API de Files
Gemini puede procesar varios tipos de datos de entrada, como texto, imágenes y audio, al mismo tiempo.
En esta guía, se muestra cómo trabajar con archivos multimedia usando la API de Files. Las operaciones básicas son las mismas para los archivos de audio, las imágenes, los videos, los documentos y otros tipos de archivos admitidos.
Para obtener orientación sobre las instrucciones de archivos, consulta la sección Guía de instrucciones de archivos.
Subir un archivo
Puedes usar la API de Files para subir un archivo multimedia. Siempre usa la API de Files cuando el tamaño total de la solicitud (incluidos los archivos, la instrucción de texto, las instrucciones del sistema, etcétera) sea superior a 100 MB. En el caso de los archivos PDF, el límite es de 50 MB.
El siguiente código sube un archivo y, luego, lo usa en una llamada a generateContent.
Python
from google import genai
client = genai.Client()
myfile = client.files.upload(file="path/to/sample.mp3")
response = client.models.generate_content(
model="gemini-3.5-flash", contents=["Describe this audio clip", myfile]
)
print(response.text)
JavaScript
import {
GoogleGenAI,
createUserContent,
createPartFromUri,
} from "@google/genai";
const ai = new GoogleGenAI({});
async function main() {
const myfile = await ai.files.upload({
file: "path/to/sample.mp3",
config: { mimeType: "audio/mpeg" },
});
const response = await ai.models.generateContent({
model: "gemini-3.5-flash",
contents: createUserContent([
createPartFromUri(myfile.uri, myfile.mimeType),
"Describe this audio clip",
]),
});
console.log(response.text);
}
await main();
Go
file, err := client.Files.UploadFromPath(ctx, "path/to/sample.mp3", nil)
if err != nil {
log.Fatal(err)
}
defer client.Files.Delete(ctx, file.Name)
resp, err := client.Models.GenerateContent(ctx, "gemini-3.5-flash", []*genai.Content{
{
Parts: []*genai.Part{
genai.NewPartFromFile(*file),
genai.NewPartFromText("Describe this audio clip"),
},
},
}, nil)
if err != nil {
log.Fatal(err)
}
printResponse(resp)
REST
AUDIO_PATH="path/to/sample.mp3"
MIME_TYPE=$(file -b --mime-type "${AUDIO_PATH}")
NUM_BYTES=$(wc -c < "${AUDIO_PATH}")
DISPLAY_NAME=AUDIO
tmp_header_file=upload-header.tmp
# Initial resumable request defining metadata.
# The upload url is in the response headers dump them to a file.
curl "${BASE_URL}/upload/v1beta/files" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-D "${tmp_header_file}" \
-H "X-Goog-Upload-Protocol: resumable" \
-H "X-Goog-Upload-Command: start" \
-H "X-Goog-Upload-Header-Content-Length: ${NUM_BYTES}" \
-H "X-Goog-Upload-Header-Content-Type: ${MIME_TYPE}" \
-H "Content-Type: application/json" \
-d "{'file': {'display_name': '${DISPLAY_NAME}'}}" 2> /dev/null
upload_url=$(grep -i "x-goog-upload-url: " "${tmp_header_file}" | cut -d" " -f2 | tr -d "\r")
rm "${tmp_header_file}"
# Upload the actual bytes.
curl "${upload_url}" \
-H "Content-Length: ${NUM_BYTES}" \
-H "X-Goog-Upload-Offset: 0" \
-H "X-Goog-Upload-Command: upload, finalize" \
--data-binary "@${AUDIO_PATH}" 2> /dev/null > file_info.json
file_uri=$(jq ".file.uri" file_info.json)
echo file_uri=$file_uri
# Now generate content using that file
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.5-flash:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts":[
{"text": "Describe this audio clip"},
{"file_data":{"mime_type": "${MIME_TYPE}", "file_uri": '$file_uri'}}]
}]
}' 2> /dev/null > response.json
cat response.json
echo
jq ".candidates[].content.parts[].text" response.json
Obtén los metadatos de un archivo
Puedes verificar que la API haya almacenado correctamente el archivo subido y obtener sus metadatos llamando a files.get.
Python
from google import genai
client = genai.Client()
myfile = client.files.upload(file='path/to/sample.mp3')
file_name = myfile.name
myfile = client.files.get(name=file_name)
print(myfile)
JavaScript
import {
GoogleGenAI,
} from "@google/genai";
const ai = new GoogleGenAI({});
async function main() {
const myfile = await ai.files.upload({
file: "path/to/sample.mp3",
config: { mimeType: "audio/mpeg" },
});
const fileName = myfile.name;
const fetchedFile = await ai.files.get({ name: fileName });
console.log(fetchedFile);
}
await main();
Go
file, err := client.Files.UploadFromPath(ctx, "path/to/sample.mp3", nil)
if err != nil {
log.Fatal(err)
}
gotFile, err := client.Files.Get(ctx, file.Name)
if err != nil {
log.Fatal(err)
}
fmt.Println("Got file:", gotFile.Name)
REST
# file_info.json was created in the upload example
name=$(jq ".file.name" file_info.json)
# Get the file of interest to check state
curl https://generativelanguage.googleapis.com/v1beta/files/$name \
-H "x-goog-api-key: $GEMINI_API_KEY" > file_info.json
# Print some information about the file you got
name=$(jq ".file.name" file_info.json)
echo name=$name
file_uri=$(jq ".file.uri" file_info.json)
echo file_uri=$file_uri
Enumera los archivos subidos
El siguiente código obtiene una lista de todos los archivos subidos:
Python
from google import genai
client = genai.Client()
print('My files:')
for f in client.files.list():
print(' ', f.name)
JavaScript
import {
GoogleGenAI,
} from "@google/genai";
const ai = new GoogleGenAI({});
async function main() {
const listResponse = await ai.files.list({ config: { pageSize: 10 } });
for await (const file of listResponse) {
console.log(file.name);
}
}
await main();
Go
for file, err := range client.Files.All(ctx) {
if err != nil {
log.Fatal(err)
}
fmt.Println(file.Name)
}
REST
echo "My files: "
curl "https://generativelanguage.googleapis.com/v1beta/files" \
-H "x-goog-api-key: $GEMINI_API_KEY"
Borra archivos subidos
Los archivos se borran automáticamente después de 48 horas. También puedes borrar manualmente un archivo subido:
Python
from google import genai
client = genai.Client()
myfile = client.files.upload(file='path/to/sample.mp3')
client.files.delete(name=myfile.name)
JavaScript
import {
GoogleGenAI,
} from "@google/genai";
const ai = new GoogleGenAI({});
async function main() {
const myfile = await ai.files.upload({
file: "path/to/sample.mp3",
config: { mimeType: "audio/mpeg" },
});
const fileName = myfile.name;
await ai.files.delete({ name: fileName });
}
await main();
Go
file, err := client.Files.UploadFromPath(ctx, "path/to/sample.mp3", nil)
if err != nil {
log.Fatal(err)
}
client.Files.Delete(ctx, file.Name)
REST
curl --request "DELETE" https://generativelanguage.googleapis.com/v1beta/files/$name \
-H "x-goog-api-key: $GEMINI_API_KEY"
Información de uso
Puedes usar la API de Files para subir archivos multimedia y, luego, interactuar con ellos. La API de Files te permite almacenar hasta 20 GB de archivos por proyecto, con un tamaño máximo por archivo de 2 GB. Los archivos se almacenan durante 48 horas. Durante ese tiempo, puedes usar la API para obtener metadatos sobre los archivos, pero no puedes descargarlos. La API de Files está disponible sin costo en todas las regiones en las que está disponible la API de Gemini.
Estrategias de instrucciones de archivos
En esta sección, se proporcionan orientación y prácticas recomendadas para usar archivos multimedia con instrucciones en la API de Gemini.
Poder usar varios tipos de datos en tus instrucciones te brinda más flexibilidad en cuanto a las tareas que puedes abordar con la API de Gemini. Por ejemplo, puedes enviar al modelo una foto de una comida deliciosa y pedirle que escriba un blog breve sobre ella.
| Instrucción | Respuesta |
|
Escribe una entrada de blog breve y atractiva basada en esta foto. Debe incluir una descripción de la comida que aparece en la foto y hablar sobre mi proceso de preparación de comidas. 
|
Preparar las comidas es una excelente manera de ahorrar tiempo y dinero, y también puede ayudarte a comer de forma más saludable. Esta comida es un excelente ejemplo de una comida saludable y deliciosa que se puede preparar con anticipación fácilmente. Esta comida incluye arroz integral, verduras asadas y pollo teriyaki. El arroz integral es un carbohidrato saludable y complejo que te brindará energía sostenida. Las verduras asadas son una excelente manera de obtener la dosis diaria de vitaminas y minerales, y el pollo teriyaki es una opción deliciosa y rica en proteínas. Esta comida también es muy fácil de preparar. Solo tienes que cocinar el arroz integral, asar las verduras y cocinar el pollo teriyaki. Una vez que todo esté cocido, divídelo en recipientes para preparar comidas y guárdalos en el refrigerador. Luego, puedes tomar un recipiente y salir en las mañanas ajetreadas. Si buscas una comida saludable y deliciosa que se pueda preparar con anticipación, esta es una excelente opción. Está repleta de nutrientes y sabor, y seguro te dejará satisfecho. ¡Salud por la preparación de comidas saludables y deliciosas! |
Si tienes problemas para obtener el resultado que deseas a partir de instrucciones que usan archivos multimedia, existen algunas estrategias que pueden ayudarte a obtener los resultados que deseas. En las siguientes secciones, se proporcionan enfoques de diseño y sugerencias para solucionar problemas que te ayudarán a mejorar las instrucciones que usan entradas multimodales.
Para mejorar tus prompts multimodales, sigue estas prácticas recomendadas:
-
Conceptos básicos sobre el diseño de prompts
- Sé específico en tus instrucciones: Crea instrucciones claras y concisas que dejen espacio mínimo para interpretaciones erróneas.
- Agrega algunos ejemplos a tu prompt: Usa ejemplos poco frecuentes para ilustrar lo que quieres lograr.
- Desglosar paso a paso: Divide las tareas complejas en subobjetivos administrables y guiando el modelo a través del proceso.
- Especifica el formato del resultado: En el prompt, solicita que el resultado tenga el formato que deseas, como Markdown, JSON, HTML y más.
- Coloca tu imagen primero para los prompts de una sola imagen: Si bien Gemini puede manejar las entradas de imágenes y texto en cualquier orden, en el caso de los prompts que contienen una sola imagen, podría tener un mejor rendimiento si esa imagen (o video) se coloca antes del prompt de texto. Sin embargo, en el caso de los prompts que requieren que las imágenes estén muy intercaladas con textos para que tengan sentido, usa el orden que sea más natural.
-
Soluciona problemas de tu prompt multimodal
- Si el modelo no extrae información de la parte relevante de la imagen: Agrega pistas sobre los aspectos de la imagen de los que quieres que el prompt extraiga información.
- Si el resultado del modelo es demasiado genérico (no lo suficientemente personalizado para la entrada de imagen o video): Al inicio del prompt, intenta pedirle al modelo que describa las imágenes o el video antes de proporcionar la instrucción de la tarea, o intenta pedirle al modelo que haga referencia a lo que hay en la imagen.
- Para solucionar la parte que falló: Pídele al modelo que describa la imagen o pídele que explique su razonamiento, para medir su comprensión inicial.
- Si el prompt muestra contenido alucinado: Intenta reducir la configuración de la temperatura o pide descripciones más cortas al modelo para que sea menos probable extrapolar detalles adicionales.
- Ajusta los parámetros de muestreo: Experimenta con diferentes opciones de configuración de temperatura y selecciones de Top-K para ajustar la creatividad del modelo.
Proporciona instrucciones específicas
Los prompts tienen más éxito cuando son claros y detallados. Si tienes un resultado específico en mente, es mejor incluir ese requisito en el prompt para asegurarte de obtener el resultado que deseas.
Para esta imagen de un panel de aeropuerto, pedirle al modelo que simplemente “describa esta imagen” podría generar una descripción general. Si necesitas que el modelo analice la hora y la ciudad de la imagen, puedes incluir esa solicitud directamente en tu instrucción.
| Instrucción | Respuesta del modelo |
|---|---|

Describe esta imagen. |
En la imagen, se muestra el panel de llegadas y salidas de un aeropuerto. |
| Prompt actualizado | Respuesta mejorada |
|---|---|
Analiza la hora y la ciudad del panel de aeropuerto que se muestra en esta imagen y crea una lista con esos datos. |
Agrega algunos ejemplos
El modelo Gemini puede aceptar varias entradas, que puede usar como ejemplos para comprender el resultado que deseas. Agregar estos ejemplos puede ayudar a que el modelo identifique los patrones y aplique la relación entre las imágenes y respuestas dadas al ejemplo nuevo. Esto también se conoce como aprendizaje "con varios ejemplos".
En el siguiente ejemplo, el resultado inicial está escrito en forma de oración y también contiene el país (Brasil). Supongamos que deseas obtener el resultado en un formato o estilo diferente y solo quieres la ciudad, no el país. Agregar ejemplos de pocos intentos a tu prompt puede hacer que el modelo responda de la manera que deseas.
| Instrucción | Respuesta del modelo |
|---|---|
 Determina la ciudad junto con el punto de referencia. |
El punto de referencia es la estatua del Cristo Redentor de Río de Janeiro, Brasil. |
| Prompt actualizado | Respuesta mejorada |
|---|---|
|
Determina la ciudad junto con el punto de referencia. 
|
ciudad: Roma, punto de referencia: el Coliseo. |

|
ciudad: Beijing, punto de referencia: la Ciudad Prohibida |
|
|
ciudad: Río de Janeiro, punto de referencia: estatua del Cristo Redentor |
Desglósala paso a paso
Para tareas complejas, como las que requieren comprensión visual y razonamiento, puede ser útil dividir la tarea en pasos más pequeños y sencillos. Como alternativa, también podría ser efectivo si le pides al modelo que "piense paso a paso" en el prompt.
| Instrucción | Respuesta del modelo |
|---|---|

¿Cuándo se me acabará el papel higiénico? |
Pronto, solo te quedan 3 rollos. |
| Prompt actualizado | Respuesta mejorada |
|---|---|
|
|
Los problemas matemáticos y otros tipos de problemas de palabras son excelentes opciones para pedirle al modelo que piense paso a paso.
| Instrucción | Respuesta |
|---|---|
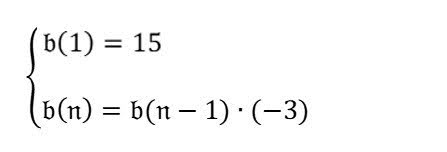
¿Cuál es el cuarto término de la secuencia? |
-135 |
La respuesta del modelo es incorrecta. Algunas formas de mejorar esto son pedirle al modelo que analice el problema antes de responder al prompt.
| Instrucción | Respuesta |
|---|---|
Analiza primero la fórmula de la imagen. Luego, en función de la fórmula, responde “¿Cuál es el cuarto término de la secuencia?”. |
Haz clic para expandir el resultado$$ b(n) = b(n-1) * (-3) $$ $$ b(1) = 15 $$
$$ b(4) = b(4-1) * (-3) $$ $$ b(4) = b(3) * (-3) $$ $$ b(3) = b(3-1) * (-3) $$ $$ b(3) = b(2) * (-3) $$ $$ b(2) = b(2-1) * (-3) $$ $$ b(2) = b(1) * (-3) $$ $$ b(2) = 15 * (-3) $$ $$ b(2) = -45 $$ $$ b(3) = b(2) * (-3) $$ $$ b(3) = -45 * (-3) $$ $$ b(3) = 135 $$ $$ b(4) = b(3) * (-3) $$ $$ b(4) = 135 * (-3) $$ $$ b(4) = -405 $$ Por lo tanto, el cuarto término de la secuencia es -405. |
Esta respuesta del modelo es correcta. Ahora, para que la respuesta sea aún más optimizada, puedes pedirle al modelo que piense paso a paso.
| Prompt actualizado | Respuesta mejorada |
|---|---|
|
¿Cuál es el cuarto término de la secuencia? Piensa paso a paso. |
El primer término es 15. El segundo término es b(1) * (-3) = 15 * (-3) = -45. El tercer término es b(2) * (-3) = -45 * (-3) = 135. El cuarto término es b(3) * (-3) = 135 * (-3) = -405. |
Especifica el formato del resultado
Un problema común es la necesidad de que el resultado del modelo esté en un formato determinado (p.ej., Markdown, JSON, HTML), en especial si el resultado del modelo debe transferirse mediante una tarea descendente. Puedes intentar que el modelo produzca un resultado en ese formato indicándoselo en la instrucción. A continuación, se muestran dos ejemplos:
| Instrucción | Respuesta del modelo |
|---|---|
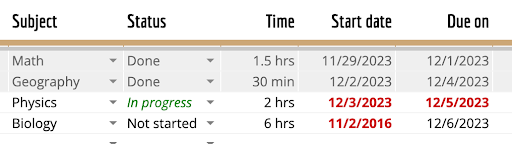
Analiza la tabla en esta imagen en formato Markdown |
| Asignatura | Estado | Tiempo | Fecha de inicio | Fecha de entrega | | ------- | ------ | ---- | ---------- | ------ | | Matemáticas | Listo | 1.5 h | 29/11/2023 | 1/12/2023 | | Geografía | Listo | 30 min | 2/12/2023 | 4/12/2023 | | Física | En curso | 2 h | 3/12/2023 | 5/12/2023 | | Biología | No iniciado | 6 h | 2/11/2016 | 6/12/2023 | |
| Instrucción | Respuesta del modelo |
|---|---|

Proporciona una lista de todos los atributos siguientes: ingredientes, tipo de cocina, vegetariano o no, en formato JSON |
|
Coloca primero la imagen para prompts de una sola imagen
Si bien Gemini puede interpretar la imagen y el texto en cualquier orden dentro de una instrucción, colocar una sola imagen antes de la instrucción de texto puede generar mejores resultados. En las siguientes muestras, notarás que la imagen se coloca primero antes del texto en cada instrucción.
Soluciona los problemas de tu instrucción multimodal
Es posible que debas solucionar los problemas de tu instrucción si no obtienes una respuesta útil. Estas son algunas estrategias que puedes probar.
Si el modelo no extrae información de la parte relevante de la imagen
Para obtener una respuesta más específica, puedes indicar desde qué aspectos de la imagen deseas que la instrucción extraiga información para generar su respuesta.
| Instrucción | Respuesta del modelo |
|---|---|

¿Cuántos días durarán estos pañales para un bebé? |
Los pañales se acabarán en 198 días. |
| Prompt actualizado | Respuesta mejorada |
|---|---|
|
¿Cuánto durarán estos pañales antes de acabarse? Usa el peso que se muestra en la caja para determinar la edad del bebé y usa la cantidad total de pañales que aparece en la caja. Divide la cantidad total por la cantidad de pañales que el bebé usa en un día. |
La caja contiene 198 pañales. La caja indica que los pañales son para niños que pesan entre 10 y 17 kg. Es probable que el niño promedio de este rango de peso tenga entre 1 y 2 años. Por lo general, un niño de 2 años usa 6 pañales por día. Por lo tanto, durarán aproximadamente 33 días (198/6). |
Si el resultado del modelo es demasiado genérico y no se adapta lo suficiente a la entrada de imagen
Para ayudar a que el modelo adapte su respuesta a las imágenes, pídele que las describa antes de realizar su tarea de razonamiento.
| Instrucción | Respuesta del modelo |
|---|---|



¿Qué tienen en común estas imágenes? |
Las cuatro imágenes son ejemplos de fotografías horizontales. |
| Prompt actualizado | Respuesta mejorada |
|---|---|
|
Primero, describe el contenido de cada imagen en detalle. ¿Qué tienen en común estas imágenes? |
En la primera imagen, se muestra a una persona empacando una maleta. La segunda imagen muestra un pasillo vacío en un centro comercial. La tercera imagen muestra un rollo de papel higiénico. La cuarta imagen muestra un mar oscuro y tormentoso. La común entre estas imágenes es que todos son ejemplos de espacios liminales. Los espacios liminales son lugares o situaciones que se encuentran entre otros dos lugares o situaciones. A menudo, se caracterizan por un sentido de incertidumbre o ambigüedad. La primera imagen muestra a la persona entre estar en casa y estar de viaje. La segunda imagen muestra el pasillo entre dos tiendas. La tercera imagen es de papel higiénico, que puede representar un baño. Un baño es un espacio de transición entre el ámbito privado y el público. Es un lugar donde nos preparamos para ir al mundo exterior o para dejarlo. En la cuarta imagen, se muestra el mar entre la calma y la tormenta. Los espacios liminales pueden ser emocionantes e inquietantes. Pueden ser un lugar de nuevos comienzos o de finales. Pueden ser un lugar de reflexión o un lugar de acción. |
También puedes intentar solicitar explícitamente que el modelo haga referencia a lo que hay en la imagen.
| Prompt actualizado | Respuesta mejorada |
|---|---|
|
¿Qué tienen en común estas imágenes? Consulta el contenido de las imágenes en tu respuesta. |
Todas las imágenes están relacionadas con viajes. La primera imagen muestra a una persona empacando una maleta; la segunda, un pasillo vacío en un centro comercial; la tercera imagen, una pila de papel higiénico, y la cuarta imagen, un mar oscuro y tormentoso. Todas estas imágenes están relacionadas con viajes porque son todo lo que las personas necesitan o usan cuando viajan. La primera imagen muestra a una persona empacando una maleta, que es lo que suelen hacer las personas cuando van a realizar un viaje. La segunda muestra un pasillo vacío en un centro comercial, que es un lugar donde las personas suelen ir a comprar artículos para sus viajes. La tercera imagen muestra una pila de papel higiénico, algo que la gente suele usar cuando viaja. La cuarta imagen muestra un mar oscuro y tormentoso, algo que las personas suelen encontrar cuando viajan. |
Las mismas sugerencias funcionan para obtener un resultado creativo a partir de imágenes. En el siguiente ejemplo con el conejo, pedirle explícitamente al modelo que incluya aspectos de la imagen puede mejorar el resultado.
| Instrucción | Respuesta del modelo |
|---|---|

¿Puedes escribirme un poema sobre esta imagen? |
Conejito, tan suave y marrón, Mordisqueas el pasto, tan verde y suave, |
| Prompt actualizado | Respuesta mejorada |
|---|---|
|
¿Puedes escribirme un poema descriptivo y dramático sobre esta imagen y también incluir la ubicación? |
Conejito sobre el verde, ¿Es el océano azul Pequeño conejo, dime la verdad, Quizás sea la enormidad de todo, Conejito, me pregunto qué soñarás, Sin importar cómo sea, conejito |
Soluciona problemas de qué parte del prompt falló
Puede ser difícil saber si un prompt falló porque el modelo no entendió la imagen en primer lugar, o si la entendió, pero no realizó los pasos de razonamiento correctos después. Para distinguir los motivos, pídele al modelo que describa el contenido de la imagen.
En el siguiente ejemplo, si el modelo responde con un bocadillo que parece extraño en combinación con el té (p.ej., palomitas de maíz), el primer paso para solucionar el problema es determinar si el modelo reconoció correctamente que la imagen contiene té.
| Instrucción | Prompt para solucionar problemas |
|---|---|

¿Qué tentempié puedo preparar en 1 minuto que se combine bien con esto? |
Describe el contenido de esta imagen. |
Otra estrategia es pedirle al modelo que explique su razonamiento. Eso puede ayudarte a limitar qué parte del razonamiento falló, si la hubiera.
| Instrucción | Prompt para solucionar problemas |
|---|---|
|
¿Qué tentempié puedo preparar en 1 minuto que se combine bien con esto? |
¿Qué tentempié puedo preparar en 1 minuto que se combine bien con esto? Explica por qué. |
¿Qué sigue?
- Intenta escribir tus propias instrucciones multimodales con Google AI Studio.
- Si quieres obtener información para usar la API de Gemini Files para subir archivos multimedia y agregarlos a tus instrucciones, consulta las guías de Vision, Audio y Procesamiento de documentos.
- Para obtener más orientación sobre el diseño de instrucciones, como el ajuste de los parámetros de muestreo, consulta la página Estrategias de instrucciones.