
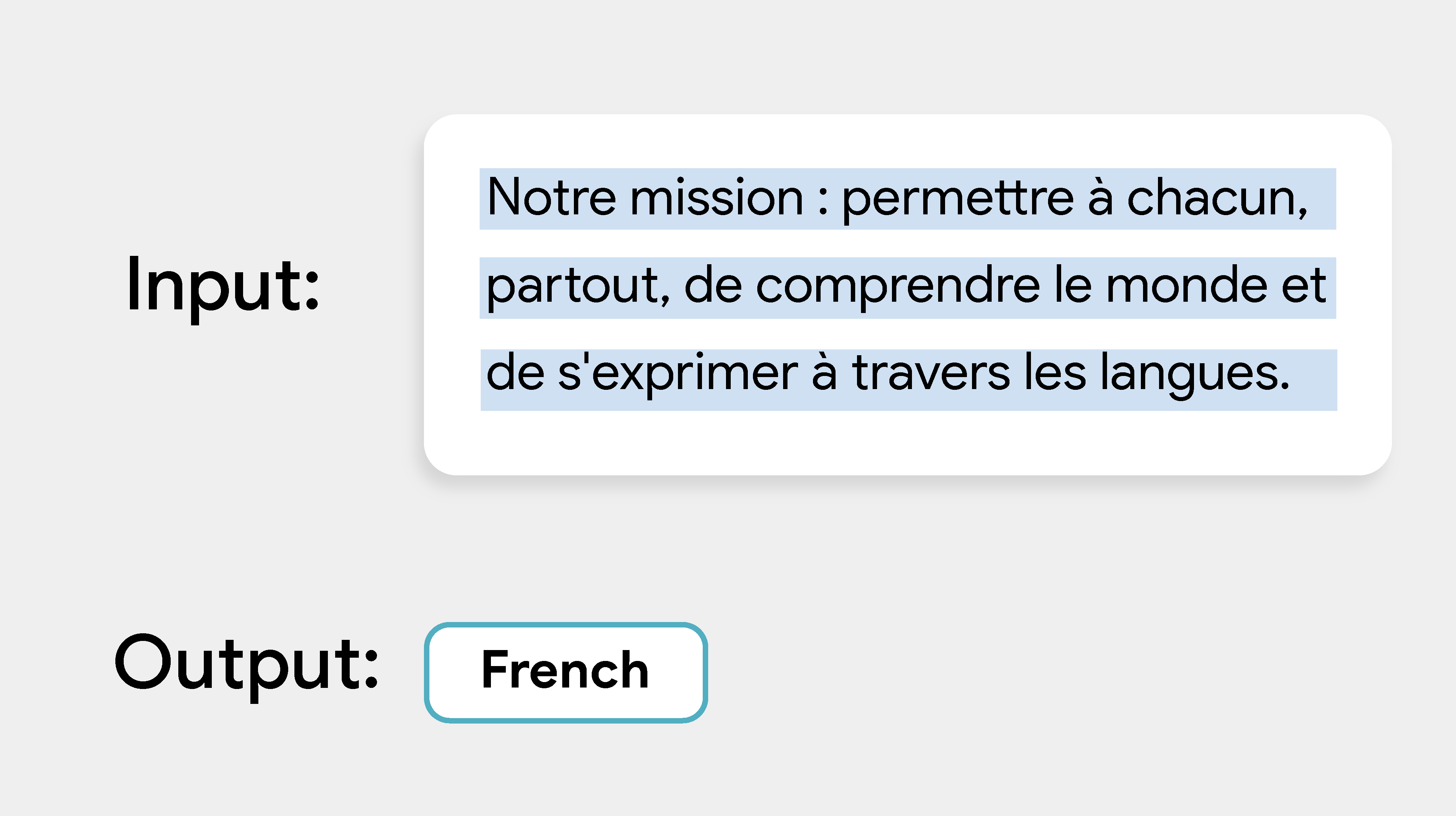
La tâche MediaPipe Language Detector vous permet d'identifier la langue d'un texte. Cette tâche fonctionne sur des données textuelles avec un modèle de machine learning (ML) et produit une liste de prédictions, où chaque prédiction consiste en un code de langue ISO 639-1 et une probabilité.
Premiers pas
Pour commencer à utiliser cette tâche, suivez l'un de ces guides d'implémentation pour votre plate-forme cible. Ces guides spécifiques à la plate-forme vous expliquent comment implémenter de manière basique cette tâche, y compris un modèle recommandé et un exemple de code avec les options de configuration recommandées:
- Android – Exemple de code – Guide
- Python – Exemple de code – Guide
- Web – Exemple de code – Guide
Détails de la tâche
Cette section décrit les fonctionnalités, les entrées, les sorties et les options de configuration de cette tâche.
Fonctionnalités
- Seuil de score : filtrez les résultats en fonction des scores de prédiction.
- Liste d'autorisation et de blocage des libellés : spécifiez les catégories détectées.
| Entrées de tâche | Sorties de tâche |
|---|---|
Le détecteur de langue accepte le type de données d'entrée suivant:
|
Le détecteur de langue génère une liste de prédictions contenant les éléments suivants:
|
Options de configuration
Cette tâche propose les options de configuration suivantes:
| Nom de l'option | Description | Plage de valeurs | Valeur par défaut |
|---|---|---|---|
max_results |
Définit le nombre maximal facultatif de prédictions de langue les plus élevées à renvoyer. Si cette valeur est inférieure à zéro, tous les résultats disponibles sont renvoyés. | N'importe quel nombre positif | -1 |
score_threshold |
Définit le seuil de score de prédiction qui remplace celui fourni dans les métadonnées du modèle (le cas échéant). Les résultats inférieurs à cette valeur sont rejetés. | N'importe quelle superposition | Non défini |
category_allowlist |
Définit la liste facultative des codes de langue autorisés. Si cet ensemble n'est pas vide, les prédictions de langue dont le code de langue ne figure pas dans cet ensemble sont filtrées. Cette option s'exclut mutuellement avec category_denylist. L'utilisation des deux entraîne une erreur. |
N'importe quelle chaîne | Non défini |
category_denylist |
Définit la liste facultative des codes de langue non autorisés. Si cet ensemble n'est pas vide, les prédictions de langue dont le code de langue figure dans cet ensemble seront filtrées. Cette option s'exclut mutuellement avec category_allowlist. L'utilisation des deux entraîne une erreur. |
N'importe quelle chaîne | Non défini |
Modèles
Nous proposons un modèle par défaut recommandé lorsque vous commencez à développer avec cette tâche.
Modèle de détecteur de langage (recommandé)
Ce modèle est conçu pour être léger (315 ko) et utilise une architecture de classification de réseau de neurones basée sur l'imbrication. Le modèle identifie la langue à l'aide d'un code de langue ISO 639-1 et peut identifier 110 langues. Pour obtenir la liste des langues acceptées par le modèle, consultez le fichier de libellés, qui liste les langues par code ISO 639-1.
| Nom du modèle | Forme d'entrée | Type de quantification | Fiche de modèle | Versions |
|---|---|---|---|---|
| Détecteur de langue | chaîne UTF-8 | none (float32) | info | Nouveautés |
Benchmarks des tâches
Voici les benchmarks de tâche pour l'ensemble du pipeline basés sur les modèles pré-entraînés ci-dessus. Le résultat de la latence correspond à la latence moyenne sur le Pixel 6 à l'aide du processeur / GPU.
| Nom du modèle | Latence du processeur | Latence du GPU |
|---|---|---|
| Détecteur de langue | 0,31 ms | - |