là cách nên dùng để lặp lại hình ảnh. Ví dụ sau đây cho thấy một câu lệnh để tạo bản đồ hoạ thông tin về quá trình quang hợp.
Python
from google import genai
from google.genai import types
client = genai.Client()
chat = client.chats.create(
model="gemini-3.1-flash-image-preview",
config=types.GenerateContentConfig(
response_modalities=['TEXT', 'IMAGE'],
tools=[{"google_search": {}}]
)
)
message = "Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plant's favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids' cookbook, suitable for a 4th grader."
response = chat.send_message(message)
for part in response.parts:
if part.text is not None:
print(part.text)
elif image:= part.as_image():
image.save("photosynthesis.png")
JavaScript
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({});
async function main() {
const chat = ai.chats.create({
model: "gemini-3.1-flash-image-preview",
config: {
responseModalities: ['TEXT', 'IMAGE'],
tools: [{googleSearch: {}}],
},
});
}
await main();
const message = "Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plant's favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids' cookbook, suitable for a 4th grader."
let response = await chat.sendMessage({message});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("photosynthesis.png", buffer);
console.log("Image saved as photosynthesis.png");
}
}
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
defer client.Close()
model := client.GenerativeModel("gemini-3.1-flash-image-preview")
model.GenerationConfig = &pb.GenerationConfig{
ResponseModalities: []pb.ResponseModality{genai.Text, genai.Image},
}
chat := model.StartChat()
message := "Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plant's favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids' cookbook, suitable for a 4th grader."
resp, err := chat.SendMessage(ctx, genai.Text(message))
if err != nil {
log.Fatal(err)
}
for _, part := range resp.Candidates[0].Content.Parts {
if txt, ok := part.(genai.Text); ok {
fmt.Printf("%s", string(txt))
} else if img, ok := part.(genai.ImageData); ok {
err := os.WriteFile("photosynthesis.png", img.Data, 0644)
if err != nil {
log.Fatal(err)
}
}
}
}
Java
import com.google.genai.Chat;
import com.google.genai.Client;
import com.google.genai.types.Content;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.GoogleSearch;
import com.google.genai.types.ImageConfig;
import com.google.genai.types.Part;
import com.google.genai.types.RetrievalConfig;
import com.google.genai.types.Tool;
import com.google.genai.types.ToolConfig;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
public class MultiturnImageEditing {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.tools(Tool.builder()
.googleSearch(GoogleSearch.builder().build())
.build())
.build();
Chat chat = client.chats.create("gemini-3.1-flash-image-preview", config);
GenerateContentResponse response = chat.sendMessage("""
Create a vibrant infographic that explains photosynthesis
as if it were a recipe for a plant's favorite food.
Show the "ingredients" (sunlight, water, CO2)
and the "finished dish" (sugar/energy).
The style should be like a page from a colorful
kids' cookbook, suitable for a 4th grader.
""");
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("photosynthesis.png"), blob.data().get());
}
}
}
// ...
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{
"role": "user",
"parts": [
{"text": "Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plants favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids cookbook, suitable for a 4th grader."}
]
}],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"]
}
}'

Sau đó, bạn có thể dùng cùng một cuộc trò chuyện để thay đổi ngôn ngữ trên hình ảnh thành tiếng Tây Ban Nha.
Python
message = "Update this infographic to be in Spanish. Do not change any other elements of the image."
aspect_ratio = "16:9" # "1:1","1:4","1:8","2:3","3:2","3:4","4:1","4:3","4:5","5:4","8:1","9:16","16:9","21:9"
resolution = "2K" # "512", "1K", "2K", "4K"
response = chat.send_message(message,
config=types.GenerateContentConfig(
response_format={"image": {aspect_ratio: aspect_ratio, image_size: resolution}},
))
for part in response.parts:
if part.text is not None:
print(part.text)
elif image:= part.as_image():
image.save("photosynthesis_spanish.png")
JavaScript
const message = 'Update this infographic to be in Spanish. Do not change any other elements of the image.';
const aspectRatio = '16:9';
const resolution = '2K';
let response = await chat.sendMessage({
message,
config: {
responseModalities: ['TEXT', 'IMAGE'],
responseFormat: {
image: {
aspectRatio: aspectRatio,
imageSize: resolution,
}
},
tools: [{googleSearch: {}}],
},
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("photosynthesis2.png", buffer);
console.log("Image saved as photosynthesis2.png");
}
}
Go
message = "Update this infographic to be in Spanish. Do not change any other elements of the image."
aspect_ratio = "16:9" // "1:1","1:4","1:8","2:3","3:2","3:4","4:1","4:3","4:5","5:4","8:1","9:16","16:9","21:9"
resolution = "2K" // "512", "1K", "2K", "4K"
model.GenerationConfig.ImageConfig = &pb.ImageConfig{
AspectRatio: aspect_ratio,
ImageSize: resolution,
}
resp, err = chat.SendMessage(ctx, genai.Text(message))
if err != nil {
log.Fatal(err)
}
for _, part := range resp.Candidates[0].Content.Parts {
if txt, ok := part.(genai.Text); ok {
fmt.Printf("%s", string(txt))
} else if img, ok := part.(genai.ImageData); ok {
err := os.WriteFile("photosynthesis_spanish.png", img.Data, 0644)
if err != nil {
log.Fatal(err)
}
}
}
Java
String aspectRatio = "16:9"; // "1:1","1:4","1:8","2:3","3:2","3:4","4:1","4:3","4:5","5:4","8:1","9:16","16:9","21:9"
String resolution = "2K"; // "512", "1K", "2K", "4K"
config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.imageConfig(ImageConfig.builder()
.aspectRatio(aspectRatio)
.imageSize(resolution)
.build())
.build();
response = chat.sendMessage(
"Update this infographic to be in Spanish. " +
"Do not change any other elements of the image.",
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("photosynthesis_spanish.png"), blob.data().get());
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"contents": [
{
"role": "user",
"parts": [{"text": "Create a vibrant infographic that explains photosynthesis..."}]
},
{
"role": "model",
"parts": [{"inline_data": {"mime_type": "image/png", "data": "<PREVIOUS_IMAGE_DATA>"}}]
},
{
"role": "user",
"parts": [{"text": "Update this infographic to be in Spanish. Do not change any other elements of the image."}]
}
],
"tools": [{"google_search": {}}],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"],
"responseFormat": {
"image": {
"aspectRatio": "16:9",
"imageSize": "2K"
}
}
}
}'
Tính năng mới với các mô hình Gemini 3 Image
Gemini 3 cung cấp các mô hình tạo và chỉnh sửa hình ảnh tiên tiến. Gemini 3.1 Flash Image được tối ưu hoá về tốc độ và các trường hợp sử dụng với khối lượng lớn, còn Gemini 3 Pro Image được tối ưu hoá cho việc sản xuất nội dung chuyên nghiệp. Được thiết kế để giải quyết những quy trình công việc khó khăn nhất thông qua khả năng suy luận nâng cao, các mô hình này có thể thực hiện xuất sắc những nhiệm vụ tạo và sửa đổi phức tạp, nhiều lượt.
- Đầu ra có độ phân giải cao: Khả năng tạo hình ảnh 1K, 2K và 4K được tích hợp sẵn.
- Hình ảnh Gemini 3.1 Flash có thêm độ phân giải 512 (0,5K) nhỏ hơn.
- Kết xuất văn bản nâng cao: Có khả năng tạo văn bản dễ đọc, cách điệu cho đồ hoạ thông tin, trình đơn, sơ đồ và thành phần tiếp thị.
- Bám sát nguồn bằng Google Tìm kiếm: Mô hình có thể sử dụng Google Tìm kiếm làm công cụ để xác minh thông tin và tạo hình ảnh dựa trên dữ liệu theo thời gian thực (ví dụ: bản đồ thời tiết hiện tại, biểu đồ cổ phiếu, các sự kiện gần đây).
- Hình ảnh Gemini 3.1 Flash bổ sung tính năng tích hợp Bám sát nguồn bằng Google Tìm kiếm cho Hình ảnh cùng với Tìm kiếm trên web.
- Chế độ Tư duy: Mô hình này sử dụng quy trình "tư duy" để suy luận thông qua các câu lệnh phức tạp. Công cụ này tạo ra "hình ảnh ý tưởng" tạm thời (có thể nhìn thấy ở phần phụ trợ nhưng không tính phí) để tinh chỉnh bố cục trước khi tạo ra thành phẩm chất lượng cao cuối cùng.
- Tối đa 14 hình ảnh tham khảo: Giờ đây, bạn có thể kết hợp tối đa 14 hình ảnh tham khảo để tạo ra hình ảnh cuối cùng.
- Tỷ lệ khung hình mới: Bản xem trước hình ảnh của Gemini 3.1 Flash bổ sung tỷ lệ khung hình 1:4, 4:1, 1:8 và 8:1.
Sử dụng tối đa 14 hình ảnh tham khảo
Các mô hình hình ảnh Gemini 3 cho phép bạn kết hợp tối đa 14 hình ảnh tham khảo. 14 hình ảnh này có thể bao gồm:
| Bản xem trước hình ảnh Gemini 3.1 Flash | Bản xem trước hình ảnh của Gemini 3 Pro |
|---|---|
| Tối đa 10 hình ảnh về các đối tượng có độ trung thực cao để đưa vào hình ảnh cuối cùng | Tối đa 6 hình ảnh về các đối tượng có độ trung thực cao để đưa vào hình ảnh cuối cùng |
| Tối đa 4 hình ảnh nhân vật để duy trì tính nhất quán của nhân vật | Tối đa 5 hình ảnh về nhân vật để duy trì tính nhất quán của nhân vật |
Python
from google import genai
from google.genai import types
from PIL import Image
prompt = "An office group photo of these people, they are making funny faces."
aspect_ratio = "5:4" # "1:1","1:4","1:8","2:3","3:2","3:4","4:1","4:3","4:5","5:4","8:1","9:16","16:9","21:9"
resolution = "2K" # "512", "1K", "2K", "4K"
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[
prompt,
Image.open('person1.png'),
Image.open('person2.png'),
Image.open('person3.png'),
Image.open('person4.png'),
Image.open('person5.png'),
],
config=types.GenerateContentConfig(
response_modalities=['TEXT', 'IMAGE'],
response_format={"image": {aspect_ratio: aspect_ratio, image_size: resolution}},
)
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif image:= part.as_image():
image.save("office.png")
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const prompt =
'An office group photo of these people, they are making funny faces.';
const aspectRatio = '5:4';
const resolution = '2K';
const contents = [
{ text: prompt },
{
inlineData: {
mimeType: "image/jpeg",
data: base64ImageFile1,
},
},
{
inlineData: {
mimeType: "image/jpeg",
data: base64ImageFile2,
},
},
{
inlineData: {
mimeType: "image/jpeg",
data: base64ImageFile3,
},
},
{
inlineData: {
mimeType: "image/jpeg",
data: base64ImageFile4,
},
},
{
inlineData: {
mimeType: "image/jpeg",
data: base64ImageFile5,
},
}
];
const response = await ai.models.generateContent({
model: 'gemini-3.1-flash-image-preview',
contents: contents,
config: {
responseModalities: ['TEXT', 'IMAGE'],
responseFormat: {
image: {
aspectRatio: aspectRatio,
imageSize: resolution,
}
},
},
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("image.png", buffer);
console.log("Image saved as image.png");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
defer client.Close()
model := client.GenerativeModel("gemini-3.1-flash-image-preview")
model.GenerationConfig = &pb.GenerationConfig{
ResponseModalities: []pb.ResponseModality{genai.Text, genai.Image},
ImageConfig: &pb.ImageConfig{
AspectRatio: "5:4",
ImageSize: "2K",
},
}
img1, err := os.ReadFile("person1.png")
if err != nil { log.Fatal(err) }
img2, err := os.ReadFile("person2.png")
if err != nil { log.Fatal(err) }
img3, err := os.ReadFile("person3.png")
if err != nil { log.Fatal(err) }
img4, err := os.ReadFile("person4.png")
if err != nil { log.Fatal(err) }
img5, err := os.ReadFile("person5.png")
if err != nil { log.Fatal(err) }
parts := []genai.Part{
genai.Text("An office group photo of these people, they are making funny faces."),
genai.ImageData{MIMEType: "image/png", Data: img1},
genai.ImageData{MIMEType: "image/png", Data: img2},
genai.ImageData{MIMEType: "image/png", Data: img3},
genai.ImageData{MIMEType: "image/png", Data: img4},
genai.ImageData{MIMEType: "image/png", Data: img5},
}
resp, err := model.GenerateContent(ctx, parts...)
if err != nil {
log.Fatal(err)
}
for _, part := range resp.Candidates[0].Content.Parts {
if txt, ok := part.(genai.Text); ok {
fmt.Printf("%s", string(txt))
} else if img, ok := part.(genai.ImageData); ok {
err := os.WriteFile("office.png", img.Data, 0644)
if err != nil {
log.Fatal(err)
}
}
}
}
Java
import com.google.genai.Client;
import com.google.genai.types.Content;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.ImageConfig;
import com.google.genai.types.Part;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
public class GroupPhoto {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.imageConfig(ImageConfig.builder()
.aspectRatio("5:4")
.imageSize("2K")
.build())
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-3.1-flash-image-preview",
Content.fromParts(
Part.fromText("An office group photo of these people, they are making funny faces."),
Part.fromBytes(Files.readAllBytes(Path.of("person1.png")), "image/png"),
Part.fromBytes(Files.readAllBytes(Path.of("person2.png")), "image/png"),
Part.fromBytes(Files.readAllBytes(Path.of("person3.png")), "image/png"),
Part.fromBytes(Files.readAllBytes(Path.of("person4.png")), "image/png"),
Part.fromBytes(Files.readAllBytes(Path.of("person5.png")), "image/png")
), config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("office.png"), blob.data().get());
}
}
}
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"contents\": [{
\"parts\":[
{\"text\": \"An office group photo of these people, they are making funny faces.\"},
{\"inline_data\": {\"mime_type\":\"image/png\", \"data\": \"<BASE64_DATA_IMG_1>\"}},
{\"inline_data\": {\"mime_type\":\"image/png\", \"data\": \"<BASE64_DATA_IMG_2>\"}},
{\"inline_data\": {\"mime_type\":\"image/png\", \"data\": \"<BASE64_DATA_IMG_3>\"}},
{\"inline_data\": {\"mime_type\":\"image/png\", \"data\": \"<BASE64_DATA_IMG_4>\"}},
{\"inline_data\": {\"mime_type\":\"image/png\", \"data\": \"<BASE64_DATA_IMG_5>\"}}
]
}],
\"generationConfig\": {
\"responseModalities\": [\"TEXT\", \"IMAGE\"],
\"responseFormat\": {
\"image\": {
\"aspectRatio\": \"5:4\",
\"imageSize\": \"2K\"
}
}
}
}"

Bám sát nguồn bằng Google Tìm kiếm
Sử dụng công cụ Google Tìm kiếm để tạo hình ảnh dựa trên thông tin theo thời gian thực, chẳng hạn như dự báo thời tiết, biểu đồ cổ phiếu hoặc sự kiện gần đây.
Xin lưu ý rằng khi sử dụng tính năng Bám sát nguồn bằng Google Tìm kiếm để tạo hình ảnh, kết quả tìm kiếm dựa trên hình ảnh sẽ không được truyền đến mô hình tạo và sẽ bị loại trừ khỏi câu trả lời (xem phần Bám sát nguồn bằng Google Tìm kiếm cho hình ảnh)
Python
from google import genai
prompt = "Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day"
aspect_ratio = "16:9" # "1:1","1:4","1:8","2:3","3:2","3:4","4:1","4:3","4:5","5:4","8:1","9:16","16:9","21:9"
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=prompt,
config=types.GenerateContentConfig(
response_modalities=['Text', 'Image'],
response_format={"image": {aspect_ratio: aspect_ratio,}},
tools=[{"google_search": {}}]
)
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif image:= part.as_image():
image.save("weather.png")
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const prompt = 'Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day';
const aspectRatio = '16:9';
const resolution = '2K';
const response = await ai.models.generateContent({
model: 'gemini-3.1-flash-image-preview',
contents: prompt,
config: {
responseModalities: ['TEXT', 'IMAGE'],
responseFormat: {
image: {
aspectRatio: aspectRatio,
imageSize: resolution,
}
},
tools: [{ googleSearch: {} }]
},
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("image.png", buffer);
console.log("Image saved as image.png");
}
}
}
main();
Java
import com.google.genai.Client;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.GoogleSearch;
import com.google.genai.types.ImageConfig;
import com.google.genai.types.Part;
import com.google.genai.types.Tool;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class SearchGrounding {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.imageConfig(ImageConfig.builder()
.aspectRatio("16:9")
.build())
.tools(Tool.builder()
.googleSearch(GoogleSearch.builder().build())
.build())
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-3.1-flash-image-preview", """
Visualize the current weather forecast for the next 5 days
in San Francisco as a clean, modern weather chart.
Add a visual on what I should wear each day
""",
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("weather.png"), blob.data().get());
}
}
}
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{"parts": [{"text": "Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day"}]}],
"tools": [{"google_search": {}}],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"],
"responseFormat": {
"image": {"aspectRatio": "16:9"}
}
}
}'

Phản hồi này bao gồm groundingMetadata chứa các trường bắt buộc sau:
searchEntryPoint: Chứa HTML và CSS để hiển thị các đề xuất tìm kiếm bắt buộc.groundingChunks: Trả về 3 nguồn hàng đầu trên web được dùng để làm cơ sở cho hình ảnh được tạo
Bám sát nguồn bằng Google Tìm kiếm hình ảnh (3.1 Flash)
Tính năng Bám sát nguồn bằng Google Tìm kiếm cho hình ảnh cho phép các mô hình sử dụng hình ảnh trên web được truy xuất thông qua Google Tìm kiếm làm bối cảnh trực quan để tạo hình ảnh. Tìm kiếm hình ảnh là một loại tìm kiếm mới trong công cụ Bám sát nguồn bằng Google Tìm kiếm hiện có, hoạt động cùng với tính năng Tìm kiếm trên web tiêu chuẩn.
Để bật tính năng Tìm kiếm bằng hình ảnh, hãy định cấu hình công cụ googleSearch trong yêu cầu API của bạn và chỉ định imageSearch trong đối tượng searchTypes. Bạn có thể sử dụng tính năng Tìm kiếm hình ảnh độc lập hoặc cùng với tính năng Tìm kiếm trên web.
Xin lưu ý rằng bạn không thể dùng tính năng Bám sát nguồn bằng Google Tìm kiếm cho hình ảnh để tìm kiếm người.
Python
from google import genai
prompt = "A detailed painting of a Timareta butterfly resting on a flower"
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=prompt,
config=types.GenerateContentConfig(
response_modalities=["IMAGE"],
tools=[
types.Tool(google_search=types.GoogleSearch(
search_types=types.SearchTypes(
web_search=types.WebSearch(),
image_search=types.ImageSearch()
)
))
]
)
)
# Display grounding sources if available
if response.candidates and response.candidates[0].grounding_metadata and response.candidates[0].grounding_metadata.search_entry_point:
display(HTML(response.candidates[0].grounding_metadata.search_entry_point.rendered_content))
JavaScript
import { GoogleGenAI } from "@google/genai";
async function main() {
const ai = new GoogleGenAI({});
const prompt = "A detailed painting of a Timareta butterfly resting on a flower";
const response = await ai.models.generateContent({
model: "gemini-3.1-flash-image-preview",
contents: prompt,
config: {
responseModalities: ["IMAGE"],
tools: [
{
googleSearch: {
searchTypes: {
webSearch: {},
imageSearch: {}
}
}
}
]
}
});
// Display grounding sources if available
if (response.candidates && response.candidates[0].groundingMetadata && response.candidates[0].groundingMetadata.searchEntryPoint) {
console.log(response.candidates[0].groundingMetadata.searchEntryPoint.renderedContent);
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"google.golang.org/genai"
pb "google.golang.org/genai/schema"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
defer client.Close()
model := client.GenerativeModel("gemini-3.1-flash-image-preview")
model.Tools = []*pb.Tool{
{
GoogleSearch: &pb.GoogleSearch{
SearchTypes: &pb.SearchTypes{
WebSearch: &pb.WebSearch{},
ImageSearch: &pb.ImageSearch{},
},
},
},
}
model.GenerationConfig = &pb.GenerationConfig{
ResponseModalities: []pb.ResponseModality{genai.Image},
}
prompt := "A detailed painting of a Timareta butterfly resting on a flower"
resp, err := model.GenerateContent(ctx, genai.Text(prompt))
if err != nil {
log.Fatal(err)
}
if resp.Candidates[0].GroundingMetadata != nil && resp.Candidates[0].GroundingMetadata.SearchEntryPoint != nil {
fmt.Println(resp.Candidates[0].GroundingMetadata.SearchEntryPoint.RenderedContent)
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{"parts": [{"text": "A detailed painting of a Timareta butterfly resting on a flower"}]}],
"tools": [{"google_search": {"searchTypes": {"webSearch": {}, "imageSearch": {}}}}],
"generationConfig": {
"responseModalities": ["IMAGE"]
}
}'
Yêu cầu về việc hiển thị
Khi sử dụng tính năng Tìm kiếm bằng hình ảnh trong tính năng Bám sát nguồn bằng Google Tìm kiếm, bạn phải tuân thủ các điều kiện sau:
- Ghi nhận nguồn: Bạn phải cung cấp một đường liên kết đến trang web chứa hình ảnh nguồn (trang "chứa" chứ không phải tệp hình ảnh) theo cách mà người dùng sẽ nhận ra đó là một đường liên kết.
- Điều hướng trực tiếp: Nếu chọn hiển thị hình ảnh nguồn, bạn phải cung cấp một đường dẫn trực tiếp, chỉ cần nhấp một lần từ hình ảnh nguồn đến trang web nguồn chứa hình ảnh đó. Bạn không được phép triển khai bất kỳ phương thức nào khác làm chậm hoặc che giấu quyền truy cập của người dùng cuối vào trang web nguồn, bao gồm nhưng không giới hạn ở bất kỳ đường dẫn nhiều lượt nhấp nào hoặc việc sử dụng trình xem hình ảnh trung gian.
Đáp
Đối với các câu trả lời có căn cứ sử dụng tính năng tìm kiếm hình ảnh, API cung cấp thông tin ghi nhận quyền tác giả và siêu dữ liệu rõ ràng để liên kết đầu ra của API với các nguồn đã xác minh. Các trường khoá trong đối tượng groundingMetadata bao gồm:
imageSearchQueries: Các cụm từ tìm kiếm cụ thể mà mô hình sử dụng cho ngữ cảnh trực quan (tìm kiếm hình ảnh).groundingChunks: Chứa thông tin nguồn cho các kết quả đã truy xuất. Đối với các nguồn hình ảnh, những nguồn này sẽ được trả về dưới dạng URL chuyển hướng bằng cách sử dụng một loại đoạn hình ảnh mới. Khối này bao gồm:uri: URL của trang web để phân bổ (trang đích).image_uri: URL trực tiếp của hình ảnh.
groundingSupports: Cung cấp các mối liên kết cụ thể để liên kết nội dung được tạo với nguồn trích dẫn có liên quan trong các đoạn.searchEntryPoint: Bao gồm chip "Google Tìm kiếm" có chứa HTML và CSS tuân thủ để hiển thị Đề xuất tìm kiếm.
Tạo hình ảnh có độ phân giải lên đến 4K
Các mô hình hình ảnh Gemini 3 tạo ra 1.000 hình ảnh theo mặc định nhưng cũng có thể xuất ra hình ảnh 2K, 4K và 512 (0, 5K) (chỉ Gemini 3.1 Flash Image). Để tạo thành phần có độ phân giải cao hơn, hãy chỉ định image_size trong generation_config.
Bạn phải sử dụng chữ "K" viết hoa (ví dụ: 1K, 2K, 4K). Giá trị 512 không sử dụng hậu tố "K". Các thông số viết thường (ví dụ: 1k) sẽ bị từ chối.
Python
from google import genai
from google.genai import types
prompt = "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English."
aspect_ratio = "1:1" # "1:1","1:4","1:8","2:3","3:2","3:4","4:1","4:3","4:5","5:4","8:1","9:16","16:9","21:9"
resolution = "1K" # "512", "1K", "2K", "4K"
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=prompt,
config=types.GenerateContentConfig(
response_modalities=['TEXT', 'IMAGE'],
response_format={"image": {aspect_ratio: aspect_ratio, image_size: resolution}},
)
)
for part in response.parts:
if part.text is not None:
print(part.text)
elif image:= part.as_image():
image.save("butterfly.png")
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const prompt =
'Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English.';
const aspectRatio = '1:1';
const resolution = '1K';
const response = await ai.models.generateContent({
model: 'gemini-3.1-flash-image-preview',
contents: prompt,
config: {
responseModalities: ['TEXT', 'IMAGE'],
responseFormat: {
image: {
aspectRatio: aspectRatio,
imageSize: resolution,
}
},
},
});
for (const part of response.candidates[0].content.parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("image.png", buffer);
console.log("Image saved as image.png");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
defer client.Close()
model := client.GenerativeModel("gemini-3.1-flash-image-preview")
model.GenerationConfig = &pb.GenerationConfig{
ResponseModalities: []pb.ResponseModality{genai.Text, genai.Image},
ImageConfig: &pb.ImageConfig{
AspectRatio: "1:1",
ImageSize: "1K",
},
}
prompt := "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English."
resp, err := model.GenerateContent(ctx, genai.Text(prompt))
if err != nil {
log.Fatal(err)
}
for _, part := range resp.Candidates[0].Content.Parts {
if txt, ok := part.(genai.Text); ok {
fmt.Printf("%s", string(txt))
} else if img, ok := part.(genai.ImageData); ok {
err := os.WriteFile("butterfly.png", img.Data, 0644)
if err != nil {
log.Fatal(err)
}
}
}
}
Java
import com.google.genai.Client;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.GenerateContentResponse;
import com.google.genai.types.GoogleSearch;
import com.google.genai.types.ImageConfig;
import com.google.genai.types.Part;
import com.google.genai.types.Tool;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class HiRes {
public static void main(String[] args) throws IOException {
try (Client client = new Client()) {
GenerateContentConfig config = GenerateContentConfig.builder()
.responseModalities("TEXT", "IMAGE")
.imageConfig(ImageConfig.builder()
.aspectRatio("16:9")
.imageSize("4K")
.build())
.build();
GenerateContentResponse response = client.models.generateContent(
"gemini-3.1-flash-image-preview", """
Da Vinci style anatomical sketch of a dissected Monarch butterfly.
Detailed drawings of the head, wings, and legs on textured
parchment with notes in English.
""",
config);
for (Part part : response.parts()) {
if (part.text().isPresent()) {
System.out.println(part.text().get());
} else if (part.inlineData().isPresent()) {
var blob = part.inlineData().get();
if (blob.data().isPresent()) {
Files.write(Paths.get("butterfly.png"), blob.data().get());
}
}
}
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{"parts": [{"text": "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English."}]}],
"tools": [{"google_search": {}}],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"],
"responseFormat": {
"image": {"aspectRatio": "1:1", "imageSize": "1K"}
}
}
}'
Sau đây là một ví dụ về hình ảnh được tạo từ câu lệnh này:

Quá trình tư duy
Mô hình hình ảnh Gemini 3 là mô hình tư duy sử dụng quy trình suy luận ("Tư duy") cho các câu lệnh phức tạp. Tính năng này được bật theo mặc định và không thể tắt trong API. Để tìm hiểu thêm về quy trình suy nghĩ, hãy xem hướng dẫn Quy trình suy nghĩ của Gemini.
Mô hình này tạo tối đa 2 hình ảnh tạm thời để kiểm thử bố cục và logic. Hình ảnh cuối cùng trong phần Suy nghĩ cũng là hình ảnh được kết xuất cuối cùng.
Bạn có thể xem những suy nghĩ dẫn đến việc tạo ra hình ảnh cuối cùng.
Python
for part in response.parts:
if part.thought:
if part.text:
print(part.text)
elif image:= part.as_image():
image.show()
JavaScript
for (const part of response.candidates[0].content.parts) {
if (part.thought) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, 'base64');
fs.writeFileSync('image.png', buffer);
console.log('Image saved as image.png');
}
}
}
Kiểm soát các cấp độ tư duy
Với Gemini 3.1 Flash Image, bạn có thể kiểm soát mức độ tư duy mà mô hình sử dụng để cân bằng chất lượng và độ trễ. thinkingLevel mặc định là minimal và các cấp độ được hỗ trợ là minimal và high. Việc đặt thinkingLevel thành minimal sẽ mang lại các phản hồi có độ trễ thấp nhất. Xin lưu ý rằng tư duy tối thiểu không có nghĩa là mô hình hoàn toàn không sử dụng tư duy.
Bạn có thể thêm giá trị boolean includeThoughts để xác định xem suy nghĩ được tạo của mô hình có được trả về trong phản hồi hay vẫn bị ẩn.
Python
from google import genai
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents="A futuristic city built inside a giant glass bottle floating in space",
config=types.GenerateContentConfig(
response_modalities=["IMAGE"],
thinking_config=types.ThinkingConfig(
thinking_level="High",
include_thoughts=True
),
)
)
for part in response.parts:
if part.thought: # Skip outputting thoughts
continue
if part.text:
display(Markdown(part.text))
elif image:= part.as_image():
image.show()
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const response = await ai.models.generateContent({
model: "gemini-3.1-flash-image-preview",
contents: "A futuristic city built inside a giant glass bottle floating in space",
config: {
responseModalities: ["IMAGE"],
thinkingConfig: {
thinkingLevel: "High",
includeThoughts: true
},
},
});
for (const part of response.candidates[0].content.parts) {
if (part.thought) { // Skip outputting thoughts
continue;
}
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
const imageData = part.inlineData.data;
const buffer = Buffer.from(imageData, "base64");
fs.writeFileSync("image.png", buffer);
console.log("Image saved as image.png");
}
}
}
main();
Go
package main
import (
"context"
"fmt"
"log"
"os"
"google.golang.org/genai"
pb "google.golang.org/genai/schema"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
defer client.Close()
model := client.GenerativeModel("gemini-3.1-flash-image-preview")
model.GenerationConfig = &pb.GenerationConfig{
ResponseModalities: []pb.ResponseModality{genai.Image},
ThinkingConfig: &pb.ThinkingConfig{
ThinkingLevel: "High",
IncludeThoughts: true,
},
}
prompt := "A futuristic city built inside a giant glass bottle floating in space"
resp, err := model.GenerateContent(ctx, genai.Text(prompt))
if err != nil {
log.Fatal(err)
}
for _, part := range resp.Candidates[0].Content.Parts {
if part.Thought { // Skip outputting thoughts
continue
}
if txt, ok := part.(genai.Text); ok {
fmt.Printf("%s", string(txt))
} else if img, ok := part.(genai.ImageData); ok {
err := os.WriteFile("image.png", img.Data, 0644)
if err != nil {
log.Fatal(err)
}
}
}
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{"parts": [{"text": "A futuristic city built inside a giant glass bottle floating in space"}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"thinkingConfig": {
"thinkingLevel": "High",
"includeThoughts": true
}
}
}'
Xin lưu ý rằng các token tư duy sẽ được tính phí bất kể includeThoughts được đặt thành true hay false, vì quy trình tư duy luôn diễn ra theo mặc định cho dù bạn có xem quy trình đó hay không.
Chữ ký suy nghĩ
Chữ ký suy nghĩ là biểu diễn được mã hoá của quy trình suy nghĩ nội bộ của mô hình và được dùng để duy trì bối cảnh suy luận trong các lượt tương tác nhiều lượt. Tất cả các phản hồi đều có trường thought_signature. Theo nguyên tắc chung, nếu nhận được chữ ký suy nghĩ trong phản hồi của mô hình, bạn nên truyền lại chính xác chữ ký đó như khi nhận được khi gửi nhật ký trò chuyện ở lượt tiếp theo. Nếu không truyền tải được chữ ký suy nghĩ, thì có thể phản hồi sẽ không thành công. Hãy xem tài liệu về chữ ký ý tưởng để biết thêm thông tin giải thích về chữ ký nói chung.
Sau đây là cách hoạt động của chữ ký tư duy:
- Tất cả các phần
inline_datacó hình ảnhmimetypenằm trong phản hồi đều phải có chữ ký. - Nếu có một số phần văn bản ở đầu (trước bất kỳ hình ảnh nào) ngay sau phần suy nghĩ, thì phần văn bản đầu tiên cũng phải có chữ ký.
- Nếu
inline_datacác phần có hình ảnhmimetypelà một phần của suy nghĩ, thì chúng sẽ không có chữ ký.
Đoạn mã sau đây cho thấy ví dụ về vị trí có chữ ký suy nghĩ:
[
{
"inline_data": {
"data": "<base64_image_data_0>",
"mime_type": "image/png"
},
"thought": true // Thoughts don't have signatures
},
{
"inline_data": {
"data": "<base64_image_data_1>",
"mime_type": "image/png"
},
"thought": true // Thoughts don't have signatures
},
{
"inline_data": {
"data": "<base64_image_data_2>",
"mime_type": "image/png"
},
"thought": true // Thoughts don't have signatures
},
{
"text": "Here is a step-by-step guide to baking macarons, presented in three separate images.\n\n### Step 1: Piping the Batter\n\nThe first step after making your macaron batter is to pipe it onto a baking sheet. This requires a steady hand to create uniform circles.\n\n",
"thought_signature": "<Signature_A>" // The first non-thought part always has a signature
},
{
"inline_data": {
"data": "<base64_image_data_3>",
"mime_type": "image/png"
},
"thought_signature": "<Signature_B>" // All image parts have a signatures
},
{
"text": "\n\n### Step 2: Baking and Developing Feet\n\nOnce piped, the macarons are baked in the oven. A key sign of a successful bake is the development of \"feet\"—the ruffled edge at the base of each macaron shell.\n\n"
// Follow-up text parts don't have signatures
},
{
"inline_data": {
"data": "<base64_image_data_4>",
"mime_type": "image/png"
},
"thought_signature": "<Signature_C>" // All image parts have a signatures
},
{
"text": "\n\n### Step 3: Assembling the Macaron\n\nThe final step is to pair the cooled macaron shells by size and sandwich them together with your desired filling, creating the classic macaron dessert.\n\n"
},
{
"inline_data": {
"data": "<base64_image_data_5>",
"mime_type": "image/png"
},
"thought_signature": "<Signature_D>" // All image parts have a signatures
}
]
Các chế độ tạo hình ảnh khác
Gemini hỗ trợ các chế độ tương tác khác với hình ảnh dựa trên cấu trúc câu lệnh và ngữ cảnh, bao gồm:
- Văn bản thành hình ảnh và văn bản (xen kẽ): Tạo ra hình ảnh kèm theo văn bản liên quan.
- Ví dụ về câu lệnh: "Tạo một công thức minh hoạ cho món paella."
- (Các) hình ảnh và văn bản thành(các) hình ảnh và văn bản (xen kẽ): Sử dụng hình ảnh và văn bản đầu vào để tạo hình ảnh và văn bản mới có liên quan.
- Ví dụ về câu lệnh: (Với hình ảnh một căn phòng có đồ nội thất) "Những màu sắc nào khác của ghế sofa sẽ phù hợp với không gian của tôi? Bạn có thể cập nhật hình ảnh không?"
Tạo hàng loạt hình ảnh
Nếu cần tạo nhiều hình ảnh, bạn có thể sử dụng Batch API. Bạn sẽ nhận được hạn mức tốc độ cao hơn để đổi lấy thời gian xử lý lên đến 24 giờ.
Tham khảo Tài liệu về tính năng tạo hình ảnh bằng Batch API và sổ tay hướng dẫn để xem các ví dụ và mã về hình ảnh bằng Batch API.
Hướng dẫn và chiến lược đặt câu lệnh
Để nắm vững cách tạo hình ảnh, bạn cần bắt đầu bằng một nguyên tắc cơ bản:
Mô tả cảnh, đừng chỉ liệt kê từ khoá. Điểm mạnh cốt lõi của mô hình này là khả năng hiểu ngôn ngữ một cách sâu sắc. Một đoạn văn mô tả, tường thuật sẽ hầu như luôn tạo ra hình ảnh tốt hơn, mạch lạc hơn so với một danh sách các từ rời rạc.
Câu lệnh để tạo hình ảnh
Các chiến lược sau đây sẽ giúp bạn tạo câu lệnh hiệu quả để tạo ra chính xác những hình ảnh mà bạn đang tìm kiếm.
Nhiếp ảnh
Để có hình ảnh chân thực, hãy sử dụng các thuật ngữ nhiếp ảnh. Đề cập đến góc camera, loại ống kính, ánh sáng và các chi tiết nhỏ để hướng dẫn mô hình tạo ra kết quả chân thực.
| Câu lệnh | Nội dung tạo sinh |
|---|---|
| Ảnh chụp cận cảnh chân dung một nghệ nhân gốm Nhật Bản lớn tuổi với những nếp nhăn sâu do ánh nắng và nụ cười ấm áp, thấu hiểu. Ông đang cẩn thận kiểm tra một chiếc bát trà mới tráng men. Khung cảnh là xưởng mộc mộc mạc, tràn ngập ánh nắng của ông. Khung cảnh được chiếu sáng bằng ánh sáng dịu nhẹ của giờ vàng, chiếu qua một ô cửa sổ, làm nổi bật kết cấu mịn của đất sét. Chụp bằng ống kính chân dung 85mm, tạo ra một phông nền mềm mại, mờ ảo (bokeh). Tâm trạng tổng thể là thanh bình và điêu luyện. Hướng dọc. |

|
Hình minh hoạ và hình dán cách điệu
Để tạo hình dán, biểu tượng hoặc thành phần, hãy nêu rõ kiểu và yêu cầu nền trắng.
| Câu lệnh | Nội dung tạo sinh |
|---|---|
| Hình dán theo phong cách kawaii về một chú gấu trúc đỏ vui vẻ đang đội một chiếc mũ tre nhỏ. Chú gấu trúc này đang nhai một chiếc lá tre xanh. Thiết kế này có đường viền rõ ràng, đậm nét, kỹ thuật đổ bóng đơn giản và bảng màu sống động. Nền phải có màu trắng. |

|
Văn bản chính xác trong hình ảnh
Gemini có khả năng kết xuất văn bản xuất sắc. Nêu rõ văn bản, kiểu phông chữ (mô tả) và thiết kế tổng thể. Sử dụng bản xem trước hình ảnh của Gemini 3 Pro để sản xuất tài sản chuyên nghiệp.
| Câu lệnh | Nội dung tạo sinh |
|---|---|
| Tạo một biểu trưng tối giản, hiện đại cho quán cà phê có tên "The Daily Grind". Văn bản phải sử dụng phông chữ sans-serif rõ ràng và in đậm. Bảng phối màu là đen và trắng. Đặt biểu trưng vào một vòng tròn. Sử dụng hạt cà phê một cách khéo léo. |
|
Bản mô phỏng sản phẩm và ảnh chụp thương mại
Phù hợp để tạo ảnh chụp sản phẩm chuyên nghiệp, rõ ràng cho thương mại điện tử, quảng cáo hoặc hoạt động xây dựng thương hiệu.
| Câu lệnh | Nội dung tạo sinh |
|---|---|
| Ảnh chụp sản phẩm có độ phân giải cao, được chụp trong phòng chụp ảnh và có ánh sáng chuyên nghiệp, cho thấy một chiếc cốc cà phê bằng gốm tối giản màu đen mờ, được đặt trên bề mặt bê tông đánh bóng. Ánh sáng được thiết lập bằng hộp hắt sáng ba điểm, được thiết kế để tạo ra những điểm sáng dịu nhẹ, khuếch tán và loại bỏ bóng đổ gắt. Góc máy là góc chụp 45 độ hơi cao để làm nổi bật các đường nét gọn gàng của sản phẩm. Siêu chân thực, với tiêu điểm rõ nét vào hơi nước bốc lên từ cà phê. Ảnh hình vuông. |

|
Thiết kế tối giản và không gian âm
Rất phù hợp để tạo nền cho trang web, bản trình bày hoặc tài liệu tiếp thị có văn bản được đặt lên trên.
| Câu lệnh | Nội dung tạo sinh |
|---|---|
| Một bố cục tối giản có một chiếc lá phong đỏ duy nhất, tinh tế nằm ở góc dưới bên phải khung hình. Nền là một canvas trống trải, rộng lớn có màu trắng nhạt, tạo ra khoảng trống đáng kể cho văn bản. Ánh sáng dịu nhẹ, khuếch tán từ phía trên bên trái. Ảnh hình vuông. |

|
Nghệ thuật tuần tự (Bảng truyện tranh / Bảng phân cảnh)
Dựa trên sự nhất quán của nhân vật và nội dung mô tả cảnh để tạo các khung hình cho việc kể chuyện bằng hình ảnh. Để đảm bảo độ chính xác về văn bản và khả năng kể chuyện, những câu lệnh này hoạt động hiệu quả nhất với Gemini 3 Pro và Gemini 3.1 Flash Image Preview.
| Câu lệnh | Nội dung tạo sinh |
|---|---|
|
Hình ảnh đầu vào: 
Câu lệnh: Tạo một truyện tranh gồm 3 khung theo phong cách nghệ thuật noir thô ráp bằng mực đen trắng có độ tương phản cao. Đặt nhân vật vào một cảnh hài hước. |

|
Bám sát nguồn bằng Google Tìm kiếm
Sử dụng Google Tìm kiếm để tạo hình ảnh dựa trên thông tin gần đây hoặc thông tin theo thời gian thực. Điều này rất hữu ích đối với tin tức, thông tin thời tiết và các chủ đề khác nhạy cảm về thời gian.
| Câu lệnh | Nội dung tạo sinh |
|---|---|
| Tạo một hình ảnh đơn giản nhưng phong cách về trận đấu tối qua của Arsenal tại giải Champions League |

|
Câu lệnh chỉnh sửa hình ảnh
Những ví dụ này cho thấy cách cung cấp hình ảnh cùng với câu lệnh dạng văn bản để chỉnh sửa, tạo bố cục và chuyển kiểu.
Thêm và xoá phần tử
Cung cấp một hình ảnh và mô tả thay đổi bạn muốn. Mô hình sẽ khớp với phong cách, ánh sáng và góc nhìn của hình ảnh gốc.
| Câu lệnh | Nội dung tạo sinh |
|---|---|
|
Hình ảnh đầu vào: 
Câu lệnh: Dựa vào hình ảnh chú mèo của tôi mà bạn cung cấp, vui lòng thêm một chiếc mũ phù thuỷ nhỏ bằng len trên đầu chú mèo. Hãy chỉnh sửa sao cho vật thể trông như đang nằm thoải mái và phù hợp với ánh sáng dịu nhẹ của bức ảnh. |

|
Chỉnh sửa cụ thể (Tạo mặt nạ ngữ nghĩa)
Xác định "mặt nạ" bằng cách trò chuyện để chỉnh sửa một phần cụ thể của hình ảnh mà không ảnh hưởng đến phần còn lại.
| Câu lệnh | Nội dung tạo sinh |
|---|---|
|
Hình ảnh đầu vào: 
Câu lệnh: Dựa vào hình ảnh phòng khách được cung cấp, hãy thay đổi chiếc ghế sofa màu xanh dương thành một chiếc ghế sofa Chesterfield bằng da màu nâu kiểu cổ điển. Giữ nguyên phần còn lại của căn phòng, bao gồm cả gối trên ghế sofa và ánh sáng. |

|
Chuyển đổi kiểu
Cung cấp một hình ảnh và yêu cầu mô hình tạo lại nội dung của hình ảnh đó theo một phong cách nghệ thuật khác.
| Câu lệnh | Nội dung tạo sinh |
|---|---|
|
Hình ảnh đầu vào: 
Câu lệnh: Biến bức ảnh được cung cấp về một đường phố hiện đại trong thành phố vào ban đêm thành phong cách nghệ thuật của bức tranh "Đêm đầy sao" của Vincent van Gogh. Giữ nguyên bố cục ban đầu của các toà nhà và ô tô, nhưng kết xuất tất cả các phần tử bằng những nét cọ xoáy, đắp nổi và bảng màu ấn tượng gồm màu xanh dương đậm và màu vàng tươi. |

|
Bố cục nâng cao: Kết hợp nhiều hình ảnh
Cung cấp nhiều hình ảnh làm bối cảnh để tạo một cảnh ghép mới. Đây là lựa chọn hoàn hảo cho bản mô phỏng sản phẩm hoặc ảnh ghép sáng tạo.
| Câu lệnh | Nội dung tạo sinh |
|---|---|
|
Hình ảnh đầu vào: 

Câu lệnh: Tạo một bức ảnh thời trang chuyên nghiệp cho thương mại điện tử. Lấy chiếc váy hoa màu xanh dương trong bức ảnh đầu tiên và mặc cho người phụ nữ trong bức ảnh thứ hai. Tạo một bức ảnh toàn thân chân thực về người phụ nữ mặc chiếc váy, với ánh sáng và bóng đổ được điều chỉnh cho phù hợp với môi trường ngoài trời. |

|
Giữ lại chi tiết có độ trung thực cao
Để đảm bảo các chi tiết quan trọng (như khuôn mặt hoặc biểu trưng) được giữ nguyên trong quá trình chỉnh sửa, hãy mô tả các chi tiết đó một cách cụ thể cùng với yêu cầu chỉnh sửa của bạn.
| Câu lệnh | Nội dung tạo sinh |
|---|---|
|
Hình ảnh đầu vào: 
Câu lệnh: Chụp bức ảnh đầu tiên về người phụ nữ có mái tóc nâu, đôi mắt xanh và biểu cảm trung tính. Thêm biểu trưng trong hình ảnh thứ hai vào áo thun đen của cô ấy. Đảm bảo khuôn mặt và các đặc điểm của người phụ nữ hoàn toàn không thay đổi. Biểu trưng phải trông như được in tự nhiên trên vải, theo các nếp gấp của áo. |
|
Tạo cảm giác sống động cho một nội dung nào đó
Tải bản phác thảo hoặc bản vẽ thô lên và yêu cầu mô hình tinh chỉnh thành một hình ảnh hoàn chỉnh.
| Câu lệnh | Nội dung tạo sinh |
|---|---|
|
Hình ảnh đầu vào: 
Câu lệnh: Biến bản phác thảo bằng bút chì thô này về một chiếc ô tô tương lai thành một bức ảnh bóng bẩy về chiếc ô tô ý tưởng đã hoàn thiện trong phòng trưng bày. Giữ nguyên các đường nét mượt mà và kiểu dáng thấp trong bản phác thảo, nhưng thêm sơn màu xanh dương ánh kim và đèn chiếu sáng vành xe neon. |

|
Đảm bảo tính nhất quán của nhân vật: Chế độ xem 360 độ
Bạn có thể tạo chế độ xem 360 độ của một nhân vật bằng cách liên tục đưa ra câu lệnh cho các góc khác nhau. Để có kết quả tốt nhất, hãy thêm những hình ảnh đã tạo trước đó vào các câu lệnh tiếp theo để duy trì tính nhất quán. Đối với những tư thế phức tạp, hãy thêm một hình ảnh tham khảo về tư thế mong muốn.
| Câu lệnh | Nội dung tạo sinh |
|---|---|
|
Hình ảnh đầu vào:
Câu lệnh: Ảnh chân dung của người đàn ông này trong studio, chụp trên nền trắng, chụp nghiêng mặt nhìn sang phải |


|
Các phương pháp hay nhất
Để nâng kết quả từ tốt lên xuất sắc, hãy kết hợp những chiến lược chuyên nghiệp này vào quy trình làm việc của bạn.
- Càng cụ thể càng tốt: Bạn càng cung cấp nhiều thông tin chi tiết, bạn càng có nhiều quyền kiểm soát. Thay vì "áo giáp giả tưởng", hãy mô tả nó: "áo giáp dạng tấm của người lùn được trang trí công phu, khắc hoạ các hoạ tiết lá bạc, có cổ áo cao và cầu vai có hình dáng giống cánh chim ưng".
- Cung cấp bối cảnh và ý định: Giải thích mục đích của hình ảnh. Khả năng hiểu ngữ cảnh của mô hình sẽ ảnh hưởng đến kết quả đầu ra cuối cùng. Ví dụ: "Tạo một biểu trưng cho một thương hiệu chăm sóc da tối giản, cao cấp" sẽ mang lại kết quả tốt hơn so với chỉ "Tạo một biểu trưng".
- Lặp lại và tinh chỉnh: Đừng mong đợi một hình ảnh hoàn hảo ngay từ lần thử đầu tiên. Sử dụng tính chất đàm thoại của mô hình để thực hiện các thay đổi nhỏ. Tiếp tục đưa ra các câu lệnh như "Tuyệt vời, nhưng bạn có thể điều chỉnh ánh sáng ấm hơn một chút không?" hoặc "Giữ nguyên mọi thứ, nhưng thay đổi biểu cảm của nhân vật sao cho nghiêm túc hơn."
- Sử dụng hướng dẫn từng bước: Đối với những cảnh phức tạp có nhiều phần tử, hãy chia câu lệnh thành các bước. "Trước tiên, hãy tạo một hình nền là khu rừng yên bình, mờ sương vào lúc bình minh. Sau đó, ở tiền cảnh, hãy thêm một bàn thờ bằng đá cổ được phủ đầy rêu. Cuối cùng, hãy đặt một thanh kiếm phát sáng duy nhất lên trên bàn thờ."
- Sử dụng "Câu lệnh phủ định ngữ nghĩa": Thay vì nói "không có ô tô", hãy mô tả cảnh mong muốn một cách tích cực: "một con đường vắng vẻ, không có dấu hiệu giao thông".
- Kiểm soát Camera: Sử dụng ngôn ngữ nhiếp ảnh và điện ảnh để kiểm soát bố cục. Các thuật ngữ như
wide-angle shot,macro shot,low-angle perspective.
Các điểm hạn chế
- Để có hiệu suất tốt nhất, hãy sử dụng các ngôn ngữ sau: tiếng Anh, tiếng Ả Rập (Ai Cập), tiếng Đức (Đức), tiếng Tây Ban Nha (Mexico), tiếng Pháp (Pháp), tiếng Hindi (Ấn Độ), tiếng Indonesia (Indonesia), tiếng Ý (Ý), tiếng Nhật (Nhật Bản), tiếng Hàn (Hàn Quốc), tiếng Bồ Đào Nha (Brazil), tiếng Nga (Nga), tiếng Ukraina (Ukraina), tiếng Việt (Việt Nam), tiếng Trung (Trung Quốc).
- Tính năng tạo hình ảnh không hỗ trợ dữ liệu đầu vào bằng âm thanh hoặc video.
- Không phải lúc nào mô hình cũng tạo ra chính xác số lượng hình ảnh mà người dùng yêu cầu một cách rõ ràng.
gemini-2.5-flash-imagehoạt động hiệu quả nhất khi có tối đa 3 hình ảnh làm dữ liệu đầu vào, trong khigemini-3-pro-image-previewhỗ trợ 5 hình ảnh có độ trung thực cao và tổng cộng tối đa 14 hình ảnh.gemini-3.1-flash-image-previewhỗ trợ độ tương đồng về ký tự lên đến 4 ký tự và độ trung thực lên đến 10 đối tượng trong một quy trình duy nhất.- Khi tạo văn bản cho một hình ảnh, Gemini hoạt động hiệu quả nhất nếu bạn tạo văn bản trước rồi yêu cầu tạo hình ảnh có văn bản đó.
gemini-3.1-flash-image-previewBám sát nguồn bằng Google Tìm kiếm hiện không hỗ trợ việc sử dụng hình ảnh thực tế về con người từ tìm kiếm trên web.- Tất cả hình ảnh được tạo đều có hình mờ SynthID.
Cấu hình không bắt buộc
Bạn có thể tuỳ ý định cấu hình các phương thức phản hồi và tỷ lệ khung hình của đầu ra của mô hình trong trường config của các lệnh gọi generate_content.
Loại kết quả
Theo mặc định, mô hình sẽ trả về văn bản và hình ảnh (tức là response_modalities=['Text', 'Image']). Bạn có thể định cấu hình phản hồi để chỉ trả về hình ảnh mà không có văn bản bằng cách sử dụng response_modalities=['Image'].
Python
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[prompt],
config=types.GenerateContentConfig(
response_modalities=['Image']
)
)
JavaScript
const response = await ai.models.generateContent({
model: "gemini-3.1-flash-image-preview",
contents: prompt,
config: {
responseModalities: ['Image']
}
});
Go
result, _ := client.Models.GenerateContent(
ctx,
"gemini-3.1-flash-image-preview",
genai.Text("Create a picture of a nano banana dish in a " +
" fancy restaurant with a Gemini theme"),
&genai.GenerateContentConfig{
ResponseModalities: "Image",
},
)
Java
response = client.models.generateContent(
"gemini-3.1-flash-image-preview",
prompt,
GenerateContentConfig.builder()
.responseModalities("IMAGE")
.build());
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{
"parts": [
{"text": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme"}
]
}],
"generationConfig": {
"responseModalities": ["Image"]
}
}'
Tỷ lệ khung hình và kích thước hình ảnh
Theo mặc định, mô hình sẽ điều chỉnh kích thước hình ảnh đầu ra cho phù hợp với kích thước hình ảnh đầu vào hoặc tạo ra các hình vuông 1:1.
Bạn có thể kiểm soát tỷ lệ khung hình của hình ảnh đầu ra bằng cách sử dụng trường aspect_ratio trong response_format trong yêu cầu phản hồi, như minh hoạ ở đây:
Python
# For gemini-2.5-flash-image
response = client.models.generate_content(
model="gemini-2.5-flash-image",
contents=[prompt],
config=types.GenerateContentConfig(
response_format={"image": {aspect_ratio: "16:9",}}
)
)
# For gemini-3.1-flash-image-preview and gemini-3-pro-image-preview
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[prompt],
config=types.GenerateContentConfig(
response_format={"image": {aspect_ratio: "16:9", image_size: "2K",}}
)
)
JavaScript
// For gemini-2.5-flash-image
const response = await ai.models.generateContent({
model: "gemini-2.5-flash-image",
contents: prompt,
config: {
responseFormat: {
image: {
aspectRatio: "16:9",
}
},
}
});
// For gemini-3.1-flash-image-preview and gemini-3-pro-image-preview
const response_gemini3 = await ai.models.generateContent({
model: "gemini-3.1-flash-image-preview",
contents: prompt,
config: {
responseFormat: {
image: {
aspectRatio: "16:9",
imageSize: "2K",
}
},
}
});
Go
// For gemini-2.5-flash-image
result, _ := client.Models.GenerateContent(
ctx,
"gemini-2.5-flash-image",
genai.Text("Create a picture of a nano banana dish in a " +
" fancy restaurant with a Gemini theme"),
&genai.GenerateContentConfig{
ImageConfig: &genai.ImageConfig{
AspectRatio: "16:9",
},
}
)
// For gemini-3.1-flash-image-preview and gemini-3-pro-image-preview
result_gemini3, _ := client.Models.GenerateContent(
ctx,
"gemini-3.1-flash-image-preview",
genai.Text("Create a picture of a nano banana dish in a " +
" fancy restaurant with a Gemini theme"),
&genai.GenerateContentConfig{
ImageConfig: &genai.ImageConfig{
AspectRatio: "16:9",
ImageSize: "2K",
},
}
)
Java
// For gemini-2.5-flash-image
response = client.models.generateContent(
"gemini-2.5-flash-image",
prompt,
GenerateContentConfig.builder()
.imageConfig(ImageConfig.builder()
.aspectRatio("16:9")
.build())
.build());
// For gemini-3.1-flash-image-preview and gemini-3-pro-image-preview
response_gemini3 = client.models.generateContent(
"gemini-3.1-flash-image-preview",
prompt,
GenerateContentConfig.builder()
.imageConfig(ImageConfig.builder()
.aspectRatio("16:9")
.imageSize("2K")
.build())
.build());
REST
# For gemini-2.5-flash-image
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash-image:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"contents": [{
"parts": [
{"text": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme"}
]
}],
"generationConfig": {
"responseFormat": {
"image": {
"aspectRatio": "16:9"
}
}
}
}'
# For gemini-3-pro-image-preview
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"contents": [{
"parts": [
{"text": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme"}
]
}],
"generationConfig": {
"responseFormat": {
"image": {
"aspectRatio": "16:9",
"imageSize": "2K"
}
}
}
}'
Các tỷ lệ hiện có và kích thước của hình ảnh được tạo được liệt kê trong các bảng sau:
3.1 Bản xem trước hình ảnh Flash
| Tỷ lệ khung hình | Độ phân giải 512 | 500 token | Độ phân giải 1K | 1.000 token | Độ phân giải 2K | 2.000 token | Độ phân giải 4K | 4.000 token |
|---|---|---|---|---|---|---|---|---|
| 1:1 | 512x512 | 747 | 1024x1024 | 1120 | 2048x2048 | 1680 | 4096x4096 | 2520 |
| 1:4 | 256x1024 | 747 | 512x2048 | 1120 | 1024x4096 | 1680 | 2048x8192 | 2520 |
| 1:8 | 192x1536 | 747 | 384x3072 | 1120 | 768x6144 | 1680 | 1536x12288 | 2520 |
| 2:3 | 424x632 | 747 | 848x1264 | 1120 | 1696x2528 | 1680 | 3392x5056 | 2520 |
| 3:2 | 632x424 | 747 | 1264x848 | 1120 | 2528x1696 | 1680 | 5056x3392 | 2520 |
| 3:4 | 448x600 | 747 | 896x1200 | 1120 | 1792x2400 | 1680 | 3584x4800 | 2520 |
| 4:1 | 1024x256 | 747 | 2048x512 | 1120 | 4096x1024 | 1680 | 8192x2048 | 2520 |
| 4:3 | 600x448 | 747 | 1200x896 | 1120 | 2400x1792 | 1680 | 4800x3584 | 2520 |
| 4:5 | 464x576 | 747 | 928x1152 | 1120 | 1856x2304 | 1680 | 3712x4608 | 2520 |
| 5:4 | 576x464 | 747 | 1152x928 | 1120 | 2304x1856 | 1680 | 4608x3712 | 2520 |
| 8:1 | 1536x192 | 747 | 3072x384 | 1120 | 6144x768 | 1680 | 12288x1536 | 2520 |
| 9:16 | 384x688 | 747 | 768x1376 | 1120 | 1536x2752 | 1680 | 3072x5504 | 2520 |
| 16:9 | 688x384 | 747 | 1376x768 | 1120 | 2752x1536 | 1680 | 5504x3072 | 2520 |
| 21:9 | 792x168 | 747 | 1584x672 | 1120 | 3168x1344 | 1680 | 6336x2688 | 2520 |
Bản xem trước hình ảnh 3 Pro
| Tỷ lệ khung hình | Độ phân giải 1K | 1.000 token | Độ phân giải 2K | 2.000 token | Độ phân giải 4K | 4.000 token |
|---|---|---|---|---|---|---|
| 1:1 | 1024x1024 | 1120 | 2048x2048 | 1120 | 4096x4096 | 2000 |
| 2:3 | 848x1264 | 1120 | 1696x2528 | 1120 | 3392x5056 | 2000 |
| 3:2 | 1264x848 | 1120 | 2528x1696 | 1120 | 5056x3392 | 2000 |
| 3:4 | 896x1200 | 1120 | 1792x2400 | 1120 | 3584x4800 | 2000 |
| 4:3 | 1200x896 | 1120 | 2400x1792 | 1120 | 4800x3584 | 2000 |
| 4:5 | 928x1152 | 1120 | 1856x2304 | 1120 | 3712x4608 | 2000 |
| 5:4 | 1152x928 | 1120 | 2304x1856 | 1120 | 4608x3712 | 2000 |
| 9:16 | 768x1376 | 1120 | 1536x2752 | 1120 | 3072x5504 | 2000 |
| 16:9 | 1376x768 | 1120 | 2752x1536 | 1120 | 5504x3072 | 2000 |
| 21:9 | 1584x672 | 1120 | 3168x1344 | 1120 | 6336x2688 | 2000 |
Hình ảnh Gemini 2.5 Flash
| Tỷ lệ khung hình | Độ phân giải | Mã thông báo |
|---|---|---|
| 1:1 | 1024x1024 | 1290 |
| 2:3 | 832x1248 | 1290 |
| 3:2 | 1248x832 | 1290 |
| 3:4 | 864x1184 | 1290 |
| 4:3 | 1184x864 | 1290 |
| 4:5 | 896x1152 | 1290 |
| 5:4 | 1152x896 | 1290 |
| 9:16 | 768x1344 | 1290 |
| 16:9 | 1344x768 | 1290 |
| 21:9 | 1536x672 | 1290 |
Lựa chọn mô hình
Chọn mô hình phù hợp nhất với trường hợp sử dụng cụ thể của bạn.
Bản xem trước hình ảnh của Gemini 3.1 Flash (Bản xem trước Nano Banana 2) nên là mô hình tạo hình ảnh mà bạn ưu tiên sử dụng, vì đây là mô hình có hiệu suất và trí thông minh toàn diện tốt nhất để cân bằng chi phí và độ trễ. Hãy xem trang giá và khả năng của mô hình để biết thêm thông tin chi tiết.
Bản xem trước hình ảnh của Gemini 3 Pro (Bản xem trước của Nano Banana Pro) được thiết kế để tạo tài sản chuyên nghiệp và thực hiện các chỉ dẫn phức tạp. Mô hình này có tính năng xác thực thông tin thực tế bằng Google Tìm kiếm, quy trình "Suy nghĩ" mặc định giúp tinh chỉnh thành phần trước khi tạo và có thể tạo hình ảnh có độ phân giải lên đến 4K. Hãy xem trang giá và khả năng của mô hình để biết thêm thông tin chi tiết.
Hình ảnh Gemini 2.5 Flash (Nano Banana) được thiết kế để mang lại tốc độ và hiệu quả. Mô hình này được tối ưu hoá cho các tác vụ có khối lượng lớn, độ trễ thấp và tạo ra hình ảnh ở độ phân giải 1024px. Hãy xem trang giá và khả năng của mô hình để biết thêm thông tin chi tiết.
Trường hợp sử dụng Imagen
Ngoài việc sử dụng các tính năng tạo hình ảnh tích hợp của Gemini, bạn cũng có thể truy cập vào Imagen, mô hình tạo hình ảnh chuyên dụng của chúng tôi, thông qua Gemini API.
Imagen 4 nên là mô hình bạn ưu tiên sử dụng khi bắt đầu tạo hình ảnh bằng Imagen. Chọn Imagen 4 Ultra cho các trường hợp sử dụng nâng cao hoặc khi bạn cần chất lượng hình ảnh tốt nhất (xin lưu ý rằng bạn chỉ có thể tạo một hình ảnh tại một thời điểm).
Bước tiếp theo
- Bạn có thể tìm thêm ví dụ và mã mẫu trong hướng dẫn về sổ tay hướng dẫn.
- Hãy xem hướng dẫn về Veo để tìm hiểu cách tạo video bằng Gemini API.
- Để tìm hiểu thêm về các mô hình Gemini, hãy xem phần Các mô hình Gemini.