ইমেজেন হলো গুগলের একটি উচ্চ-মানের ছবি তৈরির মডেল, যা টেক্সট প্রম্পট থেকে বাস্তবসম্মত ও উচ্চ মানের ছবি তৈরি করতে সক্ষম। তৈরি করা সমস্ত ছবিতে একটি সিন্থআইডি (SynthID) ওয়াটারমার্ক থাকে। ইমেজেন মডেলের উপলব্ধ বিভিন্ন সংস্করণ সম্পর্কে আরও জানতে, মডেল সংস্করণ বিভাগটি দেখুন।
ন্যানো কলার দিকে স্থানান্তর
Imagen মডেলগুলো অপ্রচলিত হয়ে গেছে এবং ২০২৬ সালের ১৭ই আগস্ট থেকে বন্ধ হয়ে যাবে। আপনার ইমেজ তৈরির প্রয়োজনে আমরা Nano Banana-তে স্থানান্তরিত হওয়ার পরামর্শ দিচ্ছি।
অভিবাসনের সাথে নিম্নলিখিত পরিবর্তনগুলো জড়িত:
- মডেলের নাম : Imagen মডেলের নামের পরিবর্তে
gemini-2.5-flash-imageব্যবহার করুন। - পদ্ধতি :
client.models.generate_contentএর পরিবর্তেclient.models.generate_imagesব্যবহার করুন। - প্রতিক্রিয়া পরিচালনা : ন্যানো ব্যানানা একটি নির্দিষ্ট ইমেজ রেসপন্স অবজেক্টের পরিবর্তে কন্টেন্টের অংশবিশেষ ফেরত দেয়, যার মধ্যে ইমেজ ডেটাও থাকতে পারে।
আরও বিস্তারিত তথ্য ও উদাহরণের জন্য ইমেজ তৈরির নির্দেশিকা দেখুন।
Imagen মডেল ব্যবহার করে ছবি তৈরি করুন।
এই উদাহরণটি Imagen মডেল ব্যবহার করে ছবি তৈরি করা প্রদর্শন করে:
পাইথন
from google import genai
from google.genai import types
from PIL import Image
from io import BytesIO
client = genai.Client()
response = client.models.generate_images(
model='imagen-4.0-generate-001',
prompt='Robot holding a red skateboard',
config=types.GenerateImagesConfig(
number_of_images= 4,
)
)
for generated_image in response.generated_images:
generated_image.image.show()
জাভাস্ক্রিপ্ট
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const response = await ai.models.generateImages({
model: 'imagen-4.0-generate-001',
prompt: 'Robot holding a red skateboard',
config: {
numberOfImages: 4,
},
});
let idx = 1;
for (const generatedImage of response.generatedImages) {
let imgBytes = generatedImage.image.imageBytes;
const buffer = Buffer.from(imgBytes, "base64");
fs.writeFileSync(`imagen-${idx}.png`, buffer);
idx++;
}
}
main();
যান
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateImagesConfig{
NumberOfImages: 4,
}
response, _ := client.Models.GenerateImages(
ctx,
"imagen-4.0-generate-001",
"Robot holding a red skateboard",
config,
)
for n, image := range response.GeneratedImages {
fname := fmt.Sprintf("imagen-%d.png", n)
_ = os.WriteFile(fname, image.Image.ImageBytes, 0644)
}
}
বিশ্রাম
curl -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/imagen-4.0-generate-001:predict" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"instances": [
{
"prompt": "Robot holding a red skateboard"
}
],
"parameters": {
"sampleCount": 4
}
}'

ইমেজ কনফিগারেশন
Imagen বর্তমানে শুধুমাত্র ইংরেজি প্রম্পট এবং নিম্নলিখিত প্যারামিটারগুলো সমর্থন করে:
-
numberOfImages: যতগুলো ছবি তৈরি করতে চান, তার সংখ্যা; ১ থেকে ৪ পর্যন্ত (উভয় সংখ্যাসহ)। ডিফল্ট মান হলো ৪। -
imageSize: তৈরি হওয়া ছবির আকার। এটি শুধুমাত্র স্ট্যান্ডার্ড এবং আলট্রা মডেলের জন্য সমর্থিত। সমর্থিত মানগুলো হলো1Kএবং2K। ডিফল্ট হলো1K। -
aspectRatio: তৈরি হওয়া ছবির অ্যাস্পেক্ট রেশিও পরিবর্তন করে। সমর্থিত মানগুলো হলো"1:1","3:4","4:3","9:16", এবং"16:9"। ডিফল্ট হলো"1:1"। personGeneration: মডেলটিকে মানুষের ছবি তৈরি করার অনুমতি দিন। নিম্নলিখিত মানগুলি সমর্থিত:-
"dont_allow": মানুষের ছবি তৈরি হওয়া ব্লক করুন। -
"allow_adult": প্রাপ্তবয়স্কদের ছবি তৈরি করুন, কিন্তু শিশুদের নয়। এটিই ডিফল্ট। -
"allow_all": প্রাপ্তবয়স্ক ও শিশুসহ ছবি তৈরি করুন।
-
ইমেজ প্রম্পট গাইড
Imagen গাইডের এই অংশে দেখানো হয়েছে কীভাবে একটি টেক্সট-টু-ইমেজ প্রম্পট পরিবর্তন করে বিভিন্ন ফলাফল পাওয়া যায়, এবং এর সাথে আপনি তৈরি করতে পারেন এমন ছবির উদাহরণও দেওয়া হয়েছে।
প্রম্পট লেখার মৌলিক বিষয়
একটি ভালো প্রম্পট হয় বর্ণনামূলক ও স্পষ্ট এবং এতে অর্থপূর্ণ কীওয়ার্ড ও মডিফায়ার ব্যবহার করা হয়। আপনার বিষয় , প্রেক্ষাপট এবং শৈলী নিয়ে চিন্তা করে শুরু করুন।

বিষয়বস্তু : যেকোনো প্রম্পটের ক্ষেত্রে প্রথম যে বিষয়টি ভাবতে হবে তা হলো বিষয়বস্তু — অর্থাৎ যে বস্তু, ব্যক্তি, প্রাণী বা দৃশ্যের ছবি আপনি চান।
প্রসঙ্গ ও প্রেক্ষাপট: বিষয়বস্তুটিকে যে প্রেক্ষাপট বা পরিবেশে স্থাপন করা হবে, সেটিও ঠিক ততটাই গুরুত্বপূর্ণ। আপনার বিষয়বস্তুটিকে বিভিন্ন ধরনের পটভূমিতে রাখার চেষ্টা করুন। যেমন—সাদা পটভূমিযুক্ত কোনো স্টুডিও, খোলা জায়গা বা ঘরের ভেতরের পরিবেশ।
স্টাইল: সবশেষে, আপনার পছন্দের ছবির স্টাইলটি যোগ করুন। স্টাইলগুলো সাধারণ (যেমন পেইন্টিং, ফটোগ্রাফ, স্কেচ) অথবা খুব নির্দিষ্ট (যেমন প্যাস্টেল পেইন্টিং, চারকোল ড্রয়িং, আইসোমেট্রিক ৩ডি) হতে পারে। আপনি একাধিক স্টাইল একত্রিতও করতে পারেন।
আপনার প্রম্পটের প্রথম সংস্করণটি লেখার পর, আরও বিশদ বিবরণ যোগ করে সেটিকে পরিমার্জন করতে থাকুন যতক্ষণ না আপনি আপনার কাঙ্ক্ষিত চিত্রটি পাচ্ছেন। পুনরাবৃত্তি গুরুত্বপূর্ণ। আপনার মূল ধারণাটি প্রতিষ্ঠা করে শুরু করুন, এবং তারপর সেই মূল ধারণাটিকে পরিমার্জন ও প্রসারিত করতে থাকুন যতক্ষণ না তৈরি হওয়া চিত্রটি আপনার কল্পনার কাছাকাছি আসে।
 |  |  |
আপনার নির্দেশনা সংক্ষিপ্ত হোক বা দীর্ঘ ও বিস্তারিত হোক, ইমাজেন মডেল আপনার ধারণাগুলোকে বিশদ চিত্রে রূপান্তরিত করতে পারে। বারবার নির্দেশনা প্রয়োগের মাধ্যমে আপনার ভাবনাকে পরিমার্জন করুন এবং নিখুঁত ফলাফল না পাওয়া পর্যন্ত বিশদ বিবরণ যোগ করতে থাকুন।
সংক্ষিপ্ত নির্দেশাবলী আপনাকে দ্রুত একটি ছবি তৈরি করতে সাহায্য করে।  | বিস্তারিত নির্দেশাবলী আপনাকে নির্দিষ্ট বিবরণ যোগ করতে এবং আপনার চিত্রটি তৈরি করতে সাহায্য করে।  |
ইমেজেন প্রম্পট লেখার জন্য অতিরিক্ত পরামর্শ:
- বর্ণনামূলক ভাষা ব্যবহার করুন : Imagen-এর একটি স্পষ্ট চিত্র তুলে ধরতে বিশদ বিশেষণ ও ক্রিয়াবিশেষণ প্রয়োগ করুন।
- প্রাসঙ্গিক তথ্য দিন : প্রয়োজনে, এআই-এর বোঝার সুবিধার্থে পটভূমি সম্পর্কিত তথ্য অন্তর্ভুক্ত করুন।
- নির্দিষ্ট শিল্পী বা শৈলীর উল্লেখ করুন : আপনার যদি কোনো বিশেষ নান্দনিকতা মাথায় থাকে, তবে নির্দিষ্ট শিল্পী বা শিল্প আন্দোলনের উল্লেখ করা সহায়ক হতে পারে।
- প্রম্পট ইঞ্জিনিয়ারিং টুল ব্যবহার করুন : আপনার প্রম্পটগুলোকে আরও পরিমার্জিত করতে এবং সর্বোত্তম ফলাফল অর্জনের জন্য প্রম্পট ইঞ্জিনিয়ারিং টুল বা রিসোর্সগুলো খতিয়ে দেখার কথা বিবেচনা করুন।
- আপনার ব্যক্তিগত এবং দলগত ছবিতে মুখের বিবরণ উন্নত করা : ছবির মূল কেন্দ্রবিন্দু হিসেবে মুখের বিবরণ নির্দিষ্ট করুন (উদাহরণস্বরূপ, নির্দেশনায় 'পোর্ট্রেট' শব্দটি ব্যবহার করুন)।
ছবিতে টেক্সট তৈরি করুন
ইমেজেন মডেল ছবিতে টেক্সট যোগ করতে পারে, যা আরও সৃজনশীল ছবি তৈরির সুযোগ করে দেয়। এই ফিচারটির সর্বোত্তম ব্যবহার করতে নিচের নির্দেশিকাটি অনুসরণ করুন:
- আত্মবিশ্বাসের সাথে পুনরাবৃত্তি করুন : আপনার কাঙ্ক্ষিত রূপটি না পাওয়া পর্যন্ত আপনাকে ছবিগুলো পুনরায় তৈরি করতে হতে পারে। Imagen-এর টেক্সট ইন্টিগ্রেশন এখনও বিকশিত হচ্ছে, এবং কখনও কখনও একাধিকবার চেষ্টা করলেই সেরা ফলাফল পাওয়া যায়।
- সংক্ষিপ্ত রাখুন : সর্বোত্তম ফলাফল পেতে টেক্সট ২৫ অক্ষর বা তার কমের মধ্যে সীমাবদ্ধ রাখুন।
একাধিক বাক্যাংশ : অতিরিক্ত তথ্য প্রদানের জন্য দুই বা তিনটি স্বতন্ত্র বাক্যাংশ নিয়ে পরীক্ষা করুন। রচনাকে আরও পরিচ্ছন্ন রাখতে তিনটির বেশি বাক্যাংশ ব্যবহার করা থেকে বিরত থাকুন।

নির্দেশনা: একটি পোস্টার যার শিরোনাম হিসেবে মোটা হরফে "Summerland" লেখা থাকবে এবং এর নিচে "Summer never felt so good" স্লোগানটি থাকবে। নির্দেশিকা স্থাপন : যদিও Imagen নির্দেশ অনুযায়ী টেক্সট স্থাপন করার চেষ্টা করতে পারে, তবুও মাঝে মাঝে কিছু ভিন্নতা আশা করা যায়। এই ফিচারটি ক্রমাগত উন্নত করা হচ্ছে।
ফন্ট শৈলী অনুপ্রাণিত করুন : Imagen-এর পছন্দকে সূক্ষ্মভাবে প্রভাবিত করতে একটি সাধারণ ফন্ট শৈলী নির্দিষ্ট করুন। হুবহু ফন্ট অনুকরণের উপর নির্ভর করবেন না, তবে সৃজনশীল ব্যাখ্যার আশা রাখতে পারেন।
ফন্ট সাইজ : ফন্ট সাইজ নির্ধারণকে প্রভাবিত করতে একটি ফন্ট সাইজ অথবা আকারের একটি সাধারণ ইঙ্গিত (যেমন, ছোট , মাঝারি , বড় ) নির্দিষ্ট করুন।
প্রম্পট প্যারামিটারাইজেশন
আউটপুট ফলাফল আরও ভালোভাবে নিয়ন্ত্রণ করার জন্য, Imagen-এর ইনপুটগুলোকে প্যারামিটারাইজ করা আপনার জন্য সহায়ক হতে পারে। উদাহরণস্বরূপ, ধরুন আপনি চান আপনার গ্রাহকরা তাদের ব্যবসার জন্য লোগো তৈরি করতে পারুক, এবং আপনি এটাও নিশ্চিত করতে চান যে লোগোগুলো যেন সবসময় একটি সলিড কালার ব্যাকগ্রাউন্ডে তৈরি হয়। এছাড়াও, আপনি একটি মেনু থেকে ক্লায়েন্টের বেছে নেওয়ার অপশনগুলোও সীমিত করতে চান।
এই উদাহরণে, আপনি নিম্নলিখিতের অনুরূপ একটি প্যারামিটারযুক্ত প্রম্পট তৈরি করতে পারেন:
A {logo_style} logo for a {company_area} company on a solid color background. Include the text {company_name}.আপনার কাস্টম ইউজার ইন্টারফেসে, গ্রাহক একটি মেনু ব্যবহার করে প্যারামিটারগুলো ইনপুট করতে পারেন এবং তাদের নির্বাচিত মানটি Imagen-এর প্রাপ্ত প্রম্পটে পূরণ হয়ে যায়।
উদাহরণস্বরূপ:
নির্দেশনা:
A minimalist logo for a health care company on a solid color background. Include the text Journey .
নির্দেশনা:
A modern logo for a software company on a solid color background. Include the text Silo .
নির্দেশনা:
A traditional logo for a baking company on a solid color background. Include the text Seed .
উন্নত প্রম্পট লেখার কৌশল
ফটোগ্রাফির বর্ণনাকারী, আকার ও উপকরণ, ঐতিহাসিক শিল্প আন্দোলন এবং ছবির গুণমান নির্ধারকের মতো বৈশিষ্ট্যের উপর ভিত্তি করে আরও সুনির্দিষ্ট নির্দেশ তৈরি করতে নিম্নলিখিত উদাহরণগুলি ব্যবহার করুন।
ফটোগ্রাফি
- নির্দেশনা: "একটি ছবি..."
এই শৈলীটি ব্যবহার করতে, এমন কীওয়ার্ড দিয়ে শুরু করুন যা Imagen-কে স্পষ্টভাবে জানিয়ে দেবে যে আপনি একটি ছবি খুঁজছেন। আপনার প্রম্পটগুলি 'একটি ছবি...' দিয়ে শুরু করুন। উদাহরণস্বরূপ:
 |  |  |
ছবির উৎস: প্রতিটি ছবি Imagen 4 মডেল ব্যবহার করে তার সংশ্লিষ্ট টেক্সট প্রম্পট থেকে তৈরি করা হয়েছে।
ফটোগ্রাফি মডিফায়ার
নিম্নলিখিত উদাহরণগুলিতে, আপনি ফটোগ্রাফি-নির্দিষ্ট বেশ কিছু মডিফায়ার এবং প্যারামিটার দেখতে পাবেন। আরও সুনির্দিষ্ট নিয়ন্ত্রণের জন্য আপনি একাধিক মডিফায়ার একত্রিত করতে পারেন।
ক্যামেরার নৈকট্য - কাছ থেকে তোলা, দূর থেকে তোলা

নির্দেশনা: কফি বিনের একটি ক্লোজ-আপ ছবি। 
নির্দেশনা: একটি ছোট ব্যাগের জুম আউট করা ছবি।
অগোছালো রান্নাঘরে কফি বিনক্যামেরার অবস্থান - আকাশ থেকে, নিচ থেকে

নির্দেশনা: গগনচুম্বী অট্টালিকাসহ একটি শহুরে শহরের আকাশ থেকে তোলা ছবি। 
নির্দেশনা: নিচ থেকে তোলা নীল আকাশসহ অরণ্যের চাঁদোয়ার একটি ছবি। আলো - প্রাকৃতিক, নাটকীয়, উষ্ণ, শীতল

নির্দেশনা: প্রাকৃতিক আলোতে তোলা একটি আধুনিক আর্মচেয়ারের স্টুডিও ছবি। 
নির্দেশনা: একটি আধুনিক আর্মচেয়ারের স্টুডিও ছবি, নাটকীয় আলো। ক্যামেরা সেটিংস - মোশন ব্লার, সফট ফোকাস, বোকেহ, পোর্ট্রেট

নির্দেশনা: গাড়ির ভেতর থেকে তোলা, মোশন ব্লারসহ আকাশচুম্বী অট্টালিকাযুক্ত একটি শহরের ছবি। 
নির্দেশনা: রাতে কোনো শহুরে সেতুর একটি মৃদু ফোকাসের ছবি। লেন্সের প্রকারভেদ - ৩৫মিমি, ৫০মিমি, ফিশআই, ওয়াইড অ্যাঙ্গেল, ম্যাক্রো

নির্দেশনা: একটি পাতার ছবি, ম্যাক্রো লেন্স 
বিষয়বস্তু: স্ট্রিট ফটোগ্রাফি, নিউ ইয়র্ক সিটি, ফিশআই লেন্স ফিল্মের প্রকারভেদ - সাদা-কালো, পোলারয়েড

নির্দেশনা: সানগ্লাস পরা একটি কুকুরের পোলারয়েড ছবি 
নির্দেশনা: সানগ্লাস পরা একটি কুকুরের সাদা-কালো ছবি
ছবির উৎস: প্রতিটি ছবি Imagen 4 মডেল ব্যবহার করে তার সংশ্লিষ্ট টেক্সট প্রম্পট থেকে তৈরি করা হয়েছে।
চিত্রাঙ্কন এবং শিল্প
- নির্দেশনার মধ্যে রয়েছে: "এর একটি painting ..." , "এর একটি sketch ..."
শিল্পশৈলী পেন্সিল স্কেচের মতো একরঙা শৈলী থেকে শুরু করে অতি-বাস্তবসম্মত ডিজিটাল শিল্প পর্যন্ত বিস্তৃত। উদাহরণস্বরূপ, নিম্নলিখিত ছবিগুলোতে একই নির্দেশনা ভিন্ন ভিন্ন শৈলীতে ব্যবহার করা হয়েছে:
পটভূমিতে আকাশচুম্বী অট্টালিকা সহ একটি কৌণিক স্পোর্টি ইলেকট্রিক সেডানের একটি [art style or creation technique] ।
 |  |  |
 |  |  |
ছবির উৎস: প্রতিটি ছবি Imagen 2 মডেল ব্যবহার করে তার সংশ্লিষ্ট টেক্সট প্রম্পট থেকে তৈরি করা হয়েছে।
আকার এবং উপকরণ
- প্রম্পটে রয়েছে: "...যা দিয়ে তৈরি..." , "...যার আকৃতি..."
এই প্রযুক্তির অন্যতম একটি শক্তি হলো, এর মাধ্যমে এমন সব চিত্র তৈরি করা যায় যা অন্যথায় কঠিন বা অসম্ভব। উদাহরণস্বরূপ, আপনি আপনার কোম্পানির লোগোটি বিভিন্ন উপকরণ ও টেক্সচারে পুনরায় তৈরি করতে পারেন।
 |  |  |
ছবির উৎস: প্রতিটি ছবি Imagen 4 মডেল ব্যবহার করে তার সংশ্লিষ্ট টেক্সট প্রম্পট থেকে তৈরি করা হয়েছে।
ঐতিহাসিক শিল্পকলার উল্লেখ
- নির্দেশনায় রয়েছে: "...এর শৈলীতে..."
কিছু শৈলী বছরের পর বছর ধরে আইকনিক হয়ে উঠেছে। নিচে ঐতিহাসিক চিত্রকলা বা শিল্পশৈলীর কিছু ধারণা দেওয়া হলো যা আপনি চেষ্টা করতে পারেন।
[art period or movement] -এর শৈলীতে একটি চিত্র তৈরি করুন: একটি বায়ু বিদ্যুৎ কেন্দ্র।
 |  |  |
ছবির উৎস: প্রতিটি ছবি Imagen 4 মডেল ব্যবহার করে তার সংশ্লিষ্ট টেক্সট প্রম্পট থেকে তৈরি করা হয়েছে।
ছবির গুণমান পরিবর্তনকারী
কিছু নির্দিষ্ট কীওয়ার্ড মডেলকে জানিয়ে দিতে পারে যে আপনি একটি উচ্চ-মানের অ্যাসেট খুঁজছেন। কোয়ালিটি মডিফায়ারের উদাহরণগুলো নিচে দেওয়া হলো:
- সাধারণ মডিফায়ার - উচ্চ-মানের, সুন্দর, শৈলীযুক্ত
- ছবি - 4K, HDR, স্টুডিও ছবি
- শিল্পকলা, চিত্রাঙ্কন - একজন পেশাদার দ্বারা, বিস্তারিত
নিম্নে গুণবাচক বিশেষক ছাড়া এবং গুণবাচক বিশেষক সহ একই প্রম্পটের কয়েকটি উদাহরণ দেওয়া হলো।
 |  একজনের তোলা ভুট্টার ডাঁটার ছবি পেশাদার ফটোগ্রাফার |
ছবির উৎস: প্রতিটি ছবি Imagen 4 মডেল ব্যবহার করে তার সংশ্লিষ্ট টেক্সট প্রম্পট থেকে তৈরি করা হয়েছে।
আকৃতির অনুপাত
Imagen ইমেজ জেনারেশন আপনাকে পাঁচটি ভিন্ন ইমেজ অ্যাস্পেক্ট রেশিও সেট করার সুযোগ দেয়।
- বর্গাকার (১:১, ডিফল্ট) - একটি আদর্শ বর্গাকার ছবি। সোশ্যাল মিডিয়া পোস্টের ক্ষেত্রে এই অ্যাস্পেক্ট রেশিও সাধারণত ব্যবহৃত হয়।
ফুলস্ক্রিন (৪:৩) - এই অ্যাস্পেক্ট রেশিওটি সাধারণত মিডিয়া বা চলচ্চিত্রে ব্যবহৃত হয়। এটি বেশিরভাগ পুরোনো (নন-ওয়াইডস্ক্রিন) টিভি এবং মিডিয়াম ফরম্যাট ক্যামেরার মাপও বটে। এটি (১:১ এর তুলনায়) দৃশ্যের বেশি অংশ আনুভূমিকভাবে ধারণ করে, যার ফলে এটি ফটোগ্রাফির জন্য একটি পছন্দের অ্যাস্পেক্ট রেশিও।

নির্দেশনা: পিয়ানো বাজানো একজন সঙ্গীতশিল্পীর আঙুলের ক্লোজ-আপ, সাদাকালো চলচ্চিত্র, ভিন্টেজ (৪:৩ অ্যাসপেক্ট রেশিও) 
নির্দেশনা: একটি উচ্চমানের রেস্তোরাঁর জন্য ফুড ম্যাগাজিনের স্টাইলে ফ্রেঞ্চ ফ্রাইয়ের একটি প্রফেশনাল স্টুডিও ছবি (৪:৩ অ্যাসপেক্ট রেশিও)। পোর্ট্রেট ফুল স্ক্রিন (৩:৪) - এটি হলো ফুলস্ক্রিন অ্যাস্পেক্ট রেশিওকে ৯০ ডিগ্রি ঘোরানো। এর ফলে ১:১ অ্যাস্পেক্ট রেশিওর তুলনায় দৃশ্যের আরও বেশি অংশ উল্লম্বভাবে ধারণ করা যায়।

নির্দেশনা: একজন মহিলা হাইকিং করছেন, ডোবায় তার বুটের প্রতিবিম্ব, পটভূমিতে বিশাল পর্বতমালা, বিজ্ঞাপনের শৈলীতে, নাটকীয় অ্যাঙ্গেল (৩:৪ অ্যাসপেক্ট রেশিও) 
নির্দেশনা: এক রহস্যময় উপত্যকা বেয়ে বয়ে চলা নদীর আকাশ থেকে তোলা দৃশ্য (৩:৪ অনুপাত) ওয়াইডস্ক্রিন (১৬:৯) - এই অনুপাতটি ৪:৩ অনুপাতের জায়গা নিয়েছে এবং বর্তমানে টিভি, মনিটর ও মোবাইল ফোনের স্ক্রিনের (ল্যান্ডস্কেপ) জন্য এটিই সবচেয়ে প্রচলিত অ্যাস্পেক্ট রেশিও। যখন আপনি পটভূমির আরও বেশি অংশ স্ক্রিনে ধারণ করতে চান (যেমন, মনোরম প্রাকৃতিক দৃশ্য), তখন এই অ্যাস্পেক্ট রেশিওটি ব্যবহার করুন।

প্রম্পট: সৈকতে সম্পূর্ণ সাদা পোশাক পরা একজন পুরুষ বসে আছেন, ক্লোজ-আপ, সোনালী মুহূর্তের আলো (১৬:৯ অ্যাস্পেক্ট রেশিও) পোর্ট্রেট (৯:১৬) - এই অনুপাতটি ওয়াইডস্ক্রিনের মতোই, তবে ঘোরানো। এটি একটি তুলনামূলকভাবে নতুন অ্যাস্পেক্ট রেশিও যা শর্ট-ফর্ম ভিডিও অ্যাপগুলোর (যেমন, ইউটিউব শর্টস) মাধ্যমে জনপ্রিয় হয়েছে। ভবন, গাছ, জলপ্রপাত বা এই জাতীয় লম্বা ও সুস্পষ্ট উল্লম্ব বৈশিষ্ট্যযুক্ত বস্তুর জন্য এটি ব্যবহার করুন।

প্রম্পট: একটি বিশাল আধুনিক, জাঁকজমকপূর্ণ ও মহাকাব্যিক গগনচুম্বী অট্টালিকার ডিজিটাল রেন্ডার, যার পটভূমিতে একটি সুন্দর সূর্যাস্ত রয়েছে (৯:১৬ অ্যাস্পেক্ট রেশিও)।
ফটোরিয়ালিস্টিক ছবি
ইমেজ জেনারেশন মডেলের বিভিন্ন সংস্করণ শৈল্পিক এবং ফটোরিয়ালিস্টিক আউটপুটের মিশ্রণ দিতে পারে। আপনি যে বিষয়বস্তু তৈরি করতে চান, তার উপর ভিত্তি করে আরও ফটোরিয়ালিস্টিক আউটপুট তৈরি করতে প্রম্পটে নিম্নলিখিত শব্দগুলো ব্যবহার করুন।
| ব্যবহারের ক্ষেত্র | লেন্সের ধরন | ফোকাল দৈর্ঘ্য | অতিরিক্ত বিবরণ |
|---|---|---|---|
| মানুষ (প্রতিকৃতি) | প্রাইম, জুম | ২৪-৩৫ মিমি | সাদা-কালো চলচ্চিত্র, ফিল্ম নোয়ার, ডেপথ অফ ফিল্ড, ডুওটোন (দুটি রঙের উল্লেখ করুন) |
| খাবার, পোকামাকড়, গাছপালা (বস্তু, স্থিরচিত্র) | ম্যাক্রো | ৬০-১০৫ মিমি | উচ্চ বিবরণ, নির্ভুল ফোকাসিং, নিয়ন্ত্রিত আলো |
| খেলাধুলা, বন্যপ্রাণী (গতি) | টেলিফটো জুম | ১০০-৪০০ মিমি | দ্রুত শাটার স্পিড, অ্যাকশন বা নড়াচড়া ট্র্যাকিং |
| জ্যোতির্বিজ্ঞান, ল্যান্ডস্কেপ (ওয়াইড-অ্যাঙ্গেল) | প্রশস্ত কোণ | ১০-২৪ মিমি | দীর্ঘ এক্সপোজার সময়, স্পষ্ট ফোকাস, দীর্ঘ এক্সপোজার, মসৃণ জল বা মেঘ |
প্রতিকৃতি
| ব্যবহারের ক্ষেত্র | লেন্সের ধরন | ফোকাল দৈর্ঘ্য | অতিরিক্ত বিবরণ |
|---|---|---|---|
| মানুষ (প্রতিকৃতি) | প্রাইম, জুম | ২৪-৩৫ মিমি | সাদা-কালো চলচ্চিত্র, ফিল্ম নোয়ার, ডেপথ অফ ফিল্ড, ডুওটোন (দুটি রঙের উল্লেখ করুন) |
সারণি থেকে কয়েকটি কীওয়ার্ড ব্যবহার করে Imagen নিম্নলিখিত প্রতিকৃতিগুলো তৈরি করতে পারে:
 |  |  |  |
নির্দেশনা: একজন নারী, ৩৫মিমি প্রতিকৃতি, নীল ও ধূসর ডুওটোন
মডেল: imagen-4.0-generate-001
 |  |  |  |
নির্দেশনা: একজন নারী, ৩৫মিমি প্রতিকৃতি, ফিল্ম নোয়ার
মডেল: imagen-4.0-generate-001
বস্তু
| ব্যবহারের ক্ষেত্র | লেন্সের ধরন | ফোকাল দৈর্ঘ্য | অতিরিক্ত বিবরণ |
|---|---|---|---|
| খাবার, পোকামাকড়, গাছপালা (বস্তু, স্থিরচিত্র) | ম্যাক্রো | ৬০-১০৫ মিমি | উচ্চ বিবরণ, নির্ভুল ফোকাসিং, নিয়ন্ত্রিত আলো |
সারণি থেকে কয়েকটি কীওয়ার্ড ব্যবহার করে Imagen নিম্নলিখিত বস্তুর ছবিগুলো তৈরি করতে পারে:
 |  |  |  |
উপকরণ: প্রেয়ার প্ল্যান্টের পাতা, ম্যাক্রো লেন্স, ৬০ মিমি
মডেল: imagen-4.0-generate-001
 |  |  |  |
নির্দেশনা: এক প্লেট পাস্তা, ১০০ মিমি ম্যাক্রো লেন্স
মডেল: imagen-4.0-generate-001
গতি
| ব্যবহারের ক্ষেত্র | লেন্সের ধরন | ফোকাল দৈর্ঘ্য | অতিরিক্ত বিবরণ |
|---|---|---|---|
| খেলাধুলা, বন্যপ্রাণী (গতি) | টেলিফটো জুম | ১০০-৪০০ মিমি | দ্রুত শাটার স্পিড, অ্যাকশন বা নড়াচড়া ট্র্যাকিং |
সারণি থেকে কয়েকটি কীওয়ার্ড ব্যবহার করে Imagen নিম্নলিখিত মোশন ইমেজগুলো তৈরি করতে পারে:
 |  | 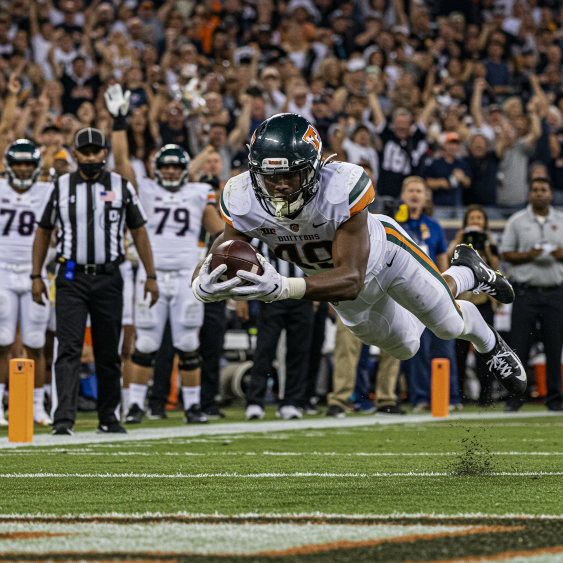 |  |
প্রম্পট: একটি বিজয়ী টাচডাউন, দ্রুত শাটার স্পিড, মুভমেন্ট ট্র্যাকিং
মডেল: imagen-4.0-generate-001
 |  |  |  |
প্রম্পট: জঙ্গলে দৌড়ানো একটি হরিণ, দ্রুত শাটার স্পিড, মুভমেন্ট ট্র্যাকিং
মডেল: imagen-4.0-generate-001
প্রশস্ত কোণ
| ব্যবহারের ক্ষেত্র | লেন্সের ধরন | ফোকাল দৈর্ঘ্য | অতিরিক্ত বিবরণ |
|---|---|---|---|
| জ্যোতির্বিজ্ঞান, ল্যান্ডস্কেপ (ওয়াইড-অ্যাঙ্গেল) | প্রশস্ত কোণ | ১০-২৪ মিমি | দীর্ঘ এক্সপোজার সময়, স্পষ্ট ফোকাস, দীর্ঘ এক্সপোজার, মসৃণ জল বা মেঘ |
সারণি থেকে কয়েকটি কীওয়ার্ড ব্যবহার করে Imagen নিম্নলিখিত ওয়াইড-অ্যাঙ্গেল ছবিগুলো তৈরি করতে পারে:
 |  |  |  |
নির্দেশনা: একটি সুবিশাল পর্বতমালা, ভূদৃশ্য, ওয়াইড অ্যাঙ্গেল, ১০ মিমি
মডেল: imagen-4.0-generate-001
 |  |  |  |
নির্দেশনা: চাঁদের একটি ছবি, জ্যোতির্বিজ্ঞান ফটোগ্রাফি, ওয়াইড অ্যাঙ্গেল ১০মিমি
মডেল: imagen-4.0-generate-001
মডেল সংস্করণ
ইমেজেন ৪ (অপ্রচলিত)
| সম্পত্তি | বর্ণনা |
|---|---|
| মডেল কোড | জেমিনি এপিআই |
| সমর্থিত ডেটা প্রকারগুলি | ইনপুট পাঠ্য আউটপুট ছবি |
| টোকেন সীমা [*] | ইনপুট টোকেন সীমা ৪৮০টি টোকেন (টেক্সট) আউটপুট ছবি ১ থেকে ৪ (আল্ট্রা/স্ট্যান্ডার্ড/ফাস্ট) |
| সর্বশেষ আপডেট | জুন ২০২৫ |
ছবি ৩
Imagen 3 মডেলটি বন্ধ করে দেওয়া হয়েছে।