Gemini Robotics-ER 1.6 es un modelo de lenguaje de visión (VLM) que aporta las capacidades de agente de Gemini a la robótica. Está diseñado para el razonamiento avanzado en el mundo físico, lo que permite a los robots interpretar datos visuales complejos, realizar razonamiento espacial y planificar acciones a partir de comandos en lenguaje natural.
Ten en cuenta que, si usabas Gemini Robotics-ER 1.5, puedes comenzar a usar el modelo 1.6 reemplazando el nombre del modelo de model="gemini-robotics-er-1.5-preview" a model="gemini-robotics-er-1.6-preview" en la llamada a la API.
Funciones y beneficios clave:
- Mayor autonomía: Los robots pueden razonar, adaptarse y responder a los cambios en entornos abiertos.
- Interacción en lenguaje natural: Facilita el uso de los robots, ya que permite asignar tareas complejas con lenguaje natural.
- Organización de tareas: Descompone los comandos de lenguaje natural en subtareas y se integra con los controladores y comportamientos existentes del robot para completar tareas a largo plazo.
- Capacidades versátiles: Localiza e identifica objetos, comprende las relaciones entre objetos, planifica agarres y trayectorias, e interpreta escenas dinámicas.
En este documento, se describe qué hace el modelo y se muestran varios ejemplos que destacan sus capacidades de agente.
Si quieres comenzar de inmediato, puedes probar el modelo en Google AI Studio.
Seguridad
Si bien Gemini Robotics-ER 1.6 se creó pensando en la seguridad, es tu responsabilidad mantener un entorno seguro alrededor del robot. Los modelos de IA generativa pueden cometer errores, y los robots físicos pueden causar daños. La seguridad es una prioridad, y hacer que los modelos de IA generativa sean seguros cuando se usan con la robótica del mundo real es un área activa y fundamental de nuestra investigación. Para obtener más información, visita la página de seguridad de robótica de Google DeepMind.
Primeros pasos: Cómo encontrar objetos en una escena
En el siguiente ejemplo, se muestra un caso de uso común de la robótica. Muestra cómo pasar una imagen y una instrucción de texto al modelo con el método generateContent para obtener una lista de objetos identificados con sus puntos 2D correspondientes.
El modelo devuelve puntos para los elementos que identificó en una imagen, y muestra sus etiquetas y coordenadas 2D normalizadas.
Puedes usar este resultado con una API de robótica o llamar a un modelo de acción-lenguaje-visión (VLA) o cualquier otra función definida por el usuario de terceros para generar acciones que un robot pueda realizar.
Python
from google import genai
from google.genai import types
PROMPT = """
Point to no more than 10 items in the image. The label returned
should be an identifying name for the object detected.
The answer should follow the json format: [{"point": <point>,
"label": <label1>}, ...]. The points are in [y, x] format
normalized to 0-1000.
"""
client = genai.Client()
# Load your image
with open("my-image.png", 'rb') as f:
image_bytes = f.read()
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/png',
),
PROMPT
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
REST
# First, ensure you have the image file locally.
# Encode the image to base64
IMAGE_BASE64=$(base64 -w 0 my-image.png)
curl -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-robotics-er-1.6-preview:generateContent \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [
{
"parts": [
{
"inlineData": {
"mimeType": "image/png",
"data": "'"${IMAGE_BASE64}"'"
}
},
{
"text": "Point to no more than 10 items in the image. The label returned should be an identifying name for the object detected. The answer should follow the json format: [{\"point\": [y, x], \"label\": <label1>}, ...]. The points are in [y, x] format normalized to 0-1000."
}
]
}
],
"generationConfig": {
"temperature": 0.5,
"thinkingConfig": {
"thinkingBudget": 0
}
}
}'
El resultado será un array JSON que contiene objetos, cada uno con un point (coordenadas [y, x] normalizadas) y un label que identifica el objeto.
JSON
[
{"point": [376, 508], "label": "small banana"},
{"point": [287, 609], "label": "larger banana"},
{"point": [223, 303], "label": "pink starfruit"},
{"point": [435, 172], "label": "paper bag"},
{"point": [270, 786], "label": "green plastic bowl"},
{"point": [488, 775], "label": "metal measuring cup"},
{"point": [673, 580], "label": "dark blue bowl"},
{"point": [471, 353], "label": "light blue bowl"},
{"point": [492, 497], "label": "bread"},
{"point": [525, 429], "label": "lime"}
]
En la siguiente imagen, se muestra un ejemplo de cómo se pueden mostrar estos puntos:

Cómo funciona
Gemini Robotics-ER 1.6 permite que tus robots contextualicen y trabajen en el mundo físico con comprensión espacial. Toma imágenes, videos y audio como entrada, y usa instrucciones en lenguaje natural para hacer lo siguiente:
- Comprender los objetos y el contexto de la escena: Identifica objetos y explica su relación con la escena, incluidas sus posibilidades de interacción.
- Comprender las instrucciones de las tareas: Interpreta las tareas que se indican en lenguaje natural, como "encuentra la banana".
- Razonamiento espacial y temporal: Comprender las secuencias de acciones y cómo los objetos interactúan con una escena a lo largo del tiempo
- Proporciona resultados estructurados: Muestra coordenadas (puntos o cuadros delimitadores) que representan las ubicaciones de los objetos.
Esto permite que los robots "vean" y "comprendan" su entorno de forma programática.
Gemini Robotics-ER 1.6 también es agentic, lo que significa que puede desglosar tareas complejas (como "poner la manzana en el tazón") en subtareas para coordinar tareas de largo plazo:
- Secuenciación de subtareas: Descompone los comandos en una secuencia lógica de pasos.
- Llamadas a funciones o ejecución de código: Ejecuta pasos llamando a tus funciones o herramientas de robot existentes, o bien ejecutando código generado.
Obtén más información sobre cómo funciona la llamada a funciones con Gemini en la página Llamada a funciones.
Cómo usar el presupuesto de pensamiento con Gemini Robotics-ER 1.6
Gemini Robotics-ER 1.6 tiene un presupuesto de razonamiento flexible que te permite controlar las compensaciones entre la latencia y la precisión. Para las tareas de comprensión espacial, como la detección de objetos, el modelo puede lograr un alto rendimiento con un presupuesto de pensamiento pequeño. Las tareas de razonamiento más complejas, como el conteo y la estimación de peso, se benefician de un mayor presupuesto de pensamiento. Esto te permite equilibrar la necesidad de respuestas de baja latencia con resultados de alta precisión para tareas más desafiantes.
Para obtener más información sobre los presupuestos de pensamiento, consulta la página de capacidades principales de Pensamiento.
Razonamiento espacial estándar
En los siguientes ejemplos, se muestran tareas de percepción robótica y razonamiento espacial con instrucciones en lenguaje natural, desde señalar y encontrar objetos en una imagen hasta planificar trayectorias. Para simplificar, los fragmentos de código de estos ejemplos se redujeron para mostrar solo la instrucción y la llamada a la API de generate_content.
Puedes encontrar el código ejecutable completo y ejemplos adicionales en el recetario de robótica.
Cómo señalar objetos
Señalar y encontrar objetos en imágenes o fotogramas de video es un caso de uso común para los modelos de lenguaje y visión (VLMs) en robótica. En el siguiente ejemplo, se le pide al modelo que encuentre objetos específicos dentro de una imagen y muestre sus coordenadas.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
queries = [
"bread",
"starfruit",
"banana",
]
prompt = f"""
Get all points matching the following objects: {', '.join(queries)}. The
label returned should be an identifying name for the object detected.
The answer should follow the json format:
[{{"point": , "label": }}, ...]. The points are in
[y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
El resultado sería similar al ejemplo de introducción, un JSON que contiene las coordenadas de los objetos encontrados y sus etiquetas.
[
{"point": [671, 317], "label": "bread"},
{"point": [738, 307], "label": "bread"},
{"point": [702, 237], "label": "bread"},
{"point": [629, 307], "label": "bread"},
{"point": [833, 800], "label": "bread"},
{"point": [609, 663], "label": "banana"},
{"point": [770, 483], "label": "starfruit"}
]

Usa la siguiente instrucción para solicitarle al modelo que interprete categorías abstractas, como "fruta", en lugar de objetos específicos y que ubique todas las instancias en la imagen.
Python
prompt = f"""
Get all points for fruit. The label returned should be an identifying
name for the object detected.
""" + """The answer should follow the json format:
[{"point": <point>, "label": <label1>}, ...]. The points are in
[y, x] format normalized to 0-1000."""
Visita la página Comprensión de imágenes para conocer otras técnicas de procesamiento de imágenes.
Cómo hacer un seguimiento de objetos en un video
Gemini Robotics-ER 1.6 también puede analizar fotogramas de video para hacer un seguimiento de los objetos a lo largo del tiempo. Consulta Entradas de video para obtener una lista de los formatos de video compatibles.
A continuación, se muestra la instrucción básica que se usa para encontrar objetos específicos en cada fotograma que analiza el modelo:
Python
# Define the objects to find
queries = [
"pen (on desk)",
"pen (in robot hand)",
"laptop (opened)",
"laptop (closed)",
]
base_prompt = f"""
Point to the following objects in the provided image: {', '.join(queries)}.
The answer should follow the json format:
[{{"point": , "label": }}, ...].
The points are in [y, x] format normalized to 0-1000.
If no objects are found, return an empty JSON list [].
"""
El resultado muestra un lápiz y una laptop que se rastrean en los fotogramas del video.
![]()
Para ver el código ejecutable completo, consulta el recetario de robótica.
Detección de objetos y cuadros delimitadores
Además de puntos únicos, el modelo también puede devolver cuadros de límite 2D, lo que proporciona una región rectangular que encierra un objeto.
En este ejemplo, se solicitan cuadros de límite 2D para objetos identificables sobre una mesa. Se le indica al modelo que limite el resultado a 25 objetos y que nombre varias instancias de forma única.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Return bounding boxes as a JSON array with labels. Never return masks
or code fencing. Limit to 25 objects. Include as many objects as you
can identify on the table.
If an object is present multiple times, name them according to their
unique characteristic (colors, size, position, unique characteristics, etc..).
The format should be as follows: [{"box_2d": [ymin, xmin, ymax, xmax],
"label": <label for the object>}] normalized to 0-1000. The values in
box_2d must only be integers
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
A continuación, se muestran las casillas que devolvió el modelo.
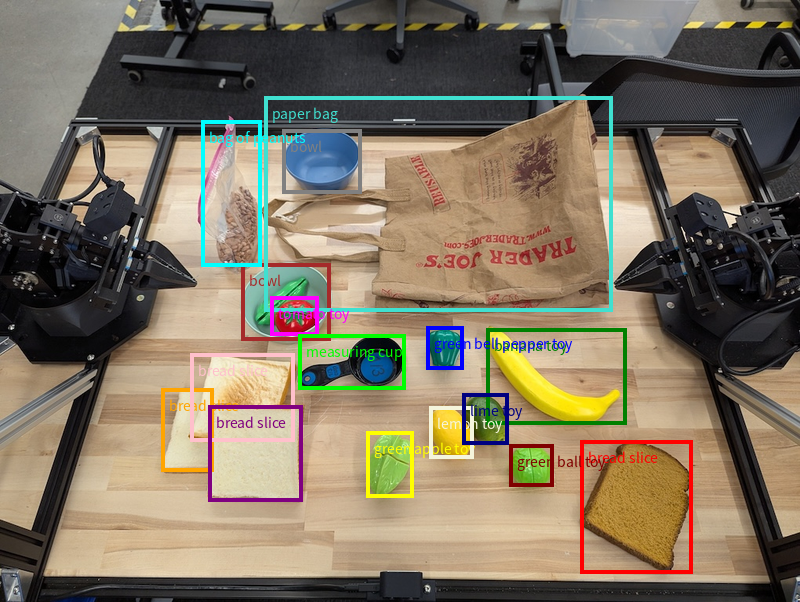
Para ver el código ejecutable completo, consulta el recetario de robótica. La página Comprensión de imágenes también incluye ejemplos adicionales de tareas visuales, como la detección de objetos y ejemplos de cuadros delimitadores.
Trayectorias
Gemini Robotics-ER 1.6 puede generar secuencias de puntos que definen una trayectoria, lo que resulta útil para guiar el movimiento del robot.
En este ejemplo, se solicita una trayectoria para mover un bolígrafo rojo a un organizador, incluido el punto de partida y una serie de puntos intermedios.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
points_data = []
prompt = """
Place a point on the red pen, then 15 points for the trajectory of
moving the red pen to the top of the organizer on the left.
The points should be labeled by order of the trajectory, from '0'
(start point at left hand) to <n> (final point)
The answer should follow the json format:
[{"point": <point>, "label": <label1>}, ...].
The points are in [y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
)
)
print(image_response.text)
La respuesta es un conjunto de coordenadas que describen la trayectoria del camino que debe seguir el lápiz rojo para completar la tarea de moverlo sobre el organizador:
[
{"point": [550, 610], "label": "0"},
{"point": [500, 600], "label": "1"},
{"point": [450, 590], "label": "2"},
{"point": [400, 580], "label": "3"},
{"point": [350, 550], "label": "4"},
{"point": [300, 520], "label": "5"},
{"point": [250, 490], "label": "6"},
{"point": [200, 460], "label": "7"},
{"point": [180, 430], "label": "8"},
{"point": [160, 400], "label": "9"},
{"point": [140, 370], "label": "10"},
{"point": [120, 340], "label": "11"},
{"point": [110, 320], "label": "12"},
{"point": [105, 310], "label": "13"},
{"point": [100, 305], "label": "14"},
{"point": [100, 300], "label": "15"}
]

Capacidades de agente
En los siguientes ejemplos, se demuestra el razonamiento robótico avanzado con las capacidades de agente del modelo, específicamente la ejecución de código. En estas situaciones, el modelo puede decidir escribir y ejecutar código de Python para manipular imágenes (por ejemplo, acercar, recortar o rotar) para resolver ambigüedades o mejorar la precisión antes de responder.
Detección de objetos (zoom y recorte)
En el siguiente ejemplo, se muestra cómo usar la ejecución de código para acercar y recortar una imagen y obtener una vista más clara cuando se detectan objetos y se devuelven cuadros delimitadores.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('sorting.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
Return JSON in the format {label: val, y: val, x: val, y2: val, x2: val} for
the compostable objects in this scene. Please Zoom and crop the image for a
clearer view. Return an annotated image of the final result with the bounding
boxes drawn on it to the API caller as a part of your process.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
El resultado del modelo sería similar al siguiente:
[
{"label": "compostable", "y": 256, "x": 482, "y2": 295, "x2": 546},
{"label": "compostable", "y": 317, "x": 478, "y2": 350, "x2": 542},
{"label": "compostable", "y": 586, "x": 556, "y2": 668, "x2": 595},
{"label": "compostable", "y": 463, "x": 669, "y2": 511, "x2": 718},
{"label": "compostable", "y": 178, "x": 565, "y2": 250, "x2": 609}
]
A continuación, se muestran las casillas que devolvió el modelo.

Lectura de un medidor analógico y aplicación de lógica
En el siguiente ejemplo, se muestra cómo usar el modelo para leer un medidor analógico y realizar cálculos de tiempo. Utiliza una instrucción del sistema para aplicar un resultado en formato JSON.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('clock.jpg', 'rb') as f:
image_bytes = f.read()
q_time = """
Tell me what the value is. Please respond in the following JSON format:\n {\n "hours": X,\n "minutes": Y,\n}. Zoom in or crop as necessary to confirm location of the clock hands.
"""
system_instruction = "Be precise. When JSON is requested, reply with ONLY that JSON (no preface, no code block)."
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
system_instruction + " " + q_time
],
config = types.GenerateContentConfig(
temperature=1.0,
)
)
print(response.text)
A continuación, se muestra un ejemplo de entrada de imagen.

El resultado del modelo sería similar al siguiente:
Time Response: {
"hours": 12,
"minutes": 44
}
Cómo medir fluidos en un recipiente
En el siguiente ejemplo, se muestra cómo usar la ejecución de código para leer un medidor y calcular el nivel de líquido como porcentaje.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('meter.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
How full is the meter of liquid?
To read it,
1) Find the points for the top of the sight window, bottom of the sight window and the liquid level, formatted as [y, x] with values ranging from 0-1000;
2) Use math to determine the liquid level as a percentage;
3) Output "Answer: ??" on a separate line, where ?? is a number without % or unit.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
A continuación, se muestra la imagen de entrada ampliada.

Cómo leer las marcas en una placa de circuito
En el siguiente ejemplo, se muestra cómo usar la ejecución de código para leer texto en un chip de placa de circuito, lo que permite que el modelo acerque, recorte y rote la imagen según sea necesario.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('circuit_board.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = "What is the number on the ESMT chip? Zoom, crop, and rotate if needed."
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
A continuación, se muestra la imagen de entrada ampliada.

Anotación de imágenes
En el siguiente ejemplo, se muestra cómo usar la ejecución de código para anotar una imagen (p.ej., dibujar flechas para indicar instrucciones de descarte) y devolver la imagen modificada.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('sorting.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
Look at this image and return it as an annotated version using arrows of
different colors to represent which items should go in which bins for
disposal. You must return the final image to the API caller.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
A continuación, se muestra un ejemplo de entrada de imagen.

El resultado del modelo sería similar al siguiente:
The annotated image shows the suggested disposal locations for the items on the table:
- **Green bin (Compost/Organic)**: Green chili, red chili, grapes, and cherries.
- **Blue bin (Recycling)**: Yellow crushed can and plastic container.
- **Black bin (Trash)**: Chocolate bar wrapper, Welch's packet, and white tissue.
Organización
Gemini Robotics-ER 1.6 puede realizar planificación de tareas y razonamiento espacial de nivel superior, inferir acciones o identificar ubicaciones óptimas en función de la comprensión contextual para coordinar tareas a largo plazo.
Cómo hacer espacio para una laptop
En este ejemplo, se muestra cómo Gemini Robotics-ER puede razonar sobre un espacio. La instrucción le pide al modelo que identifique qué objeto se debe mover para crear espacio para otro elemento.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Point to the object that I need to remove to make room for my laptop
The answer should follow the json format: [{"point": <point>,
"label": <label1>}, ...]. The points are in [y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
La respuesta contiene una coordenada 2D del objeto que responde la pregunta del usuario, en este caso, el objeto que se debe mover para dejar espacio para una laptop.
[
{"point": [672, 301], "label": "The object that I need to remove to make room for my laptop"}
]

Cómo preparar un almuerzo
El modelo también puede proporcionar instrucciones para tareas de varios pasos y señalar los objetos relevantes para cada paso. En este ejemplo, se muestra cómo el modelo planifica una serie de pasos para empacar una bolsa de almuerzo.
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-of-lunch.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Explain how to pack the lunch box and lunch bag. Point to each
object that you refer to. Each point should be in the format:
[{"point": [y, x], "label": }], where the coordinates are
normalized between 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
La respuesta a esta instrucción es un conjunto de instrucciones paso a paso sobre cómo empacar una bolsa de almuerzo a partir de la entrada de imagen.
Imagen de entrada

Salida del modelo
Based on the image, here is a plan to pack the lunch box and lunch bag:
1. **Pack the fruit into the lunch box.** Place the [apple](apple), [banana](banana), [red grapes](red grapes), and [green grapes](green grapes) into the [blue lunch box](blue lunch box).
2. **Add the spoon to the lunch box.** Put the [blue spoon](blue spoon) inside the lunch box as well.
3. **Close the lunch box.** Secure the lid on the [blue lunch box](blue lunch box).
4. **Place the lunch box inside the lunch bag.** Put the closed [blue lunch box](blue lunch box) into the [brown lunch bag](brown lunch bag).
5. **Pack the remaining items into the lunch bag.** Place the [blue snack bar](blue snack bar) and the [brown snack bar](brown snack bar) into the [brown lunch bag](brown lunch bag).
Here is the list of objects and their locations:
* [{"point": [899, 440], "label": "apple"}]
* [{"point": [814, 363], "label": "banana"}]
* [{"point": [727, 470], "label": "red grapes"}]
* [{"point": [675, 608], "label": "green grapes"}]
* [{"point": [706, 529], "label": "blue lunch box"}]
* [{"point": [864, 517], "label": "blue spoon"}]
* [{"point": [499, 401], "label": "blue snack bar"}]
* [{"point": [614, 705], "label": "brown snack bar"}]
* [{"point": [448, 501], "label": "brown lunch bag"}]
Cómo llamar a una API de robot personalizada
En este ejemplo, se muestra la organización de tareas con una API de robot personalizada. Presenta una API simulada diseñada para una operación de selección y colocación. La tarea consiste en tomar un bloque azul y colocarlo en un tazón naranja:

Al igual que en los otros ejemplos de esta página, el código ejecutable completo está disponible en el recetario de robótica.
El primer paso es ubicar ambos elementos con la siguiente instrucción:
Python
prompt = """
Locate and point to the blue block and the orange bowl. The label
returned should be an identifying name for the object detected.
The answer should follow the json format: [{"point": <point>, "label": <label1>}, ...].
The points are in [y, x] format normalized to 0-1000.
"""
La respuesta del modelo incluye las coordenadas normalizadas del bloque y el recipiente:
[
{"point": [389, 252], "label": "orange bowl"},
{"point": [727, 659], "label": "blue block"}
]
En este ejemplo, se usa la siguiente API de robot simulado:
Python
def move(x, y, high):
print(f"moving to coordinates: {x}, {y}, {15 if high else 5}")
def setGripperState(opened):
print("Opening gripper" if opened else "Closing gripper")
def returnToOrigin():
print("Returning to origin pose")
El siguiente paso es llamar a una secuencia de funciones de la API con la lógica necesaria para ejecutar la acción. La siguiente instrucción incluye una descripción de la API del robot que el modelo debe usar cuando coordine esta tarea.
Python
prompt = f"""
You are a robotic arm with six degrees-of-freedom. You have the
following functions available to you:
def move(x, y, high):
# moves the arm to the given coordinates. The boolean value 'high' set
to True means the robot arm should be lifted above the scene for
avoiding obstacles during motion. 'high' set to False means the robot
arm should have the gripper placed on the surface for interacting with
objects.
def setGripperState(opened):
# Opens the gripper if opened set to true, otherwise closes the gripper
def returnToOrigin():
# Returns the robot to an initial state. Should be called as a cleanup
operation.
The origin point for calculating the moves is at normalized point
y={robot_origin_y}, x={robot_origin_x}. Use this as the new (0,0) for
calculating moves, allowing x and y to be negative.
Perform a pick and place operation where you pick up the blue block at
normalized coordinates ({block_x}, {block_y}) (relative coordinates:
{block_relative_x}, {block_relative_y}) and place it into the orange
bowl at normalized coordinates ({bowl_x}, {bowl_y})
(relative coordinates: {bowl_relative_x}, {bowl_relative_y}).
Provide the sequence of function calls as a JSON list of objects, where
each object has a "function" key (the function name) and an "args" key
(a list of arguments for the function).
Also, include your reasoning before the JSON output.
For example:
Reasoning: To pick up the block, I will first move the arm to a high
position above the block, open the gripper, move down to the block,
close the gripper, lift the arm, move to a high position above the bowl,
move down to the bowl, open the gripper, and then lift the arm back to
a high position.
"""
A continuación, se muestra un posible resultado del modelo basado en la instrucción y la API del robot simulado. El resultado incluye el proceso de pensamiento del modelo y las tareas que planificó como resultado. También muestra el resultado de las llamadas a funciones del robot que el modelo secuenció.
Reasoning: To perform the pick and place operation, I will first move the
robotic arm to a high position above the blue block to ensure clearance. Then, I
will open the gripper in preparation for grasping. Next, I will lower the arm to
the surface level to position the gripper around the block and close the gripper
to secure it. After picking up the block, I will lift the arm to clear the
surface and move towards the orange bowl, maintaining a high position to avoid
collisions. Once positioned above the bowl, I will lower the arm to place the
block inside. I will then open the gripper to release the block. Finally, I will
lift the arm out of the bowl and call `returnToOrigin` to reset the robot's
state.
[
{
"function": "move",
"args": [
163,
427,
true
]
},
{
"function": "setGripperState",
"args": [
true
]
},
{
"function": "move",
"args": [
163,
427,
false
]
},
{
"function": "setGripperState",
"args": [
false
]
},
{
"function": "move",
"args": [
163,
427,
true
]
},
{
"function": "move",
"args": [
-247,
90,
true
]
},
{
"function": "move",
"args": [
-247,
90,
false
]
},
{
"function": "setGripperState",
"args": [
true
]
},
{
"function": "move",
"args": [
-247,
90,
true
]
},
{
"function": "returnToOrigin",
"args": []
}
]
Executing Function Calls:
moving to coordinates: 163, 427, 15
Opening gripper
moving to coordinates: 163, 427, 5
Closing gripper
moving to coordinates: 163, 427, 15
moving to coordinates: -247, 90, 15
moving to coordinates: -247, 90, 5
Opening gripper
moving to coordinates: -247, 90, 15
Returning to origin pose
Prácticas recomendadas
Para optimizar el rendimiento y la precisión de tus aplicaciones de robótica, es fundamental que comprendas cómo interactuar con el modelo de Gemini de manera eficaz. En esta sección, se describen las prácticas recomendadas y las estrategias clave para crear instrucciones, manejar datos visuales y estructurar tareas con el objetivo de obtener los resultados más confiables.
Usa un lenguaje claro y sencillo.
Adopta el lenguaje natural: El modelo de Gemini está diseñado para comprender el lenguaje natural y conversacional. Estructura tus instrucciones de forma semánticamente clara y que refleje cómo una persona daría instrucciones de forma natural.
Usa terminología cotidiana: Opta por un lenguaje común y cotidiano en lugar de jerga técnica o especializada. Si el modelo no responde como se espera a un término en particular, intenta reformularlo con un sinónimo más común.
Optimiza la entrada visual.
Acercar para ver detalles: Cuando trabajes con objetos pequeños o difíciles de discernir en una toma más amplia, usa una función de cuadro delimitador para aislar el objeto de interés. Luego, puedes recortar la imagen según esta selección y enviar la nueva imagen enfocada al modelo para obtener un análisis más detallado.
Experimenta con la iluminación y el color: La percepción del modelo puede verse afectada por condiciones de iluminación difíciles y un contraste de color deficiente.
Desglosa los problemas complejos en pasos más pequeños. Si abordas cada paso más pequeño de forma individual, puedes guiar al modelo hacia un resultado más preciso y exitoso.
Mejora la precisión a través del consenso. Para las tareas que requieren un alto grado de precisión, puedes consultar el modelo varias veces con la misma instrucción. Al promediar los resultados devueltos, puedes llegar a un "consenso" que suele ser más preciso y confiable.
Limitaciones
Ten en cuenta las siguientes limitaciones cuando desarrolles con Gemini Robotics-ER 1.6:
- Estado de la versión preliminar: Actualmente, el modelo se encuentra en versión preliminar. Las APIs y las capacidades pueden cambiar, y es posible que no sean adecuadas para aplicaciones críticas para la producción sin pruebas exhaustivas.
- Latencia: Las consultas complejas, las entradas de alta resolución o los
thinking_budgetextensos pueden aumentar los tiempos de procesamiento. - Alucinaciones: Al igual que todos los modelos de lenguaje grandes, Gemini Robotics-ER 1.6 puede "alucinar" ocasionalmente o proporcionar información incorrecta, especialmente para instrucciones ambiguas o entradas fuera de la distribución.
- Dependencia de la calidad de la instrucción: La calidad del resultado del modelo depende en gran medida de la claridad y la especificidad de la instrucción de entrada. Las instrucciones vagas o mal estructuradas pueden generar resultados subóptimos.
- Costo de procesamiento: Ejecutar el modelo, en especial con entradas de video o un valor de
thinking_budgetalto, consume recursos de procesamiento y genera costos. Consulta la página Thinking para obtener más detalles. - Tipos de entrada: Consulta los siguientes temas para obtener detalles sobre las limitaciones de cada modo.
Aviso de privacidad
Reconoces que los modelos a los que se hace referencia en este documento (los "Modelos de Robótica") aprovechan los datos de audio y video para operar y mover tu hardware de acuerdo con tus instrucciones. Por lo tanto, es posible que opere los Modelos Robóticos de manera tal que estos recopilen datos de personas identificables, como datos de voz, imágenes y similitud ("Datos Personales"). Si decides operar los Modelos Robóticos de una manera que recopile Datos Personales, aceptas que no permitirás que ninguna persona identificable interactúe con los Modelos Robóticos ni esté presente en el área que los rodea, a menos que y hasta que se les haya notificado de manera suficiente a esas personas identificables y hayan dado su consentimiento para que Google pueda proporcionar y usar sus Datos Personales según se describe en las Condiciones del Servicio Adicionales de la API de Gemini que se encuentran en https://ai.google.dev/gemini-api/terms (las "Condiciones"), incluso de acuerdo con la sección titulada "Cómo usa Google tus datos". Te asegurarás de que dicho aviso permita la recopilación y el uso de Datos Personales según se describe en las Condiciones, y realizarás esfuerzos comercialmente razonables para minimizar la recopilación y distribución de Datos Personales con técnicas como el desenfoque de rostros y el funcionamiento de los Modelos de Robótica en áreas que no contengan personas identificables en la medida en que sea posible.
Precios
Para obtener información detallada sobre los precios y las regiones disponibles, consulta la página de precios.
Versiones del modelo
Robotics-ER 1.6 (vista previa)
| Propiedad | Descripción |
|---|---|
| Código del modelo | gemini-robotics-er-1.6-preview |
| Tipos de datos admitidos |
Entradas Texto, imágenes, video y audio Resultado Texto |
| Límites de tokens[*] |
Límite de tokens de entrada 131,072 Límite de tokens de salida 65,536 |
| Funciones | No compatible Admitido Admitido Admitido Admitido Admitido Fundamentación con Google Maps Admitido No compatible No compatible Fundamentación con la Búsqueda Admitido Admitido Admitido Admitido |
| Opciones de consumo |
Admitido Admitido Admitido |
| Versiones |
|
| Última actualización | Diciembre de 2025 |
| Fecha límite de conocimiento | Enero de 2025 |
Próximos pasos
- Explora otras capacidades y sigue experimentando con diferentes instrucciones y entradas para descubrir más aplicaciones de Gemini Robotics-ER 1.6. Consulta el Colab de introducción a la robótica para obtener más ejemplos.
- Obtén información sobre cómo se crearon los modelos de Gemini Robotics teniendo en cuenta la seguridad en la página de seguridad de robótica de Google DeepMind.
- Lee sobre las actualizaciones más recientes de los modelos de Gemini Robotics en la página de destino de Gemini Robotics.