
Detyra MediaPipe Gesture Recognizer ju lejon të dalloni gjestet e duarve në kohë reale dhe ofron rezultatet e njohura të gjesteve të duarve dhe pikat referuese të duarve të zbuluara. Këto udhëzime ju tregojnë se si të përdorni "Njohësin e gjesteve" për aplikacionet në ueb dhe JavaScript.
Ju mund ta shihni këtë detyrë në veprim duke parë demonstrimin . Për më shumë informacion rreth aftësive, modeleve dhe opsioneve të konfigurimit të kësaj detyre, shihni Përmbledhjen .
Shembull kodi
Shembulli i kodit për Njohjen e Gjesteve ofron një zbatim të plotë të kësaj detyre në JavaScript për referencën tuaj. Ky kod ju ndihmon të testoni këtë detyrë dhe të filloni ndërtimin e aplikacionit tuaj të njohjes së gjesteve. Mund të shikoni, ekzekutoni dhe modifikoni shembullin e kodit të Njohësit të Gjesteve duke përdorur vetëm shfletuesin tuaj të internetit.
Konfigurimi
Ky seksion përshkruan hapat kryesorë për konfigurimin e mjedisit tuaj të zhvillimit në mënyrë specifike për të përdorur "Njohësin e gjesteve". Për informacion të përgjithshëm mbi konfigurimin e mjedisit tuaj të zhvillimit të uebit dhe JavaScript, duke përfshirë kërkesat e versionit të platformës, shihni udhëzuesin e konfigurimit për ueb .
Paketat JavaScript
Kodi i Njohjes së Gjesteve është i disponueshëm përmes paketës MediaPipe @mediapipe/tasks-vision NPM . Ju mund t'i gjeni dhe shkarkoni këto biblioteka duke ndjekur udhëzimet në udhëzuesin e konfigurimit të platformës.
Ju mund të instaloni paketat e kërkuara përmes NPM duke përdorur komandën e mëposhtme:
npm install @mediapipe/tasks-vision
Nëse dëshironi të importoni kodin e detyrës nëpërmjet një shërbimi të rrjetit të shpërndarjes së përmbajtjes (CDN), shtoni kodin e mëposhtëm në etiketën <head> në skedarin tuaj HTML:
<!-- You can replace JSDeliver with another CDN if you prefer to -->
<head>
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision/vision_bundle.js"
crossorigin="anonymous"></script>
</head>
Model
Detyra MediaPipe Gesture Recognizer kërkon një model të trajnuar që është në përputhje me këtë detyrë. Për më shumë informacion mbi modelet e trajnuara të disponueshme për Njohjen e Gjesteve, shihni seksionin Modelet e përmbledhjes së detyrave.
Zgjidhni dhe shkarkoni modelin dhe më pas ruajeni në direktorinë e projektit tuaj:
<dev-project-root>/app/shared/models/
Krijo detyrën
Përdorni një nga funksionet e "Njohjes së gjesteve" createFrom...() për të përgatitur detyrën për ekzekutimin e konkluzioneve. Përdorni funksionin createFromModelPath() me një shteg relative ose absolute drejt skedarit të modelit të trajnuar. Nëse modeli juaj tashmë është i ngarkuar në memorie, mund të përdorni metodën createFromModelBuffer() .
Shembulli i kodit më poshtë tregon përdorimin e funksionit createFromOptions() për të vendosur detyrën. Funksioni createFromOptions ju lejon të personalizoni Njohësin e Gjesteve me opsionet e konfigurimit. Për më shumë informacion mbi opsionet e konfigurimit, shihni Opsionet e konfigurimit .
Kodi i mëposhtëm tregon se si të ndërtoni dhe konfiguroni detyrën me opsione të personalizuara:
// Create task for image file processing:
const vision = await FilesetResolver.forVisionTasks(
// path/to/wasm/root
"https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision@latest/wasm "
);
const gestureRecognizer = await GestureRecognizer.createFromOptions(vision, {
baseOptions: {
modelAssetPath: "https://storage.googleapis.com/mediapipe-tasks/gesture_recognizer/gesture_recognizer.task"
},
numHands: 2
});
Opsionet e konfigurimit
Kjo detyrë ka opsionet e mëposhtme të konfigurimit për aplikacionet në ueb:
| Emri i opsionit | Përshkrimi | Gama e vlerave | Vlera e paracaktuar |
|---|---|---|---|
runningMode | Vendos modalitetin e ekzekutimit për detyrën. Ka dy mënyra: IMAGE: Modaliteti për hyrjet e një imazhi të vetëm. VIDEO: Modaliteti për kornizat e deshifruara të një videoje ose në një transmetim të drejtpërdrejtë të të dhënave hyrëse, si p.sh. nga një aparat fotografik. | { IMAGE, VIDEO } | IMAGE |
num_hands | Numri maksimal i duarve mund të zbulohet nga GestureRecognizer . | Any integer > 0 | 1 |
min_hand_detection_confidence | Rezultati minimal i besimit për zbulimin e dorës për t'u konsideruar i suksesshëm në modelin e zbulimit të pëllëmbës. | 0.0 - 1.0 | 0.5 |
min_hand_presence_confidence | Rezultati minimal i besimit të rezultatit të pranisë së dorës në modelin e zbulimit të pikës referimi me dorë. Në modalitetin "Video" dhe "Transmetimi i drejtpërdrejtë" i "Njohjes së gjesteve", nëse rezultati i sigurt i pranisë së dorës nga modeli i pikës së dorës është nën këtë prag, ai aktivizon modelin e zbulimit të pëllëmbës. Përndryshe, një algoritëm i lehtë i gjurmimit të dorës përdoret për të përcaktuar vendndodhjen e dorës(ave) për zbulimin e mëvonshëm të pikës referimi. | 0.0 - 1.0 | 0.5 |
min_tracking_confidence | Rezultati minimal i besimit që gjurmimi i dorës të konsiderohet i suksesshëm. Ky është pragu kufizues IoU i kutisë midis duarve në kuadrin aktual dhe kuadrit të fundit. Në modalitetin "Video" dhe "Transmetimi" i "Njohësit të gjesteve", nëse gjurmimi dështon, "Njohja e gjesteve" aktivizon zbulimin me dorë. Përndryshe, zbulimi i dorës anashkalohet. | 0.0 - 1.0 | 0.5 |
canned_gestures_classifier_options | Opsionet për konfigurimin e sjelljes së klasifikuesit të gjesteve të konservuara. Gjestet e konservuara janë ["None", "Closed_Fist", "Open_Palm", "Pointing_Up", "Thumb_Down", "Thumb_Up", "Victory", "ILoveYou"] |
|
|
custom_gestures_classifier_options | Opsionet për konfigurimin e sjelljes së klasifikuesit të gjesteve të personalizuara. |
|
|
Përgatitni të dhënat
Njohësi i gjesteve mund të njohë gjestet në imazhe në çdo format të mbështetur nga shfletuesi pritës. Detyra trajton gjithashtu parapërpunimin e hyrjes së të dhënave, duke përfshirë ndryshimin e madhësisë, rrotullimin dhe normalizimin e vlerës. Për të njohur gjestet në video, mund të përdorni API-në për të përpunuar shpejt një kornizë në një kohë, duke përdorur vulën kohore të kornizës për të përcaktuar se kur ndodhin gjestet brenda videos.
Drejtoni detyrën
Njohësi i gjesteve përdor metodat recognize() (me modalitetin 'image' ) dhe recognizeForVideo() (me modalitetin 'video' ) për të shkaktuar konkluzionet. Detyra përpunon të dhënat, përpiqet të njohë gjestet e duarve dhe më pas raporton rezultatet.
Kodi i mëposhtëm tregon se si kryhet përpunimi me modelin e detyrës:
Imazhi
const image = document.getElementById("image") as HTMLImageElement; const gestureRecognitionResult = gestureRecognizer.recognize(image);
Video
await gestureRecognizer.setOptions({ runningMode: "video" }); let lastVideoTime = -1; function renderLoop(): void { const video = document.getElementById("video"); if (video.currentTime !== lastVideoTime) { const gestureRecognitionResult = gestureRecognizer.recognizeForVideo(video); processResult(gestureRecognitionResult); lastVideoTime = video.currentTime; } requestAnimationFrame(() => { renderLoop(); }); }
Thirrjet në metodat e recognize() dhe recognizeForVideo() ekzekutohen në mënyrë sinkronike dhe bllokojnë lidhjen e ndërfaqes së përdoruesit. Nëse i dalloni gjestet në kornizat video nga kamera e një pajisjeje, çdo njohje do të bllokojë lidhjen kryesore. Ju mund ta parandaloni këtë duke zbatuar punëtorët e uebit për të ekzekutuar metodat recognize() dhe recognizeForVideo() në një thread tjetër.
Për një zbatim më të plotë të ekzekutimit të një detyre të Njohjes së Gjesteve, shihni shembullin e kodit .
Trajtoni dhe shfaqni rezultatet
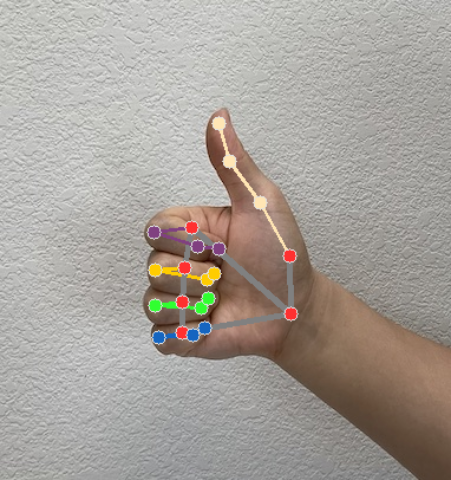
Njohësi i gjesteve gjeneron një objekt rezultati të zbulimit të gjesteve për çdo ekzekutim të njohjes. Objekti i rezultatit përmban pika referimi të dorës në koordinatat e imazhit, pika referimi të dorës në koordinatat e botës, aftësia e dorës (dora e majtë/djathtas) dhe kategoritë e gjesteve të duarve të duarve të zbuluara.
Më poshtë tregon një shembull të të dhënave dalëse nga kjo detyrë:
Rezultati i GestureRecognizerResult përmban katër komponentë, dhe secili komponent është një grup, ku secili element përmban rezultatin e zbuluar të një dore të vetme të zbuluar.
Duartësia
Duartësia përfaqëson nëse duart e zbuluara janë duart e majta apo të djathta.
Gjestet
Kategoritë e njohura të gjesteve të duarve të zbuluara.
Pikat e referimit
Ka 21 pika referimi, secila e përbërë nga koordinatat
x,ydhez. Koordinatatxdheynormalizohen në [0.0, 1.0] nga gjerësia dhe lartësia e imazhit, respektivisht. Koordinatazpërfaqëson thellësinë e pikës referuese, me thellësinë në kyçin e dorës që është origjina. Sa më e vogël të jetë vlera, aq më afër kamerës është pikë referimi. Madhësia ezpërdor përafërsisht të njëjtën shkallë six.Monumentet e botës
21 pikat referuese të dorës janë paraqitur gjithashtu në koordinatat botërore. Çdo pikë referimi përbëhet nga
x,ydhez, që përfaqësojnë koordinatat 3D të botës reale në metra me origjinën në qendrën gjeometrike të dorës.
GestureRecognizerResult:
Handedness:
Categories #0:
index : 0
score : 0.98396
categoryName : Left
Gestures:
Categories #0:
score : 0.76893
categoryName : Thumb_Up
Landmarks:
Landmark #0:
x : 0.638852
y : 0.671197
z : -3.41E-7
Landmark #1:
x : 0.634599
y : 0.536441
z : -0.06984
... (21 landmarks for a hand)
WorldLandmarks:
Landmark #0:
x : 0.067485
y : 0.031084
z : 0.055223
Landmark #1:
x : 0.063209
y : -0.00382
z : 0.020920
... (21 world landmarks for a hand)
Imazhet e mëposhtme tregojnë një vizualizim të daljes së detyrës:
Për një zbatim më të plotë të krijimit të një detyre të Njohjes së Gjesteve, shihni shembullin e kodit .