

המשימה MediaPipe Pose Landmarker מאפשרת לזהות ציוני דרך של גופים אנושיים בתמונה או בסרטון. אפשר להשתמש במשימה הזו כדי לזהות מיקומי גוף מרכזיים, לנתח את היציבה ולסווג תנועות. במשימה הזו נעשה שימוש במודלים של למידת מכונה (ML) שפועלים עם תמונות או סרטונים בודדים. הפלט של המשימה כולל ציוני דרך של תנוחת הגוף בקואורדינטות של התמונה ובקואורדינטות תלת-ממדיות של העולם.
תחילת העבודה
כדי להתחיל להשתמש במשימה הזו, פועלים לפי מדריך ההטמעה של פלטפורמת היעד. המדריכים הספציפיים לפלטפורמות האלה כוללים הנחיות להטמעה בסיסית של המשימה הזו, כולל מודל מומלץ ודוגמת קוד עם אפשרויות ההגדרה המומלצות:
- Android – דוגמה לקוד – מדריך
- Python – קוד לדוגמה – מדריך
- אינטרנט – דוגמה לקוד – מדריך
פרטי המשימה
בקטע הזה מוסבר על היכולות, הקלט, הפלט והאפשרויות להגדרה של המשימה הזו.
תכונות
- עיבוד תמונות קלט – העיבוד כולל סיבוב תמונות, שינוי גודל, נורמליזציה והמרה של מרחב צבעים.
- סף ניקוד – סינון התוצאות על סמך ציונים של תחזיות.
| קלט של משימות | פלט של משימות |
|---|---|
ה-Pose Landmarker מקבל קלט מאחד מסוגי הנתונים הבאים:
|
התוצאות של Pose Landmarker הן:
|
אפשרויות הגדרה
למשימה הזו יש את אפשרויות ההגדרה הבאות:
| שם האפשרות | תיאור | טווח ערכים | ערך ברירת מחדל |
|---|---|---|---|
running_mode |
הגדרת מצב ההפעלה של המשימה. יש שלושה מצבים: IMAGE: המצב להזנת תמונה אחת. VIDEO: המצב של פריימים מפוענחים של סרטון. LIVE_STREAM: המצב של סטרימינג בשידור חי של נתוני קלט, למשל ממצלמה. במצב הזה, צריך להפעיל את resultListener כדי להגדיר מאזין שיקבל את התוצאות באופן אסינכרוני. |
{IMAGE, VIDEO, LIVE_STREAM} |
IMAGE |
num_poses |
המספר המקסימלי של תנוחות שאפשר לזהות באמצעות התכונה Pose Landmarker. | Integer > 0 |
1 |
min_pose_detection_confidence |
דירוג האמון המינימלי שדרוש כדי שהזיהוי של התנוחה יחשב כהצלחה. | Float [0.0,1.0] |
0.5 |
min_pose_presence_confidence |
דירוג האמון המינימלי של דירוג נוכחות התנוחה בזיהוי ציוני ציון התנוחה. | Float [0.0,1.0] |
0.5 |
min_tracking_confidence |
דירוג האמון המינימלי שדרוש כדי שהמעקב אחר התנוחה ייחשבו כסתיים. | Float [0.0,1.0] |
0.5 |
output_segmentation_masks |
האם התכונה Pose Landmarker מפיקה מסכת פילוח לתנוחה שזוהתה. | Boolean |
False |
result_callback |
מגדיר את מאזין התוצאות לקבל את תוצאות ה-landmarker באופן אסינכרוני כש-Pose Landmarker נמצא במצב של שידור חי.
אפשר להשתמש בה רק כשמצב ההפעלה מוגדר כ-LIVE_STREAM |
ResultListener |
N/A |
דגמים
התכונה 'זיהוי ציוני דרך בתנוחה' משתמשת בסדרה של מודלים כדי לחזות ציוני דרך בתנוחה. המודל הראשון מזהה נוכחות של גופים אנושיים בתוך מסגרת התמונה, והמודל השני מאתר נקודות ציון בגוף.
הדגמים הבאים נארזים יחד בחבילת מודלים שניתן להורדה:
- מודל לזיהוי תנוחות: מזהה נוכחות של גופים באמצעות כמה נקודות ציון מרכזיות של תנוחות.
- מודל של ציון מיקום בתנוחה: מוסיפים מיפוי מלא של התנוחה. המודל מניב אומדן של 33 נקודות ציון תלת-ממדיות של תנוחה.
החבילה הזו משתמשת ברשת עצבית קונבולוציונית שדומה ל-MobileNetV2, והיא מותאמת לאפליקציות כושר במכשיר שפועלות בזמן אמת. בגרסה הזו של המודל BlazePose נעשה שימוש ב-GHUM, צינור עיבוד נתונים ליצירת מודלים תלת-ממדיים של צורות אנושיות, כדי להעריך את תנוחת הגוף המלאה בתלת-ממד של אדם בתמונות או בסרטונים.
| חבילת מודלים | צורת הקלט | סוג הנתונים | כרטיסי מודל | גרסאות |
|---|---|---|---|---|
| סימון נקודות ציון של תנוחות (גרסה רגילה) | גלאי תנוחות: 224 x 224 x 3 זיהוי נקודות ציון בתנוחה: 256 x 256 x 3 |
float 16 | info | חדש |
| סימון של תנוחה (מלא) | גלאי תנוחות: 224 x 224 x 3 זיהוי נקודות ציון בתנוחה: 256 x 256 x 3 |
float 16 | info | חדש |
| סימון נקודות ציון של תנוחות (כבד) | גלאי תנוחות: 224 x 224 x 3 סימון תנוחות: 256 x 256 x 3 |
float 16 | info | חדש |
מודל של 'סימון נקודות עניין בתנוחה'
המודל של ציון הדרך של התנוחה עוקב אחרי 33 מיקומים של ציוני דרך בגוף, שמייצגים את המיקום המשוער של חלקי הגוף הבאים:
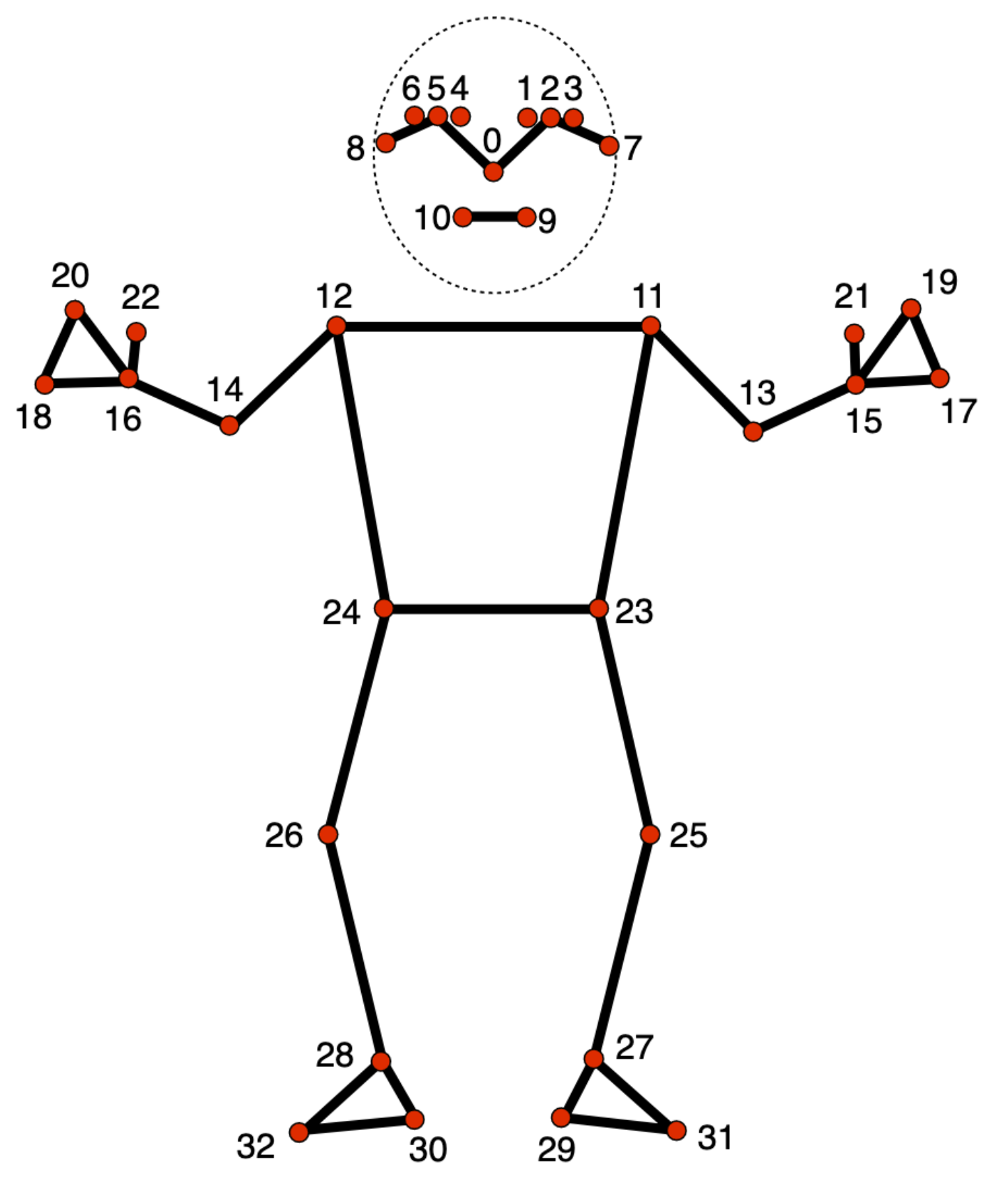
0 - nose
1 - left eye (inner)
2 - left eye
3 - left eye (outer)
4 - right eye (inner)
5 - right eye
6 - right eye (outer)
7 - left ear
8 - right ear
9 - mouth (left)
10 - mouth (right)
11 - left shoulder
12 - right shoulder
13 - left elbow
14 - right elbow
15 - left wrist
16 - right wrist
17 - left pinky
18 - right pinky
19 - left index
20 - right index
21 - left thumb
22 - right thumb
23 - left hip
24 - right hip
25 - left knee
26 - right knee
27 - left ankle
28 - right ankle
29 - left heel
30 - right heel
31 - left foot index
32 - right foot index
פלט המודל מכיל גם קואורדינטות מנורמלות (Landmarks) וגם קואורדינטות בעולם (WorldLandmarks) לכל ציון דרך.