Gemini Robotics-ER 1.6 是視覺語言模型 (VLM),可將 Gemini 的代理功能帶入機器人領域。這項技術專為實體世界中的進階推論而設計,可讓機器人解讀複雜的視覺資料、執行空間推論,並根據自然語言指令規劃動作。
請注意,如果您使用 Gemini Robotics-ER 1.5,只要在 API 呼叫中將模型名稱從 model="gemini-robotics-er-1.5-preview" 替換為 model="gemini-robotics-er-1.6-preview",即可開始使用 1.6 模型。
主要功能和優點:
- 提升自主性:機器人可以推理、適應開放式環境的變化並做出回應。
- 自然語言互動:讓使用者能以自然語言指派複雜工作,輕鬆操作機器人。
- 工作調度:將自然語言指令分解為子工作,並與現有的機器人控制器和行為整合,以完成長期任務。
- 多功能:可定位及辨識物體、瞭解物體關係、規劃抓取和軌跡,以及解讀動態場景。
本文說明模型的功能,並提供幾個範例,讓您瞭解模型的代理能力。
如要立即開始使用,可以在 Google AI Studio 中試用模型。
安全性
雖然 Gemini Robotics-ER 1.6 的設計以安全為考量,但您仍有責任確保機器人周圍環境安全無虞。生成式 AI 模型可能會出錯,實體機器人則可能造成損壞。安全是我們的首要考量,因此我們積極研究如何確保生成式 AI 模型與實體機器人搭配使用時的安全。如要瞭解詳情,請前往 Google DeepMind 機器人安全頁面。
開始使用:尋找場景中的物件
以下範例說明常見的機器人應用情境。這個範例說明如何使用 generateContent 方法,將圖片和文字提示詞傳遞至模型,以取得已識別物件的清單,以及對應的 2D 點。模型會傳回圖片中識別項目的點,並傳回這些項目的標準化 2D 座標和標籤。
您可以將這項輸出內容搭配機器人 API 使用,或呼叫視覺語言動作 (VLA) 模型或任何其他第三方使用者定義函式,為機器人產生要執行的動作。
Python
from google import genai
from google.genai import types
PROMPT = """
Point to no more than 10 items in the image. The label returned
should be an identifying name for the object detected.
The answer should follow the json format: [{"point": <point>,
"label": <label1>}, ...]. The points are in [y, x] format
normalized to 0-1000.
"""
client = genai.Client()
# Load your image
with open("my-image.png", 'rb') as f:
image_bytes = f.read()
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/png',
),
PROMPT
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
REST
# First, ensure you have the image file locally.
# Encode the image to base64
IMAGE_BASE64=$(base64 -w 0 my-image.png)
curl -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/gemini-robotics-er-1.6-preview:generateContent \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [
{
"parts": [
{
"inlineData": {
"mimeType": "image/png",
"data": "'"${IMAGE_BASE64}"'"
}
},
{
"text": "Point to no more than 10 items in the image. The label returned should be an identifying name for the object detected. The answer should follow the json format: [{\"point\": [y, x], \"label\": <label1>}, ...]. The points are in [y, x] format normalized to 0-1000."
}
]
}
],
"generationConfig": {
"temperature": 0.5,
"thinkingConfig": {
"thinkingBudget": 0
}
}
}'
輸出內容會是包含物件的 JSON 陣列,每個物件都有 point (標準化 [y, x] 座標) 和用於識別物件的 label。
JSON
[
{"point": [376, 508], "label": "small banana"},
{"point": [287, 609], "label": "larger banana"},
{"point": [223, 303], "label": "pink starfruit"},
{"point": [435, 172], "label": "paper bag"},
{"point": [270, 786], "label": "green plastic bowl"},
{"point": [488, 775], "label": "metal measuring cup"},
{"point": [673, 580], "label": "dark blue bowl"},
{"point": [471, 353], "label": "light blue bowl"},
{"point": [492, 497], "label": "bread"},
{"point": [525, 429], "label": "lime"}
]
下圖顯示這些點的範例:

運作方式
Gemini Robotics-ER 1.6 可讓機器人運用空間理解能力,在實體世界中瞭解情境並執行工作。這項功能會接收圖片/影片/音訊輸入內容和自然語言提示,然後:
- 瞭解物件和場景內容:識別物件,並瞭解物件與場景的關係,包括物件的用途。
- 瞭解工作指令:解讀以自然語言給定的工作,例如「找出香蕉」。
- 從空間和時間角度進行推理:瞭解動作序列,以及物體如何隨時間與場景互動。
- 提供結構化輸出內容:傳回代表物件位置的座標 (點或定界框)。
這項技術可讓機器人透過程式輔助「看見」及「瞭解」周遭環境。
Gemini Robotics-ER 1.6 也是代理式模型,因此能將複雜工作 (例如「把蘋果放進碗裡」) 分解為子工作,以協調長期任務:
- 子任務排序:將指令分解為邏輯步驟序列。
- 函式呼叫/執行程式碼:呼叫現有的機器人函式/工具或執行產生的程式碼,藉此執行步驟。
如要進一步瞭解 Gemini 函式呼叫的運作方式,請參閱函式呼叫頁面。
搭配 Gemini Robotics-ER 1.6 使用思考預算
Gemini Robotics-ER 1.6 具有彈性的思考預算,可讓您控管延遲與準確度之間的取捨。對於物件偵測等空間理解工作,模型可以運用少量思考預算,達到高成效。對於計數和重量估算等較複雜的推論工作,較高的思考預算有助於提升效能。這樣一來,您就能在需要低延遲回應的同時,兼顧高準確度的結果,以利處理更具挑戰性的工作。
如要進一步瞭解思考預算,請參閱「思考」核心功能頁面。
標準空間推理
以下範例說明如何使用自然語言提示詞,執行機器人感知和空間推理工作,包括在圖片中指出及尋找物件,以及規劃路徑。為簡化起見,這些範例中的程式碼片段只會顯示提示和對 generate_content API 的呼叫。
如需完整的可執行程式碼和更多範例,請參閱「機器人食譜」。
指向物件
在機器人技術中,視覺與語言模型 (VLM) 的常見用途是在圖片或影片影格中指出並尋找物件。以下範例要求模型找出圖片中的特定物件,並傳回座標。
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
queries = [
"bread",
"starfruit",
"banana",
]
prompt = f"""
Get all points matching the following objects: {', '.join(queries)}. The
label returned should be an identifying name for the object detected.
The answer should follow the json format:
[{{"point": , "label": }}, ...]. The points are in
[y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
輸出內容會與入門範例類似,是包含所找到物件座標和標籤的 JSON。
[
{"point": [671, 317], "label": "bread"},
{"point": [738, 307], "label": "bread"},
{"point": [702, 237], "label": "bread"},
{"point": [629, 307], "label": "bread"},
{"point": [833, 800], "label": "bread"},
{"point": [609, 663], "label": "banana"},
{"point": [770, 483], "label": "starfruit"}
]

使用下列提示要求模型解讀抽象類別 (例如「水果」),而非特定物件,並找出圖片中的所有例項。
Python
prompt = f"""
Get all points for fruit. The label returned should be an identifying
name for the object detected.
""" + """The answer should follow the json format:
[{"point": <point>, "label": <label1>}, ...]. The points are in
[y, x] format normalized to 0-1000."""
如需其他圖像處理技術,請參閱圖像解讀頁面。
追蹤影片中的物件
Gemini Robotics-ER 1.6 也能分析影片影格,追蹤一段時間內的物體。如需支援的影片格式清單,請參閱「影片輸入」。
以下是基本提示,用於在模型分析的每個影格中尋找特定物件:
Python
# Define the objects to find
queries = [
"pen (on desk)",
"pen (in robot hand)",
"laptop (opened)",
"laptop (closed)",
]
base_prompt = f"""
Point to the following objects in the provided image: {', '.join(queries)}.
The answer should follow the json format:
[{{"point": , "label": }}, ...].
The points are in [y, x] format normalized to 0-1000.
If no objects are found, return an empty JSON list [].
"""
輸出結果會顯示在影片影格中追蹤的筆和筆電。
![]()
如需完整的可執行程式碼,請參閱機器人食譜。
物件偵測和定界框
除了單一點之外,模型也會傳回 2D 邊界框,提供包含物件的矩形區域。
這個範例會要求取得桌上可識別物件的 2D 邊界框。模型會收到指令,將輸出內容限制為 25 個物件,並為多個執行個體命名專屬名稱。
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Return bounding boxes as a JSON array with labels. Never return masks
or code fencing. Limit to 25 objects. Include as many objects as you
can identify on the table.
If an object is present multiple times, name them according to their
unique characteristic (colors, size, position, unique characteristics, etc..).
The format should be as follows: [{"box_2d": [ymin, xmin, ymax, xmax],
"label": <label for the object>}] normalized to 0-1000. The values in
box_2d must only be integers
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
以下顯示模型傳回的方塊。
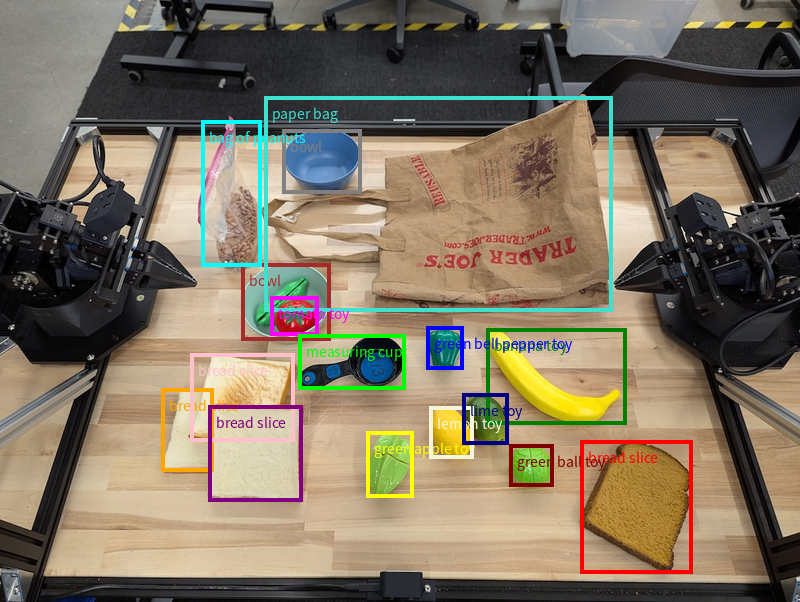
如需完整的可執行程式碼,請參閱「機器人食譜」。「圖像解讀」頁面也提供其他視覺任務範例,例如物件偵測和定界框範例。
軌跡
Gemini Robotics-ER 1.6 可生成定義軌跡的點序列,有助於引導機器人移動。
這個範例會要求將紅筆移動到收納盒的軌跡,包括起點和一系列中間點。
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
points_data = []
prompt = """
Place a point on the red pen, then 15 points for the trajectory of
moving the red pen to the top of the organizer on the left.
The points should be labeled by order of the trajectory, from '0'
(start point at left hand) to <n> (final point)
The answer should follow the json format:
[{"point": <point>, "label": <label1>}, ...].
The points are in [y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
)
)
print(image_response.text)
回應是一組座標,說明紅筆應遵循的路徑軌跡,以完成將紅筆移到收納盒頂端的工作:
[
{"point": [550, 610], "label": "0"},
{"point": [500, 600], "label": "1"},
{"point": [450, 590], "label": "2"},
{"point": [400, 580], "label": "3"},
{"point": [350, 550], "label": "4"},
{"point": [300, 520], "label": "5"},
{"point": [250, 490], "label": "6"},
{"point": [200, 460], "label": "7"},
{"point": [180, 430], "label": "8"},
{"point": [160, 400], "label": "9"},
{"point": [140, 370], "label": "10"},
{"point": [120, 340], "label": "11"},
{"point": [110, 320], "label": "12"},
{"point": [105, 310], "label": "13"},
{"point": [100, 305], "label": "14"},
{"point": [100, 300], "label": "15"}
]

代理能力
下列範例展示如何使用模型代理程式功能 (特別是程式碼執行),進行進階機器人推理。在這些情況下,模型可以決定編寫及執行 Python 程式碼來處理圖片 (例如放大、裁剪或旋轉),以解決模糊不清的問題或提高準確度,然後再回答問題。
物件偵測 (縮放及裁剪)
以下範例說明如何使用執行程式碼功能,在偵測物件及傳回定界框時,縮放及裁剪圖片,以便更清楚地查看。
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('sorting.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
Return JSON in the format {label: val, y: val, x: val, y2: val, x2: val} for
the compostable objects in this scene. Please Zoom and crop the image for a
clearer view. Return an annotated image of the final result with the bounding
boxes drawn on it to the API caller as a part of your process.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
模型輸出內容會與下列內容類似:
[
{"label": "compostable", "y": 256, "x": 482, "y2": 295, "x2": 546},
{"label": "compostable", "y": 317, "x": 478, "y2": 350, "x2": 542},
{"label": "compostable", "y": 586, "x": 556, "y2": 668, "x2": 595},
{"label": "compostable", "y": 463, "x": 669, "y2": 511, "x2": 718},
{"label": "compostable", "y": 178, "x": 565, "y2": 250, "x2": 609}
]
以下顯示模型傳回的方塊。

讀取類比儀表並套用邏輯
以下範例說明如何使用模型讀取類比儀表,並執行時間計算。並使用系統指令強制輸出 JSON 格式。
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('clock.jpg', 'rb') as f:
image_bytes = f.read()
q_time = """
Tell me what the value is. Please respond in the following JSON format:\n {\n "hours": X,\n "minutes": Y,\n}. Zoom in or crop as necessary to confirm location of the clock hands.
"""
system_instruction = "Be precise. When JSON is requested, reply with ONLY that JSON (no preface, no code block)."
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
system_instruction + " " + q_time
],
config = types.GenerateContentConfig(
temperature=1.0,
)
)
print(response.text)
以下是圖片輸入內容範例。

模型輸出內容會與下列內容類似:
Time Response: {
"hours": 12,
"minutes": 44
}
測量容器中的液體
以下範例說明如何使用程式碼執行作業,讀取電錶並計算液位百分比。
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('meter.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
How full is the meter of liquid?
To read it,
1) Find the points for the top of the sight window, bottom of the sight window and the liquid level, formatted as [y, x] with values ranging from 0-1000;
2) Use math to determine the liquid level as a percentage;
3) Output "Answer: ??" on a separate line, where ?? is a number without % or unit.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
以下是輸入內容的放大圖片。

解讀電路板上的標記
以下範例說明如何使用程式碼執行功能讀取電路板晶片上的文字,讓模型視需要縮放、裁剪及旋轉圖片。
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('circuit_board.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = "What is the number on the ESMT chip? Zoom, crop, and rotate if needed."
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
以下是輸入內容的放大圖片。

圖片註解
以下範例說明如何使用執行程式碼功能為圖片加上註解 (例如繪製箭頭表示處理說明),並傳回修改後的圖片。
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image
with open('sorting.jpeg', 'rb') as f:
image_bytes = f.read()
prompt = """
Look at this image and return it as an annotated version using arrows of
different colors to represent which items should go in which bins for
disposal. You must return the final image to the API caller.
"""
response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
tools=[types.Tool(code_execution=types.ToolCodeExecution)],
)
)
print(response.text)
以下是圖片輸入內容範例。

模型輸出內容會與下列內容類似:
The annotated image shows the suggested disposal locations for the items on the table:
- **Green bin (Compost/Organic)**: Green chili, red chili, grapes, and cherries.
- **Blue bin (Recycling)**: Yellow crushed can and plastic container.
- **Black bin (Trash)**: Chocolate bar wrapper, Welch's packet, and white tissue.
自動化調度管理
Gemini Robotics-ER 1.6 可執行任務規劃和更高階的空間推論,根據脈絡理解推斷動作或找出最佳位置,協調長期任務。
為筆電預留空間
這個範例顯示 Gemini Robotics-ER 如何推論空間。提示會要求模型找出需要移動的物件,以便為其他項目騰出空間。
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-with-objects.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Point to the object that I need to remove to make room for my laptop
The answer should follow the json format: [{"point": <point>,
"label": <label1>}, ...]. The points are in [y, x] format normalized to 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
回覆內容包含可回答使用者問題的物體 2D 座標,在本例中,該物體應移動,為筆電騰出空間。
[
{"point": [672, 301], "label": "The object that I need to remove to make room for my laptop"}
]

準備午餐
模型也能提供多步驟工作的操作說明,並指出每個步驟的相關物件。這個範例說明模型如何規劃一系列步驟來打包午餐袋。
Python
from google import genai
from google.genai import types
client = genai.Client()
# Load your image and set up your prompt
with open('path/to/image-of-lunch.jpg', 'rb') as f:
image_bytes = f.read()
prompt = """
Explain how to pack the lunch box and lunch bag. Point to each
object that you refer to. Each point should be in the format:
[{"point": [y, x], "label": }], where the coordinates are
normalized between 0-1000.
"""
image_response = client.models.generate_content(
model="gemini-robotics-er-1.6-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type='image/jpeg',
),
prompt
],
config = types.GenerateContentConfig(
temperature=1.0,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
)
print(image_response.text)
這個提示詞的回覆內容是一組逐步說明,教導如何根據輸入的圖片包裝午餐袋。
輸入圖片

模型輸出
Based on the image, here is a plan to pack the lunch box and lunch bag:
1. **Pack the fruit into the lunch box.** Place the [apple](apple), [banana](banana), [red grapes](red grapes), and [green grapes](green grapes) into the [blue lunch box](blue lunch box).
2. **Add the spoon to the lunch box.** Put the [blue spoon](blue spoon) inside the lunch box as well.
3. **Close the lunch box.** Secure the lid on the [blue lunch box](blue lunch box).
4. **Place the lunch box inside the lunch bag.** Put the closed [blue lunch box](blue lunch box) into the [brown lunch bag](brown lunch bag).
5. **Pack the remaining items into the lunch bag.** Place the [blue snack bar](blue snack bar) and the [brown snack bar](brown snack bar) into the [brown lunch bag](brown lunch bag).
Here is the list of objects and their locations:
* [{"point": [899, 440], "label": "apple"}]
* [{"point": [814, 363], "label": "banana"}]
* [{"point": [727, 470], "label": "red grapes"}]
* [{"point": [675, 608], "label": "green grapes"}]
* [{"point": [706, 529], "label": "blue lunch box"}]
* [{"point": [864, 517], "label": "blue spoon"}]
* [{"point": [499, 401], "label": "blue snack bar"}]
* [{"point": [614, 705], "label": "brown snack bar"}]
* [{"point": [448, 501], "label": "brown lunch bag"}]
呼叫自訂機器人 API
這個範例說明如何使用自訂機器人 API 編排工作。這個 API 專為取放作業設計,這項工作的目標是拿起藍色積木,然後放入橘色碗中:

與本頁的其他範例類似,完整的可執行程式碼位於 Robotics cookbook。
首先,請使用下列提示詞找出這兩項物品:
Python
prompt = """
Locate and point to the blue block and the orange bowl. The label
returned should be an identifying name for the object detected.
The answer should follow the json format: [{"point": <point>, "label": <label1>}, ...].
The points are in [y, x] format normalized to 0-1000.
"""
模型回應會包含區塊和碗的標準化座標:
[
{"point": [389, 252], "label": "orange bowl"},
{"point": [727, 659], "label": "blue block"}
]
本範例使用下列模擬機器人 API:
Python
def move(x, y, high):
print(f"moving to coordinates: {x}, {y}, {15 if high else 5}")
def setGripperState(opened):
print("Opening gripper" if opened else "Closing gripper")
def returnToOrigin():
print("Returning to origin pose")
下一步是呼叫一系列 API 函式,並使用必要邏輯執行動作。下列提示包含機器人 API 的說明,模型應在協調這項工作時使用。
Python
prompt = f"""
You are a robotic arm with six degrees-of-freedom. You have the
following functions available to you:
def move(x, y, high):
# moves the arm to the given coordinates. The boolean value 'high' set
to True means the robot arm should be lifted above the scene for
avoiding obstacles during motion. 'high' set to False means the robot
arm should have the gripper placed on the surface for interacting with
objects.
def setGripperState(opened):
# Opens the gripper if opened set to true, otherwise closes the gripper
def returnToOrigin():
# Returns the robot to an initial state. Should be called as a cleanup
operation.
The origin point for calculating the moves is at normalized point
y={robot_origin_y}, x={robot_origin_x}. Use this as the new (0,0) for
calculating moves, allowing x and y to be negative.
Perform a pick and place operation where you pick up the blue block at
normalized coordinates ({block_x}, {block_y}) (relative coordinates:
{block_relative_x}, {block_relative_y}) and place it into the orange
bowl at normalized coordinates ({bowl_x}, {bowl_y})
(relative coordinates: {bowl_relative_x}, {bowl_relative_y}).
Provide the sequence of function calls as a JSON list of objects, where
each object has a "function" key (the function name) and an "args" key
(a list of arguments for the function).
Also, include your reasoning before the JSON output.
For example:
Reasoning: To pick up the block, I will first move the arm to a high
position above the block, open the gripper, move down to the block,
close the gripper, lift the arm, move to a high position above the bowl,
move down to the bowl, open the gripper, and then lift the arm back to
a high position.
"""
以下是根據提示和模擬機器人 API,模型可能產生的輸出內容。輸出內容包括模型思考過程,以及因此規劃的任務。此外,也會顯示模型依序執行的機器人函式呼叫輸出內容。
Reasoning: To perform the pick and place operation, I will first move the
robotic arm to a high position above the blue block to ensure clearance. Then, I
will open the gripper in preparation for grasping. Next, I will lower the arm to
the surface level to position the gripper around the block and close the gripper
to secure it. After picking up the block, I will lift the arm to clear the
surface and move towards the orange bowl, maintaining a high position to avoid
collisions. Once positioned above the bowl, I will lower the arm to place the
block inside. I will then open the gripper to release the block. Finally, I will
lift the arm out of the bowl and call `returnToOrigin` to reset the robot's
state.
[
{
"function": "move",
"args": [
163,
427,
true
]
},
{
"function": "setGripperState",
"args": [
true
]
},
{
"function": "move",
"args": [
163,
427,
false
]
},
{
"function": "setGripperState",
"args": [
false
]
},
{
"function": "move",
"args": [
163,
427,
true
]
},
{
"function": "move",
"args": [
-247,
90,
true
]
},
{
"function": "move",
"args": [
-247,
90,
false
]
},
{
"function": "setGripperState",
"args": [
true
]
},
{
"function": "move",
"args": [
-247,
90,
true
]
},
{
"function": "returnToOrigin",
"args": []
}
]
Executing Function Calls:
moving to coordinates: 163, 427, 15
Opening gripper
moving to coordinates: 163, 427, 5
Closing gripper
moving to coordinates: 163, 427, 15
moving to coordinates: -247, 90, 15
moving to coordinates: -247, 90, 5
Opening gripper
moving to coordinates: -247, 90, 15
Returning to origin pose
最佳做法
如要提升機器人應用程式的效能和準確率,請務必瞭解如何有效與 Gemini 模型互動。本節將說明撰寫提示、處理視覺資料和建構工作流程的最佳做法和重要策略,協助您獲得最可靠的結果。
使用淺顯易懂的文字/語言,
使用自然語言:Gemini 模型可理解自然對話語言。請以語意清楚的方式建構提示,並模擬人類自然下達指令的方式。
使用日常用語:選擇使用常見的日常用語,而非技術或專業術語。如果模型對特定字詞的回應不如預期,請嘗試使用更常見的同義字重新措辭。
最佳化視覺輸入內容。
放大檢視細節:處理小型或難以辨識的物件時,請使用定界框函式,將感興趣的物件獨立出來。接著,你可以將圖片裁剪成所選範圍,然後將新圖片傳送給模型,進行更詳細的分析。
嘗試調整光線和色彩:光線不佳和色彩對比度不足可能會影響模型的感知能力。
將複雜問題細分為較小的步驟。逐一處理每個較小的步驟,引導模型得出更精確的結果。
透過共識提高準確度。對於需要高度精確的任務,您可以多次使用相同提示查詢模型。將傳回的結果取平均值,即可得出「共識」,這通常會更準確可靠。
限制
使用 Gemini Robotics-ER 1.6 開發時,請注意下列限制:
- 預覽狀態:模型目前處於預覽狀態。API 和功能可能會變更,且未經過全面測試,因此可能不適合用於對生產環境至關重要的應用程式。
- 延遲:複雜的查詢、高解析度輸入內容或大量
thinking_budget可能會導致處理時間增加。 - 幻覺:如同所有大型語言模型,Gemini Robotics-ER 1.6 有時也會產生「幻覺」或提供不正確的資訊,尤其是針對模稜兩可的提示或超出分布範圍的輸入內容。
- 取決於提示品質:模型輸出內容的品質高度取決於輸入提示的清晰度和具體程度。模糊不清或結構不良的提示可能會導致結果不盡理想。
- 運算成本:執行模型 (尤其是使用影片輸入內容或高
thinking_budget時) 會消耗運算資源並產生費用。詳情請參閱「思考」頁面。 - 輸入類型:如要瞭解各模式的限制,請參閱下列主題。
隱私權聲明
您瞭解本文件提及的模型 (以下稱「機器人模型」) 會運用影片和音訊資料,根據您的指示操作及移動硬體。因此,您可能會操作機器人模型,讓模型收集可識別身分者的資料,例如語音、圖像和肖像資料 (「個人資料」)。如果您選擇以會收集個人資料的方式操作機器人模型,您同意不會允許任何可識別身分的人與機器人模型互動或出現在機器人模型周圍區域,除非且直到您已充分通知這些可識別身分的人,並取得他們同意,瞭解 Google 可能會根據 https://ai.google.dev/gemini-api/terms (以下簡稱「條款」) 的 Gemini API 附加服務條款提供及使用他們的個人資料,包括「Google 如何使用您的資料」一節所述。您應確保這類通知允許收集及使用《條款》所述的個人資料,並盡可能運用商業上合理的努力,透過臉部模糊處理等技術,以及在不含可識別身分人員的區域操作機器人模型,盡量減少個人資料的收集和散布。
定價
如需價格和適用區域的詳細資訊,請參閱定價頁面。
模型版本
Robotics-ER 1.6 預先發布版
| 屬性 | 說明 |
|---|---|
| 模型代碼 | gemini-robotics-er-1.6-preview |
| 支援的資料類型 |
輸入裝置 文字、圖片、影片、音訊 輸出內容 文字 |
| 代幣限制[*] |
輸入權杖限制 131,072 輸出詞元限制 65,536 |
| 功能 | 不支援 支援 支援 支援 支援 支援 支援 不支援 不支援 支援 支援 支援 支援 |
| 計費方案 |
支援 支援 支援 |
| 個版本 |
|
| 最新更新 | 2025 年 12 月 |
| 知識截點 | 2025 年 1 月 |
後續步驟
- 探索其他功能,並持續嘗試不同的提示和輸入內容,發掘 Gemini Robotics-ER 1.6 的更多應用方式。如需更多範例,請參閱 Robotics 入門 colab。
- 如要瞭解 Gemini Robotics 模型如何將安全防護納入設計考量,請前往 Google DeepMind 機器人安全防護頁面。
- 如要瞭解 Gemini Robotics 模型的最新消息,請前往 Gemini Robotics 登陸頁面。