
7 novembre 2024
Optimiser les assistants de codage IA avec le contexte long des modèles Gemini

La génération et la compréhension de code sont l'une des frontières les plus intéressantes de l'application des fenêtres de contexte longues. Les grands ensembles de code nécessitent une compréhension approfondie des relations et des dépendances complexes, ce que les modèles d'IA traditionnels ont du mal à saisir. En augmentant la quantité de code avec de grandes fenêtres de contexte, nous pouvons atteindre un nouveau niveau de précision et d'utilité dans la génération et la compréhension du code.
Nous avons collaboré avec Sourcegraph, les créateurs de l'assistant de programmation Cody AI qui prend en charge les LLM tels que Gemini 1.5 Pro et Flash, pour explorer le potentiel des fenêtres de contexte longues dans des scénarios de programmation concrets. Sourcegraph se concentre sur l'intégration de la recherche et de l'intelligence de code dans la génération de code par IA. L'entreprise a déployé Cody avec succès auprès d'entreprises disposant de bases de code volumineuses et complexes, telles que Palo Alto Networks et Leidos. Elle était donc le partenaire idéal pour cette exploration.
Approche et résultats de Sourcegraph
Sourcegraph a comparé les performances de Cody avec une fenêtre de contexte d'un million de jetons (à l'aide de Gemini 1.5 Flash de Google) à celles de sa version de production. Cette comparaison directe leur a permis d'isoler les avantages du contexte élargi. Ils se sont concentrés sur les questions techniques, une tâche essentielle pour les développeurs qui travaillent avec de grandes bases de code. Ils ont utilisé un ensemble de données de questions difficiles qui nécessitaient une compréhension approfondie du code.
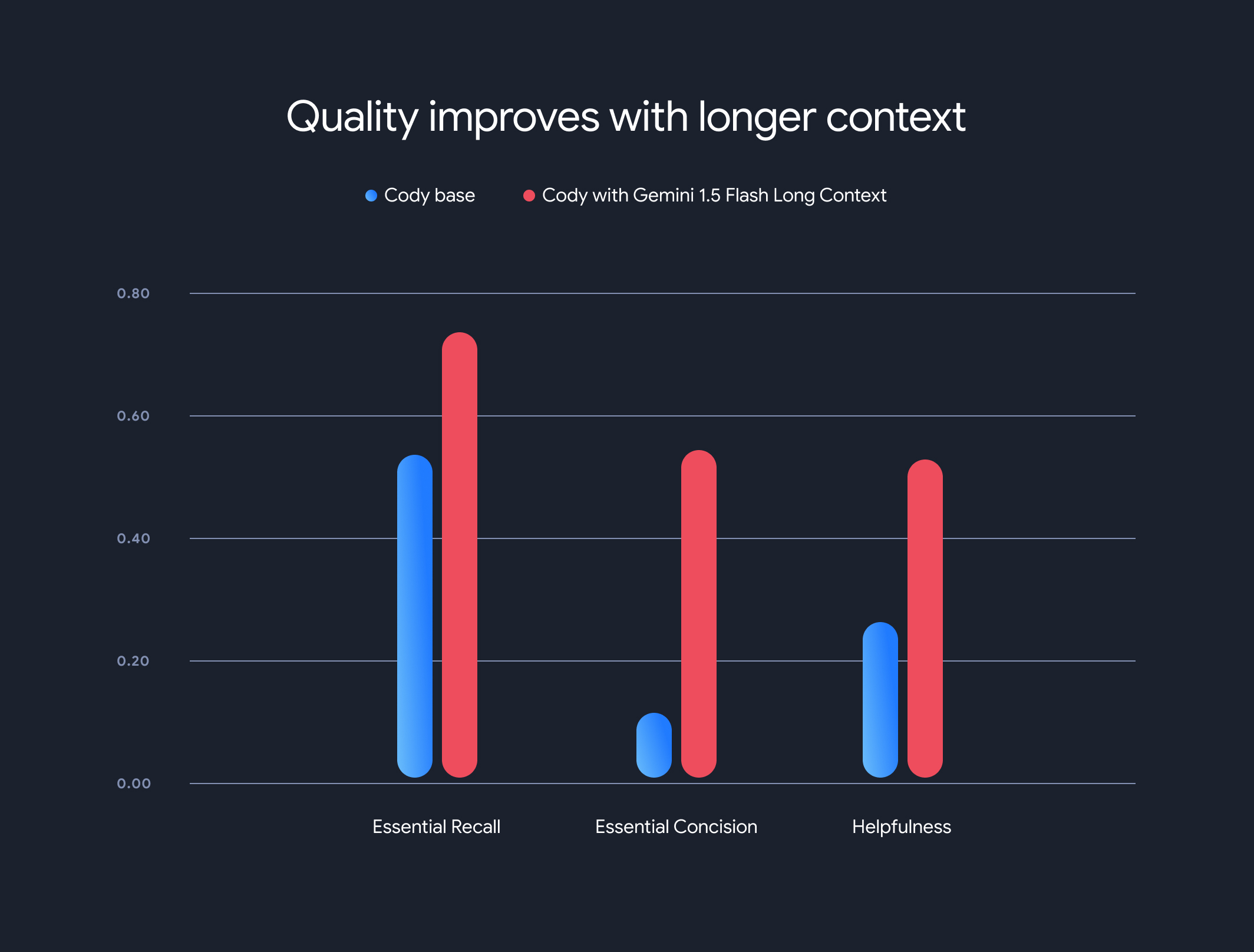
Les résultats ont été frappants. Trois des principaux benchmarks de Sourcegraph (Rappel essentiel, Concision essentielle et Utilité) ont montré des améliorations significatives lors de l'utilisation du contexte plus long.
Rappel essentiel : la proportion de faits essentiels dans la réponse a considérablement augmenté.
Concision essentielle : la proportion de faits essentiels normalisée par la longueur de la réponse s'est également améliorée, ce qui indique des réponses plus concises et pertinentes.
Utilité : le score global d'utilité, normalisé par la longueur de la réponse, a considérablement augmenté, ce qui indique une expérience plus conviviale.
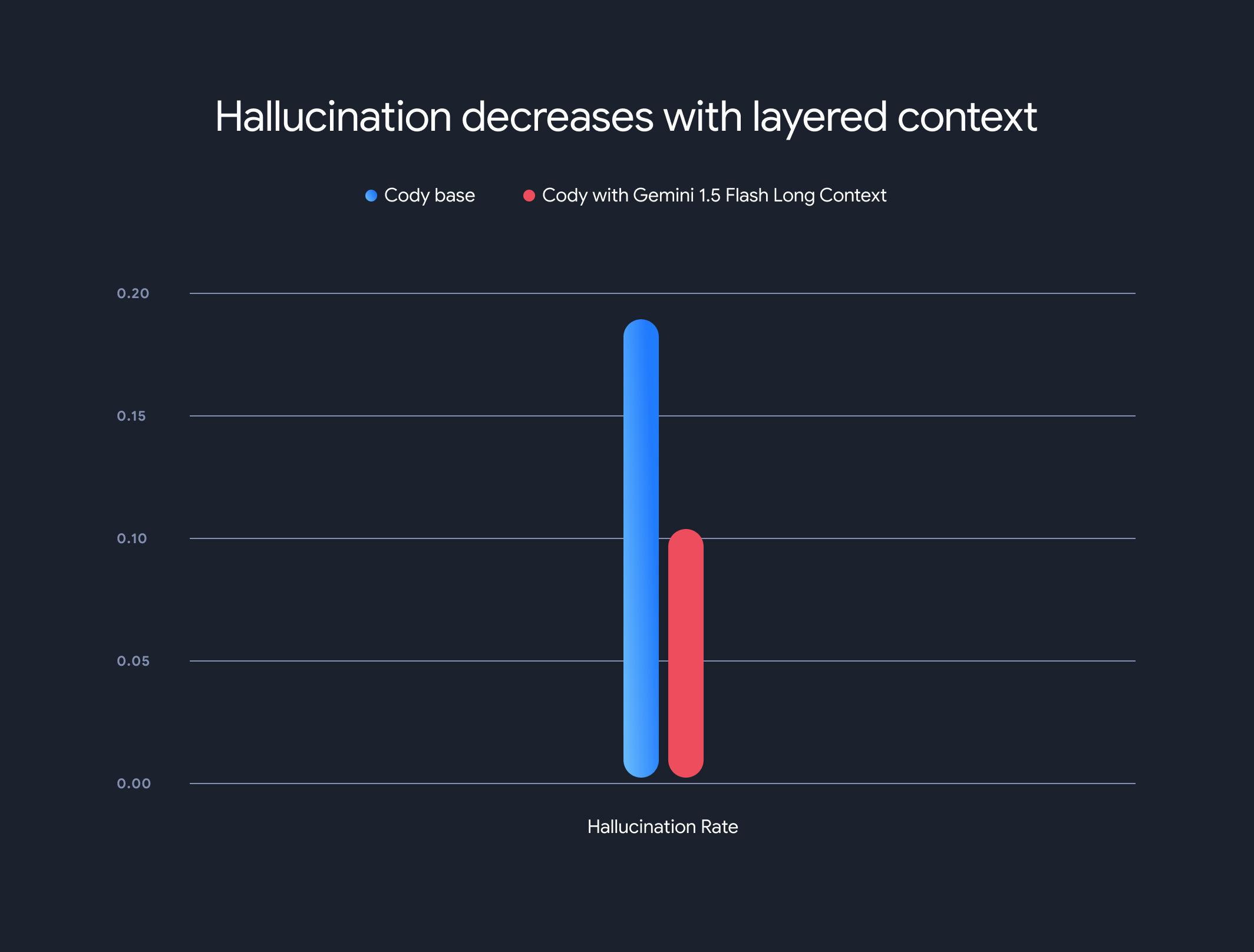
De plus, l'utilisation de modèles à contexte long a considérablement réduit le taux global d'hallucinations (génération d'informations factuellement incorrectes). Le taux d'hallucinations a diminué de 18,97 % à 10,48 %, ce qui représente une amélioration significative de la précision et de la fiabilité.
Compromis et orientation future
Bien que les avantages du contexte long soient considérables, il existe des compromis. Le temps avant le premier jeton augmente de manière linéaire avec la longueur du contexte. Pour atténuer ce problème, Sourcegraph a implémenté un mécanisme de préchargement et une architecture de modèle de contexte en couches pour la mise en cache de l'état d'exécution du modèle. Avec les modèles Gemini 1.5 Flash et Pro à long contexte, le temps de génération du premier jeton est passé de 30 à 40 secondes à environ 5 secondes pour les contextes de 1 Mo, ce qui représente une amélioration considérable pour la génération de code en temps réel et l'assistance technique.
Cette collaboration illustre le potentiel transformateur des modèles à long contexte pour révolutionner la compréhension et la génération de code. Nous sommes ravis de collaborer avec des entreprises comme Sourcegraph pour continuer à développer des applications et des paradigmes encore plus innovants grâce aux grandes fenêtres contextuelles.
Pour en savoir plus sur les méthodologies d'évaluation, les benchmarks et les analyses détaillés de Sourcegraph, y compris des exemples illustratifs, consultez leur article de blog détaillé.
Études de cas associées

AgentOps
Découvrez comment AgentOps fournit une observabilité des agents optimisée par les LLM, à la fois économique et puissante, pour les entreprises qui utilisent l'API Gemini.

Sous-calque
Découvrez comment le framework d'agents d'IA basé sur Ruby permet aux équipes de développement d'être plus productives grâce à la puissance des modèles Gemini.

Chambres
Des interactions plus riches avec les avatars grâce aux fonctionnalités de texte et audio de Gemini 2.0